
一文读懂 QUIC 协议:更快、更稳、更高效的网络通信
作者 | 李龙彦
来源:infoQ

你是否也有这样的困扰:打开 APP 巨耗时、刷剧一直在缓冲、追热搜打不开页面、信号稍微差点就直接加载失败……
如果有一个协议能让你的上网速度,在不需要任何修改的情况下就能提升 20%,特别是网络差的环境下能够提升 30% 以上;如果有一个协议可以让你在 WiFi 和蜂窝数据切换时,网络完全不断开、直播不卡顿、视频不缓冲;你愿意去了解一下它吗?它就是 QUIC 协议。本文将从 QUIC 的背景、原理、实践部署等方面来详细介绍。
类似于我们生活中签署的合同一样,比如买卖合同是为了约束买卖双方的行为按照合同的要求履行,网络协议是为了约束网络通信过程中各方(客户端、服务端及中间设备)必须按照协议的规定进行通信,它制定了数据包的格式、数据交互的过程等等,网络中的所有设备都必须严格遵守才可以全网互联。
在网络协议栈中,是有分层的,每一层负责不同的事务。我们讨论最多的有三个:应用层、传输层、网络层。应用层主要是针对应用软件进行约束,比如你访问网站需要按照 HTTP 协议格式和要求进行,你发送电子邮件需要遵守 SMTP 等邮件协议的格式和要求;传输层主要负责数据包在网络中的传输问题,比如如何保证数据传输的时候的安全性和可靠性、数据包丢了怎么处理;网络层,也叫路由转发层,主要负责数据包从出发地到目的地,应该怎样选择路径才能更快的到达。合理的网络协议能够让用户上网更快!
HTTP/3 是第三个主要版本的 HTTP 协议。与其前任 HTTP/1.1 和 HTTP/2 不同,在 HTTP/3 中,弃用 TCP 协议,改为使用基于 UDP 协议的 QUIC 协议实现。所以,HTTP/3 的核心在于 QUIC 协议。显然,HTTP/3 属于应用层协议,而它使用的 QUIC 协议属于传输层协议。
很多人可能都会有这样一个疑问,为什么在 2015 年才标准化了 HTTP/2 ,这么快就需要 HTTP/3?
我们知道,HTTP/2 通过引入“流”的概念,实现了多路复用。简单来说,假设你访问某个网站需要请求 10 个资源,你使用 HTTP1.1 协议只能串行地发请求,资源 1 请求成功之后才能发送资源 2 的请求,以此类推,这个过程是非常耗时的。如果想 10 个请求并发,不需要串行等待的话,在 HTTP1.1 中,应用就需要为一个域名同时建立 10 个 TCP 连接才行(一般浏览器不允许建立这么多),这无疑是对资源的极大的浪费。HTTP/2 的多路复用解决了这一问题,能使多条请求并发。
但现实很残酷,为什么很多业务用了 HTTP/2,反倒不如 HTTP1.1 呢?
第一:多流并发带来了请求优先级的问题,因为有的请求客户端(比如浏览器)希望它能尽快返回,有的请求可以晚点返回;又或者有的请求需要依赖别的请求的资源来展示。流的优先级表示了这个请求被处理的优先级,比如客户端请求的关键的 CSS 和 JS 资源是必须高优先级返回的,图片视频等资源可以晚一点响应。流的优先级的设置是一个难以平衡或者难以做到公平合理的事情,如果设置稍微不恰当,就会导致有些请求很慢,这在用户看来,就是用了 HTTP/2 之后,怎么有的请求变慢了。
