
基于 Nest.js+TypeORM 实战,项目已开源,推荐!
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
考拉🐨 的 Nest.js 系列文章(系列会持续更新):
学完这篇 Nest.js 实战,还没入门的来锤我!(长文预警)
Nest.js 实战系列第二篇-实现注册、扫码登陆、jwt认证等
这篇文章是上篇实现登录、注册的后续, 本来是和上一篇文章写在一起的, 考虑篇幅问题,就拆了一个下篇出来。
文章主要内容:
有的小伙伴可能觉得文章不就增删改查嘛,没什么好写的吧!
其实在我整体写下来,觉得文章模块还是涉及到很多知识点的,比如分类表与文章表的一对多以及文章表与标签表多对多处理、文件上传等,还有一些实现的小细节:关于文章摘要的提取方式,Markdown转html等,都会在这篇文章中给大家介绍清楚。
前置说明
首先我们说一下文章设计的需求,文章基本信息:标题、封面、摘要、阅读量、点赞量等;文章有分类,一篇只能选择一个分类;一篇文章可以选择多个标签,文章的状态分为草稿和已发布,考虑到后期文章的展示,还给文章设置了推荐标识。
数据表关系
前面文章中已经说了TypeORM建表时,是通过@Entity()装饰的class 映射为数据表, 所以实体中的关系也就是表关系。接下来探索一下如何用TypeORM创建一对一、一对多和多对多的关系。
一对一
一对一指的是表中一条数据仅关联另外一个表中的另一条数据。例如用户表和用户档案表, 一个用户只有一份档案。我们在TypeORM中如何实现user表和info之间这种对一对的关系呢?
// user.entity.ts
@Entity('user')
export class UserEntity {
@PrimaryGeneratedColumn()
id: number;
@Column()
username: string;
@OneToOne(type =>InfoEntity, info => info.user)
@JoinColumn()
info: InformationEntity;
}
info 是 InfoEntity类型的,但是存入在数据库中类型却是 info.id 的类型。从上面代码可以看出, 是通过@OneToOne装饰器来修饰的, 在装饰器中需要指定对方entity的类型,以及指定对方entity的外键。
@JoinColumn必须在且只在关系的一侧的外键上, 你设置@JoinColumn的哪一方,哪一方的表将包含一个relation id和目标实体表的外键。记住,不能同时在二者entity中。
看一下info实体如何实现:
@Entity('info')
export class InfoEntity {
@PrimaryGeneratedColumn()
id: number;
@Column()
idcard: string;
@Column()
gender: string;
...
@OneToOne(type =>UserEntity, user => user.info)
user: UserEntity;
}
以上两个实体映射的数据表如下:
| user表 |
+--------+--------------+-----+-----------------+----------------------+
| Field | Type | Key | Default | Extra |
+--------+--------------+-----+-----------------+----------------------+
| id | int(11) | PRI | NULL | auto_increment |
| name | varchar(255) | | NULL | |
| infoId | int(11) | MUL | NULL | |
+--------+--------------+-----+-----------------+----------------------+
| info表 |
+--------+--------------+-----+-----------------+----------------------+
| Field | Type | Key | Default | Extra |
+--------+--------------+-----+-----------------+----------------------+
| id | int(11) | PRI | NULL | auto_increment |
| idcard | varchar(255) | | NULL | |
| gender | varchar(255) | | NULL | |
+--------+--------------+-----+-----------------+----------------------+
生成的从数据表可以看出,默认生成的"relation id 格式为xxId, 如果你是数据表中希望对其进行重名名, 可以通过@JoinColumn配置,在一对多例子中会实践一下。
一对多
在一对多关系中,表A中的一条记录,可以关联表B中的一条或多条记录。比如:每一个文章分类都可以对应多篇文章,反过来一篇文章只能属于一个分类,这种文章表和分类表的关系就是一对多的关系。
同样我们用代码看看TypeOrm中如何实现这种关系的:
// category.entity.ts
import {PostEntity} from "../../post/post.entity"
@Entity('category')
export class CategoryEntity {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@OneToMany(() => PostEntity, post => post.category)
post: PostEntity[];
}
将@OneToMany添加到post属性中, 并且在@OneToMany中指定对方的类型为PostEntity, 接下来定义文章实体:
// posts.entity.ts
...
import { CategoryEntity } from './../category/entities/category.entity';
@Entity('post')
export class PostsEntity {
@PrimaryGeneratedColumn()
id: number;
@Column({ length: 50 })
title: string;
...
