
Facebook最新语言模型XLM-R:多项任务刷新SOTA,超越单语BERT

新智元报道
来源:Facebook AI
编辑:肖琴
【新智元导读】Facebook AI最新推出一个名为XLM-R的新模型,使用100种语言、2.5 TB文本数据进行训练,在多项跨语言理解基准测试中取得了SOTA的结果,并超越了单语言的BERT模型。代码已开源,来新智元 AI 朋友圈获取吧~
 Yann LeCun在Twitter上赞赏该研究
Yann LeCun在Twitter上赞赏该研究XLM-R使用自我监督(self-supervised)的训练技术实现了跨语言理解的SOTA性能。在这项任务中,用一种语言对模型进行训练,然后将模型用于其他语言,而不需要额外的训练数据。
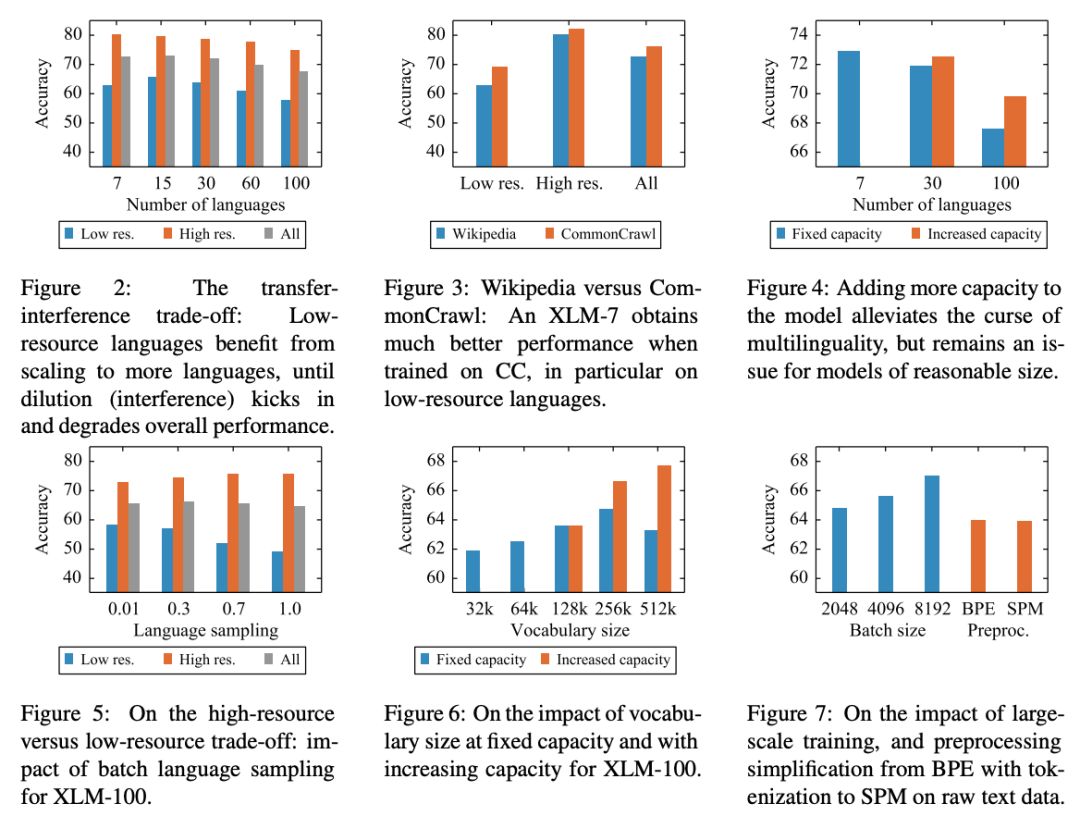
在论文“Unsupervised Cross-lingual Representation Learning at Scale”中,研究人员全面分析了无监督多语言掩码语言模型的能力和限制,特别是研究了高资源/低资源和传输/干扰的权衡,并揭示了所谓的“多语言的诅咒”。
