
深度学习在图像处理中的应用一览
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:人工智能与算法学习
计算机视觉的底层,图像处理,根本上讲是基于一定假设条件下的信号重建。这个重建不是3-D结构重建,是指恢复信号的原始信息,比如去噪声。这本身是一个逆问题,所以没有约束或者假设条件是无解的,比如去噪最常见的假设就是高斯噪声。
以前最成功的方法基本是信号处理,传统机器学习也有过这方面的应用,只是信号处理的约束条件变成了贝叶斯规则的先验知识,比如稀疏编码(sparse coding)/字典学习(dictionary learning),MRF/CRF之类。下面讨论基于深度学习的方法。
以DnCNN和CBDNet为例介绍如何将深度学习用于去噪声。
• DnCNN
最近,由于图像去噪的鉴别模型学习性能引起了关注。去噪卷积神经网络(DnCNNs)将深度结构、学习算法和正则化方法用于图像去噪。
如图是DnCNN架构图。给定深度为D的DnCNN,有三种层。(i)Conv + ReLU:第一层,64个大小为3×3×c的滤波器生成64个特征图,然后是ReLU,这里c表示图像通道数,灰度图像c = 1,彩色图像c = 3。(ii)Conv + BN + ReLU:层2~(D-1),64个大小为3×3×64的滤波器,在卷积和ReLU之间添加BN。(iii)Conv:最后一层,c个尺寸3×3×64滤波器来重建输出。
DnCNN采用残差学习训练残差映射R(y)≈v,然后得到x = y - R(y)。DnCNN模型有两个主要特征:采用残差学习来学习R(y),并结合BN来加速训练以及提高去噪性能。卷积与ReLU结合,DnCNN通过隐层逐渐将图像结构与噪声干扰的观测分开。这种机制类似于EPLL和WNNM等方法中采用的迭代噪声消除策略,但DnCNN以端到端的方式进行训练。
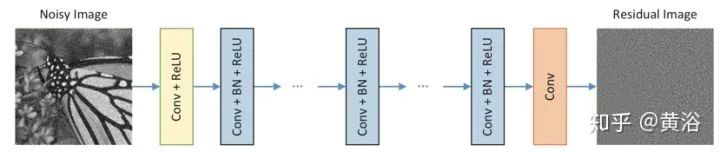
图中的网络可用于训练原始映射F(y)以预测x或残差映射R(y)以预测v。当原始映射更像是个体映射,残差映射将更容易优化。注意,噪声观察y更像是潜在干净图像x而不是残差图像v(特别是噪声水平低)。因此,F(y)将比R(y)更接近于个体映射,并且残差学习公式更适合于图像去噪。
• CBD-Net
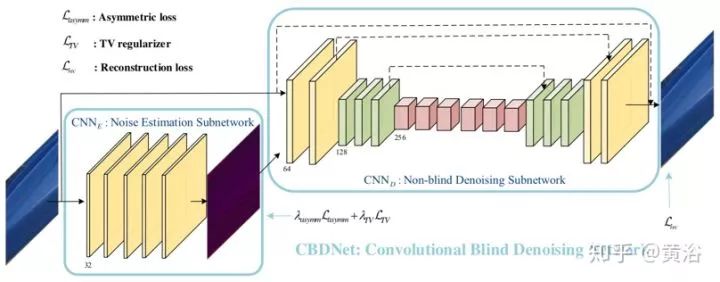
为了提高深度去噪模型的鲁棒性和实用性,卷积盲去噪网络(CBD-Net,convolutional blind denoising network)结合了网络结构、噪声建模和非对称学习几个特点。CBD-Net由噪声估计子网和去噪子网组成,使用更逼真的噪声模型进行训练,考虑到信号相关噪声和摄像头内处理流水线。非盲去噪器(例如著名的BM3D)对噪声估计误差的不对称灵敏度,可以使噪声估计子网抑制低估的噪声水平。为了使学习的模型适用于真实图像,基于真实噪声模型的合成图像和几乎无噪声的真实噪声图像合并后训练CBDNet。
如图是CBDNet盲去噪架构图。噪声模型在基于CNN的去噪性能方面起着关键作用。给定一个干净的图像x,更真实的噪声模型n(x)~N(0,σ(y))可以表示为,
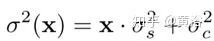
这里,n(x) = ns(x)+ nc由信号相关噪声分量ns和静止噪声分量nc组成。并且nc被建模为具有噪声方差σc2的AWGN,但是对于每个像素i,ns的噪声方差与图像强度相关,即x(i)·σs2。
CBDNet包括噪声估计子网CNNE和非盲去噪子网CNND。首先,噪声估计子网CNNE采用噪声观测y来产生估计的噪声水平图σˆ(y)= FE(y; WE),其中WE表示CNNE的网络参数。CNNE的输出为噪声水平图,因为它与输入y具有相同的大小,并通过全卷积网络。然后,非盲去噪子网络CNND将y和σˆ(y)都作为输入以获得最终去噪结果x = FD(y,σ(y); WD),其中WD表示CNND的网络参数。此外,CNNE允许估计的噪声水平图σ(y)放入非盲去噪子网络CNND之前调整。一个简单的策略是让ρˆ(y)=γσˆ(y)以交互的方式做去噪计算。
