
CVPR 2022 | 即插即用!助力自监督涨点的ContrastiveCrop开源了!

极市导读
本文重新审视了传统使用的RandomCrop,指出了其在对比学习中的缺陷,并进一步为对比学习设计了新的裁剪策略。ContrastiveCrop旨在确保大部分正样本对语义一致的前提下,加大样本之间的差异性,从而通过最小化对比损失学习到更泛化的特征。ContrastiveCrop完全即插即用,且理论上适用于任何孪生网络架构。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
引言
自SimCLR、MoCo等自监督里程碑工作发表以来,对比学习已经在视觉领域引起了极大的关注和广泛的研究。在诸多下游任务上,对比学习预训练的模型已达到甚至超越有监督预模型的迁移训练结果。目前主流的对比学习方法均采用孪生网络(Siamese network)的架构,这不可避免地带来一个问题,就是如何选取作为孪生网络输入的训练样本对。
之前的工作已经指出,数据增强操作对于达到好的对比学习性能是至关重要的。然而,却鲜有工作考虑到样本对中两个图片块(crop)的选取。基于此,本文重新审视了传统使用的RandomCrop,指出了其在对比学习中的缺陷,并进一步为对比学习设计了新的裁剪策略,命名为“对比裁剪(ContrastiveCrop)”。ContrastiveCrop旨在确保大部分正样本对语义一致的前提下,加大样本之间的差异性,从而通过最小化对比损失学习到更泛化的特征。ContrastiveCrop完全即插即用,且理论上适用于任何孪生网络架构。广泛的实验表明,在几乎不增加训练内存和计算代价的前提下,ContrastiveCrop能够在若干常用数据集上稳定提升当前主流对比学习方法的性能。
1.论文和代码地址

论文地址:https://arxiv.org/abs/2202.03278
代码地址:https://github.com/xyupeng/ContrastiveCrop
2.研究动机
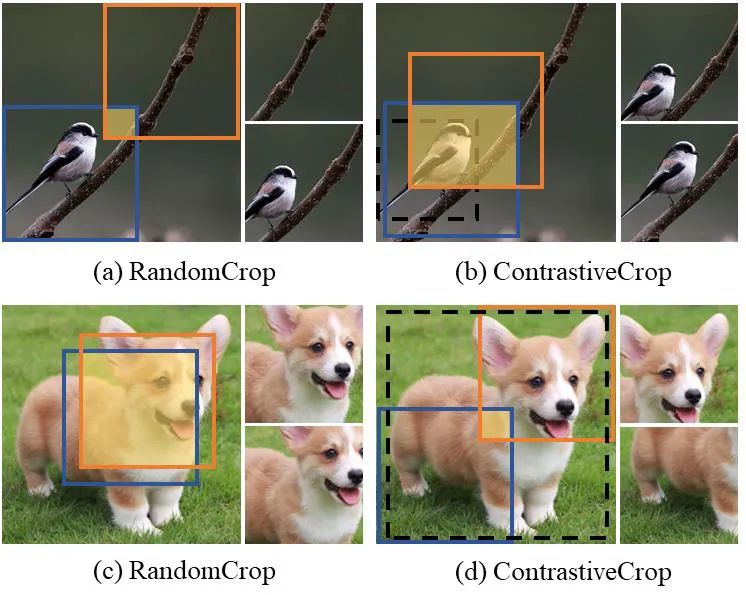
数据增强操作在对比学习中是至关重要的一个部分。以往对比学习的工作通常采用对于一张图片进行两次增强的操作,以获得同一图片的两个不同的景致(view)作为正样本对(positive pair)。尽管这些工作采用了更强的色彩增强方法(ColorJitter,GaussianBlur,GrayScale等),但是他们仍然采用随机裁剪(RandomCrop)这一监督学习中的传统裁剪策略。然而,在对比学习中,随机裁剪可能会生成错误的正样本对(如上图(a),物体对比背景),导致损害表征学习;或者有可能产生过于相似的正样本对(如上图(c)),对导致无效的优化目标。
基于此,本文提出为对比学习量身定制的”对比裁剪(ContrastiveCrop)”。ContrastiveCrop首先需要对物体轮廓进行大致的定位(Semantic-aware Localization上图虚线框),并由此来指导crops的选取。这样确保了大部分情况crop不会错失前景物体而造成错误的正样本对(如上图(b)避免了(a)中纯背景采样的情况)。在定位的基础上,ContrastiveCrop采用了中心压制的非均匀分布进行采样(Center-suppressed Sampling),增加了多次采样之间的方差,从而增大了不同crops之间的差异性(如上图(d)相比于(c)生成的crops差异性更大)。综合来说,ContrastiveCrop能够为对比学习提供语义信息一致而差异性更大的样本对,从而提升对比学习表征的泛化性。
3.方法
3.1 Preliminary
作者首先回顾了常用的裁剪方法RandomCrop。RandomCrop可以被公式化地表示为:
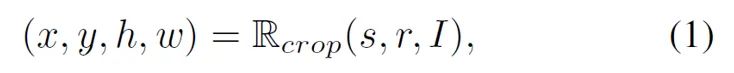
其中s代表了crop的大小(scale),r是crop的高宽比(aspect ratio),I是输入图片,Rcrop代表了随机裁剪函数,它返回一个四元组(x, y, h, w),分别定义了crop的中心坐标以及高宽。
理论上,RandomCrop使得任意大小和高宽的crop都能以相同的概率被采样出来。但是,它却没有考虑到图像中的语义信息,从而可能导致错误的正样本对。因此,设计一种知晓语义信息的裁剪策略对于对比学习来说是有必要的。
3.2 Semantic-aware Localization
为了能够获取图片的语义信息,作者首先对训练过程中的特征图进行了可视化(如下图)。

