
收藏 | 一文遍览CNN网络结构的发展

来源:人工智能AI技术 本文约2600字,建议阅读8分钟
本文介绍了十五种经典的CNN网络结构。
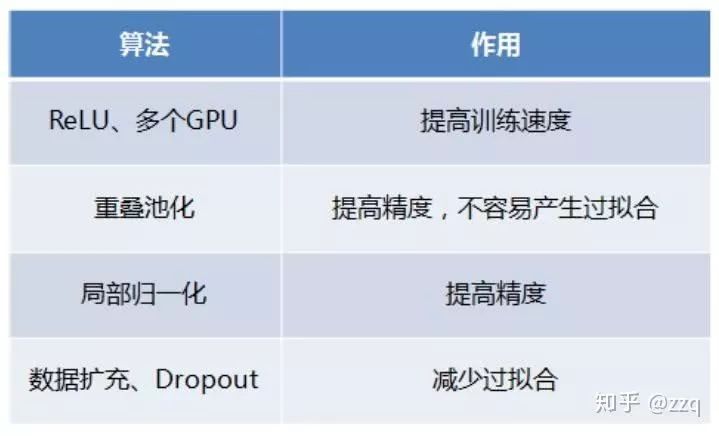
CNN基本部件介绍
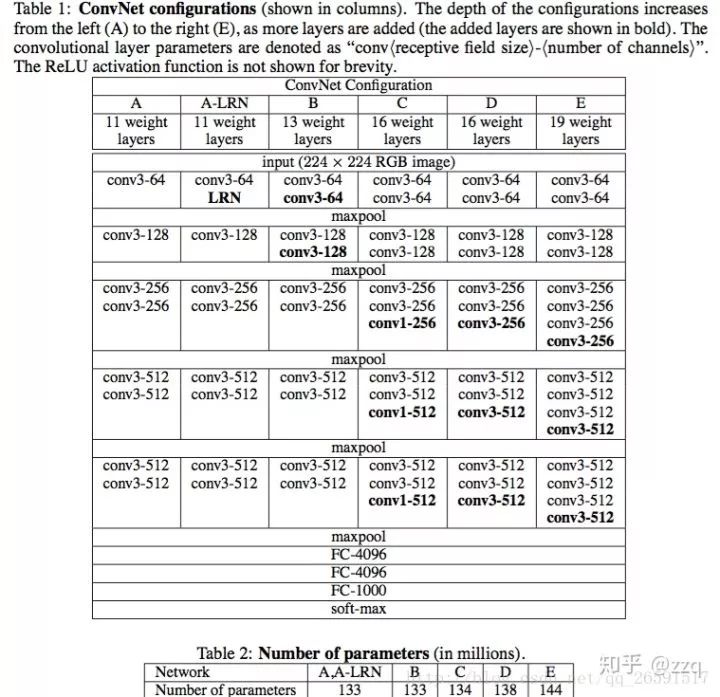
经典网络结构
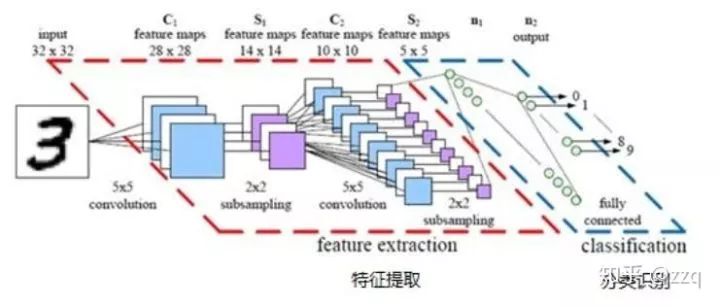

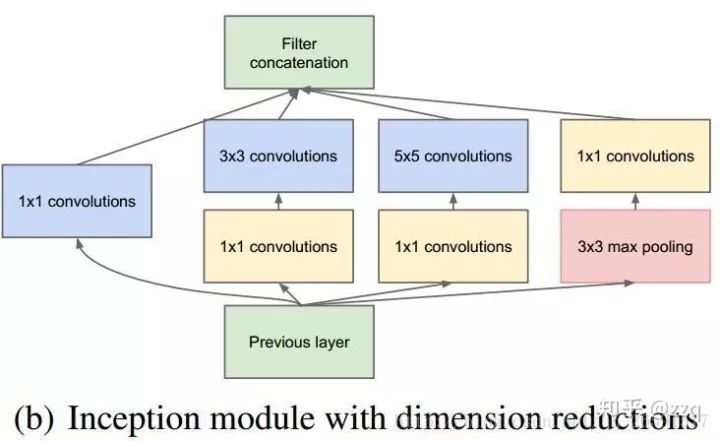