噪声估计子网CNNE是五层全卷积网络,没有池化和批量归一化(BN)操作。每个卷积层特征通道32,滤波器大小3×3。在每个卷积层之后有ReLU。与CNNE不同,非盲去噪子网络CNND采用U-Net架构,以y和σˆ(y)作为输入,在无噪干净图像给出预测x。通过残差学习学习残差映射R(y,σˆ(y); WD)然后预测x = y + R(y,σˆ(y); WD)。CNNE的16层U-Net架构引入对称跳跃连接、跨步卷积和转置卷积,来利用多尺度信息并扩大感受野。所有滤波器大小均为3×3,除最后一个,每个卷积层之后加ReLU。
将如下定义的不对称损失引入噪声估计子网,并与重建损失结合一起,训练完整的CBDNet:
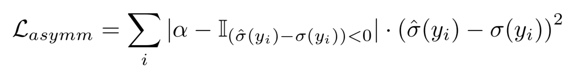
此外,引入一个全局变化(TV)正则化来约束σˆ(y)的平滑度,
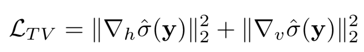
其中∇h(∇v)表示水平(垂直)方向的梯度算子。
重建损失为
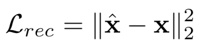
总损失函数
一些结果例子:

单图像去雾是一个具有挑战性的病态问题。现有方法使用各种约束/先验来获得似乎合理的除雾解决方案。实现去雾的关键是估计输入雾霾图像的介质传输图(medium transmission map)。
• DehazeNet
DehazeNet是一个可训练的端到端系统,用于介质传输估计。DehazeNet将雾图像输入,输出其介质传输图,随后通过大气散射模型(atmospheric scattering model)恢复无雾图像。DehazeNet采用CNN的深层架构,设计能体现图像去雾的假设/先验知识。具体而言,Maxout单元层用于特征提取,几乎所有与雾相关的特征。还有一种新的非线性激活函数,称为双边整流线性单元(Bilateral Rectified Linear Unit,BReLU),提高图像的无雾恢复质量。
下图是DehazeNet架构图。在概念上DehazeNet由四个顺序操作(特征提取、多尺度映射、局部极值和非线性回归)组成,它由3个卷积层、最大池化、Maxout单元和BReLU激活函数构成。下面依次介绍四个操作细节。
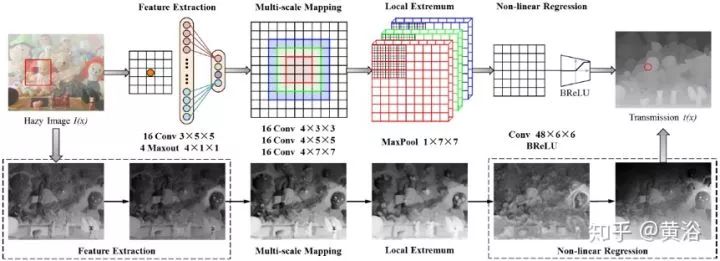
1) 特征提取:为了解决图像去雾问题的病态性,现有方法提出了各种假设,并且基于这些假设,在图像域密集地提取与雾度相关的特征,例如,著名的暗通道(dark channel),色调差和颜色衰减等;为此,选择具有特别激活函数的Maxout单元作为降维非线性映射;通常Maxout用于多层感知器(MLP)或CNN的简单前馈非线性激活函数;在CNN使用时,对k仿射特征图逐像素最大化操作生成新的特征图;设计DehazeNet的第一层如下
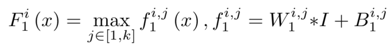
其中
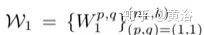
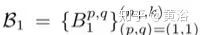
分别代表滤波器和偏差。
2) 多尺度映射:多尺度特征已经被证明对于去除雾度是有效的;多尺度特征提取实现尺度不变性有效;选择在DehazeNet的第二层使用并行卷积运算,其中任何卷积滤波器的大小在3×3、5×5和7×7之间,那么第二层的输出写为
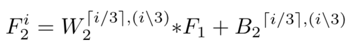
其中
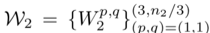
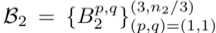
包含分为3组的n2对参数, n2是第二层的输出维度,i∈[1,n2]索引输出特征图,⌈⌉向上取整数,表示余数运算。
3) 局部极值:根据CNN的经典架构,在每个像素考虑邻域最大值可克服局部灵敏度;另外,局部极值是根据介质传输局部恒常的假设,并且通常用于克服传输估计的噪声;第三层使用局部极值运算,即
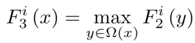
注:局部极值密集地应用于特征图,能够保持图像分辨率。
