
【数学笔记】LDA线性判别分析
点击蓝字 关注我们
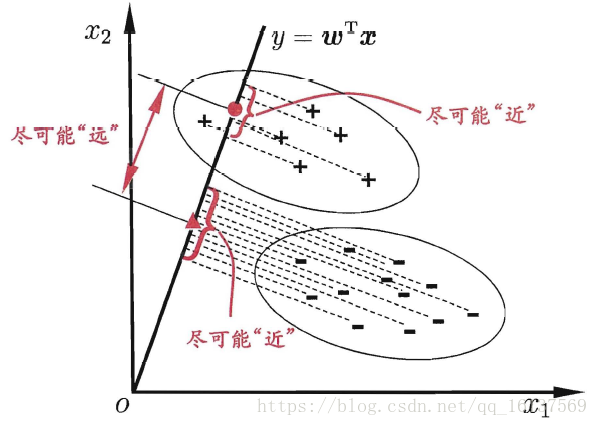
LDA的思想是设法将样本投影到一条直线上,使得:
同类样本的投影点尽可能近 异类样本的投影点尽可能远
几何展示
从简单的二分类LDA分析LDA原理
算法流程
现在我们对LDA降维的流程做一个总结。
输入:数据集D={(x1,y1),(x2,y2),...,((xm,ym))},其中任意样本xi为n维向量,yi∈{C1,C2,...,Ck},降维到的维度d。
输出:降维后的样本集$D′$
1) 计算类内散度矩阵Sw
2) 计算类间散度矩阵Sb
3) 计算矩阵Sw^−1*Sb
4)计算Sw^−1*Sb的最大的d个特征值和对应的d个特征向量(w1,w2,...wd),得到投影矩阵W
5) 对样本集中的每一个样本特征xi,转化为新的样本zi=WT*xi
6) 得到输出样本集
使用sklearn实现LDA
代码参数:
class sklearn.discriminant_analysis.LinearDiscriminantAnalysis(solver='svd',shrinkage=None,priors=None,n_components=None,store_covariance=False,tol=0.0001,covariance_estimator=None)
solver : 即求LDA超平面特征矩阵使用的方法。可以选择的方法有奇异值分解”svd”,最小二乘”lsqr”和特征分解”eigen”。一般来说特征数非常多的时候推荐使用svd,而特征数不多的时候推荐使用eigen。主要注意的是,如果使用svd,则不能指定正则化参数shrinkage进行正则化。默认值是svd。
shrinkage:正则化参数,可以增强LDA分类的泛化能力。如果仅仅只是为了降维,则一般可以忽略这个参数。默认是None,即不进行正则化。可以选择”auto”,让算法自己决定是否正则化。当然我们也可以选择不同的[0,1]之间的值进行交叉验证调参。注意shrinkage只在solver为最小二乘”lsqr”和特征分解”eigen”时有效。
priors:类别权重,可以在做分类模型时指定不同类别的权重,进而影响分类模型建立。降维时一般不需要关注这个参数。
n_components:进行LDA降维时降到的维数。在降维时需要输入这个参数。注意只能为[1, 类别数-1]范围之间的整数。如果不用于降维默认为None。
代码演示:
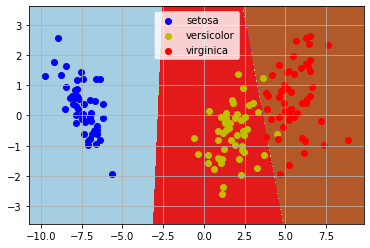
import pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn import datasetsfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysisimport numpy as np%matplotlib inlineiris = datasets.load_iris() #典型分类数据模型#这里我们数据统一用pandas处理data = pd.DataFrame(iris.data, columns=iris.feature_names)data['class'] = iris.target#这里只取两类#data = data[data['class']!=2]#为了可视化方便,这里取两个属性为例X = data[data.columns.drop('class')]Y = data['class']#划分数据集X_train, X_test, Y_train, Y_test =train_test_split(X, Y)lda = LinearDiscriminantAnalysis(n_components=2)lda.fit(X_train, Y_train)#显示训练结果print(lda.means_) #中心点print(lda.score(X_test, Y_test)) #score是指分类的正确率print(lda.scalings_)# 样本缩放比例X_2d = lda.transform(X) #现在已经降到二维X_2d=np.dot(X-lda.xbar_,lda.scalings_)#对于二维数据,我们做个可视化#区域划分lda.fit(X_2d,Y)h = 0.02x_min, x_max = X_2d[:, 0].min() - 1, X_2d[:, 0].max() + 1y_min, y_max = X_2d[:, 1].min() - 1, X_2d[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))Z = lda.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)#做出原来的散点图class1_x = X_2d[Y==0,0]class1_y = X_2d[Y==0,1]l1 = plt.scatter(class1_x,class1_y,color='b',label=iris.target_names[0])class1_x = X_2d[Y==1,0]class1_y = X_2d[Y==1,1]l2 = plt.scatter(class1_x,class1_y,color='y',label=iris.target_names[1])class1_x = X_2d[Y==2,0]class1_y = X_2d[Y==2,1]l3 = plt.scatter(class1_x,class1_y,color='r',label=iris.target_names[2])plt.legend(handles = [l1, l2, l3], loc = 'best')plt.grid(True)plt.show()
输出:
[[4.99444444 3.40277778 1.45555556 0.25277778][5.94390244 2.75853659 4.24634146 1.3195122 ][6.52571429 2.95428571 5.52285714 2.00571429]]0.9736842105263158[[-1.02533827 -0.39138399][-1.33785618 2.31273541][ 2.41859397 -0.56316402][ 2.3145385 2.41847231]]
LDA算法小结
LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在我们进行图像识别图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。
LDA算法的主要优点有:
1)在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
2)LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点有:
1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
2)LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
3)LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
4)LDA可能过度拟合数据
参来来源:
https://blog.csdn.net/brucewong0516/article/details/78684005?ops_request_misc=&request_id=&biz_id=102&utm_term=LDA%E5%8E%9F%E7%90%86&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-7-78684005.pc_search_result_before_js
https://blog.csdn.net/qq_25174673/article/details/89301192?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161442588416780261945728%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=161442588416780261945728&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-14-89301192.pc_search_result_before_js&utm_term=sklearn+%E5%AE%9E%E7%8E%B0LDA
https://blog.csdn.net/ruthywei/article/details/83045288

深度学习入门笔记
微信号:sdxx_rmbj
日常更新学习笔记、论文简述