
一文读懂 | Cache的原理
1、为什么需要 Cache
1.1 为什么需要 Cache
我们首先从一张图来开始讲为什么需要 Cache.
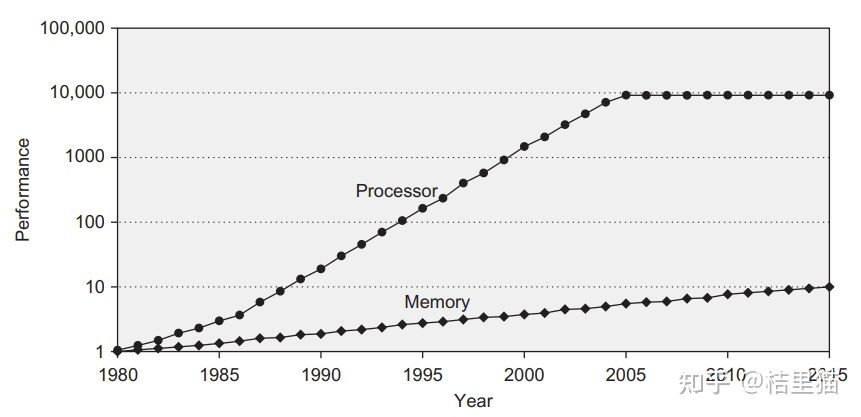
上图是 CPU 性能和 Memory 存储器访问性能的发展。
我们可以看到,随着工艺和设计的演进,CPU 计算性能其实发生了翻天覆地的变化,但是DRAM存储性能的发展没有那么快。
所以造成了一个问题,存储限制了计算的发展。
容量与速度不可兼得。
如何解决这个问题呢?可以从计算访问数据的规律入手。
我们随便贴段代码:
for (j = 0; j < 100; j = j + 1)
for( i = 0; i < 5000; i = i + 1)
x[i][j] = 2 * x[i][j];可以看到,由于大量循环的存在,我们访问的数据其实在内存中的位置是相近的。
换句专业点的话说,我们访问的数据有局部性。
我们只需要将这些数据放入一个小而快的存储中,这样就可以快速访问相关数据了。
总结起来,Cache是为了给CPU提供高速存储访问,利用数据局部性而设计的小存储单元。
1.2 实际系统中的 Cache
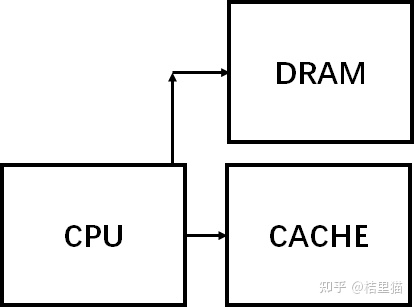
我们展示一下实际系统中的 Cache 。
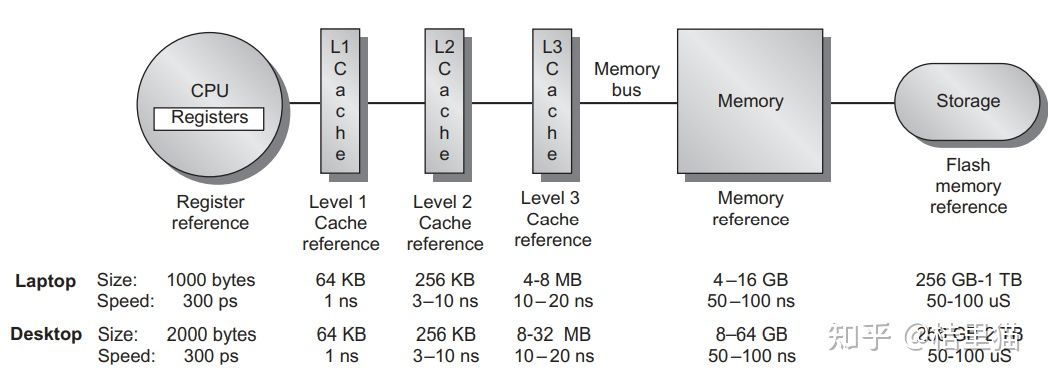
如上图所示,整个系统的存储架构包括了 CPU 的寄存器,L1/L2/L3 CACHE,DRAM 和硬盘。
数据访问时先找寄存器,寄存器里没有找 L1 Cache, L1 Cache 里没有找 L2 Cache 依次类推,最后找到硬盘中。
同时,我们可以看到,速度与存储容量的折衷关系。容量越小,访问速度越快!
其中,一个概念需要搞清楚。
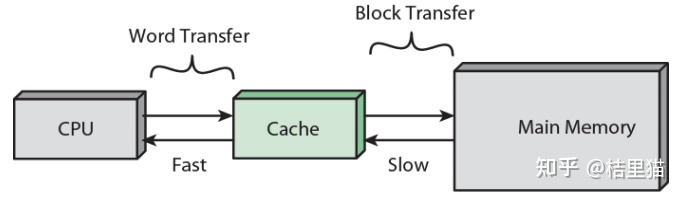
CPU 和 Cache 是 word 传输的,而 Cache 到主存是以块传输的,一块大约 64Byte 。
现有 SOC 中的 Cache 一般组成如下。
1.3 Cache 的分类
Cache按照不同标准分类可以分为若干类。
按照数据类型划分:I-Cache与D-Cache。其中I-Cache负责放置指令,D-Cache负责方式数据。两者最大的不同是D-Cache里的数据可以写回,I-Cache是只读的。
按照大小划分:分为small Cache和large Cache。没路组(后文组相连介绍)<4KB叫small Cache, 多用于L1 Cache, 大于4KB叫large Cache。多用于L2及其他Cache.