// 分类
@Exclude()
@ManyToOne(() => CategoryEntity, (category) => category.posts)
@JoinColumn({name: "category_id"})
category: CategoryEntity;
}
@ JoinColumn不仅定义了关系的哪一侧包含带有外键的连接列,还允许自定义连接列名和引用的列名。上边文章entity中,就自定义了列名为category_id, 如果不自定义, 默认生成的列名为categoryId。
TypeORM在处理“一对多”的关系时, 将一的主键作为多的外键,即@ManyToOne装饰的属性;这样建表时有最少的数据表操作代价,避免数据冗余,提高效率, 上面的实体关系会生成以下表:
| category表 |
+--------+--------------+-----+-----------------+----------------------+
| Field | Type | Key | Default | Extra |
+--------+--------------+-----+-----------------+----------------------+
| id | int(11) | PRI | NULL | auto_increment |
| name | varchar(255) | | NULL | |
+--------+--------------+-----+-----------------+----------------------+
| post表 |
+-------------+--------------+-----+------------+----------------------+
| Field | Type | Key | Default | Extra |
+-------------+--------------+-----+------------+----------------------+
| id | int(11) | PRI | NULL | auto_increment |
| title | varchar(50) | | NULL | |
| category_id | int(11) | | NULL | |
+-------------+--------------+-----+------------+----------------------+
最后再看一下多对多的关系。
多对多
在多对多关系中, 表A的中的记录可能与表B中一个或多个的记录相关联。例如,文章和标签你之间存在多对多的关系:一篇文章可以有多个标签, 一个标签页可以对应多篇文章。
// posts.entity.ts
...
import { TagEntity } from './../tag/entities/tag.entity';
@Entity('post')
export class PostsEntity {
@PrimaryGeneratedColumn()
id: number;
@Column({ length: 50 })
title: string;
...
// 标签
@ManyToMany(() => TagEntity, (tag) => tag.posts)
@JoinTable({
name: 'post_tag',
joinColumns: [{ name: 'post_id' }],
inverseJoinColumns: [{ name: 'tag_id' }],
})
tags: TagEntity[];
标签表实体:
// tag.entity.ts
...
import { PostsEntity } from 'src/posts/posts.entity';
@Entity('tag')
export class TagEntity {
@PrimaryGeneratedColumn()
id: number;
@Column({ length: 50 })
name: string;
...
@ManyToMany(() => PostsEntity, (post) => post.tags)
posts: Array<PostsEntity>;
@JoinTable用于描述“多对多”关系, 并描述中间表表的连接列。中间表是通过TypeORM 自动创建的一个特殊的单独表, 其中包含引用相关实体的列。通过配置joinColumns和inverseJoinColumns来自定义中间表的列名称。
注意:新版中是
joinColumns和inverseJoinColumns, 之前的版本是joinColumn没有s
上面的实体关系会生成以下表:
| post表 |
+-------------+--------------+-----+------------+----------------------+
| Field | Type | Key | Default | Extra |
+-------------+--------------+-----+------------+----------------------+
| id | int(11) | PRI | NULL | auto_increment |
| title | varchar(50) | | NULL | |
| category_id | int(11) | | NULL | |
+-------------+--------------+-----+------------+----------------------+
| tag表 |
+-------------+--------------+-----+------------+----------------------+
| Field | Type | Key | Default | Extra |