Inception v1
Inception-v2
Inception-v3
Inception-v4
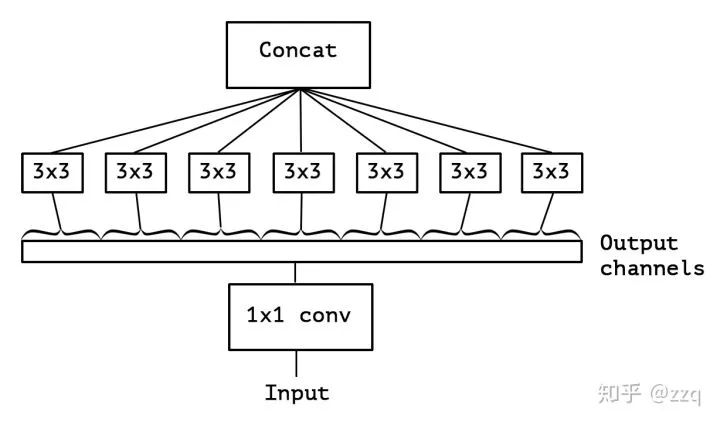
V1
V2
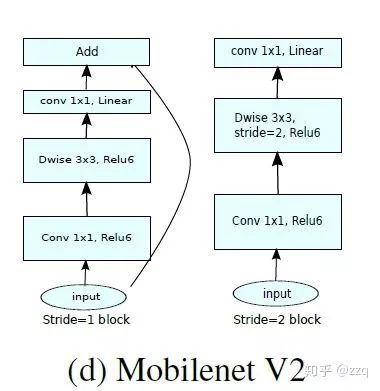
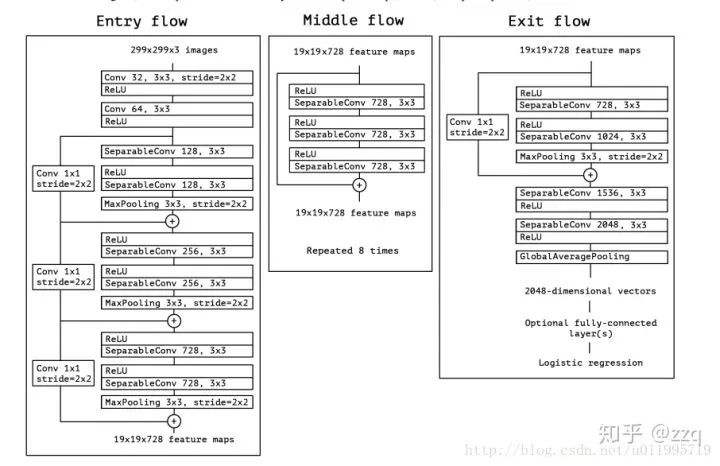
V3
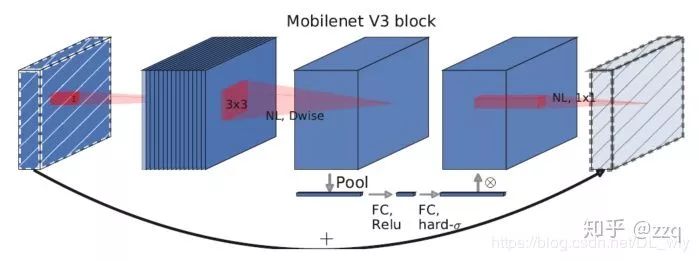
