
【论文解读】Fixing Translation Divergences in Parallel Corpora 机器翻译分歧
Fixing Translation Divergences in Parallel Corpora for Neural MT 修复神经机器翻译平行语料库中的翻译分歧
这是 Multilingual Natural Language Processing (多语言自然语言处理) 的课推荐读的论文。
机器翻译领域确实好多 challenge,但是人工智能领域好多问题真的说白了都是数据集的问题 orz。
看一下大家的解决方案~
0. 摘要
基于语料库的机器翻译方法依赖于干净的平行语料库的可用性。但是这些资源是稀缺的,而且由于在准备过程中涉及自动过程,它们通常很 noisy。
本文描述了一种用于检测平行句中翻译分歧的无监督方法。
我们依靠一个神经网络来计算跨语言句子相似度分数,然后用它来有效地过滤掉不同的翻译。
此外,网络预测的相似性分数用于识别和修复一些部分分歧,产生额外的平行片段。我们针对英法和英德机器翻译任务评估了这些方法,并表明使用过滤/校正的语料库实际上提高了 MT 性能。
1. 介绍
机器翻译 (Machine Translation, MT) 系统的质量在很大程度上取决于平行句对的可用性和质量。平行文本是稀缺资源,并且存在大型平行语料库的语言对很少。
为了解决并行数据的缺乏,已经开发了各种方法,包括使用非并行或可比较数据的方法,从单语语料库生成合成并行数据的技术,以及容易在生成的并行中引入噪声的自动对齐/翻译引擎句子。平行句中的不匹配是一个常见问题,在 MT 中大多被忽略,但它们似乎对神经 MT 引擎尤为重要。
下表是语义不同的平行句子的例子。英语 (en)、法语 (fr) 和法语注解 (gl)。分歧以粗体字表示:

表中给出了一些从 OpenSubtitles 语料库中提取的不完全语义等同的英法平行句示例。在平行语料库中发现多种类型的翻译分歧:
平行句子的两边(第一行和第二行)包含额外的片段,很可能是由于句子分割错误
有些翻译可能完全不相关(第三行)
不准确的翻译也存在(第四行)
我们提出了一种基于建模单词相似性构建跨语言句子嵌入的无监督方法,该方法依赖于能够识别几种常见跨语言分歧的神经架构。然后使用生成的嵌入来衡量句子之间的语义等价性。
为了评估我们的方法,我们发现过滤掉英法和英德翻译任务中的不同句子对后,可以提高翻译准确性。另外在某些情况下,可以通过删除不同的片段来修复不同的句子,从而进一步提高翻译质量。
2. Related Work
衡量机器翻译 (MT) 中翻译分歧的影响主要集中在句子对齐中引入噪声。结果表明,统计 MT 对噪声具有很强的鲁棒性,而神经 MT 往往更敏感。已经进行了几项研究来表征文本片段之间的语义等价程度。
一项研究提出了一种单语句子相似性网络,该网络在文本蕴含任务中取得了最先进的结果。
另一项研究训练了一个基于 SVM 的跨语言分歧检测器,结果表明,仅在非分歧句子上训练的 NMT 系统的翻译分数略高,同时需要较少的训练时间。
我们的工作不同之处在于,我们使用具有更简单拓扑结构的网络通过优化基于单词对齐的损失函数来建模句子相似度,并预测单词相似度分数以纠正分歧的句子。
3. Neural Divergence 分类器
我们网络的架构受到 word alignment (词对齐)工作的启发。使用上下文而不是固定的词嵌入