XLM-R在四个跨语言理解基准测试中取得了迄今为止最好的结果,在XNLI跨语言自然语言推理数据集上的平均准确率提高了4.7%,在最近推出的MLQA问题回答数据集上的平均F1得分提高了8.4%,在NER数据集上的平均F1得分提高了2.1%。
XLM-R身手不凡:多项任务刷新SOTA,超越单语BERT
在XLM和RoBERTa中使用的跨语言方法的基础上,我们增加了新模型的语言数量和训练示例的数量,用超过2TB的已经过清理和过滤的CommonCrawl 数据以自我监督的方式训练跨语言表示。这包括为低资源语言生成新的未标记语料库,并将用于这些语言的训练数据量扩大两个数量级。
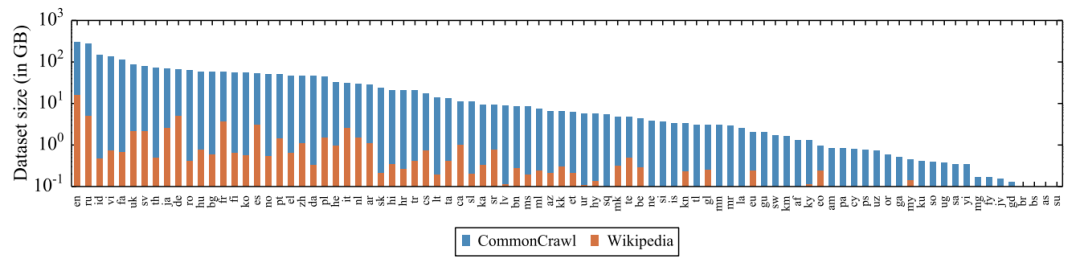 用于XLM-100的Wiki-100语料库和用于XLM-R的CC-100语料库中出现的88种语言的GiB (log-scale)数据量。CC-100将数据量增加了几个数量级,特别是对于低资源语言而言。