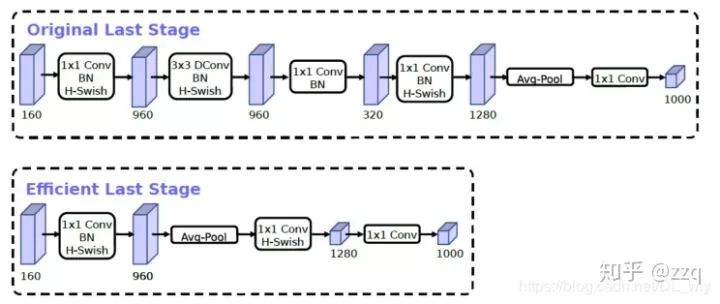
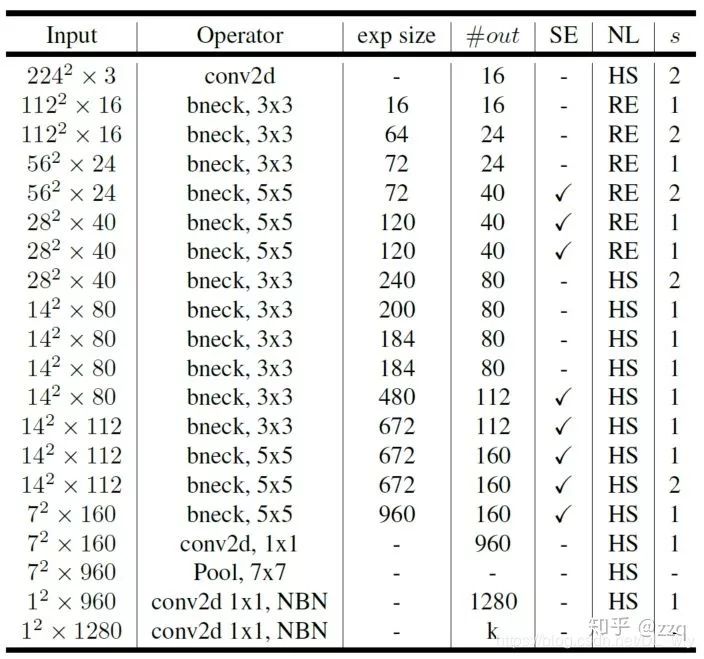
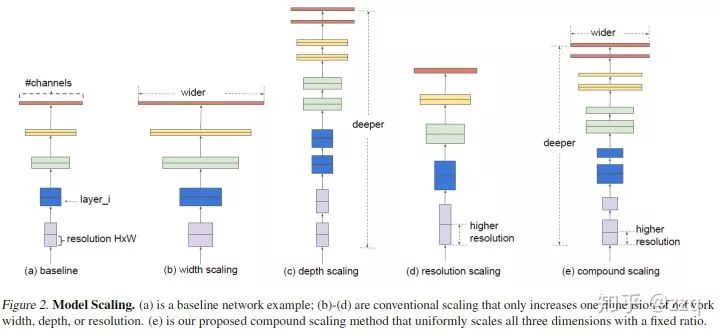
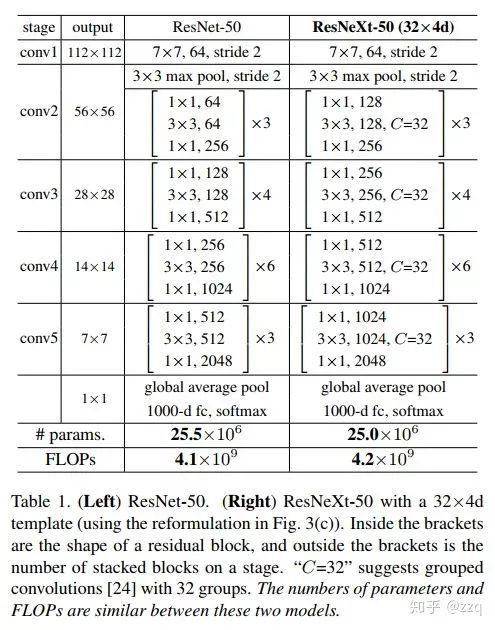
增加网络深度,如从AlexNet到ResNet,但是实验结果表明由网络深度带来的提升越来越小;
