(附论文)CVPR 2021 | 不需要标注了?看自监督学习框架如何助力目标检测
文章提出了一个自监督学习框架,可从未标注的激光雷达点云和配对的相机图像中进行点云运动估计,与现有的监督方法相比,该方法具有良好的性能,当进一步进行监督微调时,模型优于 SOTA 方法。



论文链接:https://arxiv.org/pdf/2104.08683.pdf




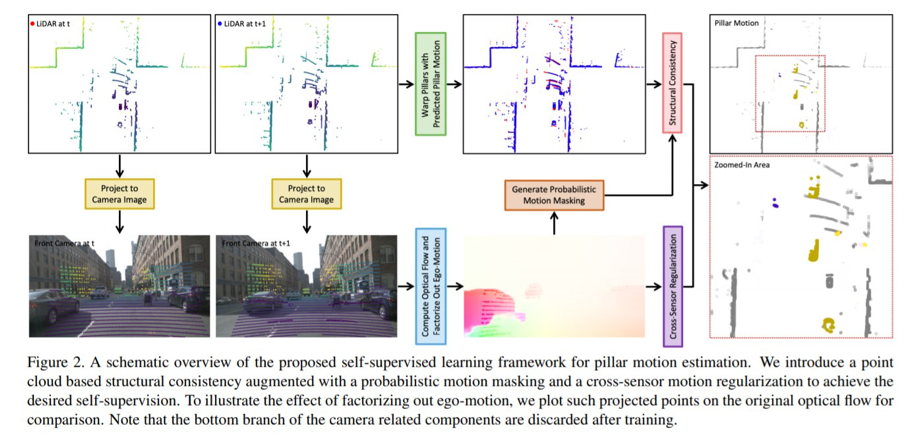


图 3:概率运动掩膜说明,左:投影点在前向相机图像上的光流(已将自我运动分解)。右:点云的一部分,颜色表示非空体柱的静态概率。
研究人员首先进行了各种组合实验,以评估设计中每个单独组件的贡献。如表 1 所示:

表 1:每个单独组件的贡献,结果包括均值和中位误差。

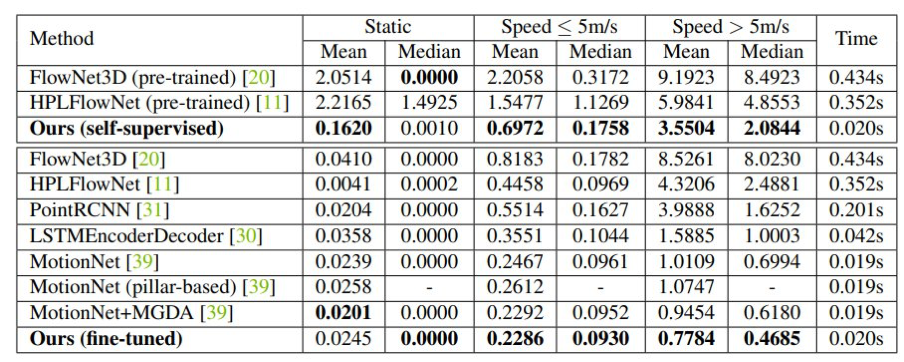
表 3:与 SOTA 结果对比。实验分为三个速度组,表中记录了平均误差和中位误差。

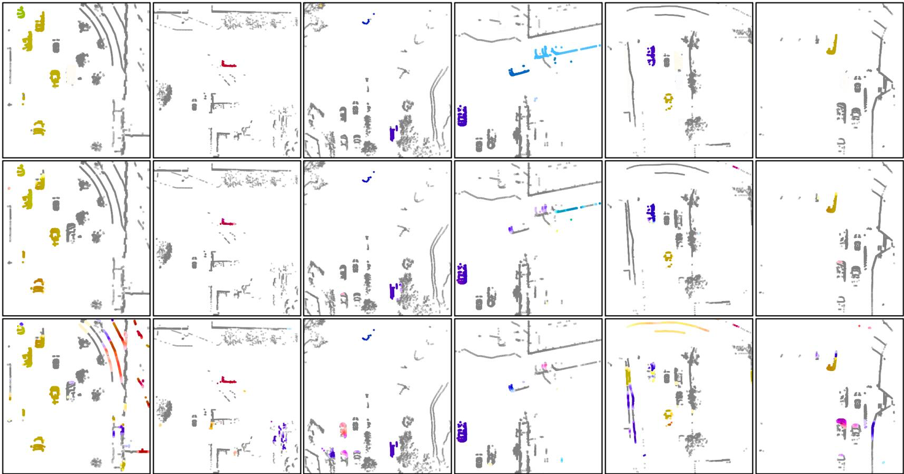
图 5:点云体柱运动预测对比。第一行显示真值运动场,第二行显示的是该研究全模型的评估结果,而只使用结构一致性的基础模型的预测结果在第三行。每一列都演示了一个场景。

✄------------------------------------------------
双一流高校研究生团队创建 ↓
专注于目标检测原创并分享相关知识 ☞
整理不易,点赞三连!
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报