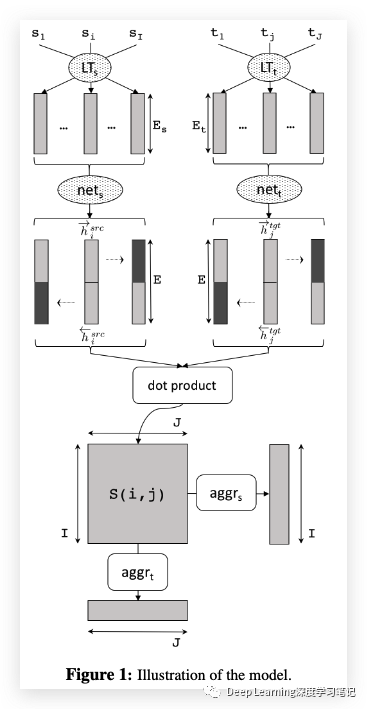
它计算任何源-目标句子对 的相似度,其中 和 。该模型由 2 个双向 LSTM 子网络 和 组成,分别对源句和目标句进行编码。
由于 和 采用相同的形式,我们只描述前一个网络:它输出前向和后向隐藏状态 和 。
然后将它们连接成一个向量,编码第 个源词作为 ;。
此外,最后的前向/后向隐藏状态(图 1 中的深灰色)也被连接起来表示整个句子 ;。然后可以使用例如获得句子对之间的相似性。例如余弦相似度:
(Eq 1)
我们的模型经过训练以最大化两个句子中单词之间的单词对齐分数,使用汇总每个源/目标单词的对齐分数的聚合函数。对齐分数 由点积 给出,进一步 aggregated 如下:
(Eq 2)
训练 loss:
(Eq 3)
3.1 反例训练
训练是通过最小化损失函数来进行的。为此需要源 () 和目标 () 词的注释示例。作为正面例子,我们使用平行语料库的成对句子;这些句子中的所有单词都被标记为平行 。
我们考虑三种类型的反面实例:
基本情况使用随机不成对的句子。
在这种情况下,所有单词都被标记为 divergent 。
由于负对可能很容易分类并且我们希望我们的网络检测不太明显的分歧,我们进一步创建更困难的负样本如下。
我们首先用具有相同词性的单词序列替换源或目标中的随机单词序列。未替换的单词被视为平行 ,而被替换的单词被注释为 。与某些替换词对齐的词也被分配了 divergent 标签。例如,给定原始句子对:
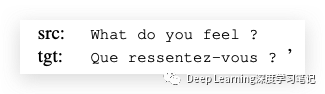 我们可以用词性标签“PRP VB”替换“you feel”,用另一个具有相同标签的序列(即“we want”),产生一个新的否定实例(不同的词以粗体显示):
我们可以用词性标签“PRP VB”替换“you feel”,用另一个具有相同标签的序列(即“we want”),产生一个新的否定实例(不同的词以粗体显示):
我们需要 word alignments (单词对齐)来识别序列 “ressentez-vous” 的 divergent,它与原始句子中的“you feel”对齐。
最后,由于在许多语料库中观察到的句子分割错误,我们还通过在源(或目标)句子的开头(或结尾)插入一个句子来构建反例。
原始句子对中的词被标注为 ,而插入的新词被认为是 divergent 的。给定与上面相同的句子对,通过在原始来源的末尾插入句子“Not.” 来创建一个反例:

为了最终避免生成句子长度差异较大的简单否定句对,我们将否定示例限制为长度比 < 2.0(最短句子为 3.0)。
3.2 Divergence Correction
我们的训练语料库包含许多遵循共同模式的不同句子,包括添加一些额外的前导/尾随词。
因此,我们实现了一个简单的算法,可以丢弃两侧的前导/尾随单词序列。为了找到包含原始句子中平行片段的最佳源 和目标 索引,我们计算:
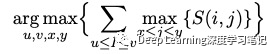
序列 被认为是可能的校正,其中我们使用具有最高相似性得分的序列来替换原始序列 。请注意,不考虑短句,我们强制 和 。下图(左)显示了对齐矩阵 的示例:
一个可接受的 correction 是:
Que ressentez-vous ? ⇔ What do you feel ?
