
【NLP】“统一语言学习范式”:详解50个任务达到sota的谷歌新模型
共 5503字,需浏览 12分钟
·
2022-05-27 21:27

现有的预训练模型(pre-trained models)通常针对特定类别的问题。迄今为止,对于正确的模型架构和预训练设置应该是什么,似乎学术界仍未达成共识。
谷歌团队在这个问题上迈出了重要一步:他们在Unifying Language Learning Paradigms这篇论文中提出了一个统一的预训练模型框架,该框架在数据集和设置中普遍有效。
在广泛的消融实验比较多个预训练目标之后,团队并发现这个方法在多种不同设置中优于 T5 和/或 GPT 模型,将这个ul2模型扩展到 20B 参数后,在 50 个完善的监督 NLP 任务上实现了 SOTA 性能,这些任务包括语言生成(自动和人工评估)、语言理解、文本分类、问答、常识推理、长文本推理、结构化知识基础和信息检索。
论文:https://arxiv.org/pdf/2205.05131.pdf
代码:https://github.com/google-research/google-research/tree/master/ul2
背景和动机:究竟如何选择预训练模型?
如今有大量的预训练语言模型提供给NLP 研究人员和从业者。
当面对应该使用什么模型的问题时,答案通常是取决于具体的任务。回答这个问题可能非常困难,这个问题包括了许多后续的细粒度问题,比如,“仅使用编码器还是使用编码器-解码器架构?”,“span corruption还是语言模型?”。
进一步追问,答案似乎总是取决于目标下游的任务。
本文对这一思考过程进行了质疑和反思,具体回答了为什么选择预训练语言模型要依赖于下游任务的问题。那么,如何对能在许多任务中普遍有效地模型进行预训练?
本文提出了使通用语言模型成为可能的关键一步:提出了一个统一的语言学习范式(UL2)的框架,简而言之,该框架在非常不同的任务和设置中始终有效。图1展示了UL2如何普遍良好地在各类下游任务上执行,而不像其他模型经常需要进行权衡。
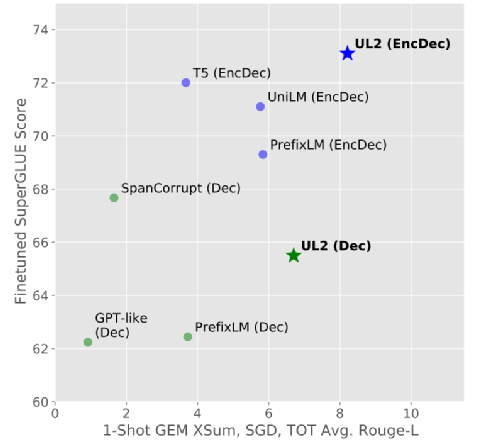
图1. UL2与其他预训练语言模型在下游任务上的对比
通用模型的吸引力是显而易见的,它的出现允许集中精力改进和扩大单一模型,而不是在N个预训练模型之间分散资源。此外,在资源受限的情况下,只有少数几个模型可以被服务(例如,在设备上),最好有一个可以在许多类型的任务上表现良好的单一预训练模型。
统一语言学习范式:任务及架构
预训练任务
许多预训练任务可以简单地表述为“输入到目标”任务,其中输入是指模型所依赖的任何形式的内存或上下文,目标是模型的预期输出。语言模型使用所有先前的时间步长作为模型的输入来预测下一个标记,即目标。在跨度损坏中,该模型利用过去和未来的所有未损坏标记作为预测损坏跨度(目标)的输入。PrefixLMs 是使用过去的token作为输入的LMs,但双向使用输入序列。这提供了比 vanilla LM 中输入的单向编码更多的建模能力。
鉴于这个观点,可以将一个预训练目标近似地简化为另一个目标。例如,在跨度损坏目标中,当损坏的跨度(即目标)等于整个序列时,问题实际上变成了语言建模问题。考虑到这一点,使用跨度损坏,通过将跨度长度设置得很大,可以有效地模拟局部区域的 LM 目标。