从图中可以发现,对比学习模型本身就可以捕捉物体大概的位置信息,从而来指导crops的选取。过去的对比学习方法在选取views的时候往往忽略了该信息。本文中,作者利用学习过程中的特征图来获取物体边框,具体如下式:
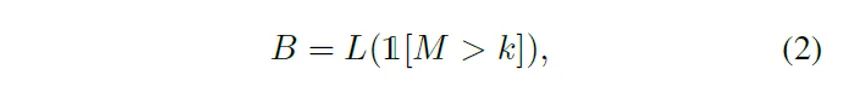
其中M代表特征图,k代表了激活点的阈值,是指示函数,L是计算矩形闭包的函数,它返回一个定位框B (如图2虚线框所示)。在得到定位框B后,采样可以被表示为
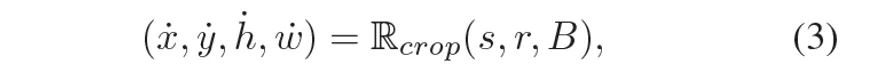
考虑到该定位框B并不完全准确,并且为了能够涵盖部分物体周围背景信息,作者仅将crop的中心限制在该框内。作者还在图3中展示了Semantic-aware Localization的效果(第二行)。对比原始的RandomCrop (第一行),加入定位信息能够很大程度上避免错误正样本对。此外,该定位框是从模型本身的特征中获取的,不需要引入额外的定位功能。

3.3 Center-suppressed Sampling
Semantic-aware localization很大程度上避免了错误正样本对的产生。但是由于其带 来了更小的选取范围, 生成具有较高相似度的样本对的可能性也提高了。为了解决这 个问题, 作者提出了“中心压制采样(Center-suppressed Sampling)"。它的核心思想 是降低crops集中在图片中心的概率, 从而增大采样的方差。具体来说, 作者选用了 Beta分布 作为采样的概率分布, 并控制 使得分布呈中间低、周围高的U 型(见图3第三行最左第一张图)。以这种概率分布进行采样能够使得crops更多地分散 在采样区域的四周, 从而减少相互之间的重叠区域。
将Semantic-aware Localization和Center-suppressed Sampling结合起来,就得到了最终的ContrastiveCrop,具体表示为
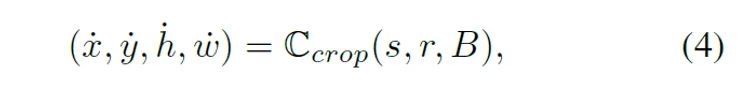
其中是代表中心压制采样的函数,B是式(2)中的定位框。ContrastiveCrop的效果在图3中有展示(第三行)。它有效地去除了绝大部分的错误正样本对,同时增大了正样本之间的差异性。整个ContrastiveCrop的流程在算法1中展示。