第二:HTTP/2 解决了 HTTP 协议层面的队头阻塞,但是 TCP 的队头阻塞仍然没有解决,所有的流都在一条 TCP 连接上,如果万一序号小的某个包丢了,那么 TCP 为了保证到达的有序性,必须等这个包到达后才能滑动窗口,即使后面的序号大的包已经到达了也不能被应用程序读取。这就导致了在多条流并发的时候,某条流的某个包丢了,序号在该包后面的其他流的数据都不能被应用程序读取。这种情况下如果换做 HTTP1.1,由于 HTTP1.1 是多条连接,某个连接上的请求丢包了,并不影响其他连接。所以在丢包比较严重的情况下,HTTP/2 整体效果大概率不如 HTTP1.1
事实上,我们并不是真的需要新的 HTTP 版本,而是需要对底层传输控制协议 (TCP) 进行升级。
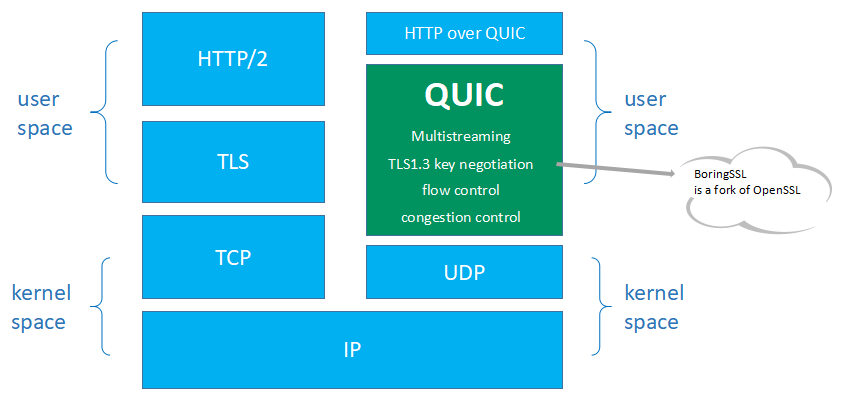
图 0-QUIC 协议栈
QUIC 协议实现在用户态,建立在内核态的 UDP 的基础之上,集成了 TCP 的可靠传输特性,集成了 TLS1.3 协议,保证了用户数据传输的安全。
数据的发送和接收,要想保证安全和可靠,一定是需要连接的。TCP 需要,QUIC 也同样需要。连接到底是什么?连接是一个通道,是在一个客户端和一个服务端之间的唯一一条可信的通道,主要是为了安全考虑,建立了连接,也就是建立了可信通道,服务器对这个客户端“很放心”,对于服务器来说:你想跟我进行通信,得先让我认识一下你,我得先确认一下你是好人,是有资格跟我通信的。那么这个确认对方身份的过程,就是建立连接的过程。
传统基于 TCP 的 HTTPS 的建连过程为什么如此慢?它需要 TCP 和 TLS 两个建连过程。如图 1 所示(传统 HTTPS 请求流程图):
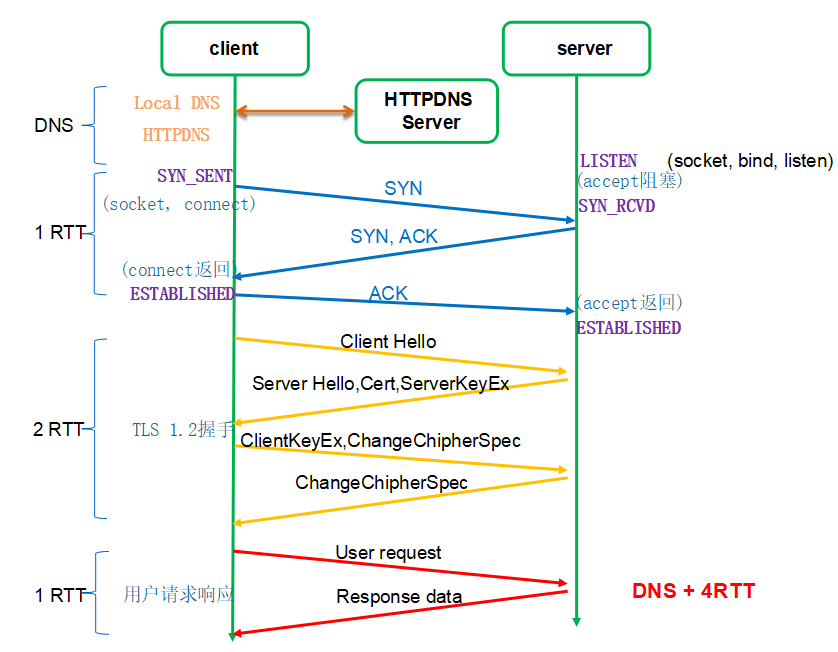
图 1- 传统 HTTPS 请求流程图
对于一个小请求(用户数据量较小)而言,传输数据只需要 1 个 RTT,但是光建连就花掉了 3 个 RTT,这是非常不划算的,这里建连包括两个过程:TCP 建连需要 1 个 RTT,TLS 建连需要 2 个 RTT。RTT:Round Trip Time,数据包在网络上一个来回的时间。
为什么需要两个过程?可恶就可恶在这个地方,TCP 和 TLS 没办法合并,因为 TCP 是在内核里完成的,TLS 是在用户态。也许有人会说把干掉内核里的 TCP,把 TCP 挪出来放到用户态,然后就可以和 TLS 一起处理了。首先,你干不掉内核里的 TCP,TCP 太古老了,全世界的服务器的 TCP 都固化在内核里了。所以,既然干不掉 TCP,那我不用它了,我再自创一个传输层协议,放到用户态,然后再结合 TLS,这样不就可以把两个建连过程合二为一了吗?是的,这就是 QUIC。
如图 2 所示,是 QUIC 的连接建立过程:初次建连只需要 1 个 RTT 即可完成建连。后续再次建连就可以使用 0-RTT 特性
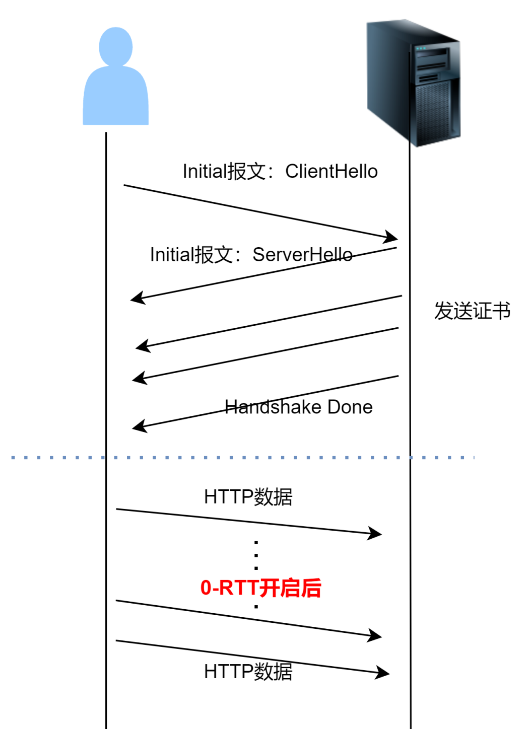
图 2-QUIC 建连过程图
