
微软提出的ZeRO到底是个啥?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
AI编辑:我是小将
本文作者:OpenMMLab @小P家的 001996,967610
https://zhuanlan.zhihu.com/p/394064174
本文已由原作者授权转载
0 前言
本次大规模训练技术系列分享之 ZeRO,主要对微软 ZeRO Optimizer 的思路和实现进行介绍,全文包含以下四个部分:
大规模训练的技术挑战 & 现有的并行训练方式
ZeRO Optimizer 的三个不同级别
ZeRO-3 具体实现思路和方式
ZeRO 的局限与大模型训练的未来
1 训练大模型的挑战
随着人工智能技术在全球的推广应用,自动驾驶、人脸识别、自然语言处理等越来越多领域通过深度学习大大提升了算法的整体性能和表现,GPU 也成为了训练模型不可或缺的基础计算设备。然而,随着模型规模的不断增大,加之模型训练的数据量也越来越大,单个 GPU 的计算能力完全无法满足大规模网络的训练需求。在密集型训练的代表——自然语言处理中,OpenAI 在 2020 年 6 月发布的第三代语言模型 GPT-3 的参数量达到了 1700 亿,相比于之前 GPT-2 的最大版本 15 亿个参数增长了百倍以上。2021 年 4 月 25 日,华为云也发布盘古系列超大预训练模型,其中包含30亿参数的全球最大视觉(CV)预训练模型,以及与循环智能、鹏城实验室联合开发的千亿参数、40TB 训练数据的全球最大中文语言(NLP)预训练模型。这些庞大的模型训练背后,必然少不了一套精妙运转的训练系统的支持,本次分享将揭秘超大模型训练系统中必不可少的一项技术——ZeRO。
2 现有并行方法
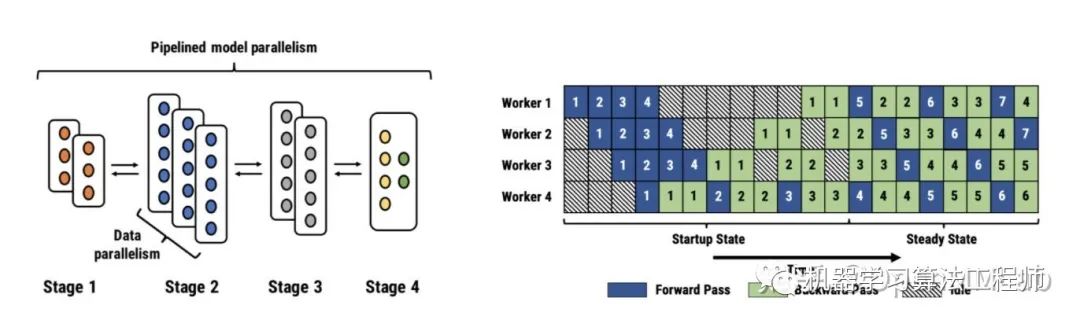
在探索 ZeRO 之前,我们需要先了解一下当前分布式训练主要的三种并行模式:数据并行、模型并行和流水线并行。
2.1 数据并行
当模型规模足够小且单个 GPU 能够承载得下时,数据并行就是一种有效的分布式训练方式。因为每个 GPU 都会复制一份模型的参数,我们只需要把训练数据均分给多个不同的 GPU,然后让每个 GPU 作为一个计算节点独立的完成前向和反向传播运算。数据并行不仅通信量较小,而且可以很方便的做通信计算重叠,因此可以取得最好的加速比。
2.2 模型并行
如果模型的规模比较大,单个 GPU 的内存承载不下时,我们可以将模型网络结构进行拆分,将模型的单层分解成若干份,把每一份分配到不同的 GPU 中,从而在训练时实现模型并行。训练过程中,正向和反向传播计算出的数据通过使用 All gather 或者 All reduce 的方法完成整合。这样的特性使得模型并行成为处理模型中大 layer 的理想方案之一。然而,深度神经网络层与层之间的依赖,使得通信成本和模型并行通信群组中的计算节点 (GPU) 数量正相关。其他条件不变的情况下,模型规模的增加能够提供更好的计算通信比。
2.3 流水线并行
流水线并行,可以理解为层与层之间的重叠计算,也可以理解为按照模型的结构和深度,将不同的 layer 分配给指定 GPU 进行计算。相较于数据并行需要 GPU 之间的全局通信,流水线并行只需其之间点对点地通讯传递部分 activations,这样的特性可以使流水并行对通讯带宽的需求降到更低。然而,流水并行需要相对稳定的通讯频率来确保效率,这导致在应用时需要手动进行网络分段,并插入繁琐的通信原语。同时,流水线并行的并行效率也依赖各卡负载的手动调优。这些操作都对应用该技术的研究员提出了更高的要求。
3 为什么需要ZeRO?
