
装逼一步到位!GauGAN代码解读来了
共 3781字,需浏览 8分钟
·
2021-07-31 21:49
AI神笔马良
如何装逼一步到位?从涂鸦到栩栩如生,英伟达的神器GauGAN来了,拥有神笔马良之手,五步画马就是这么简单。下面让我们一起解析GauGAN的代码实践过程。
GauGAN简介
英伟达的“神笔马良“,可以把涂鸦变成风景画,如同下图:
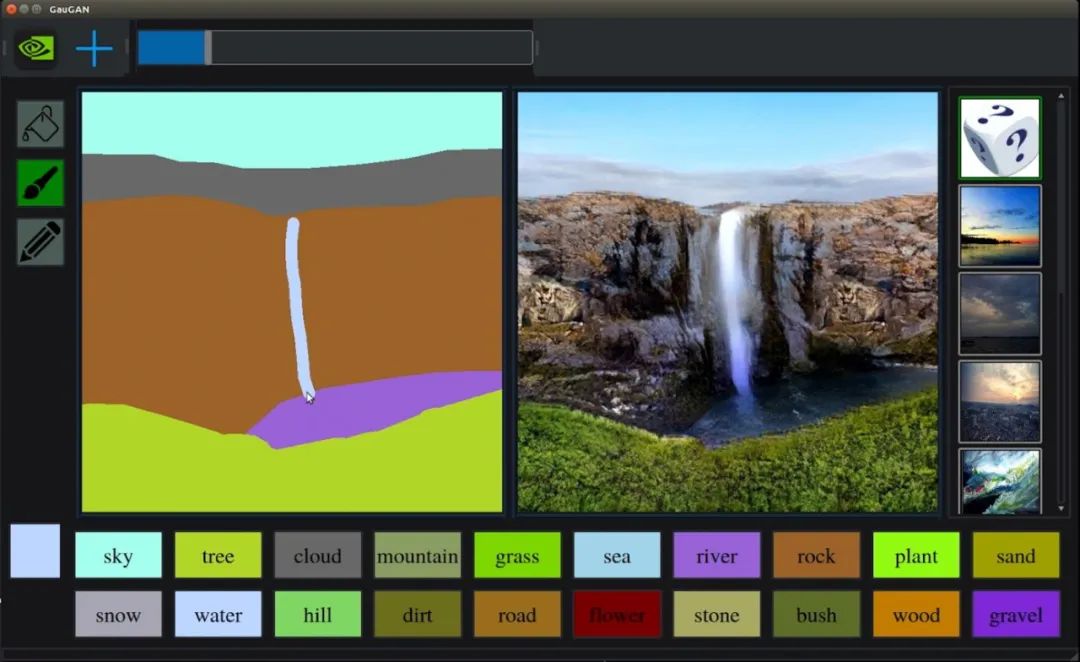
这个模型可以将一张涂鸦(语义图)生成相应的一张真实图,不少原画师已经用来画背景图了,它是怎么做到的?我们今天就来解读GanGAN代码,并使用相关数据集进行实验。
代码解读
开始前,先看下模型的创新思路:作者假设,如果语义图输入单个类别,传统的归一化层(normalization layer)倾向于“抹除”语义信息,因此作者提出了SPADE(SPatially-Adaptive (DE)normalization) 方法,GauGAN直接使用语义mask对输出激活值进行建模,即提出的空间自适应层。并且其方法可以应对各种使用语义图的生成任务。
环境配置
将SPADE代码克隆至本地,考虑到一些地区的网络可能不太好,提供一个加速通道:
git clone https://github.com.cnpmjs.org/NVlabs/SPADE.git
进入目录,根据命令行安装依赖和归一化分支:
# 安装依赖
cd SPADE/
pip install -r requirements.txt
# Synchronized BatchNorm
cd models/networks/
git clone https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
cp -rf Synchronized-BatchNorm-PyTorch/sync_batchnorm .
cd ../../
数据集ADE20K准备
下载地址:https://gas.graviti.cn/dataset/shannont/ADE20K?utm_medium=0728datawhale

