
AI能读懂40种语言,15个语种拿下22项第一,背后是中国团队22年坚守
新智元
共 5393字,需浏览 11分钟
·
2021-11-26 16:33

新智元报道
新智元报道
编辑:好困 桃子
【新智元导读】怎样才叫打破语言界的天花板?一次拿下15个语种22项第一,还让机器读懂40多种语言。能够在多语种语音语言领域制霸的背后是中国团队22年对顶天立地这一理念的坚守。

第一的背后
The heat required for boiling the water and supplying the steam can be derived from various sources, most commonly from burning combustible materials with an appropriate supply of air in a closed space (called variously combustion chamber, firebox). In manchen Fällen ist die Wärmequelle ein Atomreaktor, Erdwärme, Solarenergie oder Abwärme von einem Verbrennungsmotor oder einem Industrieprozess. En el caso de modelos o motores de vapor de juguete, la fuente de calor puede ser un calentador eléctrico.
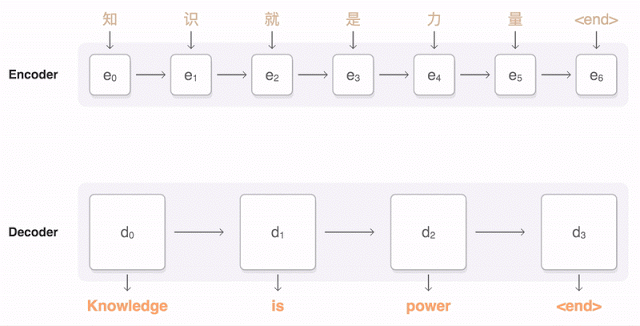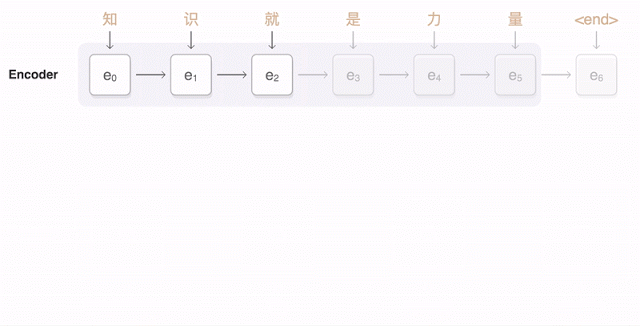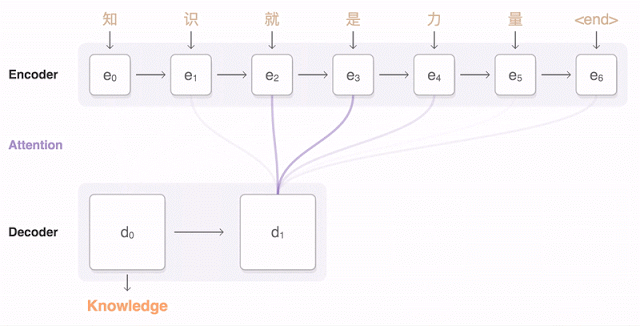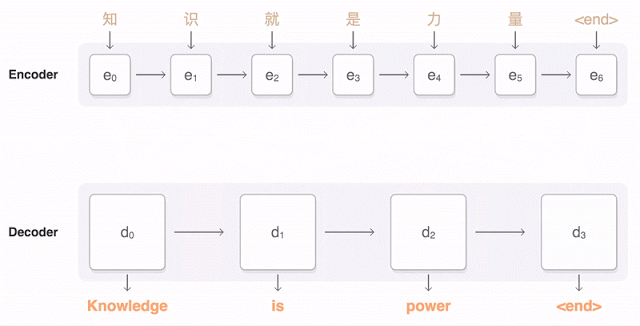
让水沸腾以提供蒸汽所需热量有多种来源,最常见的是在封闭空间(别称有 燃烧室 、火箱)中供应适量空气来燃烧可燃材料 。在某些情况下,热源是核反应堆、地热能、 太阳能或来自内燃机或工业过程的废气。如果是模型或玩具蒸汽发动机,还可以将电加热元件作为热源。

