
惊!网络设计空间到底是个啥?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
网络设计空间(Network Design Spaces)是Facebook AI在On Network Design Spaces for Visual Recognition提出的概念,一个网络设计空间定义了一个符合特定设计结构且参数化的模型群,这篇论文提出通过统计学方法来对网络设计空间进行评估,而不单单是评估某个具体的模型。Designing Network Design Spaces是这项工作的延续,这篇论文进一步提出要对网络设计空间进行设计,在通过统计学方法进行设计优化后得到了RegNet模型。这两项工作为模型设计带来了一个全新的视角:通过统计学方法来进行模型评估和优化。本篇先介绍第一个工作。
网络设计空间
在早期的工作中,评估图像分类模型性能往往采用点估计(point estimates):一个模型在benchmark数据集误差最小就是最好的,这里往往不考虑模型复杂度,如VGG优于AlexNet。最近的工作往往会比较不同复杂度(eg. flops)下模型性能,如ResNet50,ResNet101等,这种评估可以称为曲线估计(curve estimates),一个模型如果在曲线上的每个点都比较更好那就是更优的。On Network Design Spaces for Visual Recognition这篇论文提出了分布估计(distribution estimates):从网络设计空间中随机sample一定错误率的分布,并通过统计学方法来分析,从而实现对网络设计空间的评估。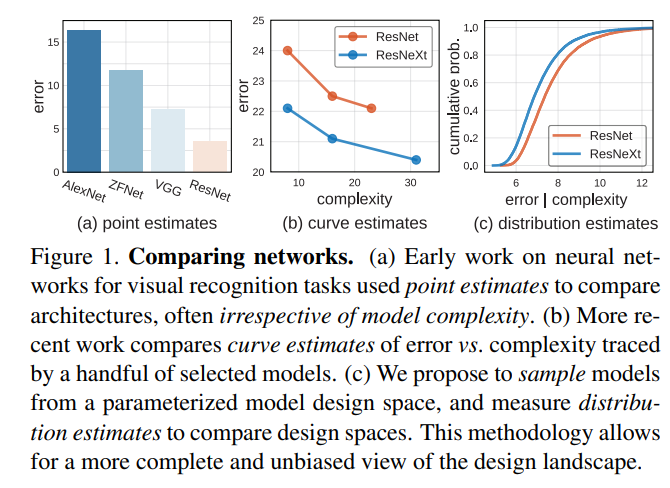
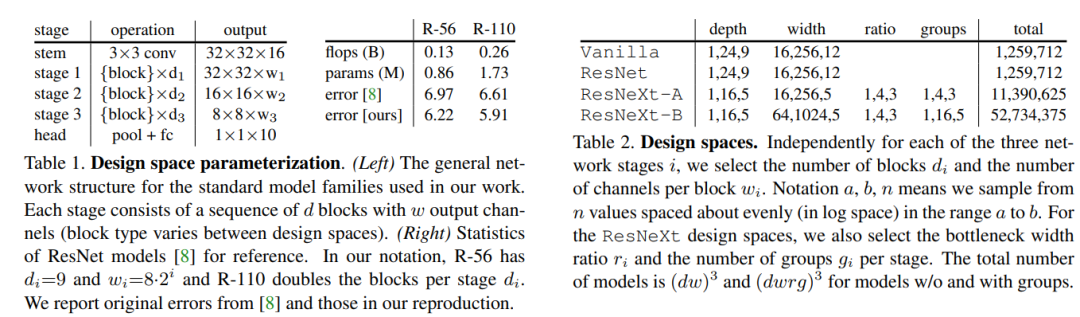