4) 非线性回归:非线性激活函数的标准选择包括Sigmoid和ReLU;前者容易受到梯度消失的影响,导致网络训练收敛缓慢或局部最优;为此提出了ReLU ,一种稀疏表示方法;不过,ReLU仅在值小于零时才禁止输出,这可能导致响应溢出,尤其是在最后一层;所以采用一种BReLU激活功能,如图所示;BReLU保持了双边约束(bilateral restraint)和局部线性;这样,第四层特征图定义为
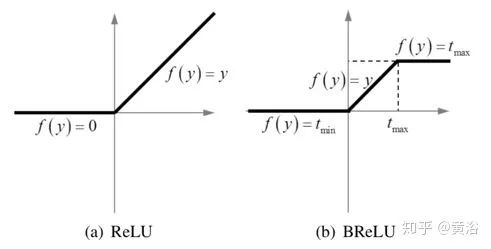
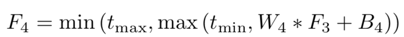
这里W4 = {W4}包含一个大小为n3×f4×f4的滤波器,B4 = {B4}包含一个偏差,tmin, max是BReLU的边际值(tmin = 0和tmax = 1) 。根据上式,该激活函数的梯度可以表示为
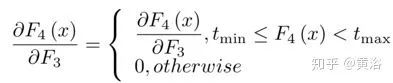
将上述四层级联形成基于CNN的可训练端到端系统,其中与卷积层相关联的滤波器和偏置是要学习的网络参数。
• EPDN
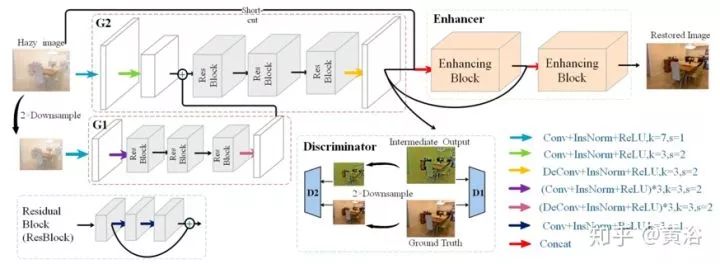
论文将图像去雾问题简化为图像到图像的转换问题,并提出增强的Pix2pix去雾网络(EPDN),它可以生成无雾图像,而不依赖于物理散射模型。EPDN由生成对抗网络(GAN)嵌入,然后是增强器。一种理论认为视觉感知是全局优先的,那么鉴别器指导生成器在粗尺度上创建伪真实图像,而生成器后面的增强器需要在精细尺度上产生逼真的去雾图像。增强器包含两个基于感受野模型的增强块,增强颜色和细节的去雾效果。另外,嵌入式GAN与增强器是一起训练的。
如图是EPDN架构的示意图,由多分辨率生成器模块,增强器模块和多尺度鉴别器模块组成。即使pix2pixHD使用粗到细特征,结果仍然缺乏细节并且颜色过度。一个可能的原因是现有的鉴别器在引导生成器创建真实细节方面受到限制。换句话说,鉴别者应该只指导生成器恢复结构而不是细节。为了有效地解决这个问题,采用金字塔池化模块,以确保不同尺度的特征细节嵌入到最终结果中,即增强块。从目标识别的全局上下文信息中看出,在各种尺度需要特征的细节。因此,增强块根据感受野模型设计,可以提取不同尺度的信息。
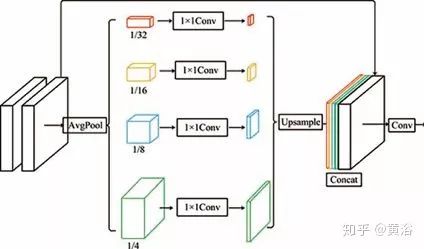
如图是增强块的架构:有两个3×3前端卷积层,前端卷积层的输出缩减,因子分别是4×,8×,16×,32×,这样构建四尺度金字塔;不同尺度的特征图提供了不同的感受域,有助于不同尺度的图像重建;然后,1×1卷积降维,实际上1×1卷积实现了自适应加权通道的注意机制;之后,将特征图上采样为原始大小,并与前端卷积层的输出连接在一起;最后,3×3卷积在连接的特征图上实现。
在EPDN中,增强器包括两个增强块。第一个增强块输入是原始图像和生成器特征的连接,而这些特征图也输入到第二个增强块。
• PMS-Net
补丁图选择网络(Patch Map Selection Network,PMS-Net)是一个自适应和自动化补丁尺寸选择模型,主要选择每个像素对应的补丁尺寸。该网络基于CNN设计,可以从输入图像生成补丁图。其去雾算法的流程图如图所示。
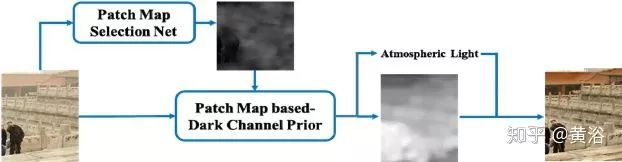
为了提高该网络的性能,PMS-Net提出一种有金字塔风格的多尺度U-模块。基于补丁图,可预测更精确的大气光和透射图。所提出的架构,可以避免传统DCP的问题(例如,白色或明亮场景的错误恢复),恢复图像的质量高于其他算法。其中,定义了一个名为补丁图(patch map)的来解决暗通道先验(DCP)补丁大小固定的问题。
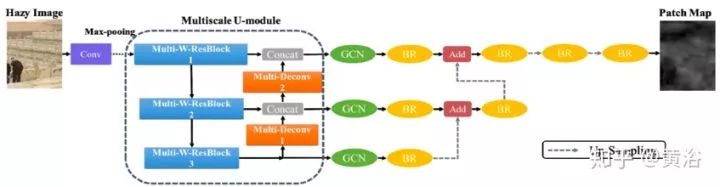
如图是PMS-Net的架构,分为编码器和解码器。最初,输入的雾图像和16个3×3内核的滤波器卷积投影到更高维空间。然后,多尺度-U模块从更高维数据中提取特征。多尺度U-模块的设计如图左侧所示。
输入将通过几个Multiscale-W-ResBlocks(MSWR),如下图左侧所示。MSWR的设计想法类似Wide-ResNet(WRN),通过增加网络宽度和减小深度来改进ResNet。每块中使用快捷方式执行Conv-BN-ReLu-Dropout-Conv-BN-ReLu这一系列操作提取信息。MSWR中多尺度概念类似Inception-ResNet,采用多层技术来增强信息的多样性,并提取详细信息。