QUIC 的 1-RTT 建连:客户端与服务端初次建连(之前从未进行通信过),或者长时间没有通信过(0-RTT 过期了),只能进行 1-RTT 建连。只有先进行一次完整的 1-RTT 建连,后续一段时间内的通信才可以进行 0-RTT 建连。
如图 3 所示:QUIC 的 1-RTT 建连可以分成两个部分。QUIC 连接信息部分和 TLS1.3 握手部分。
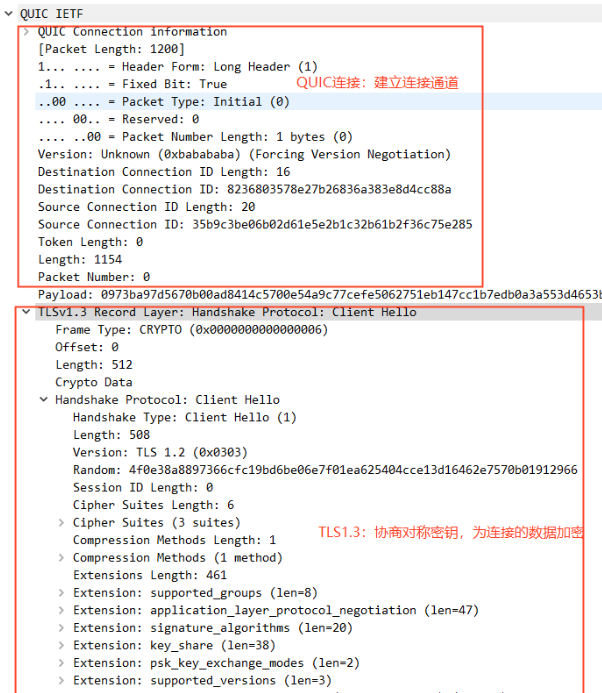
图 3-QUIC 建连抓包
QUIC 连接:协商 QUIC 版本号、协商 quic 传输参数、生成连接 ID、确定 Packet Number 等信息,类似于 TCP 的 SYN 报文;保证通信的两端确认过彼此,是对的人。
TLS1.3 握手:标准协议,非对称加密,目的是为了协商出 对称密钥,然后后续传输的数据使用这个对称密钥进行加密和解密,保护数据不被窃取。
我们重点看 QUIC 的 TLS1.3 握手过程。
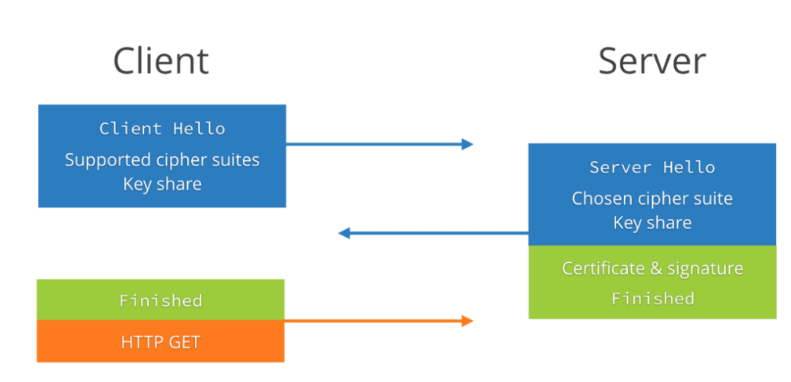
图 4-QUIC 的 1-RTT 握手流程
我们通过图 4 可以看到,整个握手过程需要 2 次握手(第三次握手是带了数据的),所以整个握手过程只需要 1-RTT(RTT 是指数据包在网络上的一个来回)的时间。
1-RTT 的握手主要包含两个过程:
客户端发送 Client Hello 给服务端;
服务端回复 Server Hello 给客户端;
我们通过下图中图 5 和图 6 来看 Client Hello 和 Server Hello 具体都做了啥:
第一次握手(Client Hello 报文)
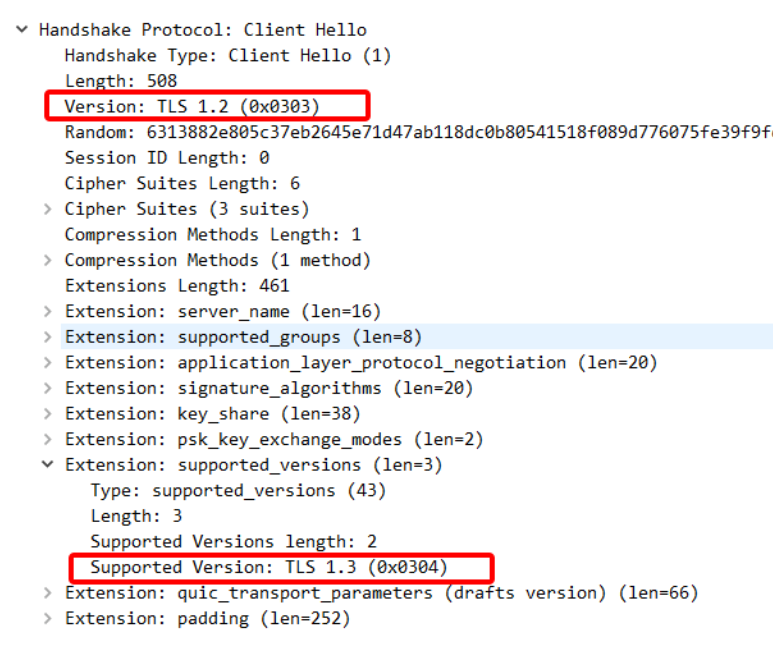
图 5-Client Hello 报文
首先,Client Hello 在扩展字段里标明了支持的 TLS 版本(Supported Version:TLS1.3)。值得注意的是 Version 字段必须要是 TLS1.2,这是因为 TLS1.2 已经在互联网上存在了 10 年。网络中大量的网络中间设备都十分老旧,这些网络设备会识别中间的 TLS 握手头部,所以 TLS1.3 的出现如果引入了未知的 TLS Version 必然会存在大量的握手失败。
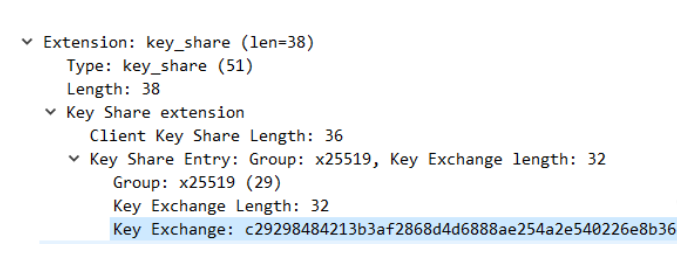
图 6-Client Hello 报文
其次,ClientHello 中包含了非常重要的 key_share 扩展:客户端在发送之前,会自己根据 DHE 算法生成一个公私钥对。发送 Client Hello 报文的时候会把这个公钥发过去,那么这个公钥就存在于 key_share 中,key_share 还包含了客户端所选择的曲线 X25519。总之,key_share 是客户端提前生成好的公钥信息。
最后,Client Hello 里还包括了:客户端支持的算法套、客户端所支持的椭圆曲线以及签名算法、psk 的模式等等,一起发给服务端。
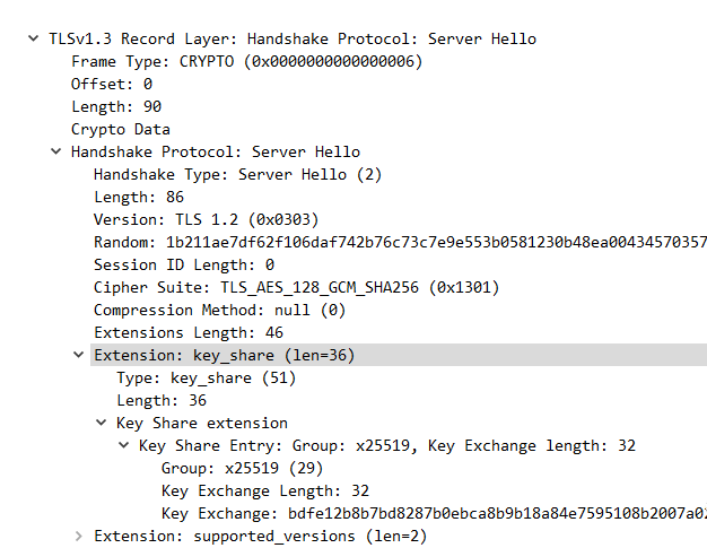