为了理解网络设计空间,这里先明确一个概念:模型族(model family)。一个模型族是指具有相关网络结构的模型集合,这个集合一般无限大,一个模型族的模型或者共享一些高级结构,或者遵循相同的设计原则。比如ResNets就是一个模型族,它包含的模型均含有残差连接,而ResNet50只是其中一个具体的模型结构。模型族只是笼统的定义,并没有具体化,而网络设计空间是可以从模型族实例化的一套具体的网络结构集合。一个网络设计空间要包含两个组件:一是一套模型超参数,一旦这些超参数确定就能实例化某个具体的网络;二是一套各个模型超参数的可允许值。设计空间可以看成是限定了的模型族,比如ResNets模型族的一个设计空间需要包含一个网络深度(depth)的超参数以及它的限定范围。论文中共选择了4个模型设计空间如下所示,模型包括stem,3个stages和head,对于ResNet,block包含2个3x3卷积和残差连接,而Vanilla不带残差连接,这里的ResNetXt的block采用分组的bottleneck结构,A和B只是超参数不同。
虽然一个网络设计空间可能包含指数级候选模型,但是我们可以从中随机抽样固定量的模型来评估以得到近似的分布,并采用经典统计学工具来进行分析。论文里采用经验分布函数(empirical distribution functions, EDFs)来比较分布,给定个抽样的模型,模型的分类误差记为,那么误差EDF就可以计算出来:
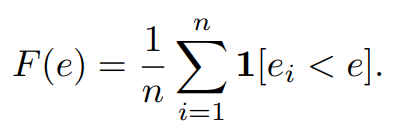
这里的就是误差小于的模型占比。对于EDF曲线,很明显曲线下的面积越大,说明误差小的模型占比越多,这样可以简单看出分布的好坏。所以EDF就可以作为网络设计空间的分布估计。论文实验采用CIFAR-10数据集,为了得到比较可靠的估计,共从每个设计空间随机采样25k个模型,总共就是100k个模型,这里限定抽样的模型的flops或者参数量小于ResNet-56。
当开发新模型,大家往往都是从一个设计空间中人工或者自动化(如NAS)找出一个误差最小的模型,这其实就是点估计。但是用点估计来评估设计空间可能是不当的,这里论文通过一个简单的实验来证明:从相同的设计空间里抽样不同量的模型。具体的,模型集B是从ResNet设计空间随机抽样100个模型,而模型集M是抽样1000个模型。