数据规模:
训练集:25574;验证集:2K;测试集:3K 内容:365个场景;3688个类别。
ADE20K 的数据集,可用于场景感知、解析、分割、多物体识别和语义理解。
图像涵盖了SUN和Places数据集中的场景,官网可视化给出了目标、部件和注释示例的数量的列表。
树状表只展示了带有超过 250 个注解示例的目标,以及带有超过 10 个注解示例的部件。

一些类别可以既是目标,也是部件。例如,一个「门」可以是一个目标(在一张室内图片中)或者一个部件(当它是车的一个门时)。一些目标经常是部件(比如一条腿、一只手),尽管在某些情况下它们看起来与整体是相互独立的(比如车库中的汽车轮子)。
而有些目标则永远不是部件(比如一个人,一辆卡车等等)。依据于部件所属的目标,相同的名称类别(比如门)可对应于若干个视觉范畴。例如,一个汽车的门从视觉上看是不同于一个橱柜的门的。然而它们也共享一些相似的可供性(affordance)。
当目标不是另一个目标的一个部件时,其分割掩码将出现在 * _seg.png 内。
如果分类是一个部件,则分割掩码将出现在 * _seg_parts.png 内。正确检测目标需要区分目标是否表现为独立目标,或者是否是另一目标的一个部件。

代码结构
官方提供的代码结构如下:

data:实现数据加载base_dataset.py是最底层的数据结构,它继承pytorch的data.Dataset类建立一个BaseDataset类,定义了get_params,get_transform等等一些函数,方便之后的使用。pix2pix_dataset.py创建了一个Pix2pixDataset类,继承了BaseDataset类,这个类才是这个工程基本的数据类型,它重写了getitem()函数,这个函数返回一个input_dict的字典,索引包括label,instance,image,path其他的.py文件都是自定义的数据集的类(ADE20K,coco等等)。
options:定义命令行参数,base_options.py定义公共的命令行参数,train_options.py和test_options.py分别定义训练和测试的命令行参数。base_options.py中包括一些在自定义数据集中比较重要的参数:label_nc为输入标签数量,contain_dontcare_label是否包含不需要的标签。use_vae是否加入风格控制,no_instance训练过程是否加入实例。model:该文件夹下的network定义了模型的各个部分normalization.py文件内定义了SPADE归一化层,为了方便实用,也创建了不使用SPADE的结构,同时定义了VGG19结构。base_network.py定义基本的网络架构,后面的所有网络类型都是继承它得到的,它的功能包括打印网络的结构,初始化各个参数。
训练新模型
如果是使用作者文档中提到的数据集,可以使用下面这行代码进行训练:
python train.py --name [experiment_name] --dataset_mode facades --dataroot [path_to_facades_dataset]
python train.py --name [experiment_name] --dataset_mode coco --dataroot [path_to_coco_dataset]
其中experiment_name是自定义的名称,dataroot后接数据集的路径。
由于ade20k的数据集比较大,我也会使用小型一点的ade20k_outdoor进行训练。将ade20k_outdoor数据集存储在datasets文件夹下。

自定义数据集可以参考使用此段命令:
python train.py --name ade_outdoor --dataset_mode custom --label_dir ./datasets/ade20k_outdoor/train_label --image_dir ./datasets/ade20k_outdoor/train_img --label_nc 300 --contain_dontcare_label
完成后在checkpoints中将看到保存好的训练模型,终端打印出Training was successfully finished。
测试模型
接下来你可以使用刚刚训练好的模型进行测试,name_of_experiment是上面自定义的名称,
python test.py --name [name_of_experiment] --dataset_mode [dataset_mode] --dataroot [path_to_dataset]
自定义数据集使用下面这行:
python test.py --name [name_of_experiment] --dataset_mode custom --label_dir ./datasets/ade20k_outdoor/val_label --image_dir ./datasets/ade20k_outdoor/val_img --label_nc 300 --contain_dontcare_label
输出结果将默认保存至results文件夹。

结果分析
下面展示一下借助GauGAN由标签图生成真实图像的结果:

从生成结果来看,本文方法有更好的视觉效果,artifact也相对比较少。可以认为,SPADE的效果好主要还是更好的保留了语义图中的语义信息的。