图 7-Client Hello 报文
第二次握手:(Server Hello 报文)

图 8-Server Hello 报文
服务端自己根据 DHE 算法也生成了一个公私钥对,同样的,Key_share 扩展信息中也包含了 服务端的公钥信息。服务端通过 ServerHello 报文将这些信息发送给客户端。
至此为止,双方(客户端服务端)都拿到了对方的公钥信息,然后结合自己的私钥信息,生成 pre-master key,在这里官方的叫法是(client_handshake_traffic_secret 和server_handshake_traffic_secret),然后根据以下算法进行算出 key 和 iv,使用 key 和 iv 对 Server Hello 之后所有的握手消息进行加密。
注意:在握手完成之后,服务端会发送一个 New Session Ticket 报文给客户端,这个包非常重要,这是 0-RTT 实现的基础。
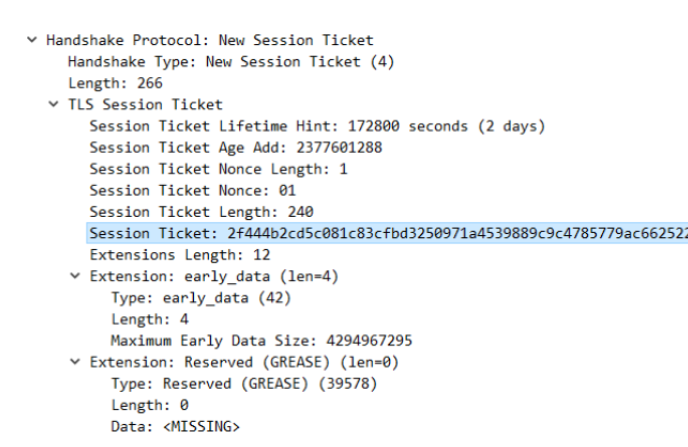
图 9-New Session Ticket 报文
这个功能类似于 TLS1.2 的会话复用,或者说 0-RTT 是基于会话复用功能的。
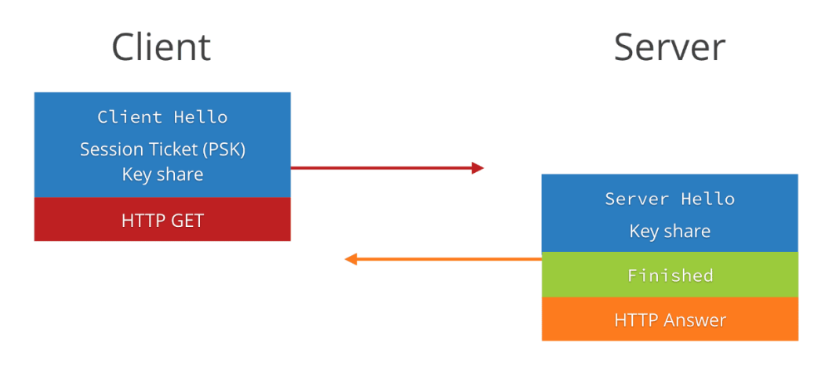
图 10- QUIC 的 0-RTT 流程图
通过上面图 10 我们可以看到,client 和 server 在建连时,仍然需要两次握手,仍然需要 1 个 rtt,但是为什么我们说这是 0-rtt 呢,是因为 client 在发送第一个包 client hello 时,就带上了数据(HTTP 请求),从什么时候开始发送数据这个角度上来看,的确是 0-RTT。
我们通过抓包来看 0-RTT 的过程:
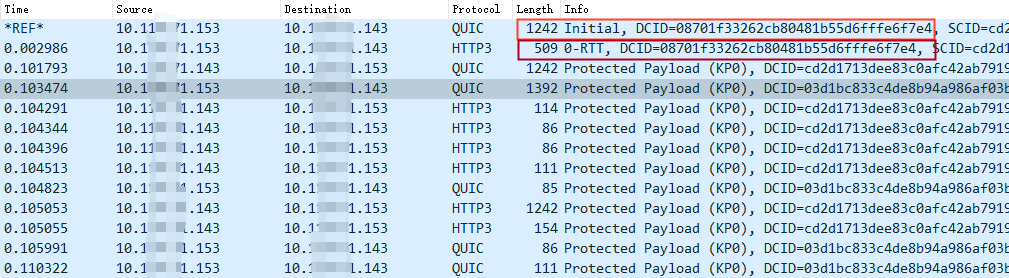
图 11- QUIC 的 0-RTT 抓包
所以真正在实现 0-RTT 的时候,请求的数据并不会跟 Initial 报文(内含 Client Hello)一起发送,而是单独一个数据包(0-RTT 包)进行发送,只不过是跟 Initial 包同时进行发送而已。
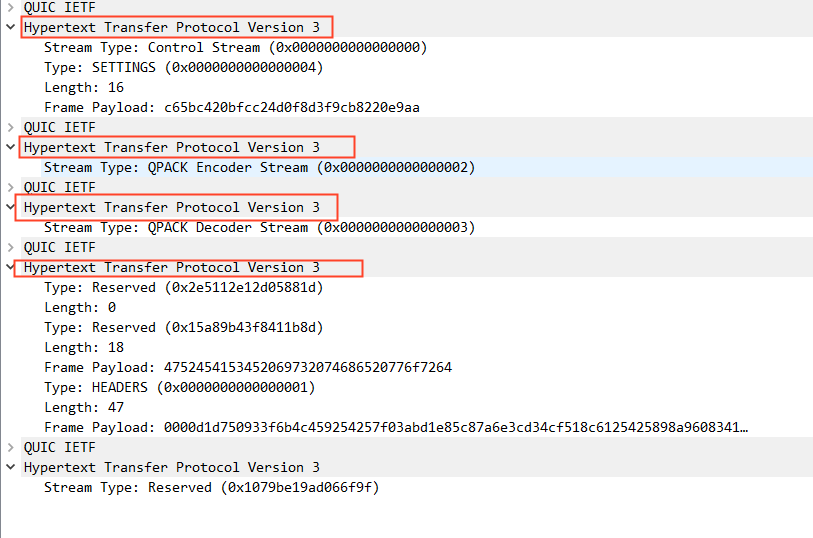
图 12- QUIC 的 0-RTT 包
我们单独看 Initial 报文发现,除了 pre_share_key、early-data 标识等信息与 1-RTT 时不同,其他并无区别。
第一,QUIC 实现的时候,必须缓存收到的乱序加密帧,这个缓存至少要大于 4096 字节。当然可以选择缓存更多的数据,更大的缓存上限意味着可以交换更大的密钥或证书。终端的缓存区大小不必在整个连接生命周期内保持不变。这里记住:乱序帧一定要缓存下来。如果不缓存,会导致连接失败。如果终端的缓存区不够用了,则其可以通过暂时扩大缓存空间确保握手完成。如果终端不扩大其缓存,则其必须以错误码 CRYPTO_BUFFER_EXCEEDED 关闭连接。
第二,0-RTT 存在前向安全问题,请慎用!
