
用 Python 爬取 QQ 空间说说和相册
回复“书籍”即可获赠Python从入门到进阶共10本电子书

文 | 某某白米饭
来源:Python 技术「ID: pythonall」
 QQ 空间在 2005 年被腾讯开发,已经经历了 15 个年头,在还没有微信的年代,看网友发表的心情、心事、照片大多都在 QQ 空间的里。它承载了80、90 后的大量青春,下面我们一起用 selenium 模块导出说说和相册回忆青春吧
QQ 空间在 2005 年被腾讯开发,已经经历了 15 个年头,在还没有微信的年代,看网友发表的心情、心事、照片大多都在 QQ 空间的里。它承载了80、90 后的大量青春,下面我们一起用 selenium 模块导出说说和相册回忆青春吧
安装 selenium
selenium 是一个在浏览器中运行,以模拟用户操作浏览器的方式获取网页源码,使用 pip 安装 selenium 模块
pip install selenium
查看 chrome 浏览器版本并下载 对应的 chrome 浏览器驱动
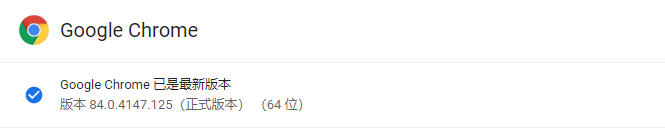
在 http://npm.taobao.org/mirrors/chromedriver 网址中找到相同版本的 chrome 驱动,并放在 python 程序运行的同一个文件夹中
登陆
按 F12 检擦网页源代码,找到登录和密码的文本框,如下图所示
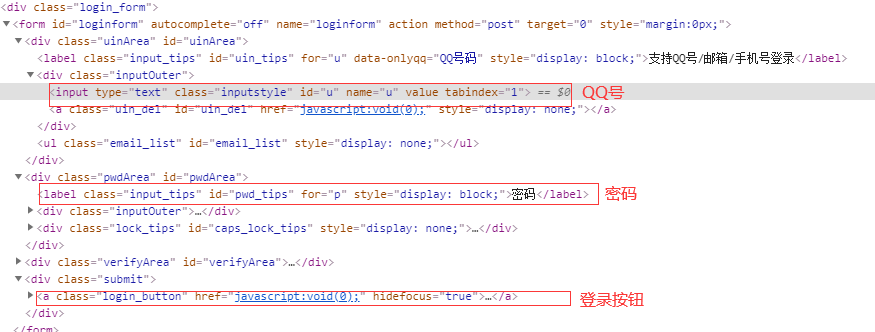
def login(login_qq,password, business_qq):
'''
登陆
:param login_qq: 登陆用的QQ
:param password: 登陆的QQ密码
:param business_qq: 业务QQ
:return: driver
'''
driver = webdriver.Chrome()
driver.get('https://user.qzone.qq.com/{}/311'.format(business_qq)) # URL
driver.implicitly_wait(10) # 隐示等待,为了等待充分加载好网址
driver.find_element_by_id('login_div')
driver.switch_to.frame('login_frame') # 切到输入账号密码的frame
driver.find_element_by_id('switcher_plogin').click() ##点击‘账号密码登录’
driver.find_element_by_id('u').clear() ##清空账号栏
driver.find_element_by_id('u').send_keys(login_qq) # 输入账号
driver.find_element_by_id('p').clear() # 清空密码栏
driver.find_element_by_id('p').send_keys(password) # 输入密码
driver.find_element_by_id('login_button').click() # 点击‘登录’