增加网络模块的宽度,但是宽度的增加必然带来指数级的参数规模提升,也非主流CNN设计;
改善CNN网络结构设计,如Inception系列和ResNeXt等。
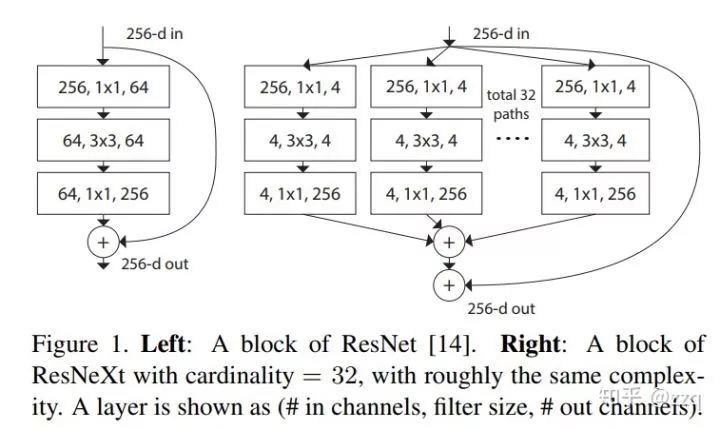
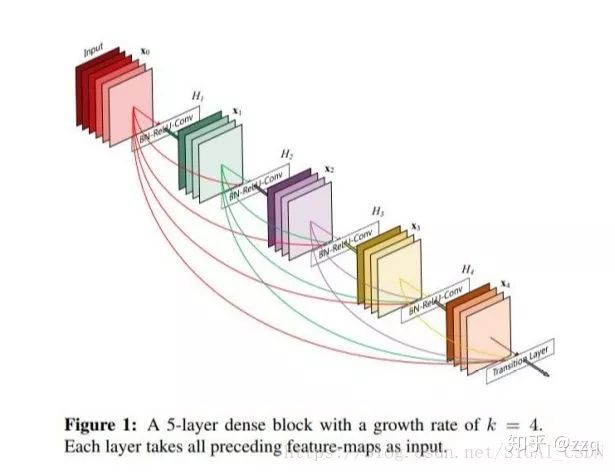
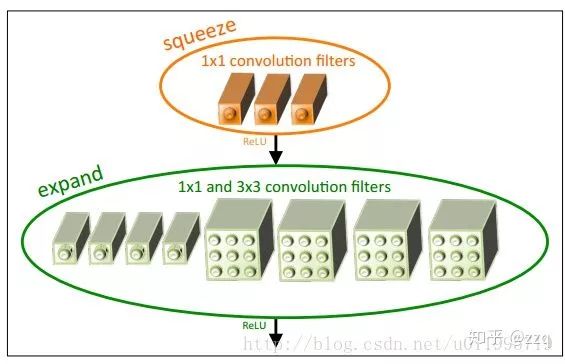
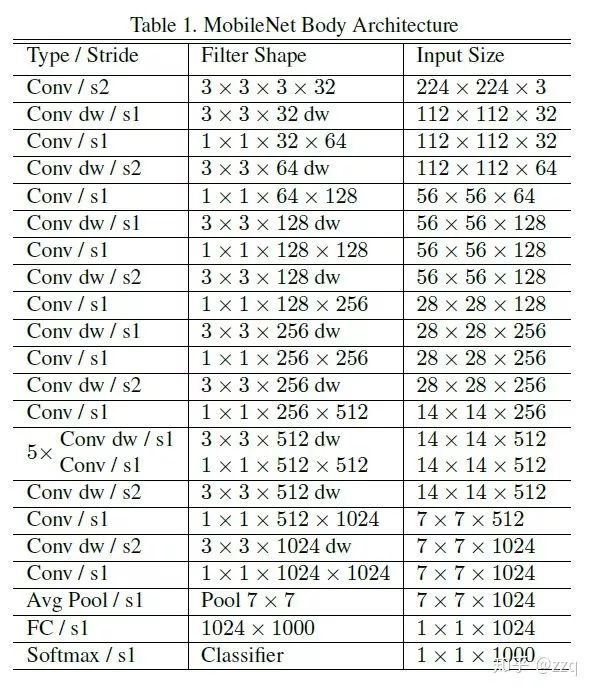