QUIC 通过连接 ID 实现了连接迁移。
我们经常需要在 WiFi 和 4G 之间进行切换,比如我们在家里时使用 WiFi,出门在路上,切换到 4G 或 5G,到了商场,又连上了商场的 WiFi,到了餐厅,又切换到了餐厅的 WiFi,所以我们的日常生活中需要经常性的切换网络,那每一次的切换网络,都将导致我们的 IP 地址发生变化。
传统的 TCP 协议是以四元组(源 IP 地址、源端口号、目的 ID 地址、目的端口号)来标识一条连接,那么一旦四元组的任何一个元素发生了改变,这条连接就会断掉,那么这条连接中正在传输的数据就会断掉,切换到新的网络后可能需要重新去建立连接,然后重新发送数据。这将会导致用户的网络会“卡”一下。
但是,QUIC 不再以四元组作为唯一标识,QUIC 使用连接 ID 来标识一条连接,无论你的网络如何切换,只要连接 ID 不变,那么这条连接就不会断,这就叫连接迁移!
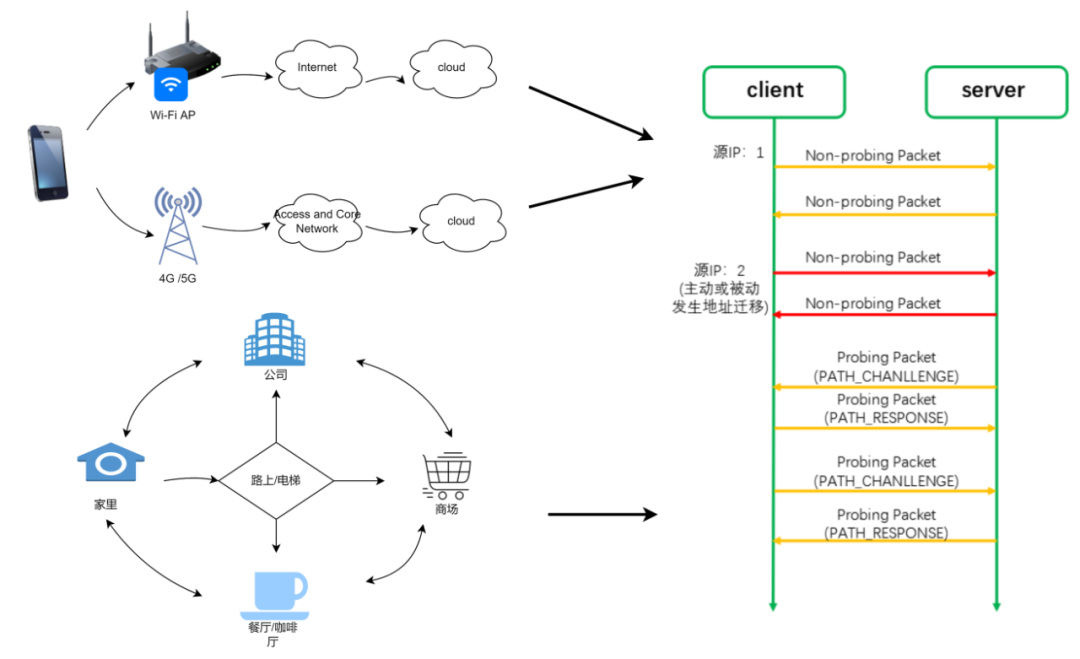
图 13-QUIC 连接迁移介绍
每条连接拥有一组连接标识符,也就是连接 ID,每个连接 ID 都能标识这条连接。连接 ID 是由一端独立选择的,每个端(客户端和服务端统称为端)选择连接 ID 供对端使用。也就是说,客户端生成的连接 ID 供服务端使用(服务端发送数据时使用客户端生成的连接 ID 作为目的连接 ID),反过来一样的。
连接 ID 的主要功能是确保底层协议(UDP、IP 及更底层的协议栈)发生地址变更(比如 IP 地址变了,或者端口号变了)时不会导致一个 QUIC 连接的数据包被传输到错误的 QUIC 终端(客户端和服务端统称为终端)上。
QUIC 限制连接迁移为仅客户端可以发起,客户端负责发起所有迁移。如果客户端接收到了一个未知的服务器发来的数据包,那么客户端必须丢弃这些数据包。
如图 14 所示,连接迁移过程总共需要四个步骤。
连接迁移之前,客户端使用 IP1 和服务端进行通信;
客户端 IP 变成 IP2,并且使用 IP2 发送非探测帧给服务端;
启动路径验证(双方都需要互相验证),通过 PATH_CHANLLENGE 帧和 PATH_RESPONSE 帧进行验证。
验证通过后,使用 IP2 进行通信。
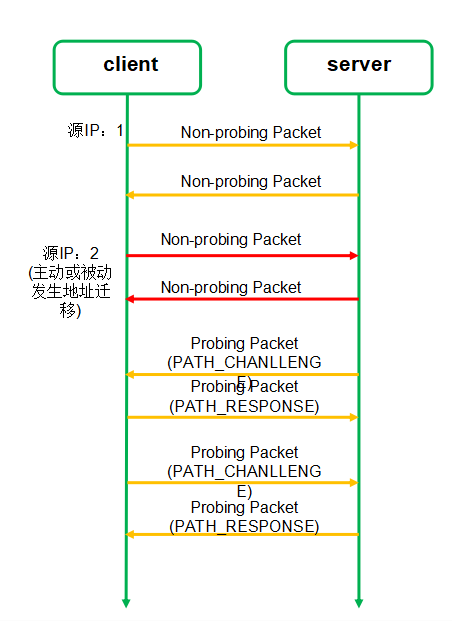
图 14- 连接迁移流程图
在 HTTP/2 中引入了流的概念。目的是实现 多个请求在同一个连接上并发,从而提升网页加载的效率。
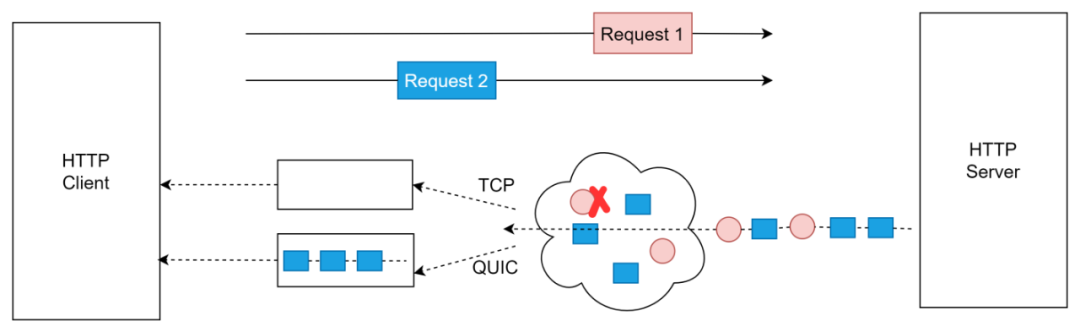
图 15-QUIC 解决 TCP 队头阻塞问题