在三种并行方式中,数据并行因其易用性,得到了最为广泛的应用。然而,数据并行会产生大量冗余 Model States 的空间占用。ZeRO 的本质,是在数据并行的基础上,对冗余空间占用进行深度优化。
在大规模训练系列之技术挑战一文中,我们介绍了大规模训练中的显存占用可以分为 Model States 与 Activation 两部分,而 ZeRO 就是为了解决 Model States 而诞生的一项技术。
首先,我们来聊一下模型在训练过程中 Model States 是由什么组成的:1. Optimizer States: Optimizer States 是 Optimizer 在进行梯度更新时所需要用到的数据,例如 SGD 中的Momentum以及使用混合精度训练时的Float32 Master Parameters。2. Gradient:在反向传播后所产生的梯度信息,其决定了参数的更新方向。3. Model Parameter: 模型参数,也就是我们在整个过程中通过数据“学习”的信息。
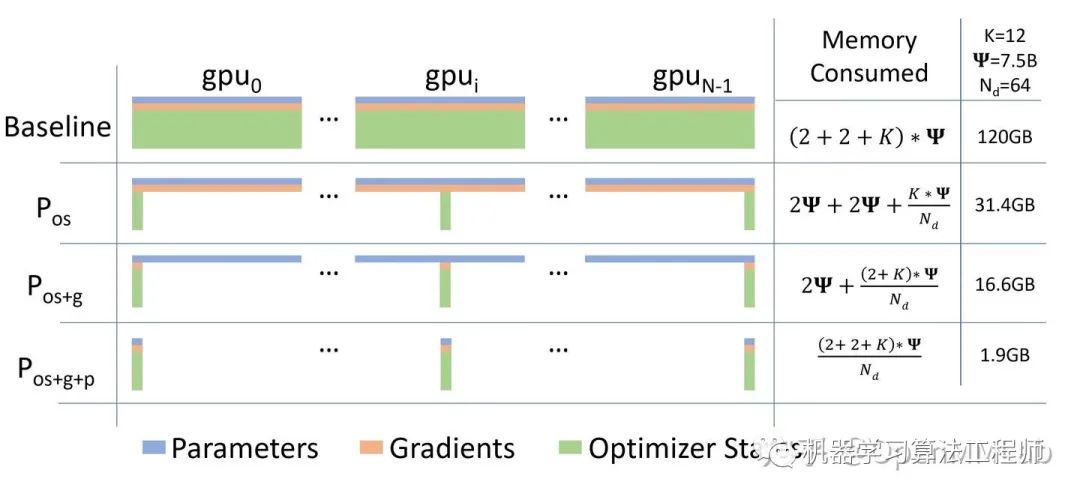
在传统数据并行下,每个进程都使用同样参数来进行训练。每个进程也会持有对Optimizer States的完整拷贝,同样占用了大量显存。在混合精度场景下,以参数量为Ψ的模型和Adam optimzier为例,Adam需要保存:- Float16的参数和梯度的备份。这两项分别消耗了2Ψ和2Ψ Bytes内存;(1 Float16 = 2 Bytes) - Float32的参数,Momentum,Variance备份,对应到 3 份4Ψ的内存占用。(1 Float32 = 4 Bytes)
最终需要2Ψ + 2Ψ + KΨ = 16Ψ bytes的显存。一个7.5B参数量的模型,就需要至少 120 GB 的显存空间才能装下这些Model States。当数据并行时,这些重复的Model States会在N个GPU上复制N份[1]。
ZeRO 则在数据并行的基础上,引入了对冗余Model States的优化。使用 ZeRO 后,各个进程之后只保存完整状态的1/GPUs,互不重叠,不再存在冗余。在本文中,我们就以这个 7.5B 参数量的模型为例,量化各个级别的 ZeRO 对于内存的优化表现。
3.1 ZeRO 的三个级别
相比传统数据并行的简单复制,ZeRO 通过将模型的参数,梯度和Optimizer State划分到不同进程来消除冗余的内存占用。
ZeRO 有三个不同级别,分别对应对 Model States 不同程度的分割 (Paritition):- ZeRO-1:分割Optimizer States;- ZeRO-2:分割Optimizer States与Gradients;- ZeRO-3:分割Optimizer States、Gradients与Parameters;
3.1.1 ZeRO-1
Optimizer States Partitioning : 4x memory reduction, same communication volume as DP
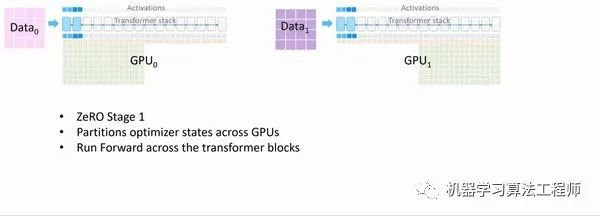
Optimizer 在进行梯度更新时,会使用参数与Optimizer States计算新的参数。而在正向或反向传播中,Optimizer States并不会参与其中的计算。因此,我们完全可以让每个进程只持有一小段Optimizer States,利用这一小段Optimizer States更新完与之对应的一小段参数后,再把各个小段拼起来合为完整的模型参数。ZeRO-1 中正是这么做的:
 ZeRO Optimizer Stage1 Animation [4]
ZeRO Optimizer Stage1 Animation [4]
假设我们有 Nd 个并行的进程,ZeRO-1 会将完整优化器的状态等分成 Nd份并储存在各个进程中。当Backward完成之后,每个进程的Optimizer: - 对自己储存的Optimizer States(包括Momentum、Variance 与 FP32 Master Parameters)进行计算与更新。- 更新过后的Partitioned FP32 Master Parameters会通过All-gather传回到各个进程中。- 完成一次完整的参数更新。
通过 ZeRO-1 对Optimizer States的分段化储存,7.5B 参数量的模型内存占用将由原始数据并行下的 120GB 缩减到 31.4GB。
3.1.2 ZeRO-2