对于点估计就是用模型集的误差最小模型来比较,下图展示了重复实验5000次的模型集B和M误差最小的差值,可以看到90%的情况下,M都比B小。这也不难理解,毕竟M包含更多的模型,更容易找到更优的模型。这只是说明如果进行了算力不一致的点估计会对设计空间产生误导(当用了更多的算力去证明某个模型设计更优在论文中非常常见,但是这看来并不可靠)。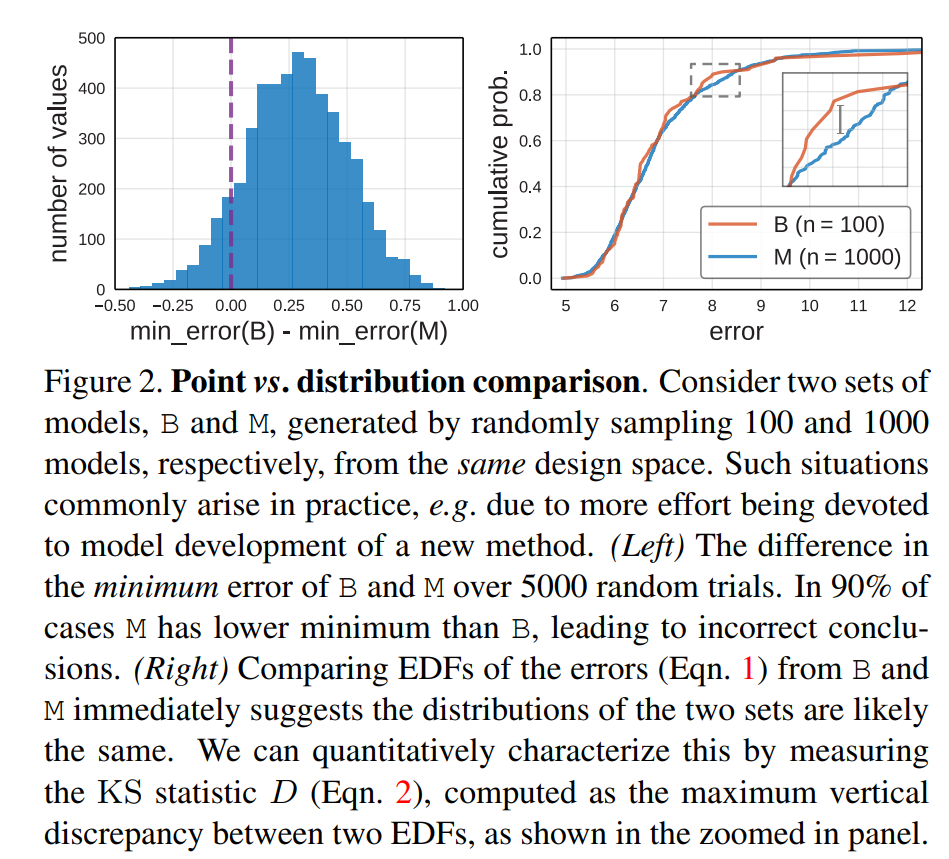 但是如果采用EDF去分析,我们会发现B和M的分布基本一致,这说明分布评估对模型量不敏感,用来对网络设计空间评估更可靠。
但是如果采用EDF去分析,我们会发现B和M的分布基本一致,这说明分布评估对模型量不敏感,用来对网络设计空间评估更可靠。
但是在做分布评估时要注意控制一些与模型性能相关的因素,如模型复杂度。对于ResNetXt-A和ResNetXt-B两者只是模型超参数不同,但是它们的EDF却有不小的差异,如果只看EDF的话,那么ResNetXt-B要优于ResNetXt-A。这说明来自同一个模型族的不同设计空间会存在差异。但是这里的分析忽略了一个重要因素对模型性能的影响,那就是模型复杂度,很显然,模型越大性能往往越优。ResNetXt-A和ResNetXt-B的超参数设置的差异可能会带来模型复杂度的影响。从ResNetXt-A和ResNetXt-B的复杂度分布来看,ResNetXt-A比ResNetXt-B包含更多复杂度大的模型,这说明两者的EDF差异肯定有复杂度差异带来的影响。论文里做的一个方案是做一个归一化的操作来消除复杂度分布不同带来的影响,具体的是假定模型复杂度分布是均匀的,根据这样的假设来确定每个模型的权重系数。下图也展示了对params和flops进行归一化的EDF分布,可以看到ResNetXt-A和ResNetXt-B两者的差异就非常小了,但依然能看到ResNetXt-B稍微优于ResNetXt-B,这可能是模型结构设置上的一些不同造成的,比如ResNetXt-B包含分组数更多的更宽模型。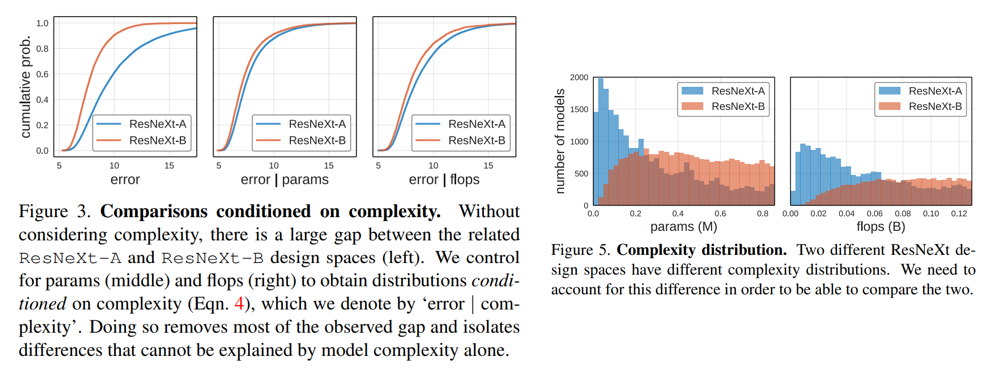