由图 15 来看,假设有两个请求同时发送,红色的是请求 1,蓝色的是请求 2,这两个请求在两条不同的流中进行传输。假设在传输过程中,请求 1 的某个数据包丢了,如果是 TCP,即使请求 2 的所有数据包都收到了,但是也只能阻塞在内核缓冲区中,无法交给应用层。但是 QUIC 就不一样了,请求 1 的数据包丢了只会阻塞请求 1,请求 2 不会受到阻塞。
有些人不禁发问,不是说 HTTP2 也有流的概念吗,为什么只有 QUIC 才能解决呢,这个根本原因就在于,HTTP2 的传输层用的 TCP,TCP 的实现是在内核态的,而流是实现在用户态度,TCP 是看不到“流”的,所以在 TCP 中,它不知道这个数据包是请求 1 还是请求 2 的,只会根据 seq number 来判断包的先后顺序。
拥塞控制算法中最重要的一个参数是 RTT,RTT 的准确性决定了拥塞控制算法的准确性;然而,TCP 的 RTT 测量往往不准确,QUIC 的 RTT 测量是准确的。

图 16-TCP 计算 RTT
如图 16 所示:由于网络中经常出现丢包,需要重传,在 TCP 协议中,初始包和重传包的序号是一样的,拥塞控制算法进行计算 RTT 的时候,无法区别是初始包还是重传包,这将导致 RTT 的计算值要么偏大,要么偏小。

图 17-QUIC 计算 RTT
如图 17 所示:QUIC 通过 Packet Number 来标识包的序号,而且规定 Packet Number 只能单调递增,这也就解决了初始包和重传包的二义性。从而保证 RTT 的值是准确的。
另外,不同于 TCP,QUIC 的拥塞控制算法是可插拔的,由于其实现在用户态,服务可以根据不同的业务,甚至不同的连接灵活选择使用不同的拥塞控制算法。(Reno、New Reno、Cubic、BBR 等算法都有自己适合的场景)
很多人搞不清楚流量控制与拥塞控制的区别。二者有本质上的区别。
流量控制要解决的问题是:接收方控制发送方的数据发送的速度,就是我的接收能力就那么大点,你别发太快了,你发太快了我承受不住,会给你丢掉 你还得重新发。
拥塞控制要解决的问题是:数据在网络的传输过程中,是否网络有拥塞,是否有丢包,是否有乱序等问题。如果中间传输的时候网络特别卡,数据包丢在中间了,发送方就需要重传,那么怎么判断是否拥塞了,重传要怎么重传法,按照什么算法进行发送数据才能尽可能避免数据包在中间路径丢掉,这是拥塞控制的核心。
所以,流量控制解决的是接收方的接收能力问题,一般采用滑动窗口算法;拥塞控制要解决的是中间传输的时候网络是否拥堵的问题,一般采用慢启动、拥塞避免、拥塞恢复、快速重传等算法。
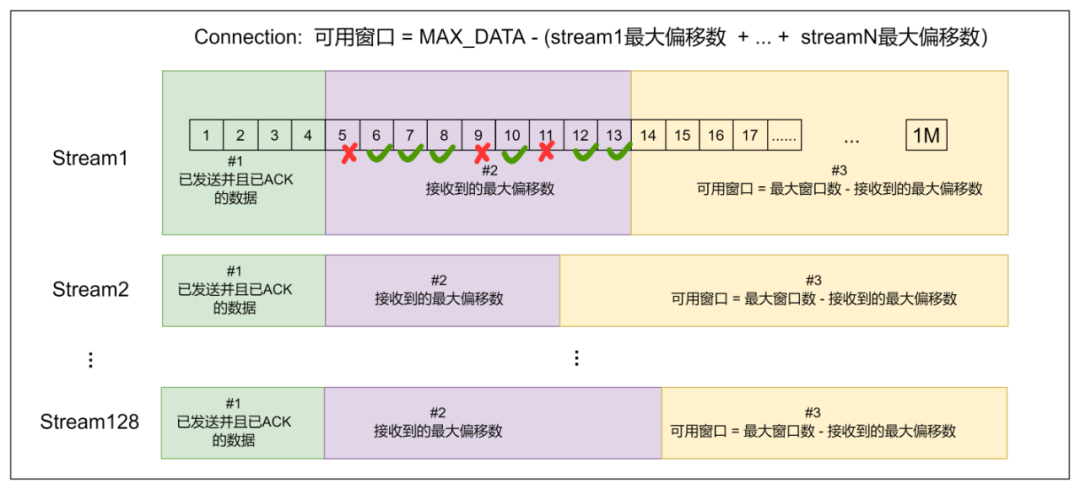
图 18-QUIC 流量控制
