
Hive SQL到底是个啥?
1. Hive的能力与应用概述
Hadoop实现了一个特别的计算模型,就是MapReduce,可以将我们的计算任务分拆成多个小的计算单元,然后分配到家用或者服务器级别的硬件机器上,从而达到降低成本以及可扩展的问题,在这个MapReduce计算模型底下,有一个分布式文件系统(HDFS),在支持分布式计算上极其重要。
而Hive就是用来查询存储在Hadoop集群上数据而存在的,它提供了HiveQL,语法与我们平时接触的SQL大同小异,它让我们不需要去调用底层的MapReduce Java API,只需要直接写熟悉的SQL,即可自动进行转换。‘
当然Hive并不是一个完整的数据库,Hadoop以及HDFS的设计,本身就约束和局限了Hive的能力:
1)最大的限制就是不支持数据行级别的Update、Delete操作;
2)不支持事务,因此不支持OLTP所需要的关键功能,它更接近OLAP,但是查询效率又十分堪忧;
3)查询效率堪忧,主要是因为Hadoop是批处理系统,而MapReduce任务(JOB)的启动过程需要消耗较长的时间;
4)如果用户需要对大规模数据使用OLTP功能的话,可以选择Hadoop的HBase及Cassandra。
综上所述,Hive最合适的应用场景就是我们当前的做数据仓库、数据中台等等的工作,维护海量数据,挖掘数据中的宝藏,形成报表、报告、建议等等。
2. MapReduce综述
如上,我们知道MapReduce是一种计算模型,该模型可以将大规模数据处理的任务拆分成多个小计算单元,然后分配到集群中的机器上去并行计算,最终合并结果返回给用户。MapReduce主要分两个数据转换操作,map和reduce过程。
Map:map操作将集合中的元素从一种形式转成另外一种形式。
Reduce:将值的集合转换成一个值。
这些map和reduce任务,就是Hadoop将job拆分后的子任务(task),然后调度这些task去完成数据的计算,而计算的位置一般都是在数据所在的位置,从而可以保证最小化网络开销。
3. Hadoop生态系统中的Hive
Hive主要由下图中的模块组成,主要分3部分(Web+Hive+Hadoop)。直接与我们用户交互的Web图形界面,有很多商业化的、开源的产品,如图所示;当然,发行版的Hive也自带有交互界面,如命令行界面(CLI)和简单的Hive网页界面(HWI),以及一列JDBC、ODBC、Thrift Server的编程模块。
我们所有的命令和查询,都会首先进入到Driver(驱动模块),通过该模块进行任务的解析编译,优化任务,生成Job执行计划,Driver的基础模块主要负责“语言翻译”,把job执行计划的XML文件驱动执行内置的、原生的Mapper和Reducer模块,从而实现MapReduce任务执行。
Thrift Server提供了可远程访问其他进程的功能,也提供使用JDBC和ODBC访问Hive的功能。另外再介绍一下Metastore,这是专门存储元数据的独立关系型数据库(一般是一个MySQL实例),Hive使用它的服务来存储表模式信息和其他元数据信息,需要使用JDBC来连接。
Hive通过和Job Tracker通信来初始化MapReduce任务(job),不必要部署在Job Tracker所在的管理节点上(一般在网关机上),之前也提到过,job拆分开的task任务,一般都会在数据所在的节点直接申请机器资源进行计算,数据文件存储于HDFS中,管理HDFS的是NameNode。
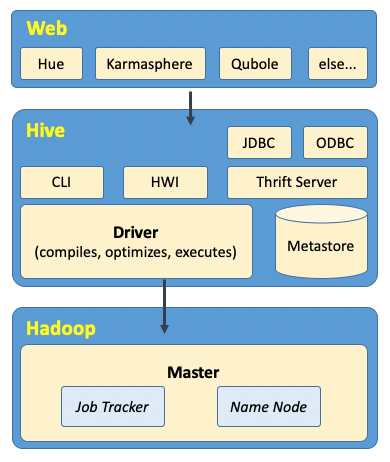
当实际执行一个分布式任务时候,集群会启动多个服务。其中,Job Tracker管理着Job,而HDFS则由Name Node管理着,每个工作节点上都有job task在执行,由每个节点的Task Tracker服务管理着,而且每个节点上还存放着分布式文件系统中的文件数据块,由每个节点上的DataNode服务管理着。
4. Hive调优
1. JOIN调优
Hive假定查询中最后一个表上最大的表,所以,在对每行记录进行连接操作时,它会尝试将其他表缓存起来,然后扫描最后那个表进行计算。因此我们需要保证连续join查询中表的大小从左往右是依次增加的。
# 低效查询
select * from big_table a
left join small_table b on a.id = b.id
# 高效查询
select * from small_table a
right join big_table b on a.id = b.id
另外,如果其中一张表是小表,还可以放入内存,Hive就可以在map端执行连接操作(称为 map-side JOIN),从而省略了常规连接操作中的reduce过程。
set hive.auto.convert.join=true;
用户可以自己配置小表的大小(单位:字节)
set hive.mapjoin.smalltable.filesize=30000000;
2. 使用 EXPLAIN
使用explain很简单,就是在SQL语句最前面加上 EXPLAIN 关键词即可,更多姿势:
explain:查看执行计划的基本内容;
explain analyze:用实际的SQL行数注释计划。从 Hive 2.2.0 开始支持;
explain authorization:查看SQL操作相关权限的信息;
explain ast:输出查询的抽象语法树。AST 在 Hive 2.1.0 版本删除了,存在bug,转储AST可能会导致OOM错误,将在4.0.0版本修复;
explain extended:加上 extended 可以输出有关计划的额外信息。
使用EXPLAIN可以帮助我们去了解hive执行顺序,协助优化Hive,对我们提升Hive脚本效率有着很大的帮助。
explain
select
count(0) t1,
count(distinct cust_id) t2
from
dm_dl.cust_info
where
inc_day = '20210920'
limit
1
输出内容如下,可以看下我的注释,输出主要两部分:
1)stage dependencies:负责输出每个stage之间的依赖
2)stage plan:每个stage的执行计划。stage里会有MapReduce的执行计划树,分为Map端和Reduce端,关键词为 Map Operator Tree 和 Reduce Operator Tree。
每个stage都是一个独立的MapReduce Job,可以从执行计划的描述大概猜到具体做了什么步骤,另外,执行计划中关于数据量的值仅供参考,因为是预估的,可能与实际的有一定出入。
STAGE DEPENDENCIES: # 显示每个stage之间的前后依赖关系
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS: # 执行计划明细
Stage: Stage-1 # 第一个stage
Map Reduce
Map Operator Tree: # Map端的逻辑操作树
TableScan # 扫描table
alias: cust_info
Statistics: Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: cust_id (type: string)
