
信用卡申请预测案例
信用卡业务,是各大银行的核心业务之一。银行收到大量信用卡申请,其中许多人因为各种原因而被拒绝,比如高的个人信用贷款余额,低的收入水平或者过高的个人征信报告查询次数等。
银行工作人员手动调研和分析这些个人申请资料很普遍,但是,容易出错,而且也很耗时(时间就是金钱,效率就是生命)。幸运的是,这项任务可以通过机器学习实现自动化,在风险可控的前提下,极大地提升了工作的效率和产能。
在本案例中,将使用机器学习技术构建一个自动信用卡申请预测模型,并利用模型去判断那些人信用卡申请可以批准,就像真正银行做的那样。
学习和实践本案例,你可以得到:
信用卡申请是个什么问题?
数据集如何整理?
模型如何构建?
模型如何应用?
一、业务理解,
问题定义
面对大量的信用卡申请资料,如何根据这些资料的信息和关联的其它信息,高效地对信用卡申请做出是否批准的判断,并兼顾产能和风险的平衡,即在风控原则约束的前提下,提升效能。
二、数据理解,
数据画像
本案例的数据集来自UCI平台提供的一份公开信用卡申请数据集。数据集的下载和数据集结构以及元数据(数据的数据)描述请访问如下链接:
http://archive.ics.uci.edu/ml/datasets/credit+approval
因为数据集涉及到个人敏感信息,所以数据集的贡献者对特征名做了匿名化处理以实现数据保密。数据集的结构,可以在后面的代码里了解。
1、导入Python库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
2、数据画像
cc_apps = pd.read_csv("datasets/cc_approvals.data", header=None)
print(cc_apps.shape)
print(cc_apps.head())
print(cc_apps.dtypes)
print(cc_apps.describe().T)
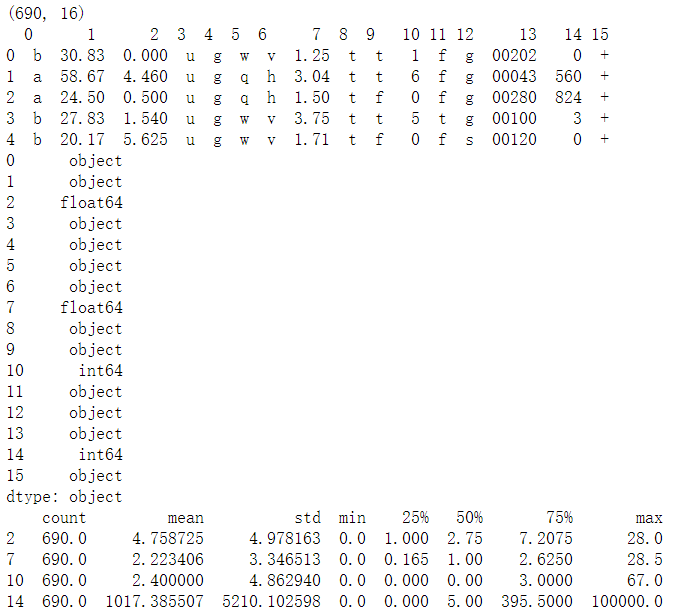
数据集包括690个观察,16个特征,特征集都做了匿名化处理。这里有篇博客(详见参考资料)对数据集的特征含义做了可能性的描述,依次是性别、年龄、债务、婚姻、银行客户、教育层次、种族、工作年限、先前违约、职业、信用评分、驾驶证、公民、邮政编码、收入和申请状态。通过数据画像的结果,可以发现数据集包括数值型和非数值型特征,这个问题我们在数据准备阶段会做相应处理。
三、数据准备,
数据整理
数据集包括数值型和非数值型特征,数据集跨度范围不一致,数据集包括一些用?符号表示数据缺失的情况。这些问题,我们都要解决。
首先,做缺失值的检测和处理。为什么要做这个事情?一方面,可以提升模型的性能,通常情况不建议直接粗暴地删除含有缺失值的变量或者样本,因为这样容易丢失信息;另一方面,有很多算法,不支持数据的缺失的情况。如何处理缺失值。本案例中,数值型变量采用均值插补法;非数值型变量采用众数插补法。
3、数据缺失值标记,发现和处理
cc_apps = cc_apps.replace("?",np.NaN)
cc_apps = cc_apps.fillna(cc_apps.mean())
print(cc_apps.info())
for col in cc_apps.columns:
if cc_apps[col].dtypes == 'object':
cc_apps[col] = cc_apps[col].fillna(cc_apps[col].value_counts().index[0])
print(cc_apps.isnull().values.sum())

4、非数值型特征处理--标签编码
接下来,做非数值型特征处理。为什么要对非数值型特征做处理和转换?一方面,可以提升计算的速度;另一方面,则是很多算法必须要要求数据集为数值型格式,比方说xgboost算法。如何做非数值型特征处理?本案例,采用标签编码的方法。
le = LabelEncoder()
for col in cc_apps.columns:
if cc_apps[col].dtype=='object':
cc_apps[col]=le.fit_transform(cc_apps[col])
5、特征筛选和缩放
第三,做特征筛选和缩放。根据特征的含义和所要解决问题,基于领域知识删除不需要特征,例如驾驶证和邮政编码,同时,把特征缩放到一致范围。
# 删除不需要的变量
# 同时对特征做缩放处理
cc_apps = cc_apps.drop([cc_apps.columns[10],cc_apps.columns[13]], axis=1)
cc_apps = cc_apps.values
X,y = cc_apps[:,0:13], cc_apps[:,13]
scaler = MinMaxScaler(feature_range=(0,1))
rescaledX = scaler.fit_transform(X)四、模型架构,
模型创建
把数据集整理好后,接下来我们做模型创建的事情,首先,把数据集划分为训练集和测试集,然后利用训练集来构建模型,利用测试集来评价模型的性能。因为本案例的问题是一个典型的二元分类问题,我们假设数据集里面特征与目标变量有一定的关系,我们选择简单常用和可解释的逻辑回归模型来创建模型。
6、数据集划分
X_train, X_test, y_train, y_test = train_test_split(rescaledX,
y,
test_size=0.33,