driver.switch_to.default_content()
driver.implicitly_wait(10)
time.sleep(5)
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
return driver
except:
print('不能访问' + business_qq)
return None
说说
登录 QQ 后默认的页面就在说说的界面,显示一页的说说是滚动加载的,必须要多次下拉滚动条后才能获取到该页所有的说说,然后用 BeautifulSoup 模块构建对象解析页面,下图是放说说的 iframe
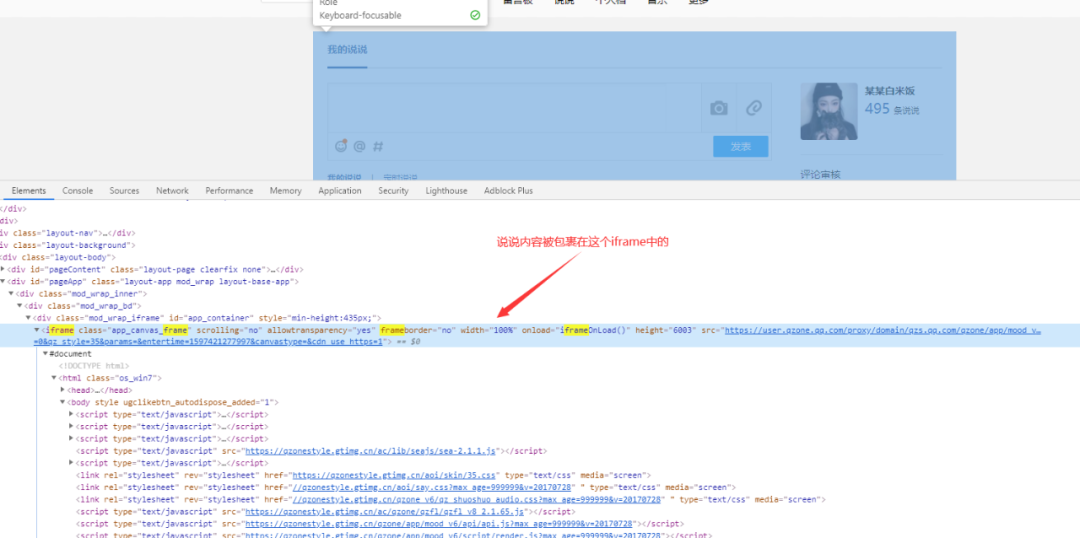
def get_shuoshuo(driver):
page = 1
while True:
# 下拉滚动条
for j in range(1, 5):
driver.execute_script("window.scrollBy(0,5000)")
time.sleep(2)
# 切换 frame
driver.switch_to.frame('app_canvas_frame')
# 构建 BeautifulSoup 对象
bs = BeautifulSoup(driver.page_source.encode('GBK', 'ignore').decode('gbk'))
# 找到页面上的所有说说
pres = bs.find_all('pre', class_='content')
for pre in pres:
shuoshuo = pre.text
tx = pre.parent.parent.find('a', class_="c_tx c_tx3 goDetail")['title']
print(tx + ":" + shuoshuo)
# 页数判断
page = page + 1
maxPage = bs.find('a', title='末页').text
if int(maxPage) < page:
break
driver.find_element_by_link_text(u'下一页').click()
# 回到主文档
driver.switch_to.default_content()
# 等待页面加载
time.sleep(3)
相册
下载相册里面的照片需要 selenium 模块模拟鼠标一步步点击页面,先点击上方的相册按钮,进去就是多个相册的列表,下图是单个相册的超链接
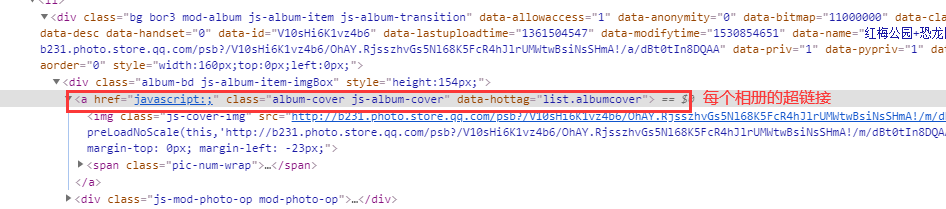
在单个相册中点击照片,界面如下图
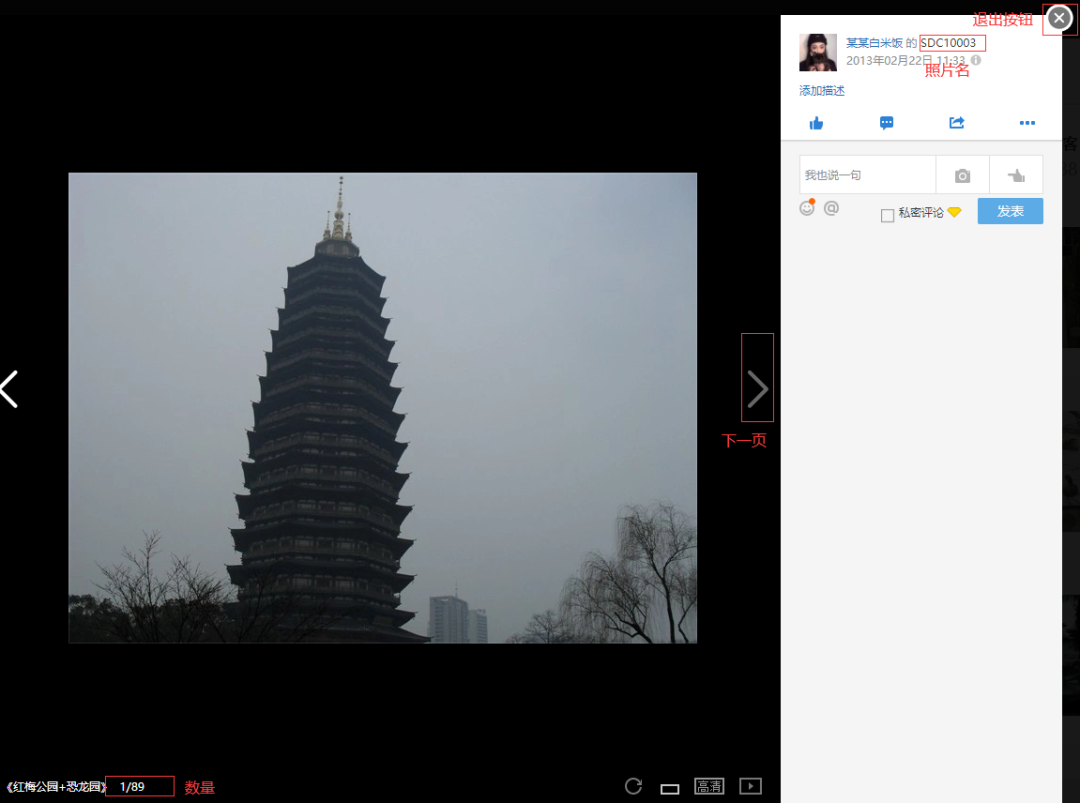
def get_photo(driver):
# 照片下载路径
photo_path = "C:/Users/xxx/Desktop/photo/{}/{}.jpg"
# 相册索引
photoIndex = 1
while True:
# 回到主文档
driver.switch_to.default_content()