按照位置划分:Inner Cache和Outer Cache。一般独属于CPU微架构的叫Inner Cache, 例如上图的L1 L2 CACHE。不属于CPU微架构的叫outer Cache.
按照数据关系划分:Inclusive/exclusive Cache: 下级Cache包含上级的数据叫inclusive Cache。不包含叫exclusive Cache。举个例子,L3 Cache里有L2 Cache的数据,则L2 Cache叫exclusive Cache。
2、Cache的工作原理
要讲清楚 Cache 的工作原理,需要回答 4 个问题:
数据如何放置
数据如何查询
数据如何被替换
如果发生了写操作,Cache如何处理
2.1 数据如何放置
这个问题也好解决。我们举个简单的栗子来说明问题。
假设我们主存中有 32 个块,而我们的 Cache 一共有 8 个 Cache 行( 一个 Cache 行放一行数据)。
假设我们要把主存中的块 12 放到 Cache 里。
那么应该放到 Cache 里什么位置呢?
三种方法:
全相连(Fully associative)。可以放在Cache的任何位置。
直接映射(Direct mapped)。只允许放在Cache的某一行。比如12 mod 8
组相连(set associative)。可以放在Cache的某几行。例如2路组相连,一共有4组,所以可以放在0,1位置中的一个。
可以看到,全相连和直接映射是Cache组相连的两种极端情况。
不同的放置方式主要影响有两点:
1、组相连组数越大,比较电路就越大,但Cache利用率更高,Cache miss发生的概率小。2、组相连数目变小,Cache经常发生替换,但是比较电路比较小。
这也好理解,内存中的块在Cache中可放置的位置多,自然找起来就麻烦。
2.2 如何在Cache中找数据
其实找数据就是一个比对过程,如下图所示。

我们地址都以 Byte 为单位的。
但主存于Cache之间的数据交换单位都是块(block,现代Cache一般一个block大约64Byte)。所以地址对最后几位是block offset。
由于我们采用了组相连,则还有几个比特代表的是存储到了哪个组。
组内放着若干数据,我们需要比较Tag, 如果组内有Tag出现,则说明我们访问的数据在缓存中,可以开心的使用了。
比如举个 2 路组相连的例子,如下图所示。
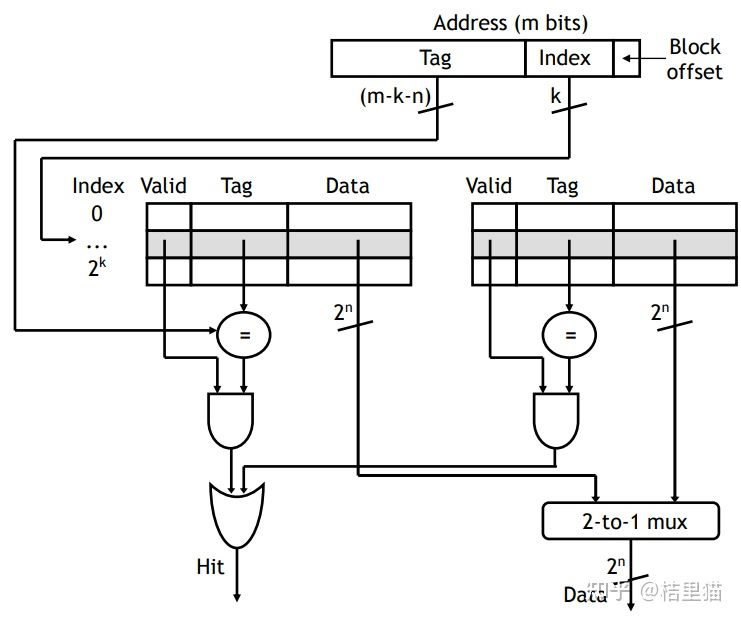
T表示Tag。直接比较Tag,就能得知是不是命中了。如果命中了,则根据index(组号)将对应的块取出来即可。
如上图所示。用index选出位于组相连的哪个组。然后并行的比较Tag, 判断最后是不是在Cache中。上图是2路组相连,也就是说两组并行比较。
那如果不在缓存中呢?这就涉及到另一个问题。
不在缓存中如何替换 Cache ?