本文定义了一个预训练任务,涵盖了使用的所有不同去噪任务。去噪任务的输入和目标由 SPANCORRUPT 函数生成,该函数由三个值 (µ, r, n) 参数化,其中 µ 是平均跨度长度,r 是损坏率,n 是损坏跨度的数量。注意,n 可能是输入长度 L 和跨度长度 μ 的函数,例如 L/µ,但在某些情况下,使用固定值 n。给定一个输入文本,SPANCORRUPT 对从平均值为 µ 的(正态或均匀)分布中提取的长度跨度引入了损坏。
损坏后,输入文本随后被馈送到去噪任务,损坏的跨度用作要恢复的目标。例如,要使用此公式构建类似于因果语言建模的目标,只需设置 (µ = L, r = 1.0, n = 1),即其跨度长度等于序列长度的单个跨度 . 为了表达一个类似于 Prefix LM 目标的方法,可以设置 (µ = L - P, r = 1.0 - P/L, n = 1),其中 P 是前缀的长度,附加约束是单个损坏的跨度总是到达序列的末尾。
这种输入到目标的公式可以应用于编码器-解码器模型和单栈transformer模型(例如,解码器模型)。因此选择选择预测下一个目标标记的模型而不是那些就地预测的模型(例如,预测 BERT 中的当前掩码标记),因为下一个目标公式更通用并且可以包含更多任务而不是使用特殊的CLS token和特定任务的头。
团队推测,一个强大的通用模型必须在预训练期间解决各种问题。鉴于预训练是使用自监督完成的,应该将这种多样性注入模型的目标,否则模型可能会缺乏某种能力,比如长文本生成。
基于此,以及当前的目标函数类型,研究定义了三个主要的范式用于预训练:
l R去噪器 常规去噪是 Raffel 等人引入的标准span corruption,使用 2 到 5 个token作为跨度长度,掩盖了大约 15% 的输入标记。这些span很短,对于获取知识而不是学习生成流畅的文本可能有用。
l S去噪器 在构建输入到目标任务时观察到严格的顺序,即前缀语言建模。为此只需将输入序列划分为两个标记子序列作为上下文和目标,这样目标就不会依赖于未来的信息。这与标准span corruption不同,其中可能存在位置比上下文token更早的目标token。
l X去噪器 一种极端版本的去噪,其中模型必须恢复大部分输入,给定一小部分到中等部分。这模拟了模型需要从信息相对有限的内存中生成长目标的情况。为此选择包含具有积极去噪的示例,其中大约 50% 的输入序列被屏蔽。这是通过增加跨度长度和/或损坏率来实现的。如果预训练任务具有较长的跨度(例如,≥ 12)或具有较大的损坏率(例如,≥ 30%),则认为它是极端的。X去噪的动机是作为常规跨度损坏和类似目标的语言模型之间的插值。
这组去噪器与之前使用的目标函数有很强的联系:R-Denoising 是 T5 跨度破坏目标,S-Denoising 连接到类似于 GPT 的因果语言模型,而 X-Denoising 可以将模型暴露于 来自 T5 和因果 LM 的目标。
值得注意的是,X 降噪器也与提高样本效率有关,因为在每个样本中可以学习到更多的标记来预测,这与 LM 的精神相似,建议以统一的方式混合所有这些任务,并有一个混合的自我监督目标。最终目标是7个降噪器的混合,配置如下:

表1. UL2混合降噪器的配置
