
Redis 批量操作 pipeline 模式
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


业务场景
项目中场景需要get一批key的value,因为redis的get操作(不单单是get命令)是阻塞的,如果循环取值的话,就算是内网,耗时也是巨大的。所以想到了redis的pipeline命令。
pipeline简介
非pipeline:client一个请求,redis server一个响应,期间client阻塞
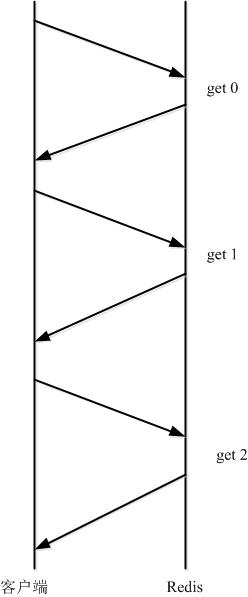
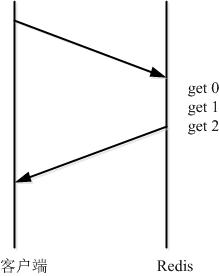
Pipeline:redis的管道命令,允许client将多个请求依次发给服务器(redis的客户端,如jedisCluster,lettuce等都实现了对pipeline的封装),过程中而不需要等待请求的回复,在最后再一并读取结果即可。
单机版
单机版比较简单,批量获取
1//换成真实的redis实例
2Jedis jedis = new Jedis();
3//获取管道
4Pipeline p = jedis.pipelined();
5for (int i = 0; i < 10000; i++) {
6 p.get("key_" + i);
7}
8//获取结果
9List<Object> results = p.syncAndReturnAll();
批量插入
1String key = "key";
2Jedis jedis = new Jedis();
3Pipeline p = jedis.pipelined();
4List<String> cacheData = .... //要插入的数据列表
5for(String data: cacheData ){
6 p.hset(key, data);
7}
8p.sync();
9jedis.close();
集群版
实际上遇到的问题是,项目上所用到的Redis是集群,初始化的时候使用的类是 JedisCluster 而不是 Jedis。去查了 JedisCluster 的文档,并没有发现提供有像 Jedis 一样的获取 Pipeline对象的 pipelined() 方法。解决方案:
Redis 集群规范有说: Redis 集群的键空间被分割为 16384 个槽(slot), 集群的最大节点数量也是 16384 个。每个主节点都负责处理 16384 个哈希槽的其中一部分。当我们说一个集群处于“稳定”(stable)状态时, 指的是集群没有在执行重配置(reconfiguration)操作, 每个哈希槽都只由一个节点进行处理。所以可以根据要插入的 key 知道这个 key 所对应的槽的号码,再通过这个槽的号码从集群中找到对应 Jedis。具体实现如下:
1//初始化得到了jedis cluster, 如何获取HostAndPort集合代码就不写了
2Set nodes = .....
3JedisCluster jedisCluster = new JedisCluster(nodes);
4
5Map<String, JedisPool> nodeMap = jedisCluster.getClusterNodes();
6String anyHost = nodeMap.keySet().iterator().next();
7
8//getSlotHostMap方法在下面有
9TreeMapString > slotHostMap = getSlotHostMap(anyHost);
1private static TreeMapString > getSlotHostMap(String anyHostAndPortStr) {
2 TreeMapString> tree = new TreeMapString>();
3 String parts[] = anyHostAndPortStr.split(":");
4 HostAndPort anyHostAndPort = new HostAndPort(parts[0], Integer.parseInt(parts[1]));
5 try{
6 Jedis jedis = new Jedis(anyHostAndPort.getHost(), anyHostAndPort.getPort());
7 List<Object> list = jedis.clusterSlots();
8 for (Object object : list) {
9 List<Object> list1 = (List<Object>) object;
10 List<Object> master = (List<Object>) list1.get(2);
11 String hostAndPort = new String((byte[]) master.get(0)) + ":" + master.get(1);
12 tree.put((Long) list1.get(0), hostAndPort);
13 tree.put((Long) list1.get(1), hostAndPort);
14 }
15 jedis.close();
16 }catch(Exception e){
17
18 }
19 return tree;
20}
上面这几步可以在初始化的时候就完成。不需要每次都调用, 把nodeMap和slotHostMap都定义为静态变量。
1//获取槽号
2int slot = JedisClusterCRC16.getSlot(key);
3//获取到对应的Jedis对象
4Map.EntryString > entry = slotHostMap.lowerEntry(Long.valueOf(slot));
5Jedis jedis = nodeMap.get(entry.getValue()).getResource();
建议上面这步操作可以封装成一个静态方法。比如命名为 public static Jedis getJedisByKey(String key) 之类的。意思就是在集群中, 通过key获取到这个key所对应的Jedis对象。这样再通过上面的 jedis.pipelined(); 来就可以进行批量插入了。以下是一个比较完整的封装
1import redis.clients.jedis.*;
3import redis.clients.jedis.exceptions.JedisMovedDataException;
4import redis.clients.jedis.exceptions.JedisRedirectionException;
5import redis.clients.util.JedisClusterCRC16;
6import redis.clients.util.SafeEncoder;
7
8import java.io.Closeable;
9import java.lang.reflect.Field;
10import java.util.*;