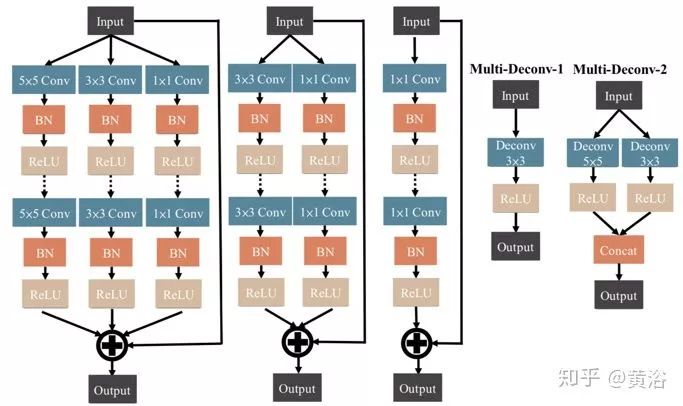
多尺度U-模块中的其他部分,Multi-Deconv模块将信息与MSWR而不是反卷积的输出连接在一起,因为反卷积层可以帮助网络重建输入数据的形状信息。因此,通过多尺度反卷积组合,可以从网络前层重建更精确的特征图。此外,Multi-Deconv执行金字塔风格并提高尺度与MSWR连接。也就是说,不同层特征图以不同的尺度运行去卷积(参见多尺度U-模块图右侧)。
为保留高分辨率,MSWR和Multi-Deconv模块的输出直接连接。然后,特征图馈送到网络更高层的Multi-Deconv模块和解码器。解码器采用全局卷积网络模块(global convolutional network modules,GCN)。边界细化模块(boundary refinement,BR)也用于边缘信息保留。上采样操作升级尺度层。此外,采用致密连接样式合并高与低分辨率的信息。PMS-Net可以预测补丁图。
下图是一些实验结果的分析:白色和明亮场景中去雾结果的比较;第1栏:输入图像; 第2栏:通过固定尺寸补丁DCP的结果; 第3栏:PMS-Net方法的结果; 第4栏:第2栏和第3栏中白色或亮部的放大; 第5栏:补丁图; 第6-7栏:分别由DCP和PMS-Net方法估计的介质传输图。

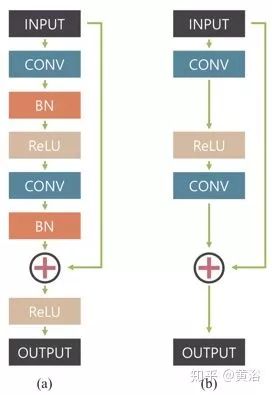
这是一种多尺度卷积神经网络,以端到端的方式恢复清晰的图像,其中模糊是由各种来源引起的,包括镜头运动、景物深度和物体运动。如图是定义的网络模型架构图,称为ResBlocks:(a)原始残余网络构建块,(b)该网络修正的模块化构建块;没有使用批量归一化(BN)层,因为训练模型使用的小批量(mini-batch)大小为2,比BN通常要小;在输出之前去除整流线性单元(ReLU)有利于提高经验性能。
设计的去模糊多尺度网络架构见下图所示:Bk,Lk,Sk分别表示模糊、潜在和GT清晰图像。下标k表示高斯金字塔第k个尺度层,下采样到1 / 2k尺度。该模型将模糊的图像金字塔作为输入并输出估计的潜在图像金字塔。每个中间尺度的输出都训练成清晰。在测试时,选择原始尺度的输出图像作为最终结果。
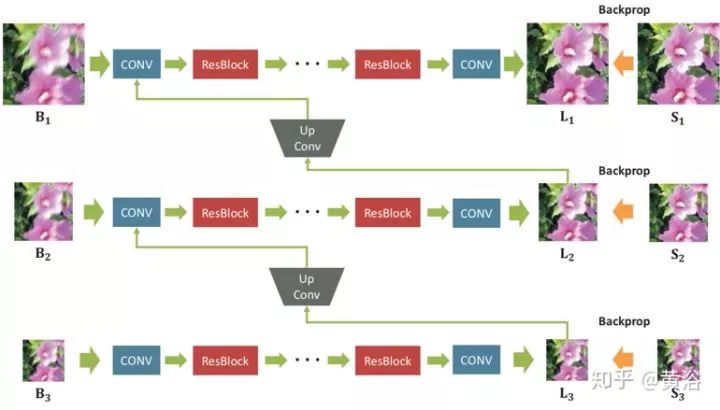
用ResBlocks堆叠足够数量的卷积层,每个尺度的感受野得以扩展。在训练时,将输入和输出高斯金字塔补丁的分辨率设置为{256×256,128×128,64×64}。连续尺度之间的比例(scale ratio)是0.5。对所有卷积层,滤波器大小为5×5。因为模型是全卷积,在测试时补丁大小可能变化。
定义一个多尺度损失函数模拟传统的粗到精方法
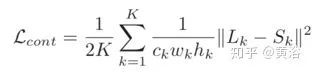
其中Lk,Sk分别表示在尺度层k的模型输出图像和GT图像。而对抗损失函数定义为
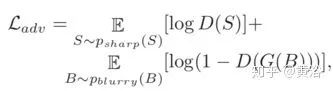
其中G和D分别是生成器和鉴别器。最终的损失函数是
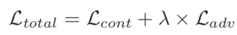
一些结果如图所示,有几个缩放的局部细节。

具有深度觉察和视角聚合(Depth Awareness and View Aggregation)的网络DAVANet是一个立体图像去模糊网络。网络中来自两个视图有深度和变化信息的3D场景线索合并在一起,动态场景中有助于消除复杂空间变化的模糊。具体而言,通过这个融合网络,将双向视差估计和去模糊整合到一个统一框架中。
下图描述立体视觉带来的模糊:(a)是与图像平面平行的相对平移引起的深度变化模糊,(b)和(c)是沿深度方向的相对平移和旋转引起的视角变化模糊。注意,所有复杂运动可以分解为这三个相对子运动模式。
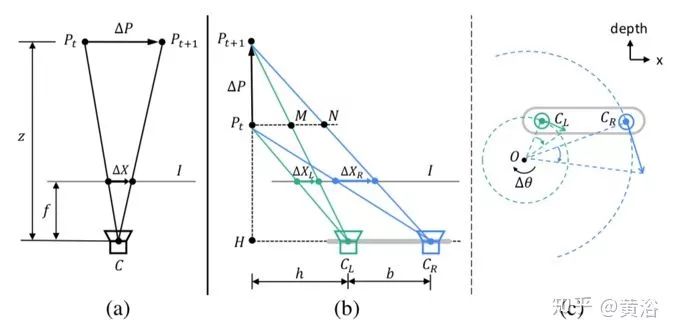
如图(a)所示,我们可以得到:
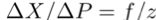
其中ΔX,ΔP,f和z分别表示模糊的大小、目标点的运动、焦距和目标点的深度。
如图(b)所示,我们知道:
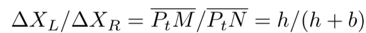
其中b是基线,h是左摄像头CL和线段PtPt+1之间的距离。
如图(c)所示,两个镜头的速度vCL,vCR与相应旋转半径CLO,CRO成正比,即
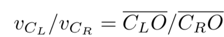
DAVANet总体流程图如图所示,由三个子网络组成:用于单镜头去模糊的DeblurNet,用于双向视差估计的DispBiNet,和以自适应选择方式融合深度和双视角信息的FusionNet。这里采用小卷积滤波器(3×3)来构造这三个子网络,因为大型滤波器并不能提高性能。
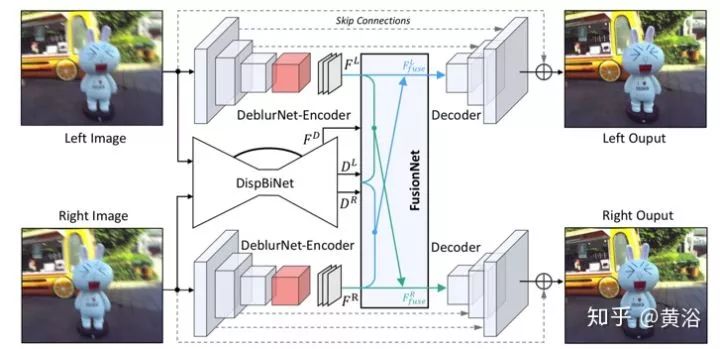
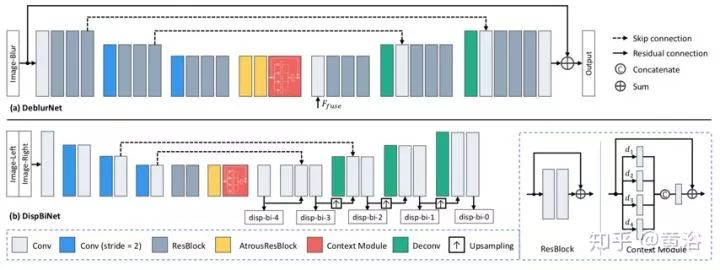
DeblurNet的结构基于U-Net,如图(a)所示。用基本残差模块作为构建块,编码器输出特征为输入尺寸的1/4×1/4。之后,解码器通过两个上采样残差块全分辨率重建清晰图像。在编码器和解码器之间使用相应特征图之间的跳连接(skip-connections)。此外,还采用输入和输出之间的残差连接。这使网络很容易估计模糊-尖锐(blurry-sharp)图像对之间的残差并保持颜色一致性。还有,在编码器和解码器之间使用两个空洞残差(atrous residual)块和一个Context模块来获得更丰富的特征。DeblurNet对两个视图使用共享权重。
受以前DispNet模型结构的启发,采用一个小型DispBiNet,如图(b)所示。与DispNet不同,DispBiNet可以预测一个前向过程的双向视差。输出是完整分辨率,网络有三次下采样和上采样操作。此外,DispBiNet中还使用了残差块、空洞残差块和Context模块。
为了嵌入多尺度特征,DeblurNet和DispBiNet采用Context模块,它包含具有不同扩张率(dilated rate)的并行扩张卷积(dilated convolution),如图所示。四个扩张率是设置为1, 2, 3, 4。Context模块融合更丰富的分级上下文信息,有利于消除模糊和视差估计。
为了利用深度和双视角信息去模糊,引入融合网络FusionNet来丰富具有视差和双视角的特征。如图所示,FusionNet采用原始立体图像IL,IR,估计的左视图DL视差,DispBiNet倒数第二层的特征FD和DeblurNet编码器的特征FL,FR作为输入,以生成融合特征FLfuse。
为双视角聚合,估计的左目视差DL将DeblurNet的右目特征FR变形到左目,即为WL(FR)。不用直接连接WL(FR)和FL,而是子网GateNet生成从0到1的软门图(soft gate map)GL。门图可以自适应选择方式用来融合特征FL和WL(FR),即选择有用的特征,并从另一个视角拒绝不正确的特征。例如,在遮挡或错误视差区域,门图值往往为0,这表明只采用参考视角F L的特征。GateNet由五个卷积层组成,如图所示,输入是左图像IL和变形的右图像WL(IR)的绝对差,即| IL - WL(IR)|,输出是单通道的门图。所有特征通道共享相同的门图以生成聚合特征:
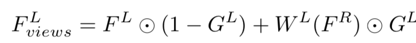
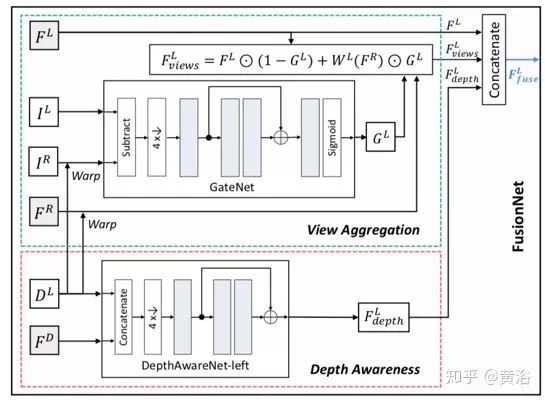
为深度觉察,使用三个卷积层的子网络DepthAwareNet,而且两个视角不共享该子网络。给定视差DL和DispBiNet的倒数第二层特征FD,DepthAwareNet-left产生深度关联的特征FL。事实上,DepthAwareNet隐式地学习深度觉察的先验知识,这有助于动态场景的去模糊。
最后,连接原始左图特征FL,视角聚合特征FLviews和深度觉察特征FLdepth生成融合的左视角特征FLfuse。然后,将FLfuse供给DeblurNet的解码器。同理,采用FusionNet一样的架构可以得到右视角的融合特征。
DeblurNet损失函数包括两个部分:MSE损失和感知损失,即
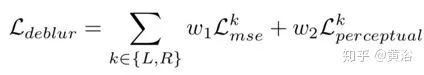
其中
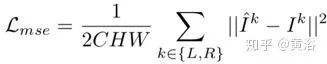