random_state=42)
6、模型创建
# 模型创建
logreg = LogisticRegression()
logreg.fit(X_train,y_train)
五、模型评价,
性能分析
把创建好的模型,在测试数据集上做模型的性能分析。我们采用模型的准确率和混淆矩阵来评价模型的性能。
y_pred = logreg.predict(X_test)
print("模型的准确率: %.3f" % logreg.score(X_test, y_test))
# 混淆矩阵
confusion_matrix(y_test, y_pred)

六、模型应用,
指导行动
针对新的的数据集,按着模型构建前的数据加工逻辑(缺失值处理+标签编码+数据缩放),做好数据处理后,然后利用构建好的模型对新数据集做预测,对预测的结果做应用,以指导信用卡申请的审批工作。
总结
本案例对信用卡申请是否批准的问题,利用机器学习的方法做了解答,以实现从人工审批过度到自动化审批的操作流程,从而提升审批的效率和客观一致性。
本案例还有很多地方值得进一步深入思考和挖掘。比方说,文章的标准化是对所有数据集进行处理,这样是否存在信息泄露问题,有待进一步验证;逻辑回归模型的超参数使用了默认值的设定,根据实际问题,是否存有最佳的超参数,也需要做相关的测试工作;模型预测的输出结果是一个介于0~1的值,然后根据临界点做比较来标记是否批准,而银行的实际应用中,需要把这种概率映射为一种分数,利用这种分数来更好地指导业务的行动等。
关于本案例,你有什么见解或者疑问,请留言或者加入Python群做讨论。
附录:案例完整代码(需要数据集的朋友可以添加我的个人微信获取或者从Kaggle平台下载获取)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
cc_apps = pd.read_csv("datasets/cc_approvals.data", header=None)
print(cc_apps.shape)
print(cc_apps.head())
print(cc_apps.dtypes)
print(cc_apps.describe().T)
cc_apps = cc_apps.replace("?",np.NaN)
cc_apps = cc_apps.fillna(cc_apps.mean())
print(cc_apps.info())
for col in cc_apps.columns:
if cc_apps[col].dtypes == 'object':
cc_apps[col] = cc_apps[col].fillna(cc_apps[col].value_counts().index[0])
print(cc_apps.isnull().values.sum())
le = LabelEncoder()
for col in cc_apps.columns:
if cc_apps[col].dtype=='object':
cc_apps[col]=le.fit_transform(cc_apps[col])
cc_apps = cc_apps.drop([cc_apps.columns[10],cc_apps.columns[13]], axis=1)
cc_apps = cc_apps.values
X,y = cc_apps[:,0:13], cc_apps[:,13]
scaler = MinMaxScaler(feature_range=(0,1))
rescaledX = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(rescaledX,
y,
test_size=0.33,
random_state=42)
# 模型创建
logreg = LogisticRegression()
logreg.fit(X_train,y_train)
y_pred = logreg.predict(X_test)
print("模型的准确率: %.3f" % logreg.score(X_test, y_test))
# 混淆矩阵
confusion_matrix(y_test, y_pred)
参考资料
1、案例的数据集的结构描述
http://rstudio-pubs-static.s3.amazonaws.com/73039_9946de135c0a49daa7a0a9eda4a67a72.html
2、LabelEncoder和OneHotEncoder
https://blog.csdn.net/quintind/article/details/79850455
3、逻辑回归算法
https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html
4、混淆矩阵
https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/
5、如何处理缺失值
https://machinelearningmastery.com/handle-missing-data-python/
公众号推荐
数据思践
数据思践公众号记录和分享数据人思考和践行的内容与故事。
Python语言群
诚邀您加入
《数据科学与人工智能》公众号推荐朋友们学习和使用Python语言,需要加入Python语言群的,请扫码加我个人微信,备注【姓名-Python群】,我诚邀你入群,大家学习和分享。