Optimizer States and Gradient Partitioning ($P_{os+g}$): 8x memory reduction, same communication volume as DP
ZeRO-1将Optimizer States分小段储存在了多个进程中,所以在计算时,这一小段的Optimizer States也只需要得到进程所需的对应一小段Gradient就可以。遵循这种原理,和Optimizer States一样,ZeRO-2也将Gradient进行了切片:
在一个Layer的Gradient都被计算出来后:- Gradient通过AllReduce进行聚合。(类似于DDP) - 聚合后的梯度只会被某一个进程用来更新参数,因此其它进程上的这段Gradient不再被需要,可以立马释放掉。(按需保留)
这样就在ZeRO-1的基础上实现了对Gradient的切分。
通过 ZeRO-2 对Gradient和Optimizer States的分段化储存,7.5B 参数量的模型内存占用将由 ZeRO-1 中 31.4GB 进一步下降到 16.6GB。
3.1.3 ZeRO-3
Optimizer States, Gradient and Parameter Partitioning ($P_{os+g+p}$): Memory reduction is linear with DP degree
当Optimizer States,Gradient都被分布式切割分段储存和更新之后,剩下的就是Model Parameter了。ZeRO-3 通过对Optimizer States,Gradient和Model Parameter三方面的分割,从而使所有进程共同协作,只储存一份完整 Model States。其核心思路就是精细化通讯,按照计算需求做到参数的收集和释放。
3.2 ZeRO-3 宏观概览
ZeRO-3 相对于 ZeRO-1 和 ZeRO-2,实现方式会复杂很多。首先我们站在宏观的角度,理解ZeRO-3 的算法原理:
3.2.1 初始化
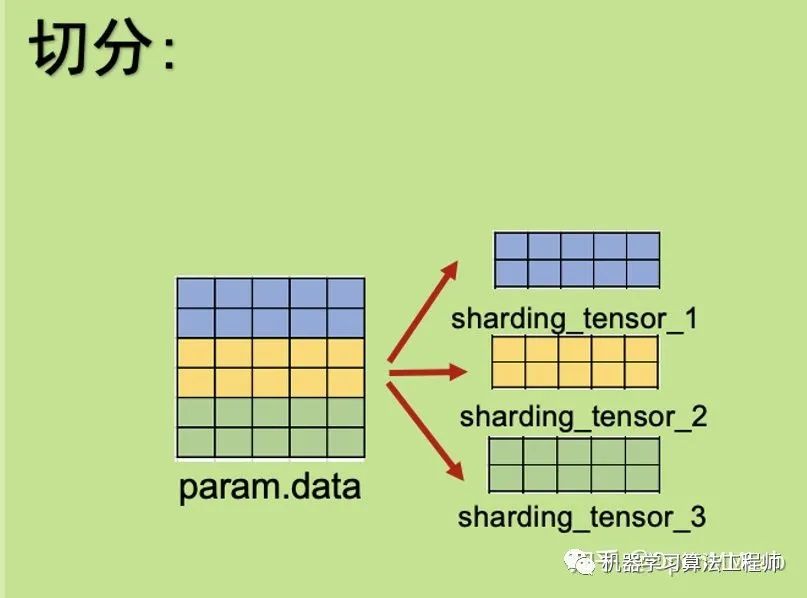
一个模型由多个Submodule组成。在初始化时,ZeRO-3 会将每个Submodule Parameter Tensor下的数据按照 GPU 的数量,分摊切割成多个小ds_tensor储存在在不同 GPU 进程中。因为ds_tensor可以共同组合出完整数据,所以原始param下的数据变为冗余信息,会被释放掉。
3.2.2 训练中
在训练过程中,ZeRO-3 会按照Submodule的计算需求进行参数的收集和释放:在当前Submodule正向/反向传播计算前,ZeRO-3 通过All-gather拿到分摊储存在不同进程中的ds_tensor,重建原始的param。重建之后的参数就可以参与计算。
在当前Submodule正向/反向传播计算后,param下的数据并没有发生变更,与 ds_tensor 相同,造成了冗余。因此,param会再次被释放。
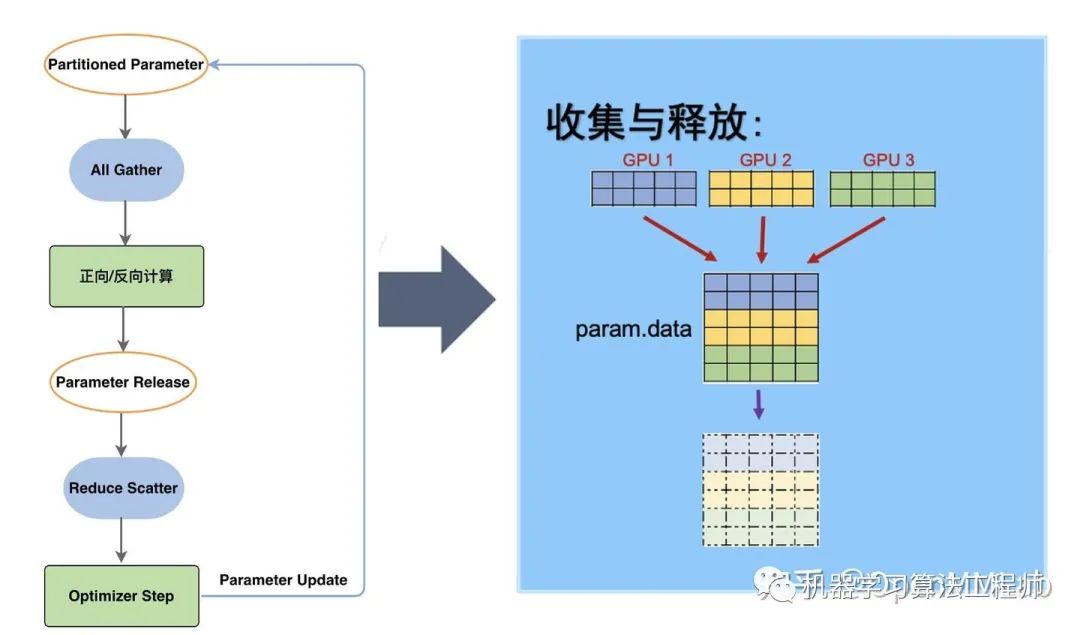
经过 ZeRO-3, 一套完整的 model states 就被分布式储存在了多个 GPU 进程中。通过按照计算需求的数据收集和释放,实现储存空间有限的情况下超大规模模型的训练。7.5B 参数量,64 卡并行的模型,内存占用将由 ZeRO-2 的 16.6GB 最终下降到 1.9GB。相较于传统数据并行下 120GB 的内存空间,ZeRO-3 显著提升了内存占用效率[1]。
以上就是 ZeRO-3 的宏观算法原理的概述。在下边的几个章节中,我们将深入源码,解读ZeRO-3 代码的实现方式和逻辑。
3.3 ZeRO-3 在 DeepSpeed 中的具体实现思路和方式
注 : 不想了解具体实现的同学可以略过这一节
在这里,我们深入代码,探索一下 ZeRO-3 是如何实现Model Parameter分布式存储的。
初始化: 分割 & 收集机制 -> submodule 收集 -> submodule 释放
3.3.1 初始化 - 模型参数的分割
参数的分割遵循着每个进程雨露均沾的原则。
首先,为了防止内存爆炸,巨大的Model Parameters必须在加载之前就被拆分并发放到各个进程中。ZeRO-3 在模型初始化时就通过class Init对其进行了分摊与切割。
python model = zero.Init(module=model)