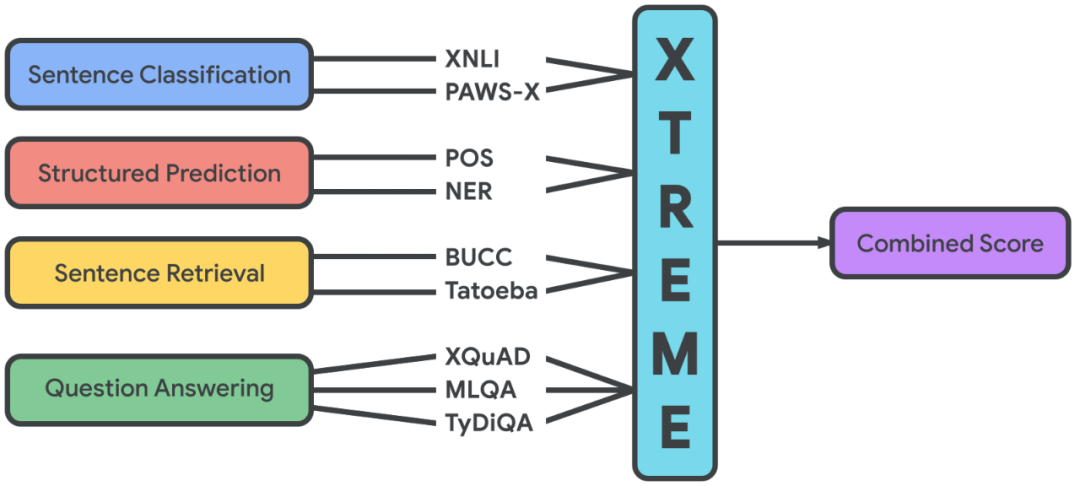
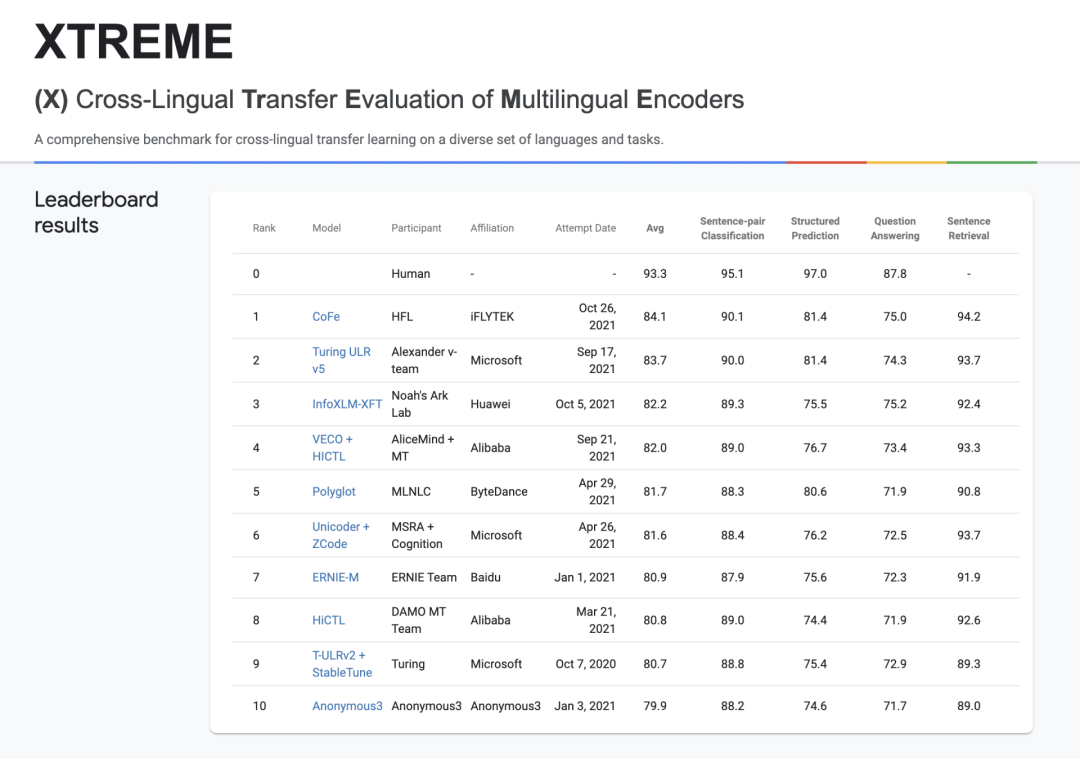
句对分类:XNLI、PAWS-X(自然语言推断) 序列标注:UDPOS(词性标注)、PANX (命名实体识别) 阅读理解:XQuAD、MLQA、TyDiQA(片段抽取型阅读理解) 句子检索:BUCC、Tatoeba(跨语言文本检索)