+-------------+--------------+-----+------------+----------------------+
| id | int(11) | PRI | NULL | auto_increment |
| name | varchar(50) | | NULL | |
| category_id | int(11) | | NULL | |
+-------------+--------------+-----+------------+----------------------+
| post_tag表 |
+-------------+--------------+-----+------------+----------------------+
| Field | Type | Key | Default | Extra |
+-------------+--------------+-----+------------+----------------------+
| tag_id | int(11) | PRI | NULL | auto_increment |
| post_id | int(11) | | NULL | |
+-------------+--------------+-----+------------+----------------------+
从上面生成的表不难得出,TypeORM处理多对多的方式是,将其转化为两个一对多的关系:
-
文章表 post 与 中间表 post_tag 一对多 -
标签表 tag 与中间表 post_tag 也是一对多
小结
前面我们学习了TypeORM 中是如何处理一对一、一对多以及多对多的关系,做一个简单的总结。
关系装饰器:
-
@OneToOne: 用于描述一对一关系 -
@ManyToOne、@OneToMany:用于描述一对多关系,OneToMany总是反向的,并且总是与ManyToOne成对出现。 -
@ManyToMany: 用于描述多对多关系 -
@JoinColumn:定义关系哪一侧带外键的连接列,可以自定义连接列名称和引用的列名称 -
@JoinTable:用于描述“多对多”关系, 并描述中间表表的连接列
文章接口实现
这里简单了绘制一个实体关系图,方便理解一下我们要定义的实体有哪些:
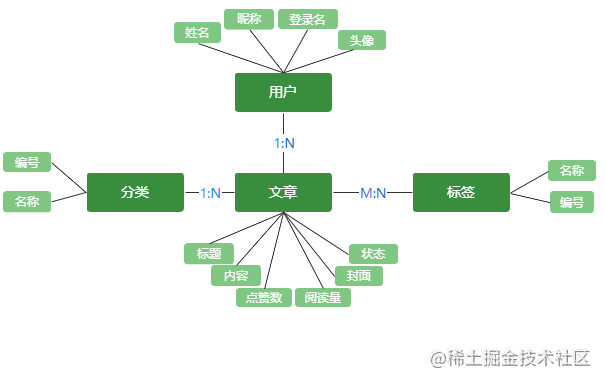
从图中可以看出,需要定义用户 User、 分类Category、标签Tag 以及文章Post 实体,其中User和Category与 Post是一对多关系,而Tag与Post是多对多。
我们要实现的接口:
-
创建文章 -
获取全部文章列表 -
通过分类/标签/作者获取文章列表 -
根据月份对文章归档 -
获取文章详情 -
更新阅读量/点赞量 -
关键词搜索文章
实体定义
上一篇文章实现登录注册时, 以及完成用户实体定义,这里就不赘述,主要介绍一下文章实体:
@Entity('post')
export class PostsEntity {
@PrimaryGeneratedColumn()
id: number; // 标记为主列,值自动生成
// 文章标题
@Column({ length: 50 })
title: string;
// markdown内容
@Column({ type: 'mediumtext', default: null })
content: string;
// markdown 转 html,自动生成
@Column({ type: 'mediumtext', default: null, name: 'content_html' })
contentHtml: string;
// 摘要,自动生成
@Column({ type: 'text', default: null })
summary: string;
// 封面图
@Column({ default: null, name: 'cover_url' })
coverUrl: string;
// 阅读量
@Column({ type: 'int', default: 0 })
count: number;
// 点赞量
@Column({ type: 'int', default: 0, name: 'like_count' })
likeCount: number;
// 推荐显示
@Column({ type: 'tinyint', default: 0, name: 'is_recommend' })
isRecommend: number;
// 文章状态
@Column('simple-enum', { enum: ['draft', 'publish'] })
status: string;
// 作者
@ManyToOne((type) => User, (user) => user.posts)
author: User;
// 分类
@Exclude()
@ManyToOne(() => CategoryEntity, (category) => category.posts)
@JoinColumn({
name: 'category_id',
})
category: CategoryEntity;
// 标签
@ManyToMany(() => TagEntity, (tag) => tag.posts)
@JoinTable({
name: 'post_tag',
joinColumns: [{ name: 'post_id' }],
inverseJoinColumns: [{ name: 'tag_id' }],
})
tags: TagEntity[];
@Column({ type: 'timestamp', name: 'publish_time', default: null })
publishTime: Date;