QUIC 是双级流控,不仅有连接这一个级别的流控,还有流这个级别的流控。如下图所示,每个流都有自己的可用窗口,可用窗口的大小取决于最大窗口数减去发送出去的最大偏移数,跟中间已经发送出去的数据包,是否按顺序收到了对端的 ACK 无关。
QUIC 协议定义了很多优秀的功能,但是在实现的过程中,我们会遇到很多问题导致无法达到预期的性能,比如 0-RTT 率很低,连接迁移失败率很高等等。
导致 0-RTT 成功率不高的原因一般有如下几个:
1. 服务端一般都是集群,对于客户端来说,处理请求的服务端是不固定的,新的请求到来时,如果当前 client 没有请求过该服务器,则服务器上没有相关会话信息,会把该请求当做一个新的连接来处理,重新走 1-RTT。
针对此种情况,我们可以考虑集群中所有的服务器使用相同的 ticket 文件。
2. 客户端 IP 不是固定的,在发生连接迁移时,服务端下发的 token 融合了客户端的 IP,这个 IP 变化了的话,携带 token 服务端校验不过,0-RTT 会失败。
针对这个问题,我们可以考虑采用如图 19 所示的方法,使用设备信息或者 APP 信息来生成 token,唯一标识一个客户端。
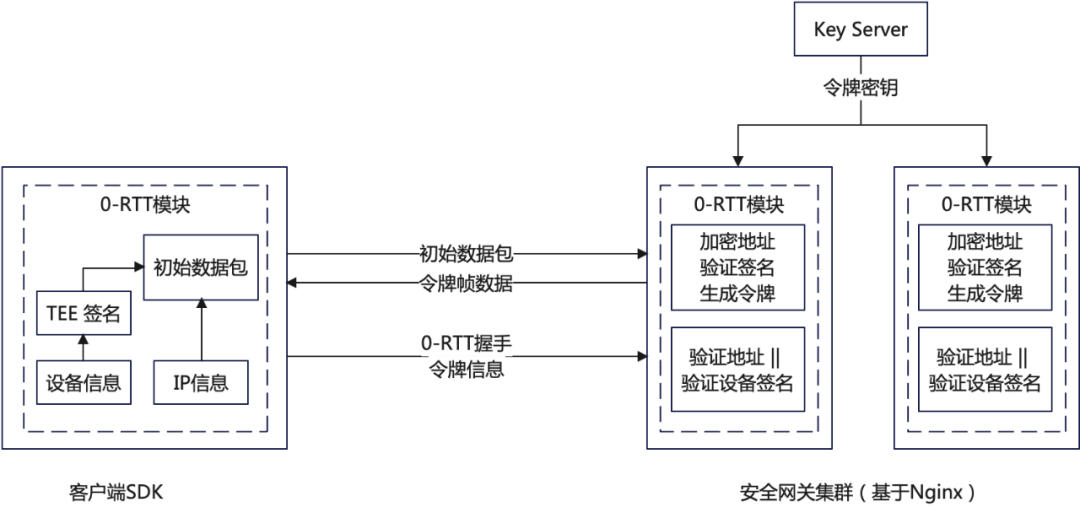
图 19- 使用设备信息提高 0-RTT 的成功率
3. Session Ticket 过期时间默认是 2 天,超过 2 天后就会导致 0-RTT 失败,然后降级走 1-RTT。可以考虑增长过期时间。
连接迁移的实现,不可避开的两个问题:一个是四层负载均衡器对连接迁移的影响,一个是七层负载均衡器对连接迁移的影响。
四层负载均衡器的影响:LVS、DPVS 等四层负载均衡工具基于四元组进行转发,当连接迁移发生时,四元组会发生变化,该组件就会把同一个请求的数据包发送到不同的后端服务器上,导致连接迁移失败;
七层负载均衡器的影响(QUIC 服务器多核的影响):由于多核的影响,一般服务器会有多个 QUIC 服务端进程,每个进程负载处理不同的连接。内核收到数据包后,会根据二元组(源 IP、源 port)选择已经存在的连接,并把数据包交给对应的 socket。在连接迁移发生时,源地址发生改变,可能会让接下来的数据包去到不同的进程,影响 socket 数据的接收。
如何解决以上两个问题?DPVS 要想支持 QUIC 的连接迁移,就不能再以四元组进行转发,需要以连接 ID 进行转发,需要建立 连接 ID 与对应的后端服务器的对应关系;
QUIC 服务器也是一样的,内核就不能用四元组来进行查找 socket,四元组查找不到时,就必须使用连接 ID 进行查找 socket。但是内核代码又不能去修改(不可能去更新所有服务器的内核版本),那么我们可以使用 eBPF 的方法进行解决。如下图 20 所示:
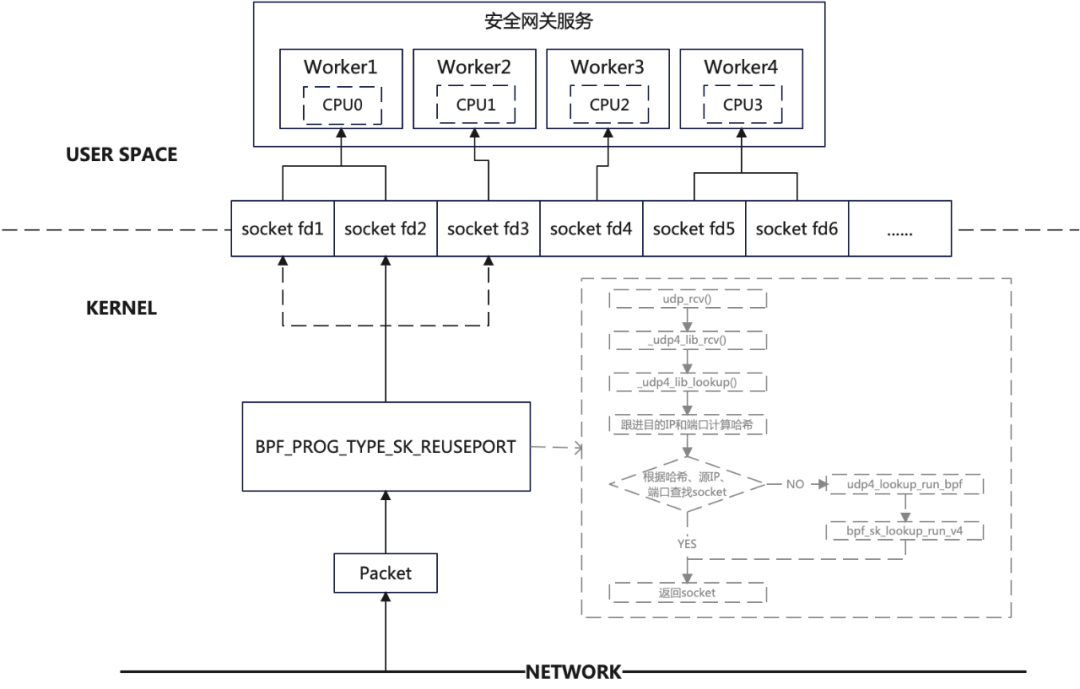
图 20- 多核 QUIC 服务器解决连接迁移问题
业内统计数据全球有 7% 地区的运营商对 UDP 有限速或者禁闭,除了运营商还有很多企业、公共场合也会限制 UDP 流量甚至禁用 UDP。这对使用 UDP 来承载 QUIC 协议的场景会带来致命的伤害。对此,我们可以采用多路竞速的方式使用 TCP 和 QUIC 同时建连。除了在建连进行竞速以外,还可以对网络 QUIC 和 TCP 的传输延时进行实时监控和对比,如果有链路对 UDP 进行了限速,可以动态从 QUIC 切换到 TCP。
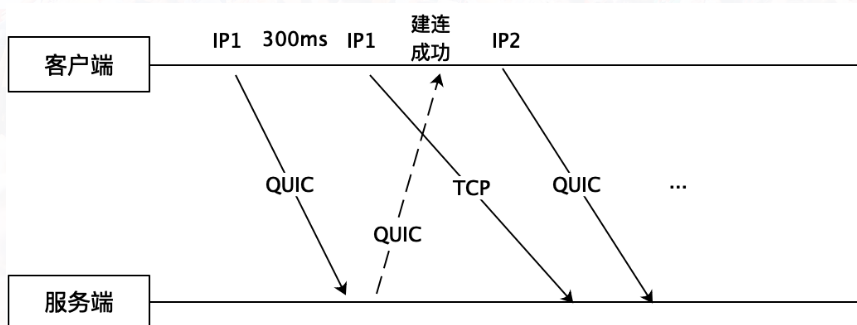
图 21-QUIC 和 TCP 协议竞速
相对于 TCP,为什么 QUIC 更消耗资源?
QUIC 在用户态实现,需要更多的内核空间与用户空间的数据拷贝和上下文切换;
QUIC 的 ACK 报文也是加密的,TCP 是明文的。
内核知道 TCP 连接的状态,不用为每一个数据包去做诸如查找目的路由、防火墙规则等操作,只需要在 tcp 连接建立的时候做一次即可,然而 QUIC 不行;
总的来说,QUIC 服务端消耗 CPU 的地方主要有三个:密码算法的开销;udp 收发包的开销;协议栈的开销;
针对这些,我们可以适当采取优化措施来:
使用 Intel 硬件加速卡卸载 TLS 握手
开启 GSO 功能。
数据在传输过程中,可以将一轮中所有的 ACK 解析后再同时进行处理,避免处理大量的 ACK。
适当将 QUIC 的包长限制调高(比如从默认的 1200 调到 1400 个字节)
减少协议栈的内存拷贝
从公开的数据来看,国内各个厂(腾讯、阿里、字节、华为、OPPO、网易等等)使用了 QUIC 协议后,都有很大的提升,比如网易上了 QUIC 后,响应速度提升 45%,请求错误率降低 50%;比如字节火山引擎使用 QUIC 后,建连耗时降低 20%~30%;比如腾讯使用 QUIC 后,在腾讯会议、直播、游戏等场景耗时也降低 30%;
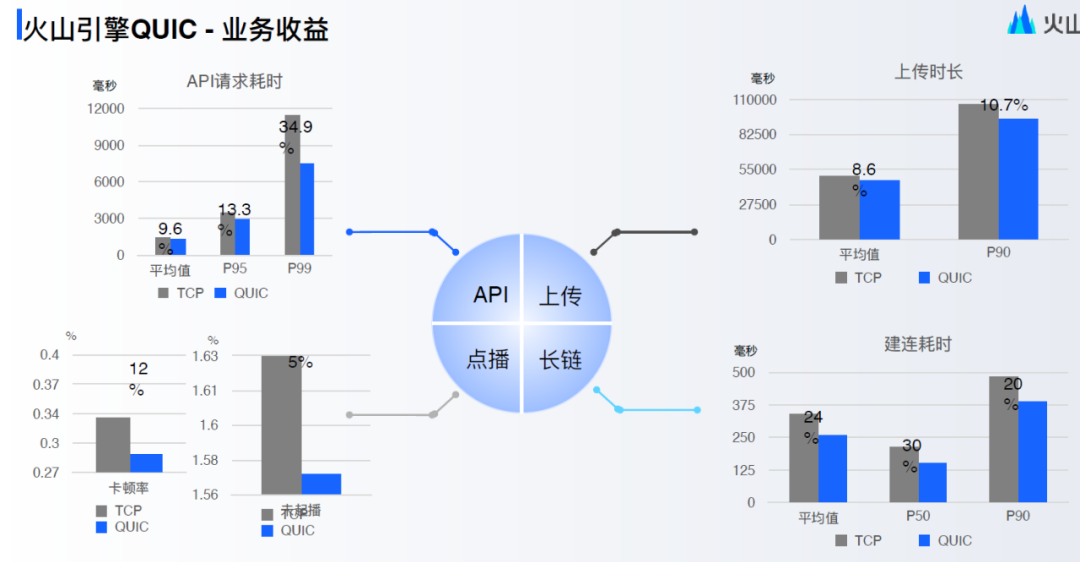
图 22- 字节火山引擎 QUIC 业务收益
QUIC 协议的出现,为 HTTP/3 奠定了基础。这是近些年在 web 协议上最大的变革,也是最优秀的一次实践。面对新的协议,我们总是有着各种各样的担忧,诚然,QUIC 协议在稳定性上在成熟度上,的确还不如 TCP 协议,但是经过近几年的发展,成熟度已经相当不错了,Nginx 近期也发布了 1.25.0 版本,支持了 QUIC 协议。所以面对这样优秀的协议,我们希望更多的公司,更多的业务参与进来使用 QUIC,推动 QUIC 更好的发展,推动用户上网速度更快!