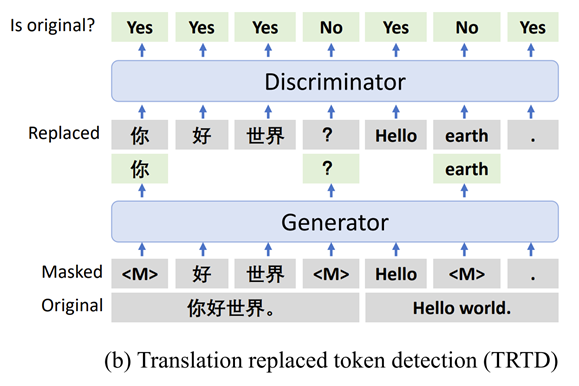
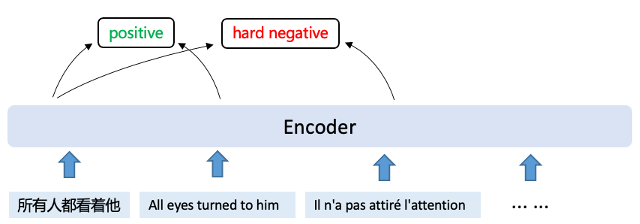
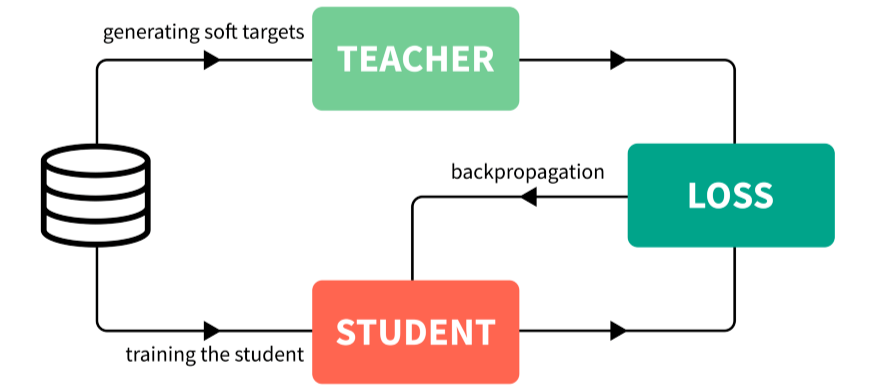
通过自监督训练,让模型自我蒸馏,提升稳定性;
多语-单语的多到一知识迁移。所谓三人行必有我师,让多语言学生模型从多个单语言教师模型学习知识,博采众长;
多语言多模型蒸馏。将多个多语言教师蒸馏至单一模型,从而提供更优的教师指导信号。