@Column({ type: 'timestamp', default: () => 'CURRENT_TIMESTAMP' })
create_time: Date;
@Column({ type: 'timestamp', default: () => 'CURRENT_TIMESTAMP' })
update_time: Date;
}
这里我将文章字段都列出来, 其中contentHtml和summary是通过用户传入的文章内容自动生成的,publishTime是文章状态为发布publish时才会添加相应的值, 这些字段都是在新增/更新文章时单独处理的。
新增文章实现
新增文章这里涉及到的逻辑,我们一一进行拆分:
首先,新增文章并不是任何人都可以创建的, 首先必须登录,所以我们需要校验token, 其次用户角色必须是admin或者root才可行, 如果是visitor游客, 那没有权限创建。
接着,我们需要对字段进行验证,文章title是必传的,如果没有不能创建;其次文章标题重复时,不能新增,所有需要先查询要新增的文章是否存在。
然后需要对分类和标签的插入进行处理,同时还需要判断status是草稿draft还是发布publish, 如果是publish,需要设置publishTime为当前时间。
顺着这个思路, 我们来实现一下这个接口, 首先判断用户有没有新增文章的权限
定义授权守卫RoleGuard
其实我们常说的鉴权本质上分为两步:
-
认证(identification): 检查用户是否为合法用户,用于确认用户的身份。这一步不会跟权限扯上关系, 比如上一篇文章登录认证实现的登录获取
token -
授权(authorization):通过
认证的用户, 获得相应的角色。不同的角色具有不同的权限。比如游客不能写文章、只有查看、点赞的权限
那我们就需要处理授权, 知道通过认证的用户到底有没有操作权限。怎么来实现呢?这里我们使用Nestjs中的守卫Guard来实现。
守卫的本质也是中间件的一种, 如果当前请求是不被允许的,当前中间将不会调用后续中间件, 达到阻断请求的目的。
-
在 auth模块中创建role.guard.ts文件,定义基于角色的身份验证的路由守卫,中间件都需要用@Injectable()装饰器处理,需要实现一个canActivate接口。
// role.guard.ts
...
@Injectable()
export class RolesGuard implements CanActivate {
constructor(
private readonly reflector: Reflector,
private readonly jwtService: JwtService,
) {}
canActivate(context: ExecutionContext): boolean {
// 获取路由角色
const roles = this.reflector.get('roles', context.getHandler());
if (!roles) {
return true;
}
// 读取user
const req = context.switchToHttp().getRequest();
const user = req.user;
if (!user) {
return false;
}
// 判断用户的角色是否包含和roles相同的角色列表,并返回一个布尔类型
const hasRoles = roles.some((role) => role === user.role);
return hasRoles;
}
}
-
定义一个角色装饰器 @Roles, 在role.guard.ts中实现:
export const Roles = (...roles: string[]) => SetMetadata('roles', roles);
-
在路由控制器中使用授权守卫 RoleGuard, 通过@Roles装饰器设置可访问路由的角色admin和root:
// posts.controller.ts
@ApiOperation({ summary: '创建文章' })
@ApiBearerAuth()
@Post()
@Roles('admin', 'root')
@UseGuards(AuthGuard('jwt'), RolesGuard)
async create(@Body() post: CreatePostDto, @Req() req) {
return await this.postsService.create(req.user, post);
}
一个完整授权守卫的从定义到使用就完全实现了,实现的功能是:根据获取当前用户的角色与当前正在处理的路径所需的实际角色进行比较,判断其是否满足条件。
对上面代码实现进行简单分析:
-
为了获得路径设置的可访问角色,定义了
@Roles装饰器, 并使用Reflector辅助类获取(它由框架提供, 并从@nestjs/core中导入) -
因为授权之前首先需要对
token进行认证, 认证通过后才会进入角色授权守卫 -
通 request对象可以获取到user -
使用守卫时认证在前 @UseGuards(AuthGuard('jwt'), RolesGuard) -
判断当前用户的角色是否包含在路由要求的角色列表中
-
存在, 返回true,进入请求 -
不存在, 返回false,阻断请求, 并抛出一个 ForbiddenException异常, 你也可以自定义抛出异常。
业务逻辑实现
// posts.service.ts
async create(user, post: CreatePostDto): Promise<number> {
const { title } = post;
if (!title) {
throw new HttpException('缺少文章标题', HttpStatus.BAD_REQUEST);
}