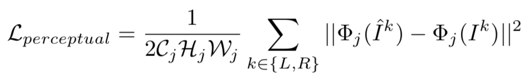
DispBiNet的视差损失函数如下:
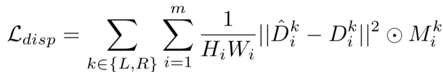
如图显示的是视差对去模糊的作用:(a)(f)(g)和(h)分别表示模糊图像、清晰图像、预测的视差和GT视差。(b)和(e)是单目去模糊网络DeblurNet和双目去模糊网络DAVANet的结果。在(c),两个左图像输入,DispBiNet不能为深度觉察和视角聚合提供任何深度信息或视差。在(d)中,为了消除视角聚合的影响,不会从FusionNet中其他视图变形该特征。由于该网络可以准确估计和采用视差,因此其性能优于其他方法

• Deep Bilateral Learning
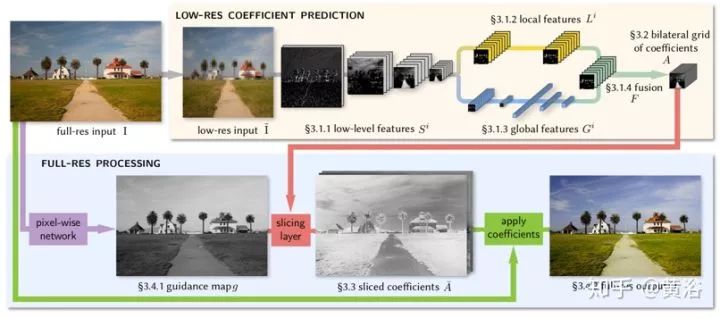
这是一种做图像增强的神经网络架构,其灵感来自双边网格处理(bilateral grid processing)和局部仿射颜色变换。基于输入/输出图像对,训练卷积神经网络来预测双边空间(bilateral space)局部仿射模型的系数。网络架构目的是学习如何做出局部的、全局的和依赖于内容的决策来近似所需的图像变换。输入神经网络是低分辨率图像,在双边空间生成一组仿射变换,以边缘保留方式切片(slicing)节点对这些变换进行上采样,然后变换到全分辨率图像。该模型是从数据离线训练的,不需要在运行时访问原始操作。这样模型可以学习复杂的、依赖于场景的变换。
如图所示,对低分辨率的输入I的低分辨率副本I~执行大部分推断(图顶部),类似于双边网格(bilateral grid)方法,最终预测局部仿射变换。图像增强通常不仅取决于局部图像特征,还取决于全局图像特征,如直方图、平均强度甚至场景类别。因此,低分辨率流进一步分为局部路径和全局路径。将这两条路径融合在一起,则生成代表仿射变换的系数。
而高分辨率流(图底部)在全分辨率模式工作,执行最少的计算,但有捕获高频效果和保留边缘的作用。为此,引入了一个切片节点。该节点基于学习的导图(guidance map)在约束系数的低分辨率格点做数据相关查找。基于全分辨率导图,给定网格切片获得的高分辨率仿射系数,对每个像素做局部颜色变换,产生最终输出O。在训练时,在全分辨率下最小化损失函数。这意味着,仅处理大量下采样数据的低分辨率流,仍然可以学习再现高频效果的中间特征和仿射系数。
下面可以从一些例子看到各个改进的效果。如图所示,低级卷积层具备学习能力,可以提取语义信息。用标准双边网格的喷溅操作(splatting operation)替换这些层会导致网络失去很大的表现力。

如图所示,全局特征路径允许模型推理完整图像,(a)例如再现通过强度分布或场景类型的调整。(b)如果没有全局路径,模型可以做出空间不一致的局部决策。

如图所示,新切片节点对架构的表现力及其对高分辨率效果的处理至关重要。用反卷积滤波器组替换该节点会降低表现力(b),因为没有使用全分辨率数据来预测输出像素。由于全分辨率导图,切片层以更高的保真度(c)逼近。

如图所示,(b)HDR的亮度畸变,特别是在前额和脸颊的高光区域出现的海报化畸变(posterization artifacts)。相反,切片节点的导图使(c)正确地再现(d)基础事实GT。

• Deep Photo Enhancer
它提出一种不成对学习(unpaired learning)的图像增强方法。给定一组具有所需特征的照片,该方法学习一种照片增强器,将输入图像转换为具有这些特征的增强图像。在基于双路(two-way)生成对抗网络(GAN)框架基础上,改进如下:1)基于全局特征扩充U-Net,而全局U-Net是GAN模型的生成器;2)用自适应加权方案改进Wasserstein GAN(WGAN),训练收敛更快更好,对参数敏感度低于WGAN-GP;3)在双路GAN的生成器采用单独BN层,有助于生成器更好地适应自身输入分布,提高GAN训练的稳定性。