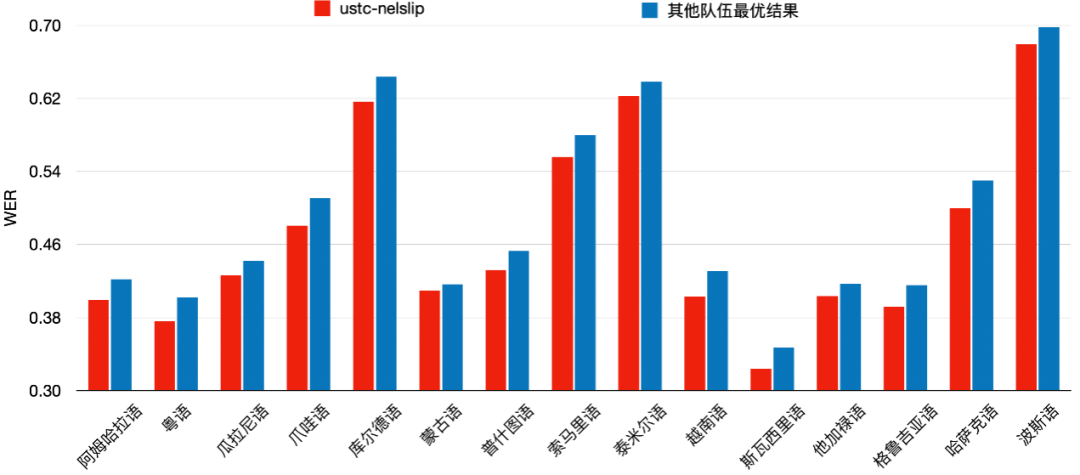
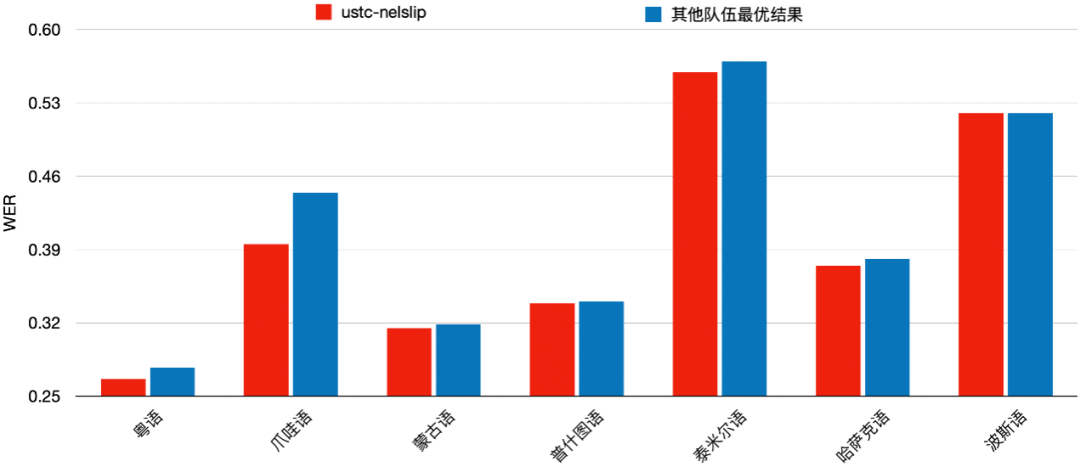
语言 | 语言 | 语言 |
粵语 | 普什图语 | 他加禄语 |
瓜拉尼语 | 索马里语 | 格鲁吉亚语 |
爪哇语 | 泰米尔语 | 哈萨克语 |
库尔德语 | 越南语 | 阿姆哈拉语 |
蒙古语 | 斯瓦西里语 | 波斯语 |
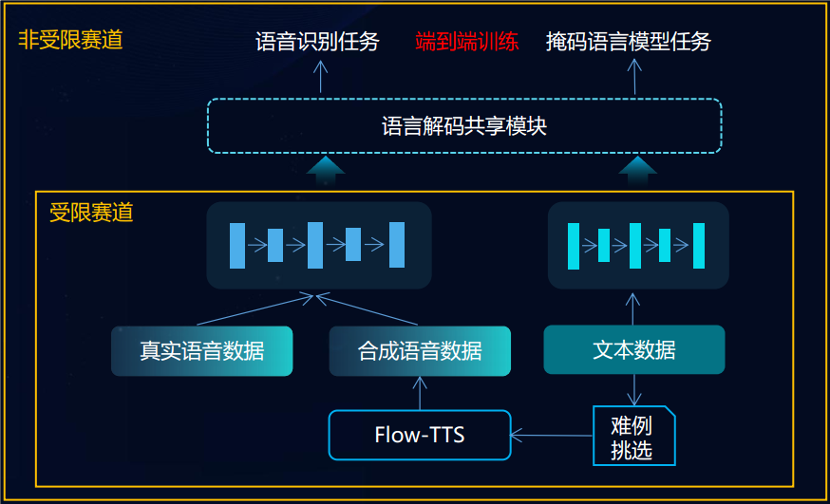
文本掩码语言模型任务、合成数据语音识别两个目标,两个任务联合训练以充分利用海量无监督文本;
共享语言解码模块,实现了语音和文本隐层表达空间的统一,大大缓解了低资源语种的数据稀疏问题。
顶天立地,22年坚守
顶天立地,22年坚守

今年5月份又发布了双屏翻译机,可以做到精准实时的翻译,而且有很多语种选择。
它光是中外互译就多达60种,还有5种中文方言与英语互译,2种难懂的民族语言(藏语和维吾尔语)也能与普通话互译。

用户可以一边说另一边就能翻译,只需按下时说话,松开即可翻译,能做到0.5秒疾速响应。
此外,讯飞的智能录音笔,也可以支持10个语种的语音转写和分离。
就拿SR302来说,不仅支持粤语、重庆话、贵州话等12种方言转写,同时还可进行英语、日语、法语等10大语种的转写。

参考资料:

评论