用于XLM-100的Wiki-100语料库和用于XLM-R的CC-100语料库中出现的88种语言的GiB (log-scale)数据量。CC-100将数据量增加了几个数量级,特别是对于低资源语言而言。在fine-tuning期间,我们利用多语言模型的能力来使用多种语言的标记数据,以改进下游任务的性能。这使我们的模型能够在跨语言基准测试中获得state-of-the-art的结果,同时超过了单语言BERT模型在每种语言上的性能。
我们调整了模型的参数,以抵消以下不利因素:使用跨语言迁移来将模型扩展到更多的语言时限制了模型理解每种语言的能力。我们的参数更改包括在训练和词汇构建过程中对低资源语言进行上采样,生成更大的共享词汇表,以及将整体模型容量增加到5.5亿参数。
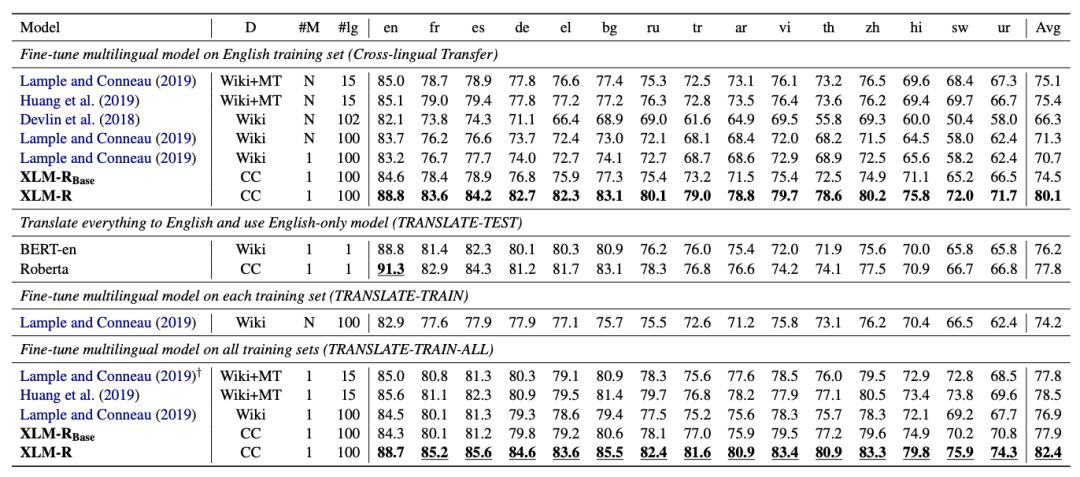 跨语言分类结果
跨语言分类结果命名实体识别结果
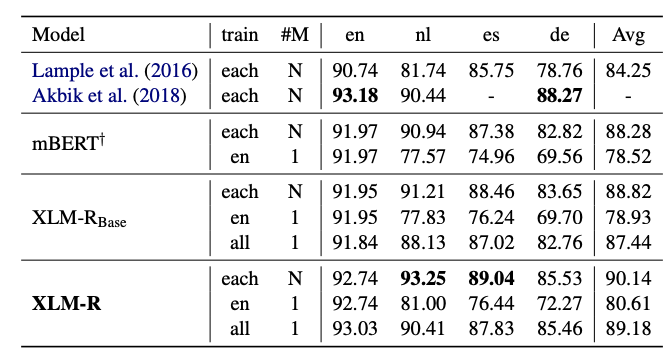 命名实体识别的结果。
命名实体识别的结果。 MLQA问题回答的结果。