11import java.util.function.BiConsumer;
12
14public class JedisClusterPipeline extends PipelineBase implements Closeable {
15
16 /**
17 * 用于获取 JedisClusterInfoCache
18 */
19 private JedisSlotBasedConnectionHandler connectionHandler;
20 /**
21 * 根据hash值获取连接
22 */
23 private JedisClusterInfoCache clusterInfoCache;
24
25 /**
26 * 也可以去继承JedisCluster和JedisSlotBasedConnectionHandler来提供访问接口
27 * JedisCluster继承于BinaryJedisCluster
28 * 在BinaryJedisCluster,connectionHandler属性protected修饰的,所以需要反射
29 *
30 *
31 * 而 JedisClusterInfoCache 属性在JedisClusterConnectionHandler中,但是这个类是抽象类,
32 * 但它有一个实现类JedisSlotBasedConnectionHandler
33 */
34 private static final Field FIELD_CONNECTION_HANDLER;
35 private static final Field FIELD_CACHE;
36 static {
37 FIELD_CONNECTION_HANDLER = getField(BinaryJedisCluster.class, "connectionHandler");
38 FIELD_CACHE = getField(JedisClusterConnectionHandler.class, "cache");
39 }
40
41 /**
42 * 根据顺序存储每个命令对应的Client
43 */
44 private Queue clients = new LinkedList<>();
45 /**
46 * 用于缓存连接
47 * 一次pipeline过程中使用到的jedis缓存
48 */
49 private Map jedisMap = new HashMap<>();
50 /**
51 * 是否有数据在缓存区
52 */
53 private boolean hasDataInBuf = false;
54
55 /**
56 * 根据jedisCluster实例生成对应的JedisClusterPipeline
57 * 通过此方式获取pipeline进行操作的话必须调用close()关闭管道
58 * 调用本类里pipelineXX方法则不用close(),但建议最好还是在finally里调用一下close()
59 * @param
60 * @return
61 */
62 public static JedisClusterPipeline pipelined(JedisCluster jedisCluster) {
63 JedisClusterPipeline pipeline = new JedisClusterPipeline();
64 pipeline.setJedisCluster(jedisCluster);
65 return pipeline;
66 }
67
68 public JedisClusterPipeline() {
69 }
70
71 public void setJedisCluster(JedisCluster jedis) {
72 connectionHandler = getValue(jedis, FIELD_CONNECTION_HANDLER);
73 clusterInfoCache = getValue(connectionHandler, FIELD_CACHE);
74 }
75
76 /**
77 * 刷新集群信息,当集群信息发生变更时调用
78 * @param
79 * @return
80 */
81 public void refreshCluster() {
82 connectionHandler.renewSlotCache();
83 }
84
85 /**
86 * 同步读取所有数据. 与syncAndReturnAll()相比,sync()只是没有对数据做反序列化
87 */
88 public void sync() {
89 innerSync(null);
90 }
91
92 /**
93 * 同步读取所有数据 并按命令顺序返回一个列表
94 *
95 * @return 按照命令的顺序返回所有的数据
96 */
97 public List{
98 List 使用例子
1 public Object testPipelineOperate() {
2 // String[] keys = {"dylan1","dylan2"};
3 // String[] values = {"dylan1-v1","dylan2-v2"};
4 // int[] exps = {100,200};
5 // JedisClusterPipeline.pipelineSetEx(keys, values, exps, jedisCluster);
6 long start = System.currentTimeMillis();
7
8 List<String> keyList = new ArrayList<>();
9 for (int i = 0; i < 1000; i++) {
10 keyList.add(i + "");
11 }
12 // List pipeline = JedisClusterPipeline.pipeline(this::getValue, keyList, jedisCluster);
13 // List pipeline = JedisClusterPipeline.pipeline(this::getHashValue, keyList, jedisCluster);
14 String[] keys = {"dylan-test1", "dylan-test2"};
15
16 List<Map<String, String>> all = JedisClusterPipeline.pipelineHgetAll(keys, jedisCluster);
17 long end = System.currentTimeMillis();
18 System.out.println("testPipelineOperate cost:" + (end-start));
19
20 return Response.success(all);
21 }推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!