const doc = await this.postsRepository.findOne({
where: { title},
});
if (doc) {
throw new HttpException('文章已存在', HttpStatus.BAD_REQUEST);
}
let { tag, category = 0, status, isRecommend, coverUrl } = post;
// 根据分类id获取分类
const categoryDoc = await this.categoryService.findById(category);
// 根据传入的标签id,如 `1,2`,获取标签
const tags = await this.tagService.findByIds(('' + tag).split(','));
const postParam: Partial<PostsEntity> = {
...post,
isRecommend: isRecommend ? 1 : 0,
category: categoryDoc,
tags: tags,
author: user,
};
// 判断状态,为publish则设置发布时间
if (status === 'publish') {
Object.assign(postParam, {
publishTime: new Date(),
});
}
const newPost: PostsEntity = await this.postsRepository.create({
...postParam,
});
const created = await this.postsRepository.save(newPost);
return created.id;
}
联表查询
以获取全部文章列表为例,这个接口实现主要的点在于多表关联查询的实现, 首先需要认识一下多表关联查询怎么实现。介绍三种 TypeORM提供的多表关联查询方式
-
Find选项 -
Query Builder -
原生SQL
find 选项
所有存储库和管理器查找方法都接受特殊选项,您可以使用这些选项查询所需的数据:
查询所有文章(不涉及到关联关系)
const postRepository = connect.getRepository(PostsEntity)
const result = await postRepository.find()
执行的SQL类似于:
select * from post
使用select指定要查询的字段:
const postRepository = connect.getRepository(PostsEntity)
const result = await postRepository.find({select:["id","title"]})
执行的SQL类似:
select id, title from post
查询条件是通过where来指定, 这里就不一一进行演示,直接看多表关联find应该如何查询, 通过relations指定关联查询(前提是先有外键关联关系):
const postRepository = connect.getRepository(PostsEntity)
const result = await postRepository.find({relations:["author"]})
执行的SQL类似
select a.*, b.* from post as a left join user as b on a.authorId = b.id
除了find选项实现查询,TypeORM还提供了一种QueryBilder方式。
QueryBilder 相关
find操作起来很简洁,但是无法应对所以场景:
QueryBuilder是 TypeORM 最强大的功能之一 ,它让我们可以使用优雅便捷的语法构建 SQL 查询,执行并获得自动转换的实体。
有三种方式可以创建QueryBuilder:
// 1. 使用 connection:
import { getConnection } from "typeorm";
const user = await getConnection()
.createQueryBuilder()
.select("user")
.from(User, "user")
.where("user.id = :id", { id: 1 })
.getOne();
// 2. 使用 entity manager:
import { getManager } from "typeorm";
const user = await getManager()
.createQueryBuilder(User, "user")
.where("user.id = :id", { id: 1 })
.getOne();
// 3.使用 repository:
import { getRepository } from "typeorm";
const user = await getRepository(User)
.createQueryBuilder("user")
.where("user.id = :id", { id: 1 })
.getOne();
QueryBilder中实现连表查询的常用方法是leftJoinAndSelect,看看如何使用的:
const posts = await this.postsRepository
.createQueryBuilder('post')
.leftJoinAndSelect('post.tags','tag')
.getMany()
查询结果:
[
{
id: 46,
title: '文章1'
content: '测试文章内容输入....',
...
tags: [
{
id: 1,
name: 'vue'
},{
id: 9,
name: 'vuex'
}]
}...]