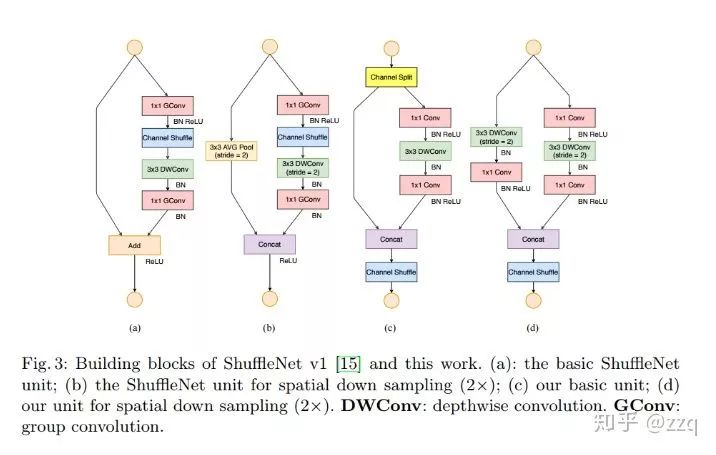
V1
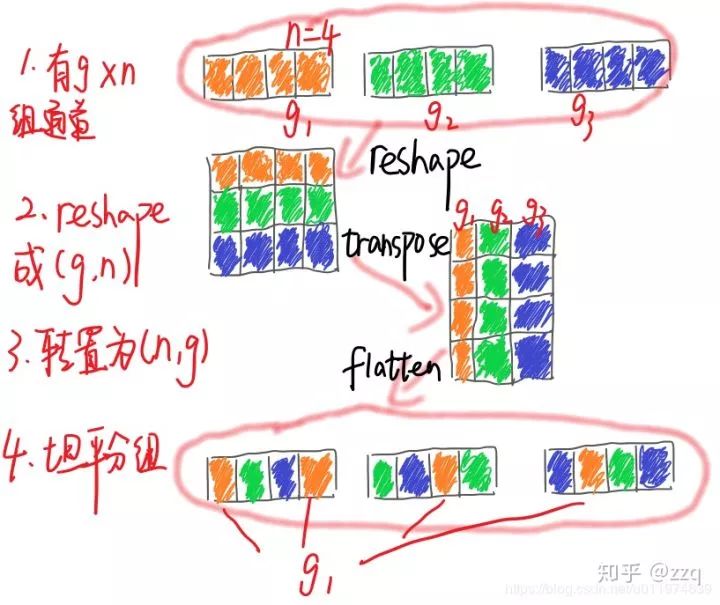
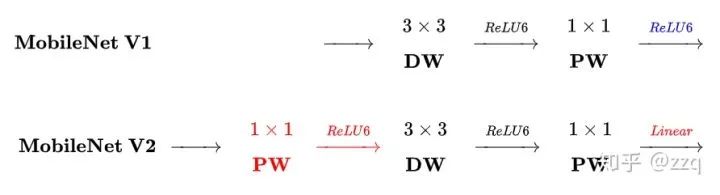
V2
输入通道数与输出通道数保持相等可以最小化内存访问成本;
分组卷积中使用过多的分组会增加内存访问成本;
网络结构太复杂(分支和基本单元过多)会降低网络的并行程度;
element-wise的操作消耗也不可忽略。
评论