4.实验
作者在CIFAR-10/100, Tiny ImageNet,STL-10和ImageNet数据集上对一些主流对比学习方法(SimCLR, MoCo V1 & V2,BYOL,SimSiam)做了线性分类实验。作者同时也在下游目标检测和实例分割任务上验证了方法的迁移效果。
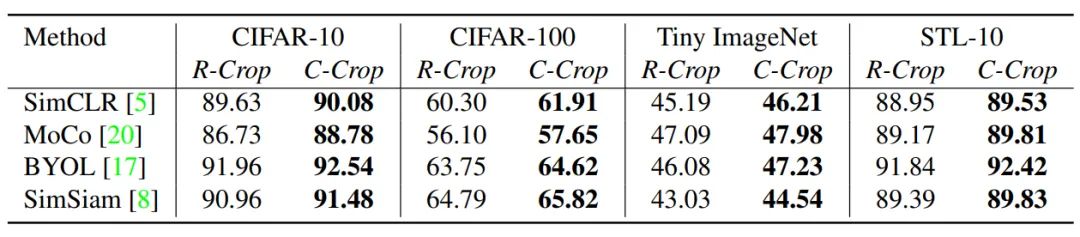
表1对比了RandomCrop (R-Crop)和ContrastiveCrop (C-Crop)在一些小规模数据集上的线性分类表现。对于不同数据集和不同对比学习方法,ContrastiveCrop稳定比RandomCrop高了0.4%~2.0%分类准确率。
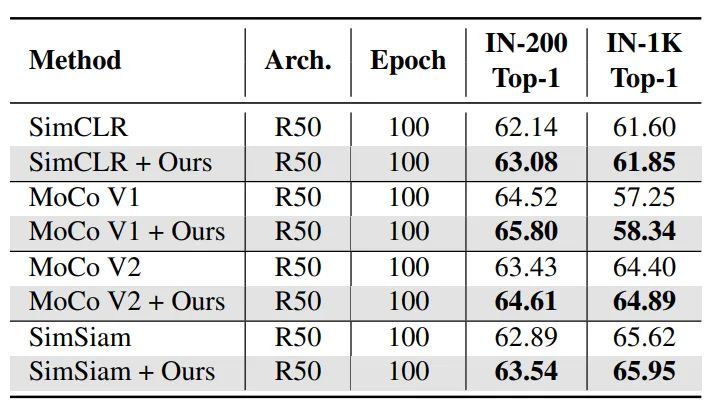
表2展示了在ImageNet随机200类(IN-200)以及整个1000类(IN-1K)上的线性分类准确率。ContrastiveCrop的结果仍然全面高于使用RandomCrop的原始方法。
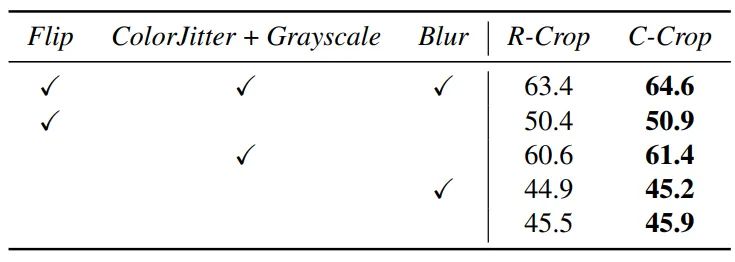
作者还展开了与其他变换(transformation)结合的消融实验。如表3所示,去掉其他所有transformation、单纯使用ContrastiveCrop就可以带来提升。而加上其他所有transformation则可以最大程度地发挥ContrastiveCrop的作用,带来最大的提升。
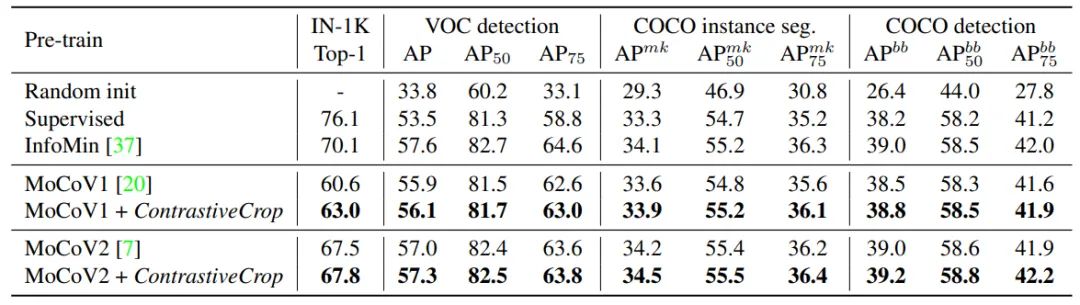
最后,在下游目标检测和实例分割任务上,ContrastiveCrop预训练模型的微调结果也一致好于RandomCrop。
5.总结
这篇文章审视了传统RandomCrop在对比学习中的缺陷,并提出为对比学习量身定制的ContrastiveCrop。ContrastiveCrop通过Semantic-aware Localization来确保大部分正样本对的语义一致性,并通过Center-suppressed Sampling加大样本之间的差异性。广泛的实验表明,简单替换RandomCrop为ContrastiveCrop就能够为对比学习带来稳定的性能提升。
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