zero.Init初始化过程对传入的module做了如下的四步:- 判定传入 ZeRO-3 的module非None - 在一个for loop中,遍历其下submodule中的所有参数 - 在 tensor 的 data 分割改变之前,对每一个parameter tensor套一层_convert_to_deepspeed_param的马甲用于记录tensor的特性(shape, numel, etc),防止后期因为 padding 和 partition 导致原始数据特性的丢失 - 参数完成conver_to_deepspeed_param之后,param.partition()对其进行均分切割并分摊给各个进程。
param.partition()中会按照如下步骤进行参数切分:
1. 根据进程数量(self.world_size)来计算 parameter partition 之后的 size:
partition_size = tensor_size // self.world_size2. 创建一个 partition_size 大小的空白 tensor:
partitioned_tensor = torch.zeros(partition_size, dtype=param.dtype, device=self.remote_device)3. 计算 partition 需要截取和储存的数据区间:
start = partition_size * self.rank
end = start + partition_size4. 把原始 param 拉成一维后,按照进程自己的 rank 来决定偏移量的start和end,计算出截取的区间并放进partitioned_tensor里,把这个新创建的 tensor 挂在原始的param.ds_tensor下:
one_dim_param = param.contiguous().view(-1)
src_tensor = one_dim_param.narrow(0, start, partition_size)
param.ds_tensor.copy_(src_tensor)5. 把原始的param.data减少到1个scalar tensor:
# 因为param.data已经被分散储存在param.ds_tensor下,
# 所以这一部分会将param.data释放掉,修改为只储存一个scalar的形式参数。
# 这也是为什么要通过_convert_to_deepspeed_param的马甲记录下原始信息的原因。
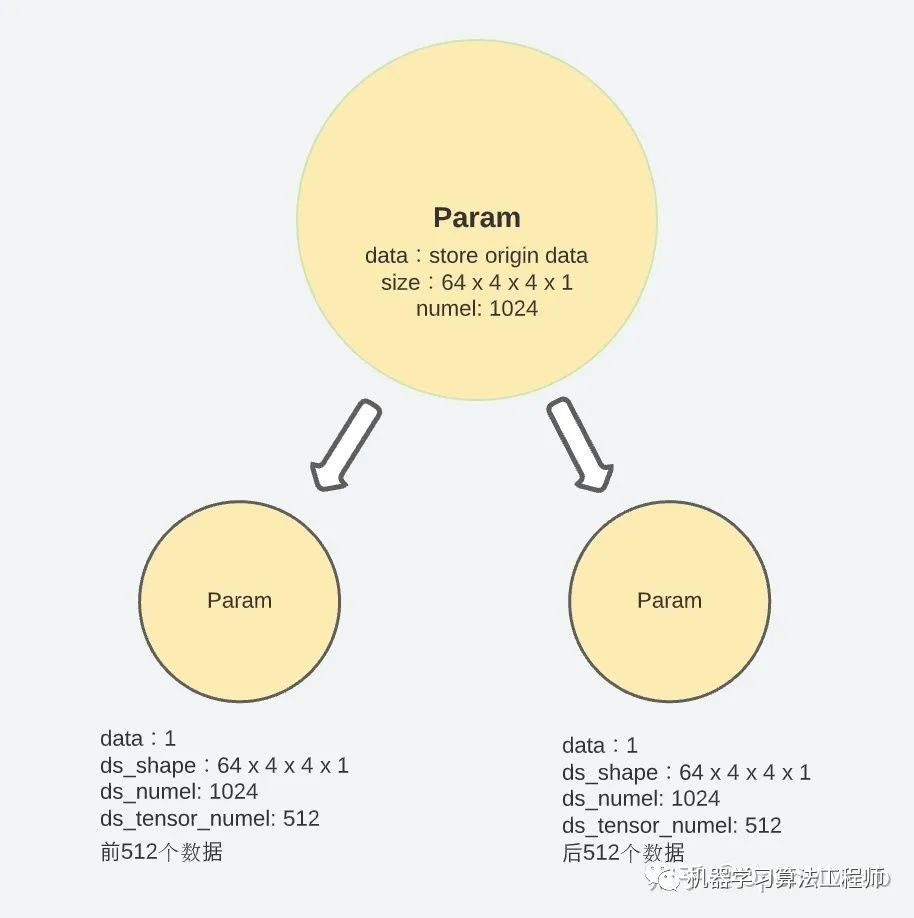
param.data = torch.ones(1).half().to(param.device)通过以上五个步骤,每个 module 中的参数就被拆分并储存到了不同的进程中,当这一步结束时,原始在param.data长度变为了 1,分段后的参数则放在param.ds_tensor中。
假设有 Nd 个 GPUs, 某一个model parameter的数据量(numel)为 T, 则其会被para.partition()成 Nd个小数据块分发到Nd个进程中,每个进程中保持 T/Nd小段原始数据。在需要重建完整 tensor 进行计算时,ZeRO-3 通过之前记录下的原始shape, numel等特性对参数进行完整的重构。
3.3.2 初始化 - 模型参数收集初始化
根据每个 submodule 需求做到更精细化的参数收集与释放。
拆分好了model parameter之后,下一步需要考虑的就是如何在需要时快速的找到这些分摊储存的参数,并且重新组合成完整的参数进行运算。参数的收集与释放虽然发生在每次的 forward 与 backward 中,但是需要在初始化就建立好控制信息,针对这个目的,ZeRO-3 中创建了另外两个 class:- class PartitionedParameterCoordinator
- class PrefetchCoordinator
这两个 class 用于负责在forward和backward时协调module parameters的获取和释放。
为了能够在模型forward和backward中及时拿到模型参数,ZeRO初始化过程的一个重要环节就是给每个submodule创建 hooks。
首先我们来一起了解一下 PyTorch 中的 hook。根据 PyTorch 的文档的介绍:
"You can register a function on a Module or Tensor. The hook can be a forward hook or a backward hook. The forward hook will be executed when a forward call is executed. The backward hook will be executed in the backward phase. "
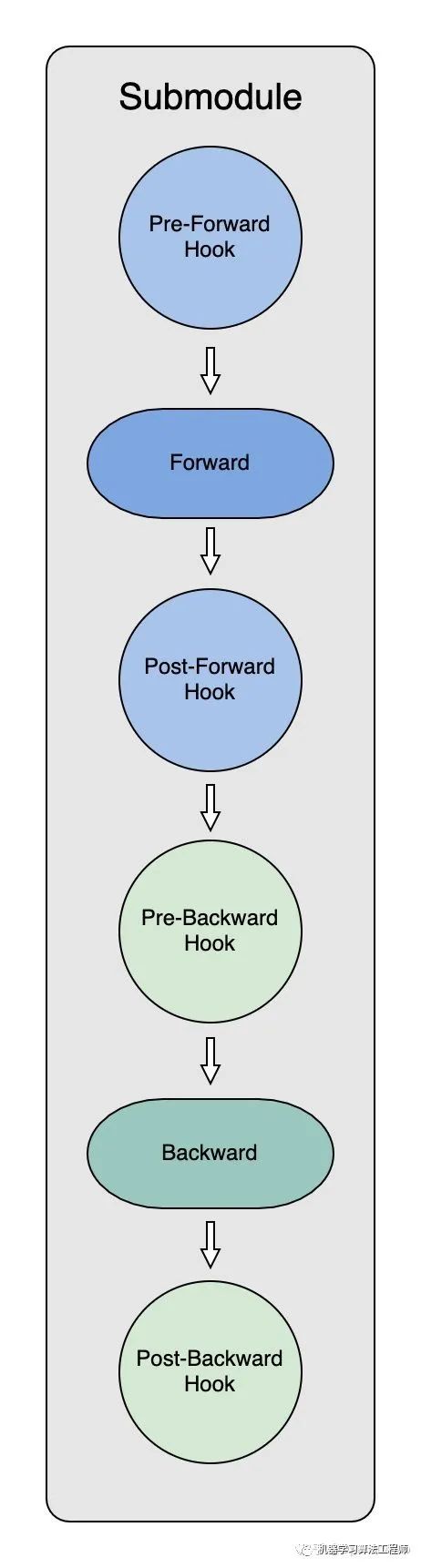
通过使用hook,我们可以在保留网络输入输出结构的同时,方便地获取、改变网络中间层变量的值和梯度。ZeRO-3 Optimizer初始化的过程中,代码通过递归的方式,对module下的每个submodule都挂上了四个 hook:
_pre_forward_module_hook,在submodule的forward开始前负责module parameters获取;_post_forward_module_hook,在submodule的forward结束后负责module parameters释放;_pre_backward_module_hook,在submodule的backward开始前负责module parameters获取;_post_backward_module_hook,在submodule的backward结束后负责module parameters释放;
在每个submodule的forward和backward计算前,hook会调用:- class PartitionedParameterCoordinator 中的fetch_sub_module和all_gather收集重建自己需要的parameter。- class PrefetchCoordinator中的prefetch_next_sub_modules则最大化利用通讯带宽,提前all_gather收集到未来submodule需要的parameter,为之后的计算做好准备。
计算完成后,hook 则通过:- class PartitionedParameterCoordinator 中的release_sub_module再次释放当前submodule的parameters。
通过这样的方式,在每一个iteration中,各个submodule就可以对自己需要的参数做出计算前的获取和计算后的释放。
3.3.3 前向传播中的 ZeRO-3
前向传播中 Model Parameter 的获取(Pre-Forward Hook)
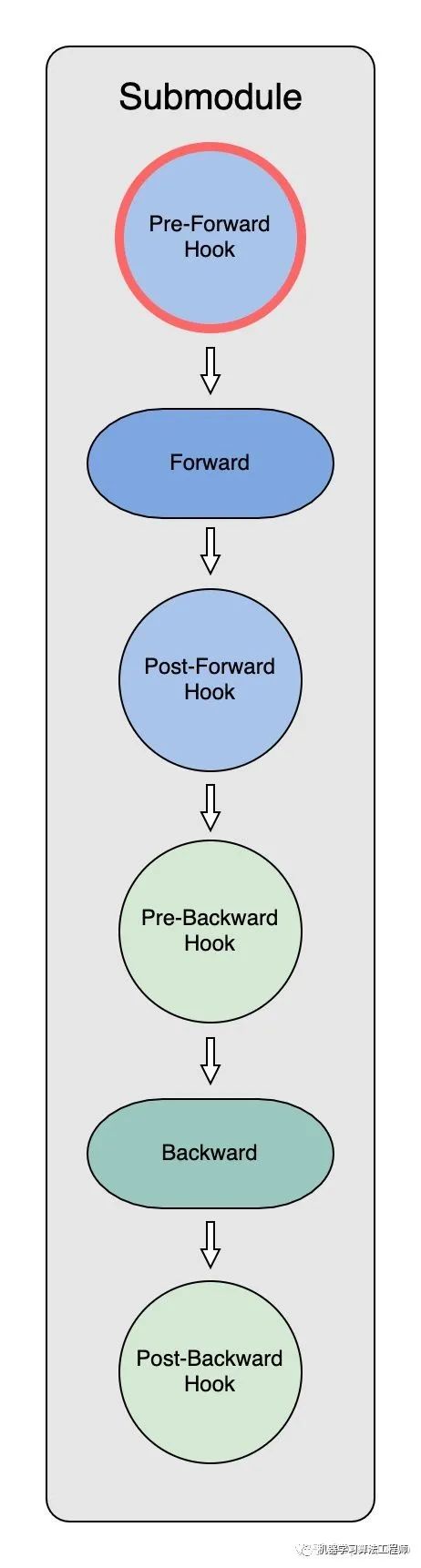
在初始化时,ZeRO-3 Optimizer 把全部module parameter分散partition到了不同的 GPU 上。因此,在每个submodule做forward之前,需要: - 明确submodule所需要的parameter - 通过进程间通讯拿到分散储存的partitioned parameter - 重新构造出原始parameter进行运算
而整个流程都是通过PartitionedParameterCoordinator和PrefetchCoordinator实现的。每个submodule在Pre-forward hook中进行了四步操作:1. param_coordinator.record_trace 在第一个iteration时,record_trace会通过param_coordinator记录下一份model的完整运行记录trace,也就是各nn.module的执行顺序。在之后的iteration,运行记录已经创建好了,record_trace就不再发挥作用。2. param_coordinator.fetch_sub_module 因为module forward会逐层进行,当获得submodule的信息后:- 通过submodule.named_parameters()收集当前需要的全部partitioned parameters。- 通过all_gather,各个进程中的partitioned parameters会被重新组合构建成原始parameter。- 利用原始parameter进行submodule.forward的计算。3. param_coordinator.prefetch_next_sub_modules 为了节省通讯时间,提高效率,Pre-Forward Hook中也会提前预取当前submodule后的submodule的参数,并对其标记以便后续调用。4. param_coordinator.increment_step Step会更新当前Submodule在trace中走到了哪一步,从而确定之后prefetch_next_sub_modules的起点。
在最后,经过以上的三步处理,便实现了:- 完成submodule计算所需的所有parameter重建。- 完成下一个submodule计算的准备。- submodule加入most_recent_sub_module_step字典中并做记录。
在第一个iteration后,通过之前创建好的trace,在之后计算过程中按照trace中的顺序,从当前step进行对参数的fetch和eager prefetch。
通过以上完整的四个步骤,就实现了一个submodule在Pre-forward hook中的操作。在实际过程中,因为module可以逐层分成多个submodule,所以整个module的forward过程中会不断的对各submodule重复以上操作。
前向传播中 Model Parameter 的分割释放(Post-Forward Hook)
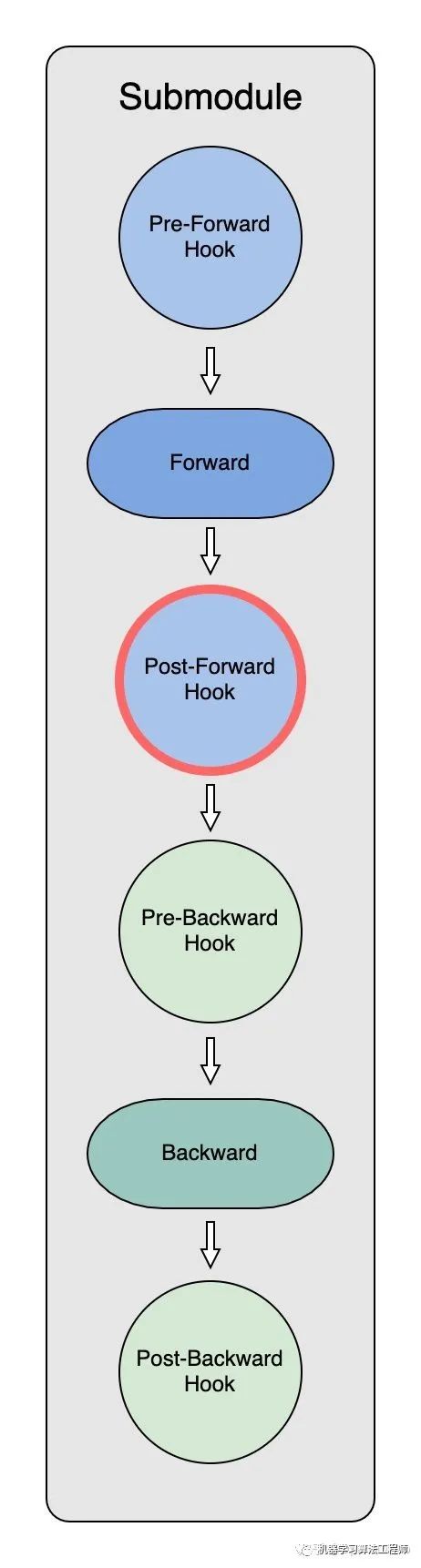
当submodule完成正向传播计算后,post_forward_hook会释放掉当前的subomdule,参数也会再次被 partition。但与初始化partition不同的是,此时每个进程中已经有了自己的小段data,所以此时partition只需要把计算前重建的完整大tensor再次释放掉:
# param.data does not store anything meaningful in partitioned state
param.data = torch.ones(1, dtype=self.dtype).to(param.device)通过这样的方式,每个进程中 submodule 只需要在计算前收集参数,计算后释放参数,从而大大减少了冗余空间占用。
当module所有的submodule都完整正向传播完成后,engine会将记录submodule执行顺序的step_id重新归为0,重新回到整个计算trace最初起点,准备下一次计算流程的开始。
3.3.4 反向传播中的ZeRO-3
反向传播中 Model Parameter 的获取(Pre-Backward Hook)
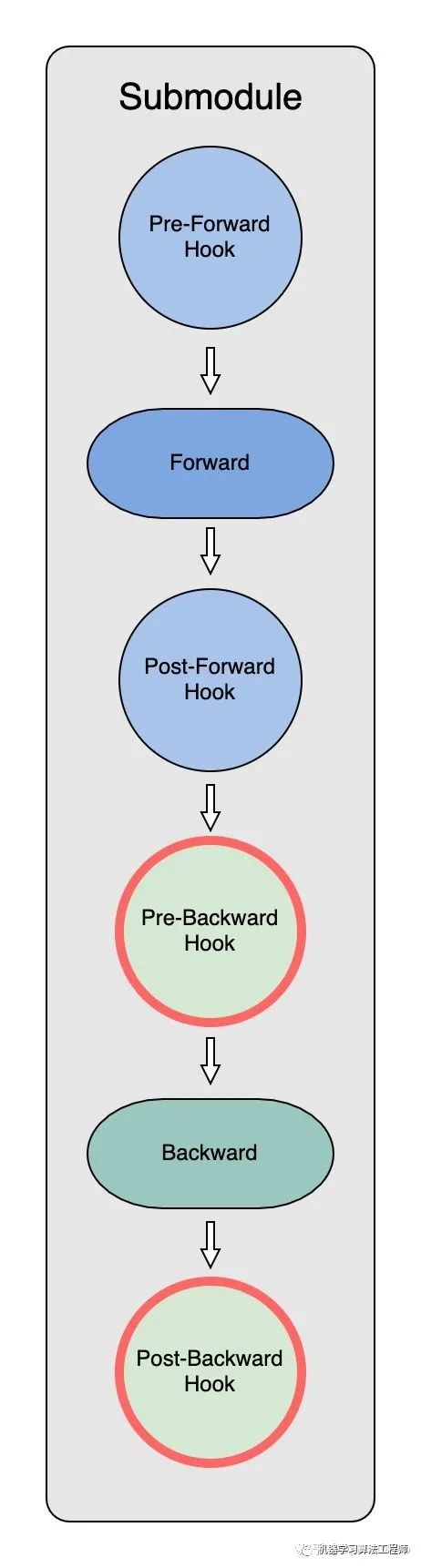
pre-backward_hook也是通过record_trace, fetch_sub_module, prefetch_next_sub_modules和next_step来实现过程的记录、参数的获取,并为下一步准备。
但是,由于 PyTorch 不支持Pre Backward Hook,因此这里得曲线救国一下:使用register_forward_hook挂上一个autograd.Function,这样就可以实现在 module backward 之前执行自定义的操作。在backward前,参数收集和分割的操作通过torch.autograd.Function挂在了各个submodule的tensor上。
当该tensor反向传播计算时,autograd的backward会调用ctx.pre_backward_function(ctx.module)依次完成:1. record_trace 2. fetch_sub_module 3. prefetch_next_sub_modules 4. next_step 这四步操作也与Pre-Forward Hook中的四步操作一致。
反向传播中 Model Parameter 的分割释放(Post-Backward Hook)
当backward结束之后,PostBackward hook中的PostBackward Function也会和post_forward_function一样将parameter释放,从而减少model parameter的空间占用。[3]
3.3.5 Evaluation
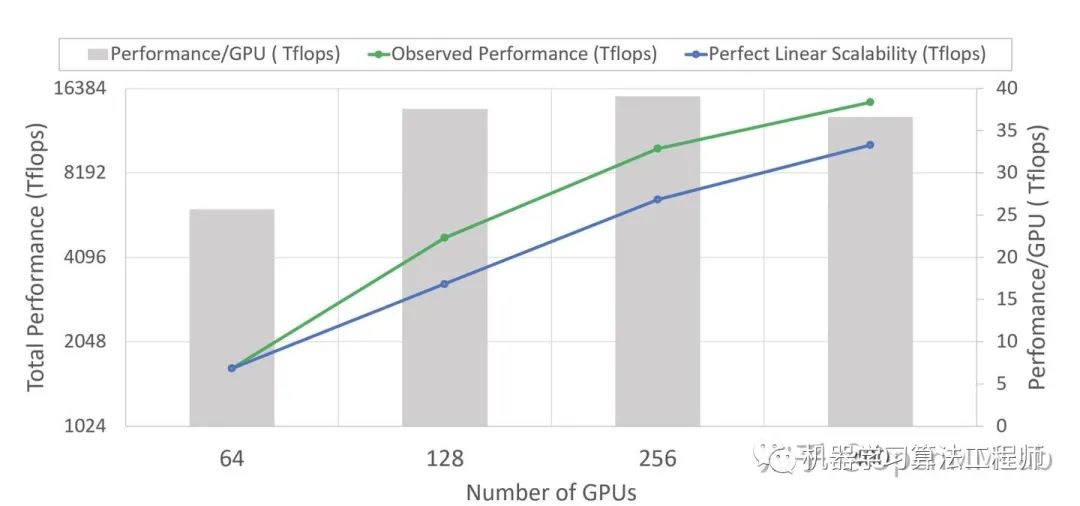
ZeRO 在 stage2 时就可在如下四个方面有杰出的表现。
ZeRO-R optimizes activation memory by identifying and removing activation replication in existing MP approaches through activation partitioning. It also offloads activations to CPU when appropriate.
在 ZeRO-2 和 ZeRO-R 配合可以支持高达170 billion 参数的模型训练。
模型规模:相较于 Megatron 局限于 40B parameters,ZeRO-2 和 ZeRO-R 的组合可以支持多达 170 billion 参数的模型训练,是当前 SOTA 方式的 8 倍。
训练速度:在 400 张 Nvidia V100 GPU 集群上,ZeRO 可以将 100B 参数量的模型训练速度提升近 10 倍,达到 38 TFlops/GPU,总体高达 15 Petaflops。
延展性:在 64-400 个 GPUs 区间,ZeRO 使训练速度具备超 GPU增量的加速比。
model states内存占用的减少,支持了更大的batch sizes的训练,从而提升模型的整体表现。易用性:数据和模型开发人员无需做任何模型并行就可训练高达 13 billion 参数的模型,从而减少了模型重构带来的成本开销。[1]
在 ZeRO-3 的加持下,ZeRO Optimization 性能会得到进一步的提升。
ZeRO-3 可以在单纯数据并行的模式下,实现在 1024 个 GPUs 上训练超过 1 Trillion 的模型。配合模型并行,ZeRO 通过 16 路模型并行和 64 路数据并行,更是支持高达超过 2 Trillion 的模型训练[1]。
4 What's next ? ZeRO 的局限与大模型训练的未来
4.1 简单粗暴的ZeRO也有局限性
ZeRO 在每个 submodule 的前向和反向传播中进行了参数的collection与partition。在这种策略下:1. 单个 submodule 在前向或反向传播中所占用的显存(参数、梯度、Outputs、Workspace)小于单个GPU的容量。2. 频繁利用通信来传递参数、梯度等信息,导致通信成为瓶颈。
4.1.1 大 Layer
例如 Transformer Model 中的一个64K hidden dimension Layer,在 Float16 下也需要超过 64GB 的显存来储存模型参数和梯度。在计算正向和反向传播时,需要至少两个超过 32GB 的连续 memory buffer。这样的需求即使在 NVIDIA A100 中也很难满足。为了解决超大 Layer 这一难题,研究人员在 ZeRO 基础之上引入了对单层 Layer 的拆分技术,也就是俗称的模型并行。这里简单提一下两个比较有意思的工作:
Megatron-LM [5] 中充分利用了 Transformer 的模型结构,对多个 GEMM 进行了相当高效的拆分。在
MLP中,以纵向并行的方式划分第一个 GEMM,后续的GeLU与第二个GEMM只在本地进行,唯一的通信在Dropout前对第二个GEMM的输出做个加和。通过这样的方式,GEMM 就可以被分到不同的 GPU 上,并只需在正向和反向传播时各做一次AllReduce。对于Self-Attention模块其也用了类似的拆分方法,核心仍是利用了分块矩阵乘法。
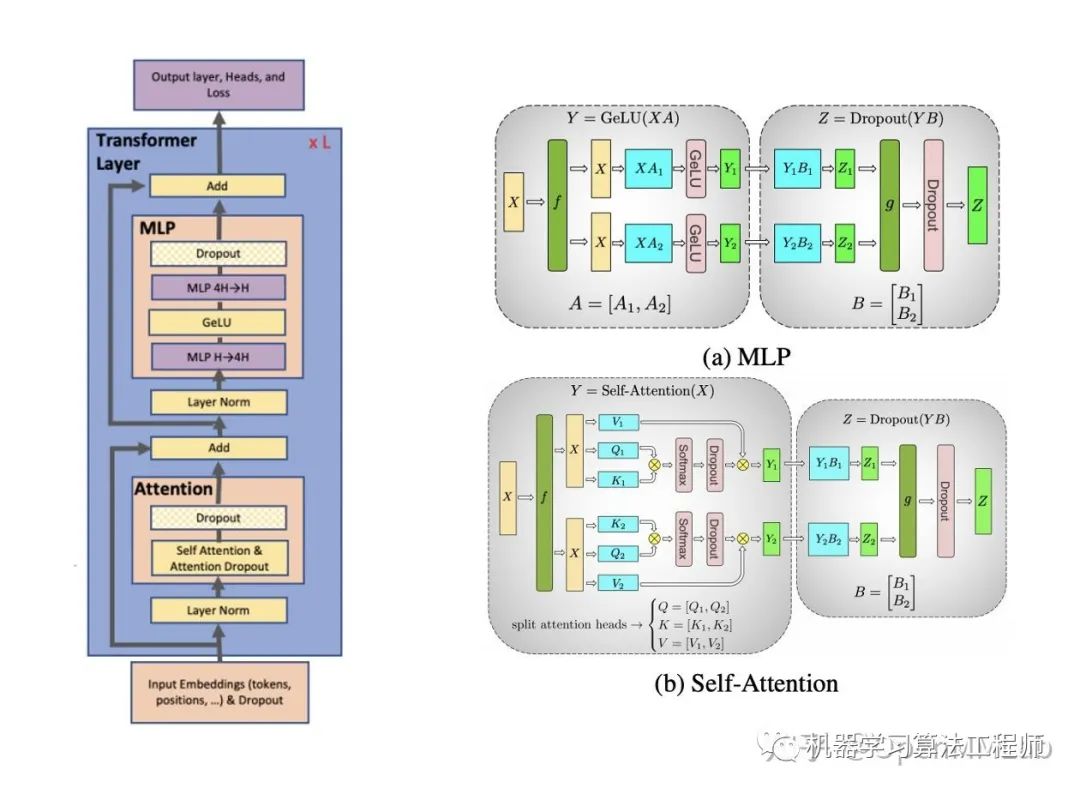
Optimus [7] 同样利用了 Transformer 模型矩阵乘法的本质,但是不在行列的维度上分割矩阵,而是采用二维矩阵分割,并在理论效率上显著超过了前者。(PS:这两个工作的名字真是因吹斯汀
4.1.2 大通信
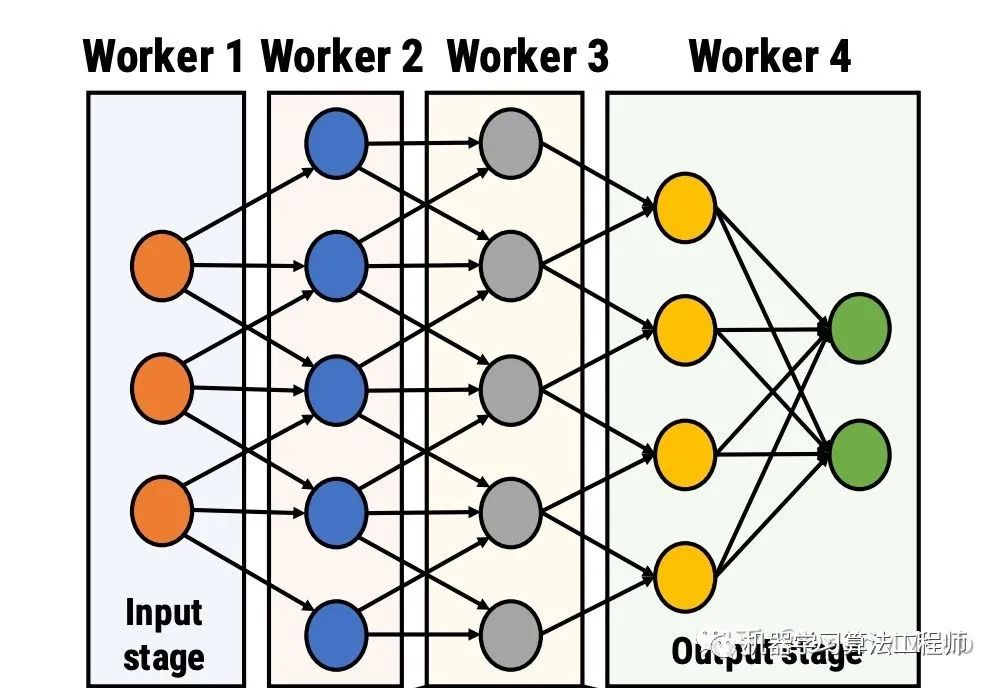
通信问题则主要考虑引入流水线并行来缓解。流水线并行将模型按层切分成了很多个 Stage,每一个 Worker 只持有一部分 Layer。切分后,不但每张卡上的参数和计算量减少了,同时 Worker 和 Worker 之间也只需要通信临界层的 Activations。
对于 Transformer 模型来说,临界层的 Activations 大小远远小于参数、梯度的大小,因此可以采用在节点间做流水线并行,节点内多卡做数据并行的方式来缓解节点间的通信压力,同时充分利用节点内的超高带宽。也可以将数据并行分为两级,一级在节点内做通信量较大的 ZeRO 数据并行,另一级在多个流水线并行间做普通的数据并行。
4.2 最后
细心的朋友可能已经发现了,将上述的流水线并行、模型并行与数据并行相融合,就成了目前火热的 3D 混合并行。也正是 3D 混合并行支撑起了 GPT-3、盘古等千亿参数 Transformer 模型的训练,纵然 3D 混合并行恐怖如斯,其仍然有许多局限性,这个就放在之后的系列分享中再展开了。
放眼未来的大模型训练,同样也不会是 ZeRO 技术或某项技术独霸天下,而是在各类技术的更迭与融合中,形成一个愈发高效、通用、易用的大模型训练系统。目前我们组也正在朝着视觉大模型这个极具挑战的方向努力,希望看到这里的你也能加入进来一起搞大新闻,简历请发 yanzijie@sensetime.com (备注来自知乎,第一时间处理)。
引用
[1] Samyam R, Jeff R, Olatunji R, Yuxiong H. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. arxiv.org/pdf/1910.02054. 2019.
[2] Turing-NLG: A 17-billion-parameter language model by Microsoft
[3] Rangan M, Junhua W. ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters. 2020.
[4] KDD 2020: Hands on Tutorials: Deep Speed -System optimizations enable training deep learning models
[5] Mohammad S, Mostofa P, Raul P, et al. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism arxiv.org/abs/1909.08053 .2019
[6] Rangan M, Andrey P. ZeRO-Infinity and DeepSpeed: Unlocking unprecedented model scale for deep learning training. 2021
[7] Xu Q, Li S, Gong C, et al. An Efficient 2D Method for Training Super-Large Deep Learning Models[J]. arXiv preprint arXiv:2104.05343, 2021.
附录
PyTorch 的模型必须具有以下的三种特性:1.必须继承nn.Module这个类,要让 PyTorch 知道这个类是一个 Module 2.在init(self)中设置好需要的"组件"(如conv,pooling,Linear,BatchNorm等) 3.最后,在forward(self,x)中定义好的“组件”进行组装,就像搭积木,把网络结构搭建出来,这样一个模型就定义好了。
根据 PyTorch 的文档介绍, nn.Module是所有模型的基础 class,我们构建的各种模型网络也是这个nn.Module的subclass,并且每个 Module 也可以包含其他的 Module。
“All network components should inherit from nn.Module and override the forward() method. That is about it, as far as the boilerplate is concerned. Inheriting from nn.Module pro ides functionality to your component. ”
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)# submodule: Conv2d
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))PyTorch 给出的上述例子中,class Model就是继承了nn.Module,其内部两个nn.Conv2d各自也继承了nn.Module,nn.Conv2d就是class Model的submodule了。在 stage3 中,ZeRO 就是利用了 module 的这种嵌套的特性来实现模型参数的记录和并行。
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
