
底层进阶 | 移动端 GPU 架构 -- TBR 模型
共 3790字,需浏览 8分钟
·
2021-11-17 16:34
在知乎上关注了好多图形学大佬,感觉现在知乎的技术氛围要比掘金推荐旧文好多了,经常会推送感兴趣的领域内容,而且还可以和作者私信交流。
这段时间看到有大佬分享 GPU 架构相关的内容,做图像渲染的还是要懂 GPU 才行的,毕竟是和它打交道嘛。
这位大佬就是知乎作者:无缘补天的梧桐,主页连接如下:
https://www.zhihu.com/people/wu-tong-16-43
大佬分享了一些桌面端 GPU 架构的内容,写了很多干货文章:
【GPU】Tesla架构(一):初识GPU架构 https://zhuanlan.zhihu.com/p/403354366 【GPU】Tesla架构(二):血汗工厂 https://zhuanlan.zhihu.com/p/416334635 【GPU】Tesla架构(三):通用计算及其“物流网” https://zhuanlan.zhihu.com/p/425082340
最重要的作者还分享了一篇移动端 GPU 架构的文章,阅读之后受益良多,也分享给大家:
原文连接如下:https://zhuanlan.zhihu.com/p/433254219
以下是作者原文内容:
习惯了桌面端GPU的那一套玩法,初次接触移动端GPU会有许多新鲜感。
桌面端GPU,数据倾泻而下一路畅通无阻:顶点数据被分发到对应SM里的warp中,经过一通顶点运算后,就直接被甩到光栅化硬件里,然后碎成一堆片元,再次被裹挟到新warp中算出颜色值写回帧缓冲中。
整个过程的原则就是能跑多快跑多快,单看每个数据(顶点或片元),能找到其他31个同行跟我一起跑路就行,其他数据爱跑到哪跑到哪,跟我没有半毛钱关系。
桌面端GPU这套硬件流水线,跟逻辑管线较为接近。但这对硬件有一个最基础的要求:国道省道小村小路整套物流系统都得十分健全,以保证海量的数据能在这里面如鱼得水,玩命狂奔。而这,正是移动端GPU的死穴。
移动端GPU由于电源功率、芯片面积、布线以及封装等天生残缺,高带宽意味着高耗电,别说GPU,整个手机行业最大的短板就在电池上。
我们被迫向落后科技妥协的下限顶多是一天充一次电,打一局游戏就得充一次电然后还得为忍受发热练就铁砂掌的魔幻局面估计没人能够忍受。因此注重对功耗控制的移动端,那必然是要从GPU架构设计到图形算法上,都想方设法地压榨带宽消耗。毕竟帧数太少还可以靠人眼补帧,手机没电自动关机了那还玩个锤子。(•́へ•́╬)
这决定了移动端GPU,无法同桌面端GPU一样,采用围绕大量专用带宽而设计的即时模式渲染器(Immediate Mode Renderers, IMR)架构。当前主流的移动端GPU架构,如PowerVR、高通的Adreno和ARM的Mali,全是基于块的渲染(Tile-Based Rendering, TBR)架构。