MLQA问题回答的结果。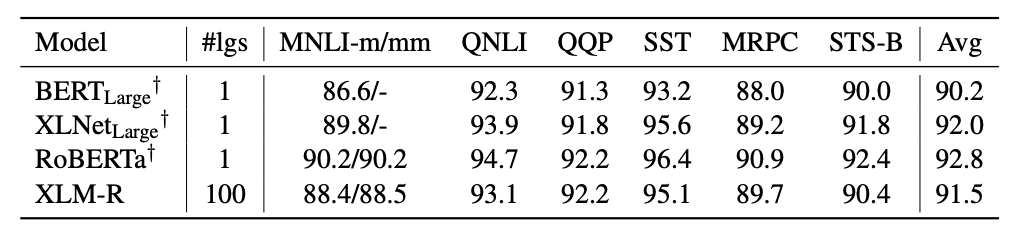 GLUE dev结果。†的结果来自 Liu et al. (2019)。我们比较了XLMR与BERT-Large、XLNet和Roberta在英语GLUE benchmark上的性能。
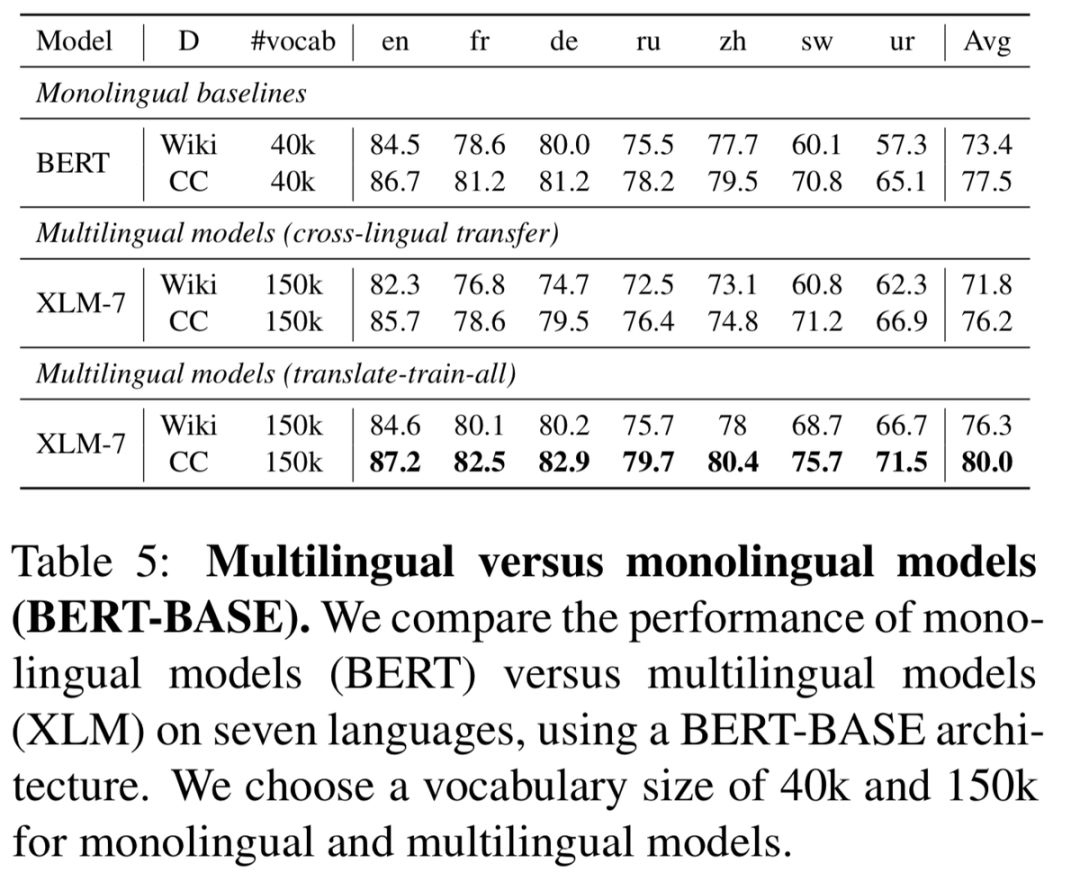
GLUE dev结果。†的结果来自 Liu et al. (2019)。我们比较了XLMR与BERT-Large、XLNet和Roberta在英语GLUE benchmark上的性能。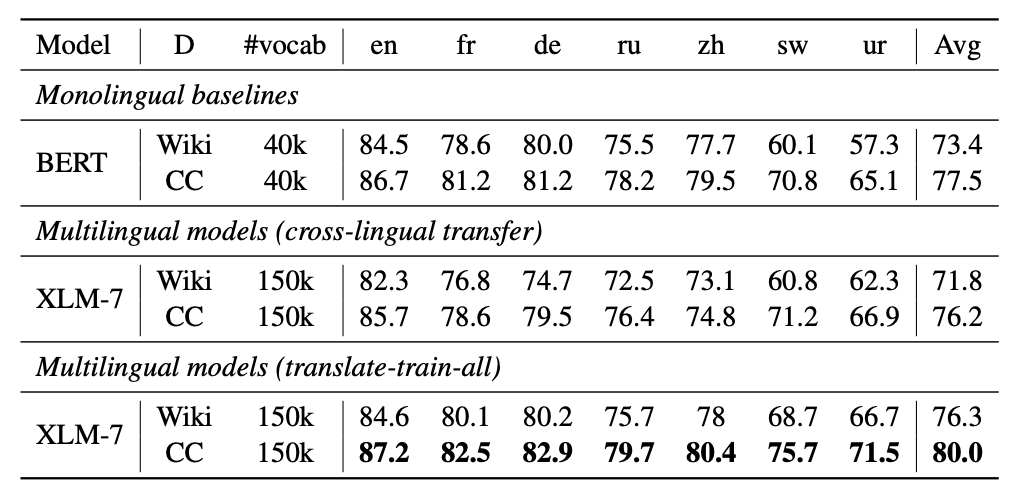 多语言模型vs单语言模型(BERT-BASE)。我们使用一个基于BERT的结构,比较了在七种语言上单语模型(BERT)和多语模型(XLM)的性能。
多语言模型vs单语言模型(BERT-BASE)。我们使用一个基于BERT的结构,比较了在七种语言上单语模型(BERT)和多语模型(XLM)的性能。论文地址:https://arxiv.org/pdf/1911.02116.pdf
评论