分布评估设计空间相比点估计可以观察到更多的东西,比如分布的形状,如图所示,从ResNet的EDF我们可以看到超过80%的模型误差小于8%,而 Vanilla这一比例只有15%,这说明带有残差连接的结构的绝对性优势。另外前面说过曲线下面积也可以作为一个评价指标。此外,我们也可以比较随机搜索的效率,即找到一个好模型的容易度,从下图可以看到相同的实验量,ResNet比Vanilla找的模型更优。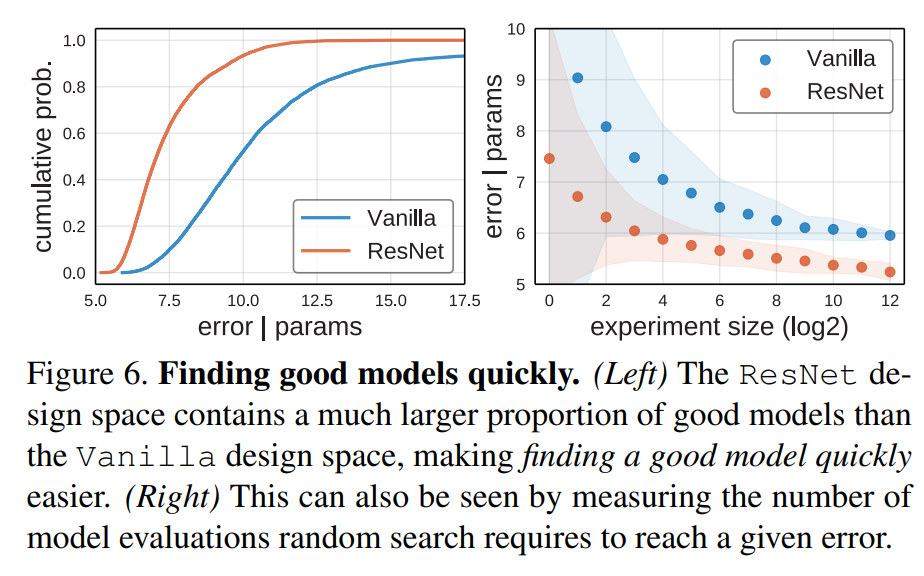 最后一个重要的问题,为了得到可靠的分布估计,所需要的最小抽样量是多少。论文也通过实验证明,100样本就能得到比较合理的分布,而1000个样本和10000个样本得到的分布几乎没有差异了。这说明100~1000个样本是一个比较合理的抽样范围。不过,这个参数应该在不同场景下(数据集,设计空间等)会有差异。
最后一个重要的问题,为了得到可靠的分布估计,所需要的最小抽样量是多少。论文也通过实验证明,100样本就能得到比较合理的分布,而1000个样本和10000个样本得到的分布几乎没有差异了。这说明100~1000个样本是一个比较合理的抽样范围。不过,这个参数应该在不同场景下(数据集,设计空间等)会有差异。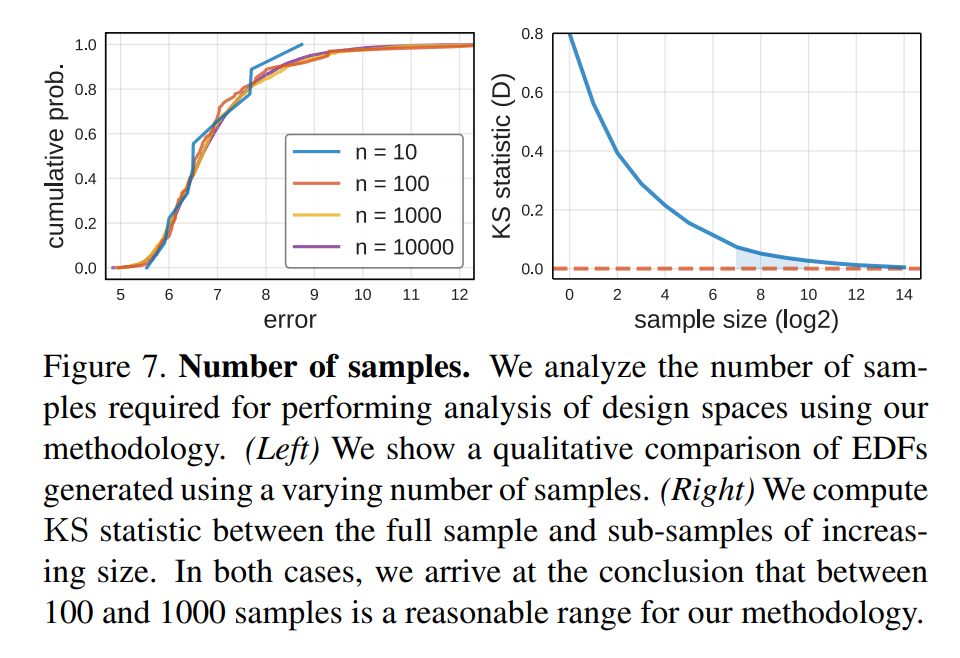 此外,论文也对NAS的设计空间做了分析,采用EDF可以对不同的NAS空间做一个更可靠的评估。
此外,论文也对NAS的设计空间做了分析,采用EDF可以对不同的NAS空间做一个更可靠的评估。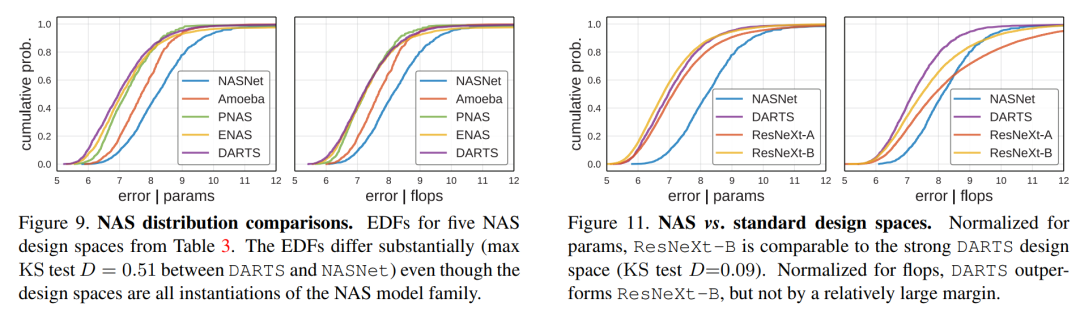
那么如何用分布评估来去设计并优化网络设计空间呢,下期再讲!
参考
On Network Design Spaces for Visual Recognition Designing Network Design Spaces facebookresearch/pycls pytorch/vision
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