如图介绍了双路GAN的架构。(a)是单向GAN的架构。给定输入x∈X,生成器GX将x变换为y'= GX(x)∈Y。鉴别器DY旨在区分目标域{y}中的样本和生成的样本{y'= GX(x)}。为了实现循环一致性,双路GAN被采用,例如CycleGAN 和DualGAN 。它们需要G'Y(GX(x))= x,其中生成器G'Y采用GX生成的样本并将其映射回源域X。此外,双路GAN通常包含前向映射(X →Y)和后向映射(Y→X)。(b)显示了双路GAN的体系结构。在前向传播时,
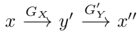
,检查x''和x之间的一致性。在后向传播时,
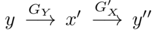
,检查y和y''之间的一致性。

如图是GAN的生成器和鉴别器架构。生成器器基于U-Net,但添加全局特征。为了提高模型效率,全局特征的提取与U-Net的收缩部分共享前五层局部特征的提取。每个收缩步骤包括5×5滤波、步幅为2、SELU激活和BN。对全局特征来说,假定第五层是32×32×128特征图,收缩后进一步减小到16×16×128然后8×8×128。通过全连接层、SELU激活层和另一个全连接层,将8×8×128特征图减少到1×1×128。然后将提取的1×1×128全局特征复制32×32个拷贝,并和低级特征32×32×128之后相连接,得到32×32×256特征图,其同时融合了局部和全局特征。在融合的特征图上执行U-Net的扩展路径。最后,采用残差学习的思想,也就是说,生成器只学习输入图像和标注图像之间的差异。
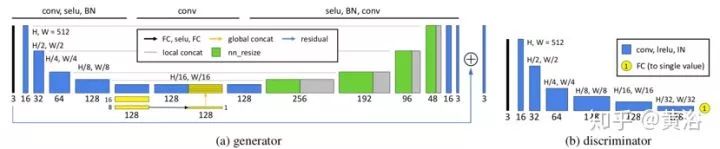
WGAN依赖于训练目标的Lipschitz约束:当且仅当它梯度模最多是1时,一个可微函数是1-Lipschtiz 。为了满足约束条件,WGAN-GP通过添加以下梯度惩罚直接约束鉴别器相对于其输入的输出梯度模,
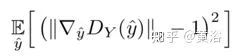
其中yˆ是沿目标分布与生成器分布之间的直线的采样点。
参数λ加权原鉴别器损失的惩罚。λ确定梯度趋进1的趋势。如果λ太小,无法保证Lipschitz约束。另一方面,如果λ太大,则收敛可能缓慢,因为惩罚可能过重加权鉴别器损失。λ的选择很重要。相反,使用以下梯度惩罚,
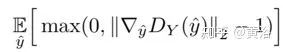
这更好地反映了要求梯度小于或等于1并且仅惩罚大于1部分的Lipschitz约束。更重要的是,可采用自适应加权方案调整权重λ,选择适当的权重,即梯度位于所需的间隔内,比如[1.001, 1.05]。如果滑动窗(大小= 50)内的梯度移动平均值(moving average of gradients)大于上限,则意味着当前权重λ太小而且惩罚力不足以确保Lipschitz约束。因此,通过加倍权重来增加λ。另一方面,如果梯度移动平均值小于下限,则将λ衰减一半,这样就不会变得太大。这个改进,称为A-GAN(自适应GAN)。
前面图(a)生成器作GX而图(b)鉴别器用作DY,得到以前图(a)单路GAN的架构。同样推广A-GAN可以得到如以前图(b)的双路GAN架构。
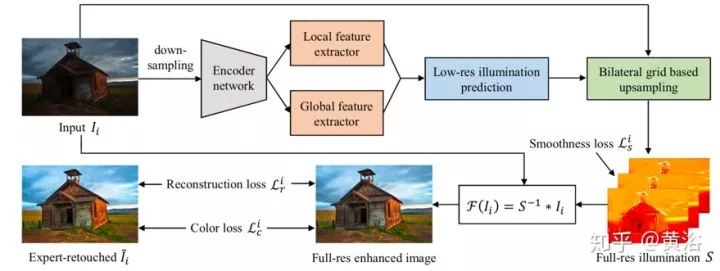
• Deep Illumination Estimation
这是一种基于神经网络增强曝光不足照片的方法,其中引入中间照明(intermediate illumination),将输入与预期的增强结果相关联,也加强了网络的能力,能够从专家修改的输入/输出图像对学习复杂的摄影修整过程。基于该模型,用照明的约束和先验定义一个损失函数,并训练网络有效地学习各种照明条件的修整过程。通过这些方式,网络能够恢复清晰的细节,鲜明的对比度和自然色彩。
从根本上说,图像增强任务可以被称为寻找映射函数F,从输入图像I增强,I ̃ = F(I)是期望的图像。在Retinex的图像增强方法中,F的倒数通常建模为照明图S,其以像素方式与反射图像I ̃相乘产生观察图像I:I = S * I ̃。
可以将反射分量I ̃视为曝光良好的图像,因此在模型中,I ̃作为增强结果,I作为观察到的未曝光图像。一旦S已知,可以通过F(I)= S-1 * I获得增强结果I ̃. S被模型化为多通道(R,G,B)数据而不是单通道数据,以增加其在颜色增强方面的能力,尤其是处理不同颜色通道的非线性特性。