对于 X 和 R 降噪器,跨度长度是从平均值为 µ 的正态分布中采样的。对于 S-Denoisers,使用均匀分布,将损坏的 span 的数量固定为 1,并附加一个约束,即损坏的 span 应该在原始输入文本的末尾结束。这大致相当于 seq2seq 去噪或 Prefix LM 预训练目标。
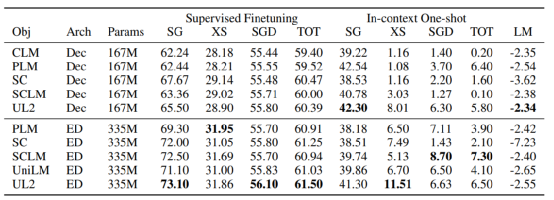
表2. 不同预训练模型在各个下游任务上的实验结果
由于 LM 是 Prefix-LM 的一个特例,没有必要在混合中包含一个随意的 LM 任务。所有任务在混合中的参与度大致相等。本文还探索了一种替代方案,将 S 降噪器的数量增加到混合物中降噪器的 50%,而所有其他降噪器占据剩余部分。
模型架构
UL2 采用与架构无关的设计理念。
两种架构(编码器-解码器与仅解码器)之间的选择更多是一种效率权衡,并且架构选择不应与预训练目标混为一谈。因此模型有一个 UL2 解码器和一个 UL2 编码器-解码器,
UL2 采用了相当标准的vanilla T5 transform,并通过经受时间考验的修改进行了增强,即 GLU 层(Shazeer,2020)和 T5 风格的相对注意力。为了不进一步将架构修改与预训练贡献混为一谈,模型的主干仍然类似于 T5 模型,这也与 (Narang et al., 2021) 等结果有关。
基线模型
研究将UL2与以下预训练模型进行对比,分别是Causal Language Model (标准的从左到右的自回归语言模型预训练,本文称为 GPT-like)、Prefix LM (Causal LM 的变种)、Span Corruption 、Span Corruption + LM 、UniLM。
所有目标都探索了单栈和编码器-解码器架构。
所有架构都是在编码器-解码器或仅解码器模型结构中实现的目标输入,因为 BERT 风格的掩码语言建模预训练已经有效地被这种预训练风格所包含。本文也不建议使用特定于任务的分类头,因为它们显然违背了拥有通用模型的原则。
实验设置
研究使用的数据集是 SuperGLUE ,由 8 个 NLU 子任务组成。
此外也对来自 GEM 基准的 3 个数据集进行了实验,这些数据集专注于语言生成问题。
对于所有这些任务,评估监督微调和基于提示的一次性学习。最后还使用 C4 验证集上的困惑度分数比较了UL2模型在文本生成方面的一般能力。
对于 SuperGLUE,团队会在适当的时候报告完善的指标,例如准确度、F1 或精确匹配。对于 GEM 基准,使用 Rouge-L 指标。对于语言建模,使用负对数困惑。模型的普遍性,即它们在所有任务范围内的集体表现,是这里的主要评估标准。为了从这个角度进行模型之间的比较,需要一个综合性能得分。但是,不同任务的指标在本质上存在很大差异——例如,F1 和困惑度。
为了解决这个问题,团队选择报告并使用相对于基线的归一化相对增益作为整体指标。为此,使用标准语言模型(仅解码器)(GPT-like)和标准跨度去噪编码器-解码器(T5)作为主要基线,并报告所有方法与这些成熟候选者的相对性能。团队认为这是比较这些模型最合适的方法,因为很容易推断新模型通常比流行设置(例如,GPT 或 T5-like)好多少。此外还强调了整体收益是标准化的这一事实,因此这变得更难利用或容易受到基准彩票效应的影响。
消融实验结果
没有简单的方法来比较只解码器模型和编码器-解码器模型,但可以用计算匹配的方式或参数匹配的方式来比较它们。因此,这组结果中的编码器-解码器模型的参数数量大约是解码器模型的两倍,但速度相似。