# driver.switch_to.parent_frame()
# 点击头部的相册按钮
driver.find_element_by_xpath('//*[@id="menuContainer"]/div/ul/li[3]/a').click()
#等待加载
driver.implicitly_wait(10)
time.sleep(3)
# 切换 frame
driver.switch_to.frame('app_canvas_frame')
# 各个相册的超链接
a = driver.find_elements_by_class_name('album-cover')
# 单个相册
a[photoIndex].click()
driver.implicitly_wait(10)
time.sleep(3)
# 相册的第一张图
p = driver.find_elements_by_class_name('item-cover')[0]
p.click()
time.sleep(3)
# 相册大图在父frame,切换到父frame
driver.switch_to.parent_frame()
# 循环相册中的照片
while True:
# 照片url地址和名称
img = driver.find_element_by_id('js-img-disp')
src = img.get_attribute('src').replace('&t=5', '')
name = driver.find_element_by_id("js-photo-name").text
# 下载
urlretrieve(src, photo_path.format(qq, name))
# 取下面的 当前照片张数/总照片数量
counts = driver.find_element_by_xpath('//*[@id="js-ctn-infoBar"]/div/div[1]/span').text
counts = counts.split('/')
# 最后一张的时候退出照片浏览
if int(counts[0]) == int(counts[1]):
# 右上角的 X 按钮
driver.find_element_by_xpath('//*[@id="js-viewer-main"]/div[1]/a').click()
break
# 点击 下一张,网页加载慢,所以10次加载
for i in (1, 10):
if driver.find_element_by_id('js-btn-nextPhoto'):
n = driver.find_element_by_id('js-btn-nextPhoto')
ActionChains(driver).click(n).perform()
break
else:
time.sleep(5)
# 相册数量比较,是否下载了全部的相册
photoIndex = photoIndex + 1
if len(a) <= photoIndex:
break
示例结果

总结
大家在看十几年前的说说和照片是不是感觉满满的黑历史快要溢出屏幕了。时光荏苒、岁月如梭,愿一切安好。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~