outputColumnNames: _col1
Statistics: Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count(0), count(DISTINCT _col1)
keys: _col1 (type: string)
mode: hash
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: + # 可以看到聚合后的结果是有排序的
Statistics: Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE
TopN Hash Memory Usage: 0.1
value expressions: _col1 (type: bigint)
Reduce Operator Tree: # Reduce端的逻辑操作树
Group By Operator
aggregations: count(VALUE._col0), count(DISTINCT KEY._col0:0._col0)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 24 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 24 Basic stats: COMPLETE Column stats: NONE
File Output Operator # 文件输出操作
compressed: false
Statistics: Num rows: 1 Data size: 24 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: 1
Processor Tree:
ListSink
加入关键字 explain formatted 就可以以json格式输出啦。
{
"STAGE DEPENDENCIES": {
"Stage-1": {
"ROOT STAGE": "TRUE"
},
"Stage-0": {
"DEPENDENT STAGES": "Stage-1"
}
},
"STAGE PLANS": {
"Stage-1": {
"Map Reduce": {
"Map Operator Tree:": [
{
"TableScan": {
"alias:": "cust_info",
"filterExpr:": "(inc_day = '20210920') (type: boolean)",
"Statistics:": "Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE",
"children": {
"Select Operator": {
"expressions:": "cust_id (type: string)",
"outputColumnNames:": [
"_col1"
],
"Statistics:": "Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE",
"children": {
"Group By Operator": {
"aggregations:": [
"count(0)",
"count(DISTINCT _col1)"
],
"keys:": "_col1 (type: string)",
"mode:": "hash",
"outputColumnNames:": [
"_col0",
"_col1",
"_col2"
],
"Statistics:": "Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE",
"children": {
"Reduce Output Operator": {
"key expressions:": "_col0 (type: string)",
"sort order:": "+",
"Statistics:": "Num rows: 1115055 Data size: 113735610 Basic stats: COMPLETE Column stats: NONE",
"TopN Hash Memory Usage:": "0.1",
"value expressions:": "_col1 (type: bigint)"
}
}
}
}
}
}
}
}
],
"Reduce Operator Tree:": {
"Group By Operator": {
"aggregations:": [
"count(VALUE._col0)",
"count(DISTINCT KEY._col0:0._col0)"
],
"mode:": "mergepartial",
"outputColumnNames:": [
"_col0",
"_col1"
],
"Statistics:": "Num rows: 1 Data size: 24 Basic stats: COMPLETE Column stats: NONE",
"children": {
"Limit": {
"Number of rows:": "1",
"Statistics:": "Num rows: 1 Data size: 24 Basic stats: COMPLETE Column stats: NONE",
"children": {
"File Output Operator": {
"compressed:": "false",
"Statistics:": "Num rows: 1 Data size: 24 Basic stats: COMPLETE Column stats: NONE",
"table:": {
"input format:": "org.apache.hadoop.mapred.TextInputFormat",
"output format:": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"serde:": "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"
}
}
}
}
}
}
}
}
},
"Stage-0": {
"Fetch Operator": {
"limit:": "1",
"Processor Tree:": {
"ListSink": { }
}
}
}
}
}
5. HiveSQL背后实现原理
平时我们经常写Hive SQL,我们知道Hive会自动帮我们转译成MapReduce Job,调用集群分布式能力去完成任务计算。那么,Hive是如何将SQL转化成MapReduce Job的?可以见下图:

主要就是通过5步完成,从Hive SQl --> AST Tree --> Query Block --> Operator Tree --> MapReduce Job --> 执行计划DAG。

推荐阅读
欢迎长按扫码关注「数据管道」