如图是网络的流水线图。增强曝光不足的照片需要调整局部(对比度,细节清晰度,阴影和高光)和全局特征(颜色分布,平均亮度和场景类别)。从编码器网络生成的特征考虑局部和全局上下文信息,见图上部。为了驱动网络学习从输入的曝光不足图像(Ii)到相应的专家修饰图像(I ̃)的照明映射,设计了一种损失函数,具有照明平滑度先验知识以及增强的重建和颜色损失,见图底部。这些策略有效地从(Ii,I ̃i)学习S,通过各种各样的照片调整来恢复增强的图像。值得一提的是,该方法学习低分辨率下预测图像-照明映射的局部和全局特征,同时基于双边网格的上采样将低分辨率预测扩展到全分辨率,系统实时性好。
下图展示了一些增强的结果例子(上:输入,下:增强)。

1. K Zhang et al., “Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising”,IEEE T-IP,2017
2. A Ignatov et al., “DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks“,arXiv 1704.02470, 2017
3. P. Svoboda et al., “Compression artifacts removal using convolutional neural networks”. arXiv 1605.00366, 2016.
4. B. Cai et al.,”Dehazenet: An end-to-end system for single image haze removal”. IEEE T-IP, 2016
5. X. Mao, C. Shen, Y.-B. Yang. “Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections”. Advances in Neural Information Processing Systems 29, 2016
6. Z. Yan et al., “Automatic photo adjustment using deep neural networks”. ACM Trans. Graph., 2016
7. M Gharbi et al.,“Deep Bilateral Learning for Real-Time Image Enhancement”, arXiv 1707.02880, 2017
8. S Nah, T Kim, K Lee,“Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring”, CVPR, 2017
9. Y Chen et al.,“Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs”, CVPR, 2018.
10. J Zhang et al., "Dynamic Scene Deblurring Using Spatially Variant Recurrent Neural Networks", CVPR 2018.
11. S Guo et al.,“Toward Convolutional Blind Denoising of Real Photographs”, CVPR, 2019
12. R Wang et al.,“Underexposed Photo Enhancement using Deep Illumination Estimation”, CVPR 2019.
13. Y Qu et al.,“Enhanced Pix2pix Dehazing Network”, CVPR, 2019
14. S Zhou et al.,“DAVANet: Stereo Deblurring with View Aggregation”, CVPR 2019.
15. W Chen, J Ding, S Kuo,“PMS-Net: Robust Haze Removal Based on Patch Map for Single Images”, CVPR, 2019
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~