从结果可以看出leftJoinAndSelect自动加载了文章1的所有标签tags。
leftJoinAndSelect第一个参数是要加载的关系, 第二个参数是为此关系的表分配的别名。后面可以在查询构建器中的任何位置使用此别名。例如, 筛选有标签名为node的文章:
const posts = await this.postsRepository
.createQueryBuilder('post')
.leftJoinAndSelect('post.tags','tag')
.where('tag.name=:name', { name: 'node' });
.getMany()
SQL原生语句
利用以上对find和QueryBilder知识点的学习, 可以实现获取文章列表的接口, 这里我使用的是QueryBilder方式, 源码文件中,也有find方式的实现, 感兴趣的小伙伴自己下载源码看。
async findAll(query): Promise<PostsRo> {
const qb = await this.postsRepository
.createQueryBuilder('post')
.leftJoinAndSelect('post.category', 'category')
.leftJoinAndSelect('post.tags', 'tag')
.leftJoinAndSelect('post.author', 'user')
.orderBy('post.updateTime', 'DESC');
qb.where('1 = 1');
qb.orderBy('post.create_time', 'DESC');
const count = await qb.getCount();
const { pageNum = 1, pageSize = 10, ...params } = query;
qb.limit(pageSize);
qb.offset(pageSize * (pageNum - 1));
let posts = await qb.getMany();
const result: PostInfoDto[] = posts.map((item) => item.toResponseObject());
return { list: result, count: count };
}
在上面代码中使用到了toResponseObject实例方法来整理返回数据的格式,这方法是在posts.entity.ts中定义的, 因为在很多返回文章数据的地方都需要对数据进行格式化,比如,直接查询出来的结果,标签是嵌套的数组对象, 而前端只需要显示标签,我们直接返回多个标签名就可以了,同理,联表查询出来的user、category等数据都是嵌套的,我们也需要进行处理。
// posts.entity.ts
toResponseObject(): PostInfoDto {
let responseObj: PostInfoDto = {
...this,
isRecommend: this.isRecommend ? true : false,
};
if (this.category) {
responseObj.category = this.category.name;
}
if (this.tags && this.tags.length) {
responseObj.tags = this.tags.map((item) => item.name);
}
if (this.author && this.author.id) {
responseObj.userId = this.author.id;
responseObj.author = this.author.nickname || this.author.username;
}
return responseObj;
}
最后我们查询出来的数据的格式就清爽多了(省略了一些字段显示) :
{
"data": {
"list": [
{
"id": 47,
"title": "2323232",
"content": "string",
"status": "publish",
"category": "前端",
"tags": [ "JavaScript","node"],
"author": "admin",
"userId": "d2244619-f6a9-4bb2-b00f-b809eb9a458a"
}
],
"count": 7
},
"code": 0,
"msg": "请求成功"
}
文章阅读量
对于文章阅读量计数,我们这里采用的方案是,获取文章详情时,阅读量+1。首先表明这个实现只是一个过渡方案,虽然实现简单, 但是有几个问题:
-
当有大量的人同时阅读这个内容的时候,可能涉及到加锁的问题 -
当流量较大时,同时读取和修改同一条数据, 对数据库压力来说压力很大 -
同一个人不停的属性页面,也容易导致数据准确率不高
针对上面的问题是有解决方案的, 可以通过redis很方便的解决, 鉴于部分小伙伴对redis不甚了解, 所以后面会单独用一篇文章来将redis, 以及在我们项目中的应用,
阅读量+1实现
在posts.service.ts中业务代码实现:
async findById(id): Promise<any> {
const qb = this.postsRepository
.createQueryBuilder('post')
.leftJoinAndSelect('post.category', 'category')
.leftJoinAndSelect('post.tags', 'tag')
.leftJoinAndSelect('post.author', 'user')
.where('post.id=:id')
.setParameter('id', id);
const result = await qb.getOne();
if(!result) throw new HttpException(`id为${id}的文章不存在`, HttpStatus.BAD_REQUEST);
await this.postsRepository.update(id, {count: result.count+1})
return result.toResponseObject();
}
上传文件到COS