如果看过我之前的GPU系列文章,可能大家对桌面端GPU里,总公司、分公司、每个工作室、物流仓储等紧密联系的各个模块会有些印象。
而移动端GPU的特点就是,负责运算的shader engine和外界能不交流就不交流,迫不得已要交流了,就打包成块快速交接,活像一个自闭少年。
类似英伟达的SM,拥有专有的高速缓存,每家名字都不一样,我之后就统一用mali的,省得混乱。
与八纵八横的发达铁路网不同,移动端GPU就像松散的封建老欧洲,因为山高水远,shader engine们就像一个个独立王国,尽可能包办一切。现在就让我们走进这个独立王国,来领略一下未曾见过的异域风情吧。
打包成块:第一次延迟
在桌面端,每个三角形都是自由自在的小精灵,大家按照提交顺序进入流水线。而移动端,我们遇到的第一件新鲜事就是——分块(Binning,PowerVR称为Tiling)。

主要流程如下:
每个三角形在运行完顶点着色器后,会将变换后的顶点存储在片内,而不是直接光栅化 将这些变换后的顶点进行图元组装、剔除、裁剪后,由Tilling引擎(该过程由专用的硬件单元负责,以确保足够高效)决定每个图元属于哪个tile,将图元地址存放到对应的per-tile list中(关于每一块包含哪些图元的信息,PowerVR称为Primitive List,Adreno称为Visiblity Stream) per-tile lists和变换后的图元(着色器状态、属性等)被存放到内存中的Parameter Buffer中
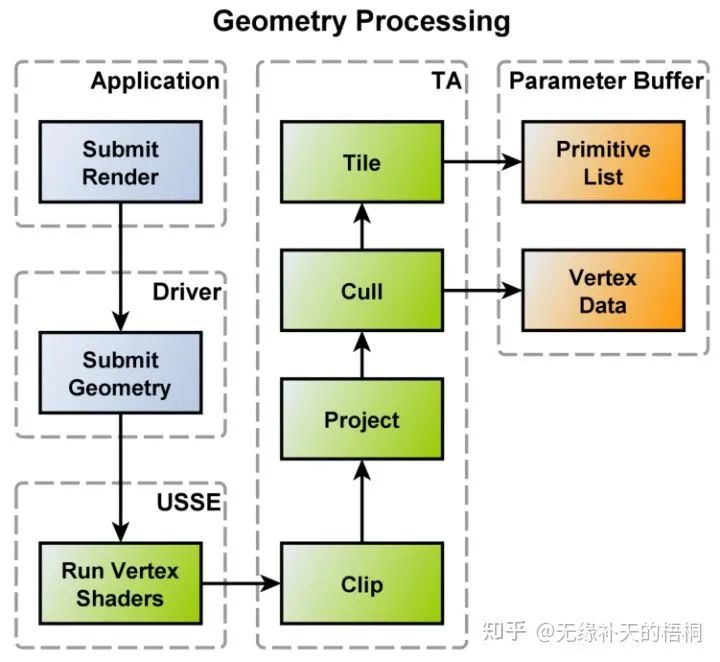
看到这儿,我们可能会迷惑?啥玩意儿?不是说带宽很紧张要勒紧裤腰带过苦日子吗?怎么还在主存里搞了这么一个buffer,在顶点着色器和光栅化之间横生枝节。顶点着色器运算完直接光栅化不香吗,非得传回主存然后再让shader engine读一遍,这不是自讨苦吃吗?
因为这是TBR为了之后巨大的带宽收益,不得不提前付出的些许带宽代价。
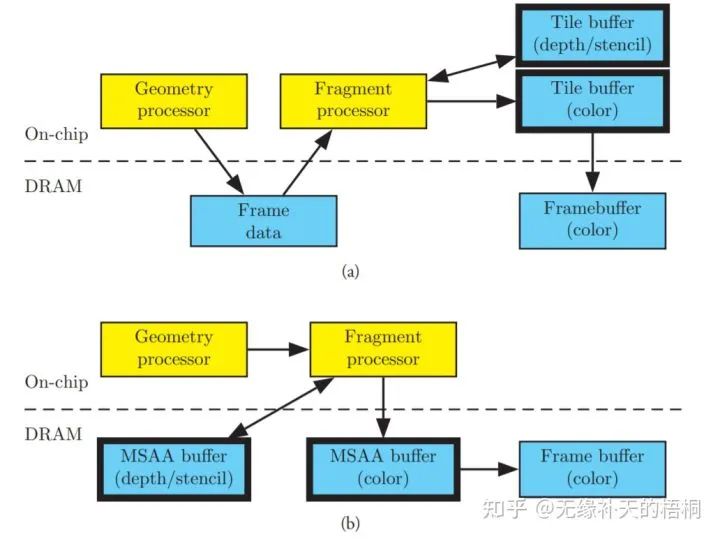
正因为这些代价,三角形们得以被打包切成了块,意味着其对应要绘制到的帧缓冲(包括深度缓冲)都可以切成块。
而这么一个小块交给一个单独的shader engine来全权负责就成为了可能。shader engine就可以将这么一小块帧缓冲存在自己内部的高速缓存中。
与IMR相比,大量深度缓冲和颜色缓冲的来回读写,被隔离在了片内的高速缓存中,每一块的帧缓冲在最终渲染完成后才会被写回主存。
这就是TBR所希冀的带宽节省带来的巨大收益!
绝不多算任何一个不必要的片元:第二次延迟
除了延迟光栅化以外,主流移动端GPU还会进一步延迟片元着色,以在像素级别上,实现overdraw的消除,即不将任何计算资源浪费在对最终渲染画面无关的片元上。
每一块的图元光栅化成片元后,会等待所有片元全部经过深度测试后才进行片元着色,以确保只有离视线最近的片元才会被着色。
由于专利原因和实现上的细微区别,该技术在不同架构中有不同的名称,PowerVR为HSR (Hidden Surface Removal),Adreno为Early Z Rejection,Mali为FPK (Forward Pixel Killing)。
与桌面端GPU常见的early-z硬件优化相比,这些技术不需要排序并从前往后绘制物体。且由于物体可能出现相交的复杂情况,early-z即使经过排序也只能实现粗糙的overdraw消除。
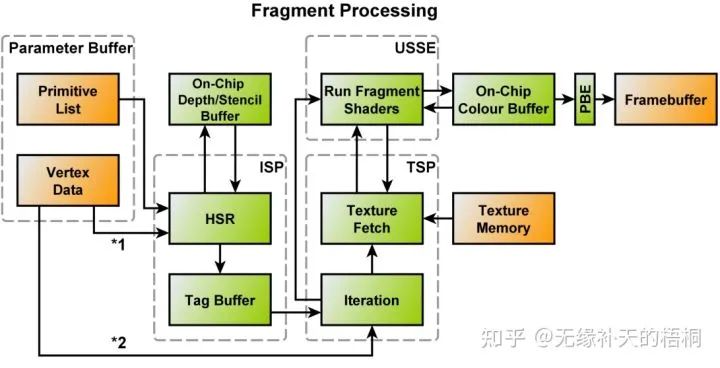
不过,有许多情况会影响硬件延迟片元着色的顺利进行:
半透明:会打断HSR,会强行渲染出当前所有最近片元,以便于混合。混合完后,如果紧接着又是不透明物体,则继续进行HSR。所以优化方案为:把半透明物体放最后画。
Alpha Test/Discard:会先将它当作不透明物体经过HSR,如果未通过深度测试无事发生;如果通过深度测试那就运行片元着色器,若最终被discard,那么就会回过头更新HSR。
各种绝境求生的骚操作
除了最主要的TBR架构外,移动端GPU为了尽可能节省带宽消耗,还有诸多丧心病狂的技术优化手段。比如:
MSAA所需的巨大存储压力现在也可以搭便车,只存在于片内高速缓存中,帧缓冲在片内混合完样本后再传出
在片元着色时,下一帧的顶点处理和Binning可以并行进行,当然这会带来进一步的延迟
将顶点着色器拆分成位置运算和其他属性运算,计算完位置后就进行Binning以进一步节省带宽
前后帧未变化的块不写回内存,甚至通过分析用户操作以及各种输入是否与前一帧都相同来直接避免某一块的运算,这对于大量画面都是静态的休闲手游而言,是十分实用的技术
还有许多硬件上的设计细节也全是为节省带宽和功耗而服务的,比如在高速缓存上仍然储存纹理的压缩格式、暂时没有任务的元器件直接休眠等……
除了功耗这一移动端GPU优化的核心指标以外,对于渲染画面的提升各大厂商也有自己的尝试。
Imagination Technologies早在2016年就展示了实时光线追踪测试板PowerVR GR6500,并计划在不久的将来推出基于PowerVR架构的GPU,支持高级硬件光线追踪加速器;
而在最近,三星与AMD合作,计划在2022年推出基于AMD的RDNA 2架构的Exynos 2200 GPU,将支持硬件级光线追踪。可以预见,消费级移动端光追硬件,将很快到来。
得益于移动端芯片架构的高效设计,苹果在2020年末推出的M1 Soc以及在2021年推出的M1 Pro和M1 Max,标志着桌面电脑开始转向ARM架构。
M1的GPU性能与之前的移动端GPU相比,有着巨大的提升,也证明了移动端GPU架构不仅在功耗控制上具有优势,在性能上也具有巨大潜力。
移动端和桌面端的GPU架构互相借鉴与融合,将成为未来GPU架构设计的主要趋势。

技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。
私信领取相关资料
推荐阅读:
觉得不错,点个在看呗~
