
深度学习debug实践中的一些经验之谈
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者土豆
https://zhuanlan.zhihu.com/p/158739701
编辑王萌 澳门城市大学(深度学习冲鸭)
文仅分享,侵删

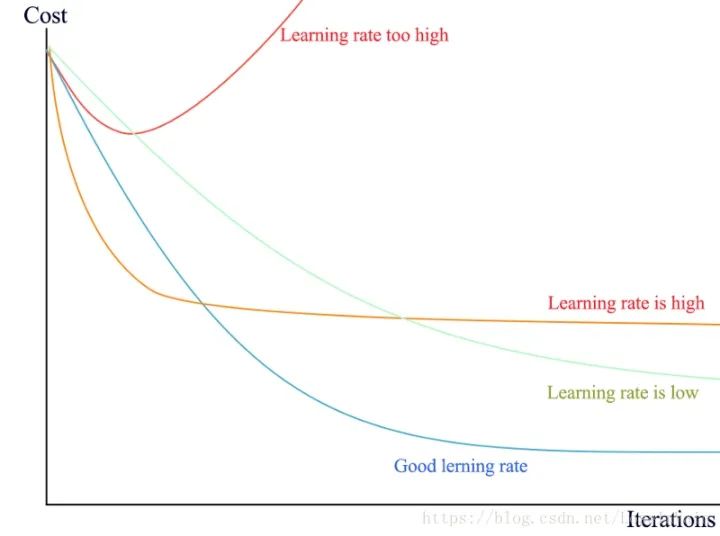
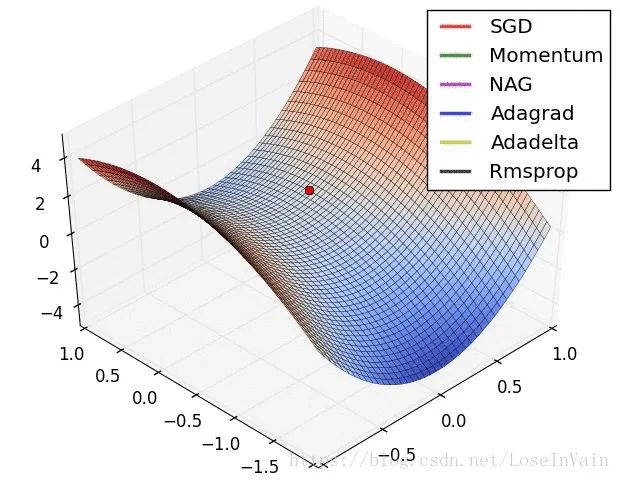
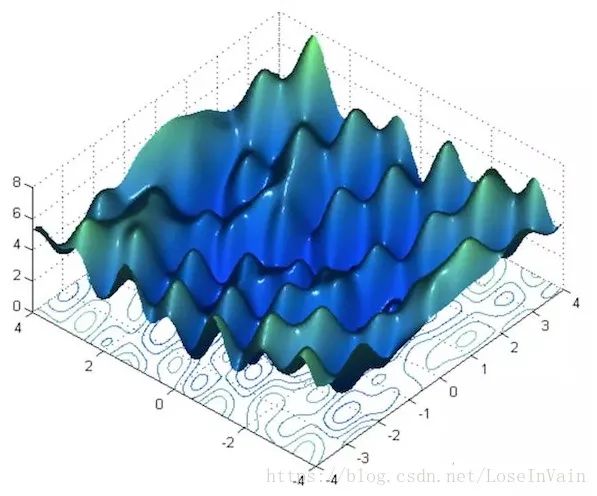
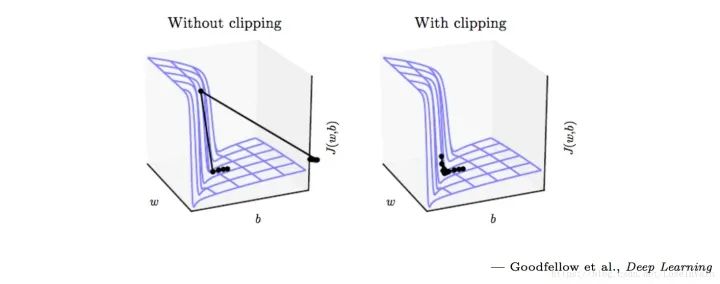
tf.clip_by_value(t,clip_value_min, # 指定截断最小值clip_value_max, # 指定截断最大值name=None)