2.3 如何替换Cache中的数据
Cache中的数据如何被替换的?这个就比较简单直接。
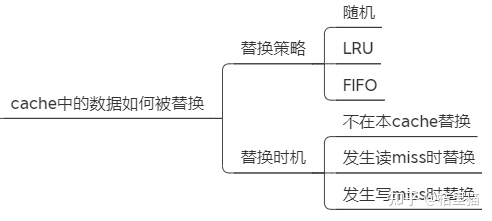
随机替换。如果发生Cache miss里随机替换掉一块。
Least recently used. LRU。最近使用的块最后替换。
First in, first out (FIFO), 先进先出。
实际上第一个不怎么使用,LRU 和 FIFO 根据实际情况选择即可。
Cache 在什么时候数据会被替换内?也有几种策略。
不在本 Cache 替换。如果Cache miss了,直接转发访问地址到主存,取到的数据不会写到Cache.
在读MISS时替换。如果读的时候Cache里没有该数据,则从主存读取该数据后写入Cache。
在写MISS时替换。如果写的时候Cache里没有该数据,则将本数据调入Cache再写。
2.4 如果发生了写操作怎么办
Cache毕竟是个临时缓存。
如果发生了写操作,会造成Cache和主存中的数据不一致。如何保证写数据操作正确呢?
也有三种策略。
通写:直接把数据写回Cache的同时写回主存。极其影响写速度。
回写:先把数据写回Cache, 然后当Cache的数据被替换时再写回主存。

通写队列:通写与回写的结合。先写回一个队列,然后慢慢往主存储写。如果多次写同一个数据,直接写这个队列。避免频繁写主存。
3、Cache一致性
Cache 一致性是 Cache 中遇到的比较坑的一个问题。
什么原因需要 Cache 处理一致性呢?
主要是多核系统中,假如core 0读了主存储的数据,写了数据。core 1也读了主从的数据。这个时候core 1并不知道数据已经被改动了,也就是说,core 1 Cache中的数据过时了,会产生错误。
Cache一致性的保证就是让多核访问不出错。

Cache一致性主要有两种策略。
策略一:基于监听的一致性策略
这种策略是所有Cache均监听各Cache的写操作,如果一个Cache中的数据被写了,有两种处理办法。
写更新协议:某个Cache发生写了,就索性把所有Cache都给更新了。
写失效协议:某个Cache发生写了,就把其他Cache中的该数据块置为无效。
策略 1 由于监听起来成本比较大,所以只应用于极简单的系统中。
策略二:基于目录的一致性策略
这种策略是在主存处维护一张表。记录各数据块都被写到了哪些Cache, 从而更新相应的状态。一般来讲这种策略采用的比较多。又分为下面几个常用的策略。
SI: 对于一个数据块来讲,有share和invalid两种状态。如果是share状态,直接通知其他Cache, 将对应的块置为无效。
MSI:对于一个数据块来讲,有share和invalid,modified三种状态。其中modified状态表表示该数据只属于这个Cache, 被修改过了。当这个数据被逐出Cache时更新主存。这么做的好处是避免了大量的主从写入。同时,如果是invalid时写该数据,就要保证其他所有Cache里该数据的标志位不为M,负责要先写回主存储。
MESI:对于一个数据来讲,有4个状态。modified, invalid, shared, exclusive。其中exclusive状态用于标识该数据与其他Cache不依赖。要写的时候直接将该Cache状态改成M即可。
我们着重讲讲 MESI。图中黑线:CPU的访问。红线:总线的访问,其他Cache的访问。
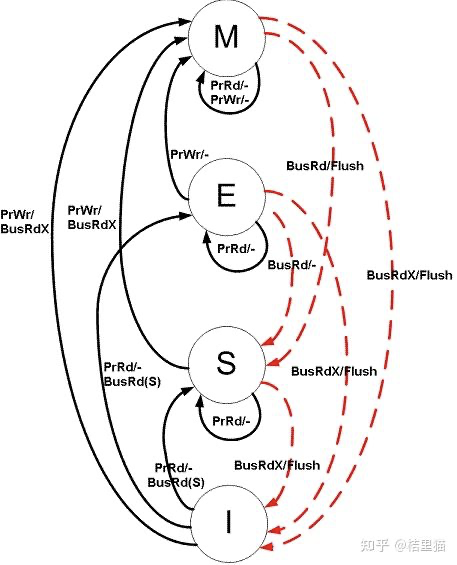
当前状态时I状态时,如果发生处理器读操作 prrd。
如果其他Cache里有这份数据,如果其他Cache里是M态,先 把M态写回主存再读。否则直接读。最终状态变为S。
其他Cache里没这个数据,直接变到E状态。
当前状态为S态。
如果发生了处理器读操作,仍然在S态。
如果发生了处理器写操作,则跳转到M状态。
如果其他Cache发生了写操作,跳到I态。
当前状态E态
发生了处理器读操作还是E。
发生了处理器写操作变成M。
如果其他Cache发生了读操作,变到S状态。
当前状态M态
发生了读操作依旧是M态。
发生了写操作依旧是M态。
如果其他Cache发生了读操作,则将数据写回主存储,变换到S态。
4、总结
Cache 在计算机体系架构中有非常重要的地位,本文讲了 Cache中最主要的内容,具体细节可以再根据某个点深入研究。
来源:https://zhuanlan.zhihu.com/p/386919471