对应于 。
4 Experiments
4.1 Corpora
我们从英语-法语 OpenSubtitles 语料库中过滤掉 divergences,该语料库由一系列电影和电视字幕组成。我们还使用非常 noisy 的英语-德语 Paracrawl4 语料库。
这两个语料库都存在许多潜在的分歧。为了评估英法翻译性能,我们使用了 En-Fr Microsoft Spoken Language Translation 语料库,该语料库是根据实际的 Skype 对话创建的。英语-德语的表现是在公开可用的 Newstest-2017 上评估的,对应于从在线资源中选择的新闻报道。
为了更好地评估我们的分类器在面对不同单词分歧时的质量,我们还从原始 OpenSubtitles 语料库中收集了 500 个包含不同类型示例的句子:
200 对句子; 100 个不成对的句子; 100个带有替换示例的句子; 100 个带有插入示例的句子。
所有数据都使用 OpenNMT5 进行预处理,执行最少的标记化。在标记化之后,每个词汇表之外的单词都被映射到一个特殊的 UNK 标记,假设词汇表包含 50000 个更频繁的单词。
4.2 Neural Divergence
个单元格的词嵌入使用 fastText 进行初始化,通过 MUSE (Multilingual Unsupervised and Supervised Embeddings)[2] 进一步对齐。
两个双向 LSTM 都使用 256 维隐藏表示 。网络优化是使用带有梯度裁剪的 SGD 完成的。对于每个 epoch,我们随机选择 100 万个句子对,每 batch 放置 32 个示例。我们运行 10 个 epoch,当验证集的损失增加时,每个 epoch 从 0.8 开始衰减。Divergence 按照(equation1) 计算,并设置 r = 1.0;对于 divergence correction,我们使用 N = 20 和 τ = 3。每种类型的示例(Paired, Unpaired, Replace 和 Inser)始终生成相同数量的示例。替换和插入方法所需的对齐是使用 fast align[3] 执行的
4.3 Neural Translation
除了上面详述的基本标记化之外,我们还执行 Byte-Pair Encoding,其中包含通过连接两种语言端学习的 30000 次合并操作。神经系统基于开源项目 OpenNMT;使用类似于 Transformer 的模型。
编码器和解码器都有 6 层
多头注意力在 8 头以上
隐藏层大小为 512
前馈网络的内层大小为 2048
词嵌入有 512 个 cells
dropout probability 设置为 0.1
batch size 设置为 3072
优化器是 Lazy Adam,β1 = 0.9,β2 = 0.98
warmup steps = 4000
训练在 30 个 epoch 后停止
5 Results
我们评估了 divergence 分类器在单词级别预测不同类型发散的能力。测试集是手动标注的,模型是在 OpenSubtitles 语料库上训练的。如果一个词的聚合分数为负,则该词被认为是 divergence 的。
结果表明,只要模型是用这些类型的例子训练的,平行和不成对的句子中的 non-divergent 词很容易被发现。
然而,当模型没有使用不成对的句子进行训练时,准确性会急剧下降。包含 divergent 词和 non-divergent 词混合的句子的准确性较低。

下图图 2 说明了我们的网络在使用 PU 示例(右)和 PURI 示例(左)进行训练时的输出。前者(右)无法预测某些分歧,很可能是因为其训练集不包含混合分歧和非分歧词的句子。此外,使用 PURI 示例训练的网络正确地为该对分配了较低的相似性分数,因为两个句子没有传达完全相同的含义。
最后,使用不同训练数据配置获得的 BLEU 分数如表 3 所示:
整个数据集 (all)
优化 equation 3 后最相似的对 (sim)
在应用 (sim+fix) 的校正算法之后
Ref 和 Fix 列表示训练中使用的原始句子和更正句子的数量(以百万为单位)

过滤句子对 (sim) 后获得的结果明显优于基线(all), 分别为 +0.94 和 +2.25 BLEU。
关于 OpenSubtitles,当修复 250 万个句子(第 4 行)时,准确度进一步提高了 +2.01,而相同的句子对在以其原始形式(第 3 行)添加时没有显示任何改进。
Paracrawl 语料库也得到了类似的结果。修复 250 万个句子(第 4 次)后的结果优于使用原始形式(第 3 次)获得的结果。
6 结论与展望
介绍了一种基于深度神经网络的无监督方法,用于检测平行语料库中的翻译差异。该模型优化单词对齐并在单词级别计算细粒度的分歧预测。过滤掉未对齐或发散的单词的结果会产生更大更好的训练集。与使用整个数据集进行训练相比,实验显示出显著的改进。
我们计划使用该模型预测单语语料库上的句子嵌入,通过向量相似性度量收集平行对,并在应用子词标记化和使用多个 LSTM 层捕获机器翻译上下文中的层次结构后测量性能。
Reference
知乎 Echo: https://zhuanlan.zhihu.com/p/605716470
[1]原文地址:https://aclanthology.org/D18-1328/
[2]Facebook research 多语言无监督和监督嵌入: https://github.com/facebookresearch/MUSE
[3] word aligner: https://github.com/clab/fast_align
[4] github 地址:https://github.com/SYSTRAN/similarity