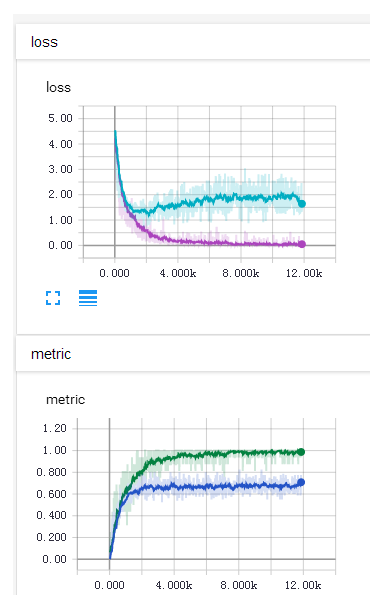
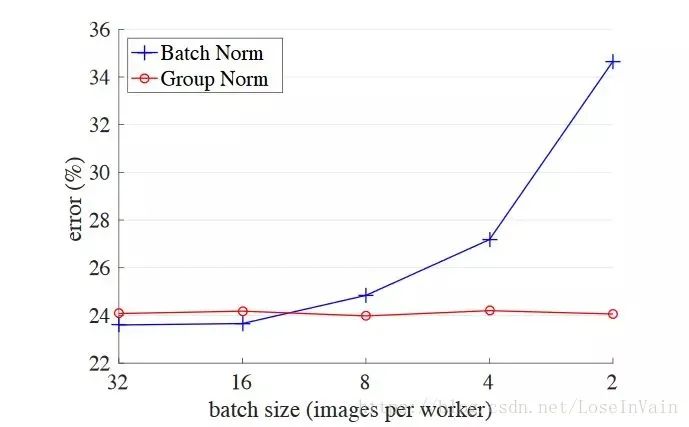
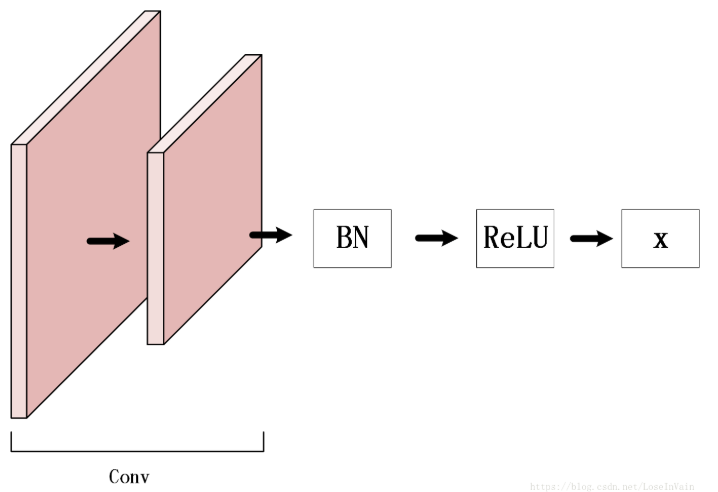
graph LRweights --> BatchNormBatchNorm --> ReLU
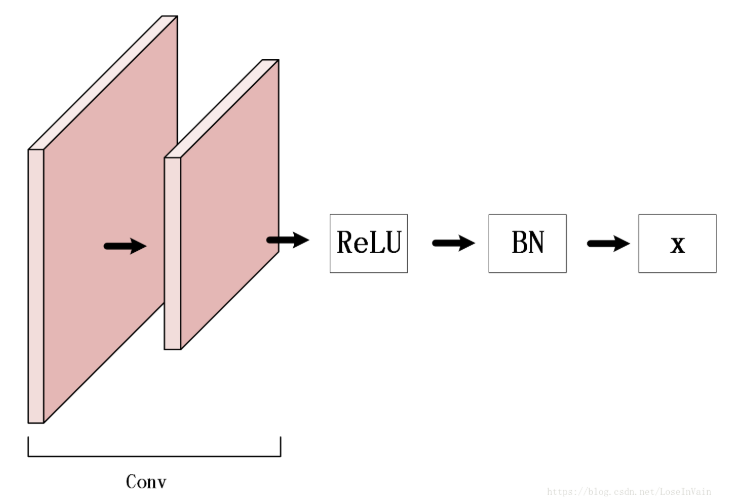
graph LRReLU --> BatchNorm+dropoutBatchNorm+dropout --> weights
softmax层的,才能保证概率和为1,不然可能会出现KL散度为负数的笑话。log_softmax而目标值需要是softmax值,也就说输入值需要进行对数操作后再转变为概率分布[27]。评论