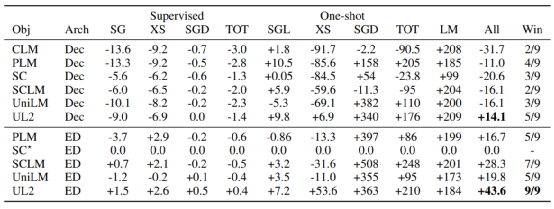
表3. 对比标准编码器-解码器模型的相对性能
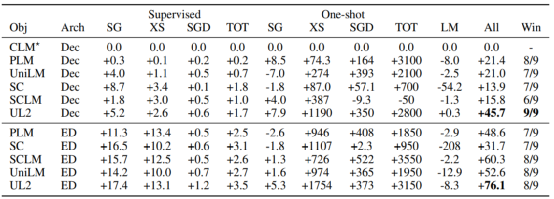
表4. 对比GPT类模型的相对性能
当使用 T5 作为参考基线时,除了 UL2 解码器,没有一个预训练的解码器模型优于 T5。此外,整体相对性能下降了 10% 到 30%。
这里最好的解码器基线模型是 Prefix-LM 解码器模型,它比 T5 基线差大约 10%。从这些结果中可以清楚地看出,当且仅当不考虑存储时,编码器-解码器模型应该优于仅解码器模型。
基于与类似 GPT(因果 LM + 解码器)和类似 T5(跨度损坏 + 编码器解码器)设置的相对比较,能够轻松确定完善的设置是否确实是最优的或已经接近最优的。首先,因果 LM(如GPT)设置似乎是更差的配置,因为它优于所有的基线。
因此,团队使直截了当建议尽可能至少使用 Prefix-LM 或 UniLM 进行训练。最好的仅解码器模型(UL2 除外)是 Prefix-LM 预训练,它为语言模型保留一个内存前缀以作为条件。关于 Prefix-LM 预训练,有趣的是 Prefix-LM 实际上比 T5 span 损坏设置好 +16.7%。Prefix-LM 编码器-解码器模型确实不如 SuperGLUE 上的默认 T5 模型有效,但总的来说,它更强大,尤其是在一次性或开放文本生成方面。
总体而言,在 Prefix LM 和跨度损坏编码器 - 解码器模型 (T5) 之间,尚不清楚哪个是普遍优越的模型,因为在不同的子任务之间存在给予和接受,尽管值得注意的是 Prefix-LM EncDec 模型只轻微牺牲了某些任务的性能,而其他任务的性能却大幅增加了数倍。
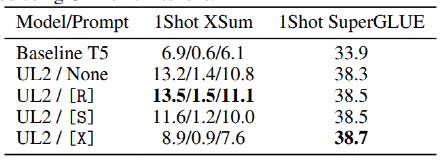
表5. one-shot实验结果
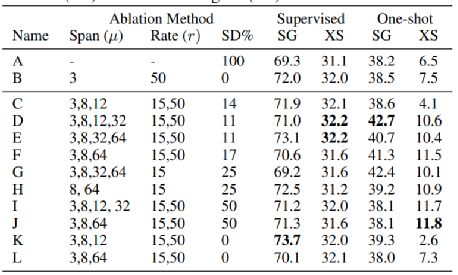
表6. Mixture-of-Denoisers的消融实验结果
为了确定模式切换能力对性能有影响,团队进行了消融实验,用 one-shot XSum 和 one-shot SuperGLUE 进行实验。表 5 报告了改变范式提示给模型的结果。
首先观察到的是提示对模型性能有相当大的影响,即使用正确或错误的提示会导致 48% 的性能差距。
另一方面,SuperGLUE 对提示不太敏感。在 SuperGLUE 上,使用提示几乎总是比在一次性评估期间不使用提示要好。然而,对于 XSum,获得正确的提示似乎对于良好的性能至关重要。
总而言之,本文提出了一种新的范式来训练普遍有效的模型。
1、提出了一种新的降噪器混合 (MoD) 预训练,它将多个预训练任务混合。
2、引入了模式切换,一种将下游任务行为与上游预训练相关联的方法。
此外,大量实验表明,UL2 在大多数的有监督和少样本任务上始终优于 GPT 类模型和T5模型,在9个任务上优于 T5,归一化后的整体增益提升76.1%。最后,UL2 扩展到20B参数,并在60 个 NLP 任务进行了多样化的实验。结果表明,UL2 在其中的 50 个下游任务上都实现了SOTA的性能。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: