
【论文解读】使用文本相似性模型扩充 user-item 图
【Augmenting the User-Item Graph with Textual Similarity Models】
这也是 Google Pair 团队的研究,另外一篇推荐系统相关的~
这篇主要是讲的推荐系统数据增强相关的研究。
0. 摘要
本文介绍了一种通过将释义相似性模型应用于广泛可用的文本数据(例如评论和产品描述)来增强推荐系统中的数据的方法。由此产生的新语义关系被添加到用户-项目图中,这增加了图的密度而不需要额外的标记数据。数据增强技术在使用不同类型空间的各种推荐算法和三类亚马逊产品评论上进行了评估。结果表明,数据增强技术可以显著改进所有类型的模型,在冷启动设置中基于知识图谱的推荐系统的收益尤其显著,从而获得最先进的性能。
1. 介绍
本文介绍了一种改进推荐系统的方法,该方法通过使用从产品描述和评论等文本数据中派生的语义关系来扩充数据。
这些关系是使用预训练的语义相似性模型创建的,并被添加到 user - item 图中,以补充从交互中学习到的隐式 user-user 和 item-item 相似性。数据增强技术在各种推荐模型(包括知识图谱推荐系统)上进行了评估,并被证明在冷启动设置中特别有效。
使用不同的几何空间(包括欧几里德空间、复数空间和双曲空间)比较增强模型的性能,发现在双曲空间中效果最好。
该论文还表明,与从原始文本中提取潜在特征的基线方法相比,所提出的技术在减少泛化误差方面更有效。
最后,本文讨论了使用数据依赖偏差(使用从文本派生的关系来增强图形)和几何偏差(选择几何空间来嵌入关系)来提高推荐性能。
2.挖掘语义关系
motivation
文本评论和项目描述可用于推荐系统,以改进潜在特征学习并做出更好的推荐。传统的方法是在矩阵分解中使用这些特征,但这可能会给模型带来负担,并且可能并不总能带来显著的性能提升。
另一种方法是利用文本相似性模型的进步,为推荐系统提供基于内容的明确相似性,而无需监督或增加计算复杂性。这可以通过基于计算的文本相似性向交互图添加新边来完成,这可以作为有效的正则化器并增加图的密度,特别是在冷启动场景中。
method
作者的目标是通过基于文本描述和项目评论之间的语义相似性,使用 item-item 关系来扩充 user-item 交互图,从而改进推荐系统的推荐。为此,我们收集了每个项目的所有可用文本,使用各种启发式方法对其进行过滤,然后使用通用句子编码器 (USE) 计算 text embedding。每个 item 的最终 embedding 是其各个评论或描述符的 embedding 的平均值。然后,该方法使用余弦相似度计算项目对之间的相似度,并将前 k 个最高相似度分数作为交互图中的关系添加。此过程旨在通过合并来自项目描述和评论的附加信息来改进系统的推荐。
3. REPRESENTING THE GRAPH
知识图谱
知识图谱是一种多关系图,其中节点表示实体,类型化的边表示这些实体之间的关系。这些图通常用于表示和查询异构知识,通常表示为一组(头、关系、尾)三元组。要使用知识图谱,通常要学习图中实体和关系的向量表示,以便保留图的结构。这些表示通常采用实体的 h,t 向量和关系的 r 向量的形式,并且使用评分函数 𝜙 评估三元组正确的可能性。然后可以在下游应用程序中使用这些矢量表示。
推荐系统的知识图谱
知识图谱嵌入方法已广泛用于推荐系统,作为一种合并辅助信息和提高性能的方法。这些方法允许用户、项目和其他实体之间的多种关系在知识图中表示并合并到推荐系统中。这可以降低过度拟合的风险并提高模型的泛化能力,并允许系统学习可用于推荐的不同类型的实体交互。然而,以前的工作大多只应用了比较有限的方法,例如翻译方法,并没有利用更新的和表达性更强的方法,这些方法已经在知识图谱完成任务上取得了最先进的性能。这些较新的方法包括将图形嵌入非欧几里德几何中的方法,例如双曲空间,或使用复数或四元数代数。
在下表中,我们展示了 KG embedding 方法及其 operator ,以及他们已应用的推荐系统的工作。
方法比较
RotatE 是一种表示复杂向量空间中的实体和关系的方法,并将关系定义为源实体和目标实体之间的复杂平面中的旋转。MuRP 是一种基于头部实体上的特定关系 Möbius 乘法和尾部实体上的 Möbius 加法对三元组 (h, r, t) 的可能性进行评分的方法。RotRef 是 MuRP 的扩展,包括双曲空间中的旋转和反射,并将这些操作的结果与切线空间中的注意力机制相结合。
图增强
这里使用 item 之间的语义关系来扩充 user-item 图的方法,例如产品和品牌之间的关系,或者电影导演和演员之间的关系。添加这些语义关系可以修改图的大小和结构,从而影响对图进行操作的最佳 embedding 空间。
4. 交互图分析
本文讨论了使用 embedding 来表示欧几里德空间中的图形。作者指出,许多现实世界的图形都表现出非欧几里得特征,例如幂律度数分布和无标度网络的属性,这表明存在潜在的双曲几何。作者旨在了解哪种类型的黎曼流形作为这些类型的图的嵌入空间是更好的选择。他们分析了图的结构和几何属性,发现当他们用额外的关系扩充图时,添加的边会修改它的连通性和结构,使其更像双曲线。
Data
亚马逊数据集(Amazon dataset), 亚马逊数据集是推荐系统的标准基准,并以文本描述的形式提供项目评论和元数据。作者重点关注“乐器”、“视频游戏”和“艺术、手工艺和缝纫”类别,这些类别在规模和领域上形成了多样化的数据集。除了向图中添加语义关系外,作者还包括在之前的工作中探索过的关系,例如“also_bought”、“also_view”、“category”和“brand”。下表指出了添加到最终增强图中的每种关系类型的数量。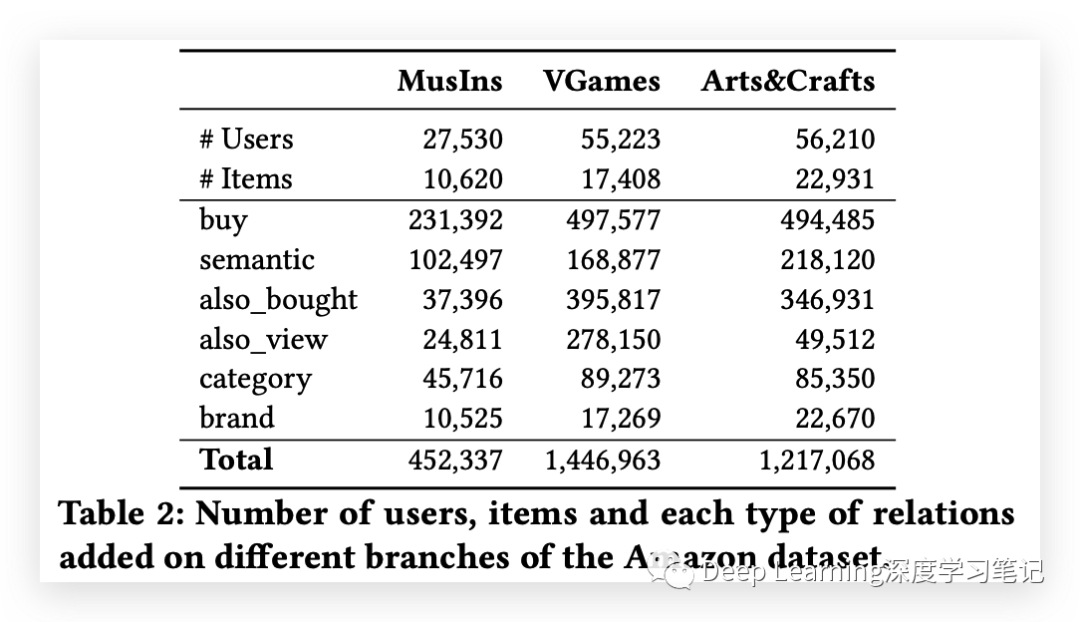
Hyperbolic Geometry(双曲线几何)
双曲几何是具有常负曲率的非欧几何。它非常适合嵌入具有层次结构的数据,因为随着点远离原点,空间量呈指数增长,这反映了树中节点随着与根的距离增加而呈指数增长。在这项工作中,作者分析了在 n 维庞加莱球中运行的模型,这是一个由方程 定义的双曲空间区域 < 1. 该空间中两点 x 和 y 之间的距离由以下方程定义: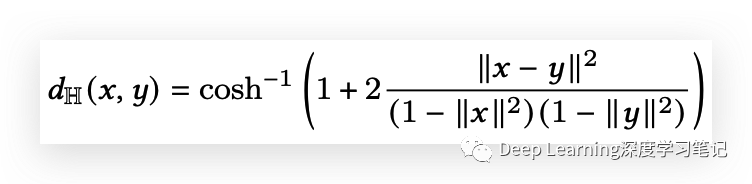
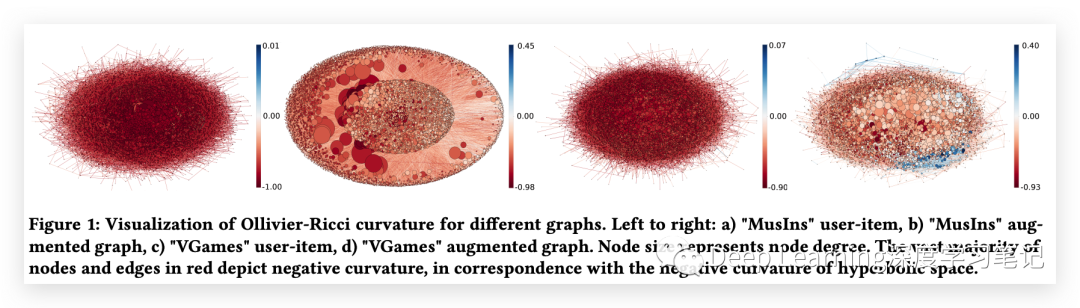
曲率分析
曲率是描述物体局部形状的属性。正曲率对应于像球体这样的表面,其中平行路径彼此靠近,而负曲率对应于像 spheres 这样的表面,其中平行路径往往相距更远。在这项工作中,作者应用 Ollivier-Ricci 曲率对图进行分析,发现 user-item 图中的节点和边表现出非常负的曲率。随着更多的关系被添加到图中,它变得更加 connected,但整体曲率仍然是负的。作者认为,这种负曲率对应于双曲空间的负曲率,这种几何对 user-item 图和扩充图都更好。
𝛿-双曲性
-双曲性,也称为 Gromov 双曲性,是给定度量空间的双曲性的度量。它被计算为一个单一的数字,较小的值表示一个更双曲线或负弯曲的空间。该度量也适用于图形,下表显示了 均值和 最大值。
他们发现,将 user-item 图与扩充图进行比较时,这两种度量都会降低,这表明扩充图更像双曲线。
5. 实验
实验部分主要是比较在推荐系统中生成推荐的各种知识图谱 (KG) 技术,重点是那些在双曲线空间中操作的技术。作者在 Amazon 数据集上评估了几种 KG 方法以及几种基线推荐系统的性能。他们比较了两种设置的结果:一种仅使用 user-item 交互,另一种使用添加了关系的图表。他们使用归一化的折扣累积增益和命中率作为评估指标。
作者旨在回答几个研究问题,包括 KG 方法与其他推荐系统相比的表现如何、数据扩充的影响以及不同关系在改进推荐中的重要性。他们发现 KG 方法通常优于基线推荐系统,并且数据增强可以显著提高性能。他们还发现某些关系对于改进推荐比其他关系更重要。
6. 实验结果和讨论
Performance over user-item graph
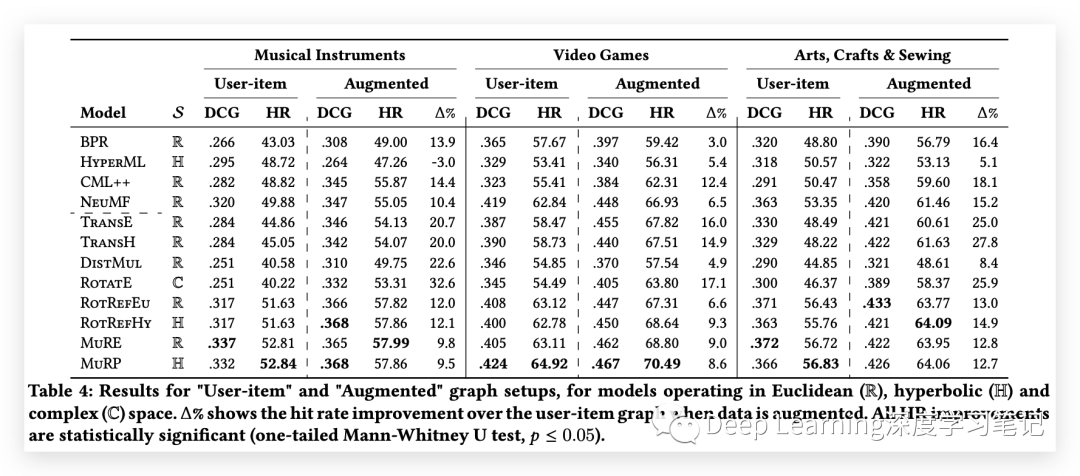
与 user-item 结果中的其他推荐系统和知识图谱方法相比,NeuMF 模型似乎表现得非常好。RotRef 和 MuR 也表现良好,尽管它们被设计为处理多关系图并且在这种情况下只被提供单一类型的关系。仅应用于 user-item 图的 KG 方法也表现出高性能。建议将这些 KG 方法用作未来推荐系统研究的 strong 基线。
利用增强数据
详细见上表,所有模型,包括推荐系统和知识图谱方法,在增强图上训练时都显示出改进的性能,一些模型的性能提升高达 32.6%。用于创建增强图的致密化过程通过在实体之间添加有意义的关系来减少稀疏性。RS 模型不是为合并多关系信息而设计的,它仍然受益于扩展的训练集,并且能够以改进推荐的方式对用户和项目进行聚类。TransE 和 TransH 在添加关系后表现出特别大的相对性能提升,而 HyperML 和 CML++ 并没有表现出那么大的提升。MuR 和 RotRef 是此设置中性能最好的模型。双曲线和欧几里德模型也显示出有竞争力的结果,在某些情况下,MuRP 优于其欧几里德模型。Advanced KG 方法表现出比旧方法更好的性能,并且优于为两种设置中的任务设计的 RS 模型。
关系消融(Relation Ablation)
研究了个体关系对 MuRP 模型性能的贡献,结果表明每个关系都带来了 user-item 图的改进。发现语义关系在“Musical Instruments”分支中表现最好,而 also_bought 关系在其他两个分支中更有帮助。对于测试集中数据集的所有分支,所有关系的组合都优于单独的设置。在“冷启动”设置中,重点是交互次数最少的 2% 的用户,语义关系带来了最显著的性能提升,尤其是对于稀疏用户和项目。在某些情况下,“Cold Test” 的性能也被发现优于 “Test”,这可能是由于当用户与不同 item 进行大量交互时,很难将用户 embeddings 放置在接近他们所有偏好的位置。
评论的作用
Relations vs Features
将语义关系从文本描述中合并辅助信息的有效性与之前工作中合并潜在特征的不同方法进行了比较。结果表明,对于某些模型,语义关系比潜在特征带来了更大的改进,并且它们可以与潜在特征有效结合,为推荐提供补充信息。通常,语义关系被发现是对从文本数据中提取的信息进行建模的有效方法。详见下表。
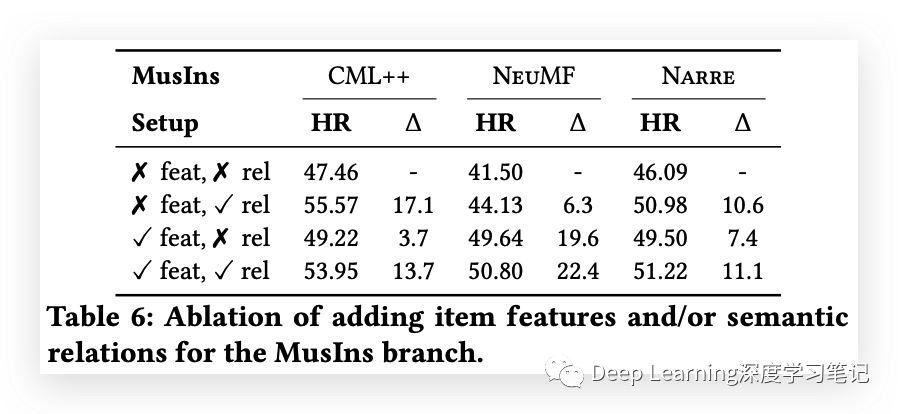
语义关系的文本类型
这里分析了不同类型的文本在提取特征和捕获项目相似性方面的有用性。结果发现,在关系之上添加特征会降低 CML++ 的性能,而 NeuMF 在移除特征后性能会急剧下降。不使用任何特征的 MuRP 在将元数据与最长评论相结合的文本用于学习项目相似性时表现最佳。仅使用元数据也显示出具有竞争力的性能。没有发现具有高情绪极性的评论对于捕获项目相似性有用。结果表明,将最长的评论与元数据相结合是了解项目相似性的最有用方法,但也可以单独利用元数据来获得有竞争力的结果。
Encoder 分析
本研究比较了三种不同的预训练编码器以无监督方式捕获文本相似性的性能:USE、BERT 和 Sentence-BERT。MuRP 模型用于分析这些编码器在过滤可用文本的四种不同标准下的有用性。结果发现,BERT 在用于扩展具有语义关系的 user-item 图时表现不佳,而 Sentence-BERT 比 BERT 有一些改进。USE 被发现是找评论和元数据相似性的最有效编码器,因为它能够识别 item 之间更广泛的相似性。
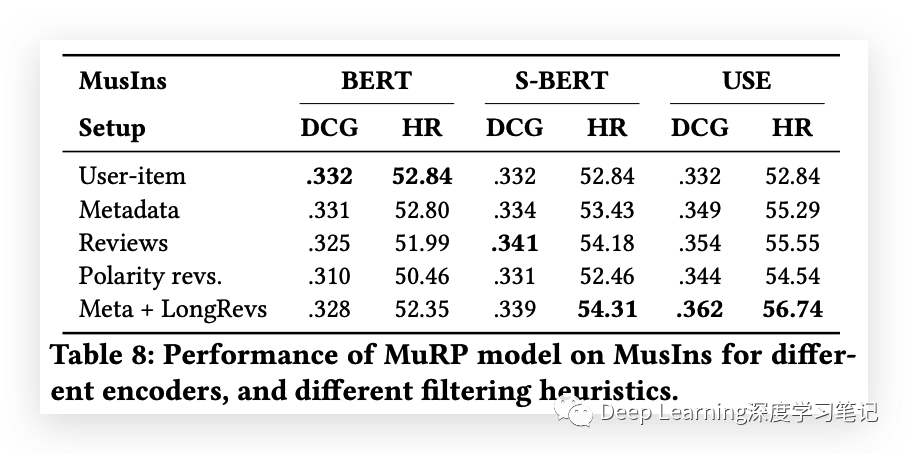

度量空间分析
实验表明,双曲线方法可以改进在欧几里德空间或复数中运行的系统,并且特别擅长嵌入层次结构。另外,发现双曲线模型中嵌入的范数与相应类别的交互次数相关,而欧几里德模型则没有相关性。在重建由双曲线和欧几里得模型学习的层次结构时,发现双曲线模型更简洁和精确,而欧几里得模型噪声更大。这表明双曲线模型能够自动推断由标签分布产生的层次结构,并因此提供更具可解释性的空间。
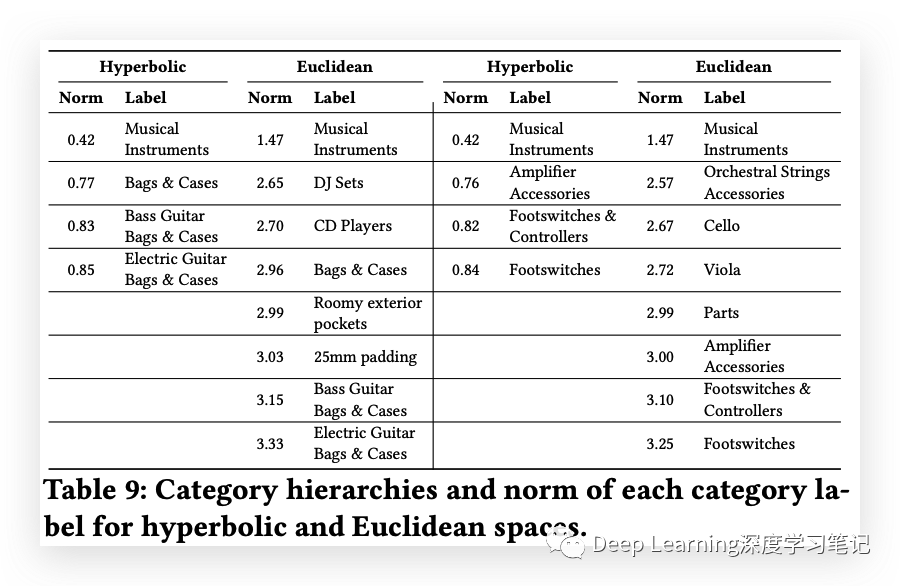
7. RELATED WORK
数据增强
这里提出了一种新的无监督方法,用于基于应用于文本属性的语义文本模型来学习项目或用户之间的相似关系。该方法扩展了之前将评论信息作为正则化技术的研究,并显著提高了推荐系统中冷启动问题的性能。数据增强在机器学习中很重要,因为它可以在不影响模型容量的情况下减少泛化误差,并且已以各种方式应用于推荐系统,例如扩展共同购买的产品、生成伪 user-item 交互以及利用项目端信息。
使用文本的推荐
在之前的研究中,从评论中挖掘的文本已被用于改进推荐系统,作为正则化器或学习更好的用户和 item 表示。然而,一些研究人员认为,评论在推荐系统中的作用被夸大了,它们的好处仅限于某些条件。这里提出了一种使用文本通过数据增强来改进推荐系统的方法,它可以在不增加用户和项目表示的情况下改进它们的大小,也不会像正则化方法那样直接限制模型的表达能力。
知识图谱推荐
这里比较了 RS 中各种 KG embedding 方法的性能。结果表明,当使用数据增强时,较新的 KG embedding 方法的性能明显更好,并且优于以前的 KG 推荐系统和其他最先进的 RS。这表明数据增强可能是提高基于 KG 的 RS 性能的有用方法,并且更新的 KG embedding 方法在这种情况下特别有效。
双曲线空间
双曲空间被发现在各种应用中都很有用,包括问答、机器翻译、语言建模、层次分类和分类细化。在推荐系统 (RS) 中,双曲几何已被观察到在某些数据集中自然出现,并且双曲空间已与度量学习方法结合使用。这里检查了双曲线方法的使用,通过数据扩充扩展用户项目图并分析由此产生的双曲线空间的属性,从而提高 RS 中推荐的可解释性和性能。
8. 总结
在这项工作中,基于将预训练语言模型应用于广泛可用的文本属性,提出了一种无监督数据增强技术,通过向用户项目图添加语义关系来改进推荐系统 (RS)。
这里提出了一种简单的无监督数据增强技术,可以将语义关系添加到 user-item 图中,基于将预训练的语言模型应用到广泛可用的文本属性。这可以被认为是一个数据依赖的先验引入有效的归纳偏置,而不会增加推理时模型的计算成本。
这种技术被证明可以提高各种现代知识图谱 (KG) 方法的性能,包括那些不是为处理多关系信息而设计的方法,并且在冷启动设置中特别有效。发现使用评论或简短的产品描述作为文本输入是有效的。该技术还被发现受益于在双曲空间中的操作,这提高了推荐的可解释性。建议进一步研究以探索这些结果对 denser domains 的普遍性。
Reference:
论文原文: https://arxiv.org/abs/2109.09358
Google Pair: https://pair.withgoogle.com/tools/
知乎: https://zhuanlan.zhihu.com/p/596123817