在前面文章实体定义中有文章封面coverUrl字段,文章封面我们不是直接上传到服务器的,而是使用腾讯云的对象存储cos。
我们都知道在前端实现文件上传,但是将SecretId和SecretKey暴露在前端页面, 很容易泄露,存在严重的安全隐患, 所以上传文件到腾讯云COS还是放在后端去实现更合理。
为了节省资源以及资源复用,在上传图片时,计算图片MD5值对比文件是否已经存在,如果存在则不再上传,而是返回查询到的文件地址。
文件上传过程实现流程:
-
首先获取到上传的文件 -
根据文件后缀判断文件类型,指定上传文件的路径(将不同的文件类型上传到对应的文件夹中) -
MD5加密文件生成字符串,对文件进行命名 -
查询文件是否已存在于COS中 -
存在,则拼接文件路径返回 -
不存在, 调用腾讯api将文件上传到cos中
Nest内置文件上传
为了处理文件上传, Nest.js为Express提供了一个基于multer中间件包的内置模块,Multer 处理以 multipart/form-data 格式发布的数据,该格式主要用于通过 HTTP POST 请求上传文件。
我们无需再安装multer, 为了有更好的代码提示和类型检查,最好安装一下类型包:
npm i -D @types/multer
要实现单个文件上传,只需要将FileInterceptor()拦截器绑定到路由, 然后使用@UploadFile装饰器从请求中提取文件。
@Post('upload')
@ApiOperation({ summary: '上传文件' })
@ApiConsumes('multipart/form-data')
@UseInterceptors(FileInterceptor('file'))
async uploadFile(@UploadedFile('file') file: Express.Multer.File) {
return await this.appService.upload(file);
}
这样我们就可以获取到上传的文件,此时我们获取到的文件如下:
{
fieldname: 'file',
originalname: '1636192811zfb.jpg',
encoding: '7bit',
mimetype: 'image/jpeg',
buffer: <Buffer 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 00 00 01 96 00 00 02 44 08 06 00 00 00 35 e6 02 2f 00 00 00 01 73 52 47 42 00 ae ce 1c e9 00 00 00 04 ... 62223 more bytes>,
size: 62273
}
但是我们想要对文件的名字以及后缀名进行一下处理,怎么实现呢?
方式一:放到service中去处理,这种方式没什么多说点的~
说说另一种方式, 就是通过配置multer的diskStorage,让上传的文件带有后缀名且名字根据MD5加密。
代码实现:
const image = ['gif', 'png', 'jpg', 'jpeg', 'bmp', 'webp'];
const video = ['mp4', 'webm'];
const audio = ['mp3', 'wav', 'ogg'];
...
@UseInterceptors( FileInterceptor('file', {
storage: multer.diskStorage({
// 配置上传后文件存储位置
destination: (req, file, cb) => {
// 根据上传的文件类型将图片视频音频和其他类型文件分别存到对应英文文件夹
const mimeType = file.mimetype.split('/')[1];
let temp = 'other';
image.filter((item) => item === mimeType).length > 0
? (temp = 'image')
: '';
video.filter((item) => item === mimeType).length > 0
? (temp = 'video')
: '';
audio.filter((item) => item === mimeType).length > 0
? (temp = 'audio')
: '';
const filePath = `${config.fileTempPath}${temp}`;
// 判断文件夹是否存在,不存在则自动生成
if (!fs.existsSync(filePath)) {
fs.mkdirSync(filePath);
}
return cb(null, `${filePath}`);
},
// 配置文件名称
filename: async (req, file, cb) => {
const index = file.originalname.lastIndexOf('.');
const md5File = await getMd5File(file);
//获取后缀
const ext = file.originalname.substr(index);
cb(null, md5File + ext);
},
}),
}),
)
其中对文件MD5加密实现如下,使用的是crypto来进行加密:
function getMd5File(file) {
const buffer =Buffer.from(JSON.stringify(file), 'utf-8')
const md5File = crypto
.createHash('md5')
.update(JSON.stringify(buffer))
.digest('hex');
return md5File
}
获取到利用MD5加密的文件名后, 接下来就是对接腾讯云对象API, 主要使用两个API:文件上传和文件对象获取
腾讯云存储文件
首先我们需要有腾讯云账号, 并且开通对象存储功能,拿到对象存储的SecretId和SecretKey
首先安装腾讯云提供的Node.js版本的SDK, cos-nodejs-sdk-v5
npm install cos-nodejs-sdk-v5 --save
初始化COS对象, 需要使用SecretId和SecretKey, 我这里是将这两个变量写在.env文件中的:
const { env } = process;
...
const cos = new COS({
SecretId: env.TXSecretId,
SecretKey: env.TXSecretKey,
});
文件上传实现:
async uploadFile(cosName: string, localPath: string): Promise<UploadFileRo> {
return new Promise((resolve, reject) => {
const params = {
Bucket: env.Bucket,
Region: env.Region,
Key: this.cosPath + cosName, // cos 图片地址
FilePath: localPath /* 必须 ,本地地址*/,
SliceSize: 1024 * 1024 * 2 /* 超过2MB使用分块上传,非必须 */,
};
cos.uploadFile({
...params,
onFileFinish: (err, data, options) => {
console.log(options.Key + '上传' + (err ? '失败' : '完成'));
}},
(err, data) => {
// 删除本地文件
fs.unlinkSync(localPath);
if (err) throw new HttpException(err, 401);
resolve({
url: 'https://' + data.Location,
filename: cosName,
} as UploadFileRo);
},
);
});
}
调用cos的uploadFile方法, 参数说明:
-
Bucket: 存储桶的名称 -
Region:存储桶所在地域 -
Key: 对象在存储桶中的唯一标识, 需要注意包含存储桶中的路径,不仅仅是文件名称 -
FilePath: 上传的文件所在路径 -
SliceSize:设置分块上传大小
最后,记得删除存在服务器上的文件, 否则文件会越来越多,占用空间。这里还可进行优化
获取文件对象
async getFile(filename: string, localPath: string): Promise<UploadFileRo> {
return new Promise((resolve, reject) => {
cos.getBucket({
Bucket: env.Bucket,
Region: env.Region,
Prefix: this.cosPath + filename},
(err, data) => {
// 删除本地文件
fs.unlinkSync(localPath);
if (err) {
reject(err);
throw new HttpException(err, 401);
}
// 文件已存在
if (data.Contents && data.Contents.length > 0) {
resolve({ url: this.urlPrefix + this.cosPath + filename })
} else {
resolve({ url: '' });
}
}
);
});
}
当获取到文件时,拼装文件地址返回。前面已经实现了文件上传到腾讯云以及获取, 最后需要做的就是判断什么时机调用上传。
首先必须调用获取文件对象方法getFile判断当前文件是否已经在腾讯云COS中已存在,如果已经存在,直接返回结果, 反之进行上传, 在app.service.ts文件中实现:
import { CosService, UploadFileRo } from './core/shared-service/cos.service';
@Injectable()
export class AppService {
constructor(private readonly cosService: CosService) {}
async upload(file): Promise<UploadFileRo> {
// 判断文件是否存在
const existFile = await this.cosService.getFile(file.filename, file.path);
if (existFile.url) {
return existFile;
}
return await this.cosService.uploadFile(file.filename, file.path);
}
}
单文件上传至腾讯云就实现了, 可以思考一下多文件上传如何实现~
关于文章模块的实现还有使用中间件实现自动生成文章摘要以及markdown转html, 实现比较简单,篇幅太长就不一一的介绍了, 可以在源码中查看(文末有源码获取方式)。
公众号回复【Nest.js】 获取源码
总结
回顾一下【Nest入门系列文章】
预告一下接下来【Nest.js进阶系列文章】,会对Nest.js的核心知识点进行详细拆解,结合Redis解决我们入门系列文章中留下的坑,并且对数据库操作高级应用的讲解。
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
如果你觉得这篇内容对你有帮助,我想请你帮我2个小忙:
1. 点个「在看」,让更多人也能看到这篇文章
2. 订阅官方博客 www.inode.club 让我们一起成长
参考链接:
微信扫码登录背后的实现原理:https://juejin.cn/post/6881597417637511181
TypeOrm操作数据库:https://segmentfault.com/a/1190000040207165
点赞和在看就是最大的支持❤️