
人物属性模型移动端实验记录
共 17514字,需浏览 36分钟
·
2021-03-18 22:47
【GiantPandaCV导语】最近项目有需求,需要把人物属性用在移动端上,需要输出性别,颜值和年龄三个维度的标签, 用来做数据分析收集使用,对速度和精度有一定的需求,做了一些实验,记录如下。
一、模型
模型结构,这里考虑了两种形式,一种是多头的,一种是单头的,具体如下:
SingleHead backbone+avgpool后面 接一个卷积,卷积核为(inp, (gender_class+beauty_class+age_class), 3, 3) backbone+avgpool后面 接入一个channel shuff层, 再接入一个卷积,和第一种一样。 MutilHead backbone+avgpool后面,接入三个FC,每个FC对应一个维度的任务。 backbone+avgpool后面,先接入一个SE模块后,接三个FC,每个FC对应一个维度的任务。 backbone+avgpool后面,接入一个512维度的FC,后接入三个FC,每个FC对应一个维度的任务。 backbone+avgpool后面,接入三个512维度的FC来做embeeding,后接入三个FC,每个FC对应一个维度的任务。
如下图所示:
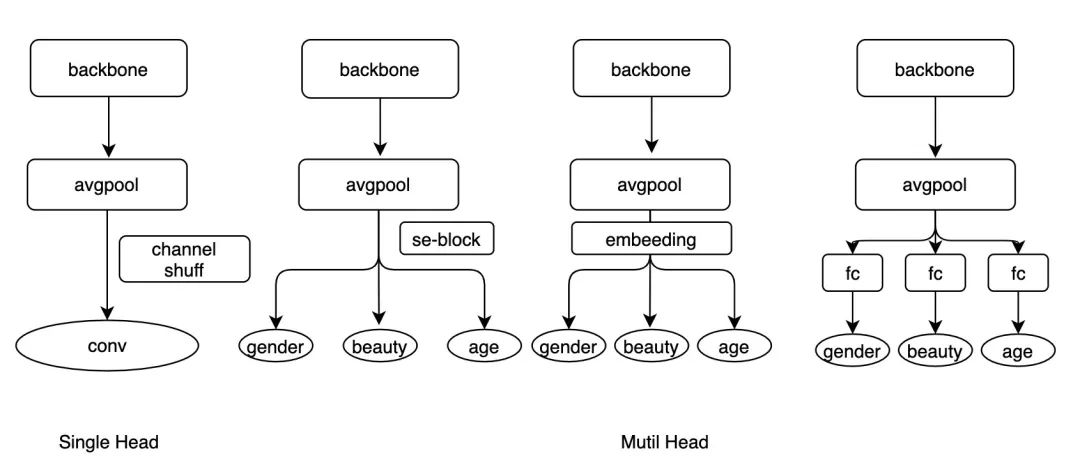
图1-不同模型结构
训练, 训练数据总计35w,每张图片都带有三个维度的标签,使用Horovod分布式框架进行训练,采用SGD优化器,warmup5个epoch,使用cosine进行衰减学习率,总计训练60个epoch,训练代码可以参考https://github.com/FlyEgle/cub_baseline。
实验对比,对于SingleHead模型,MutilHead的1,2模型,采用的是mobilenetv2作为backbone,对于MutilHead的3,4模型,采用的是mobilenetv2x0.5作为backbone。这里对比的baseline为resnest50的结果,结果如下:
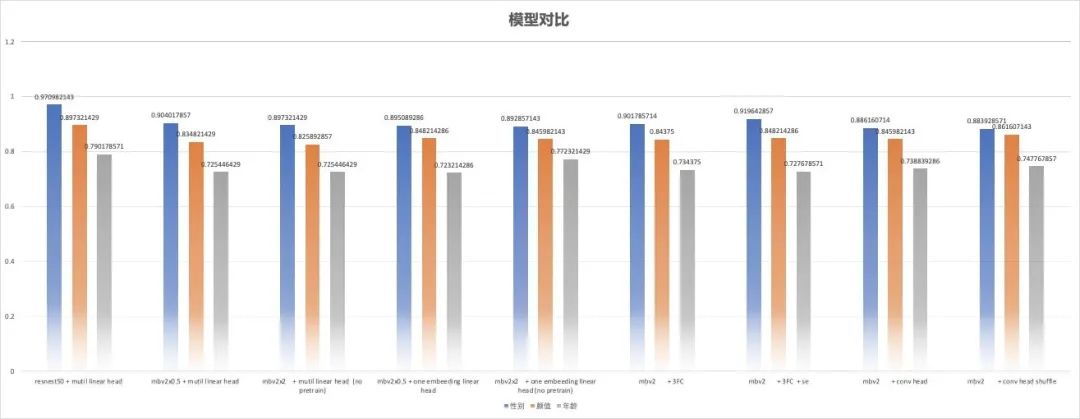
图2-结果对比
结论,出于性能和速度的考虑,确定了以mbv2x0.5作为backbone,模型结构为mutilhead-4的模型。
| 模型 | SIZE | FLOPs | PARAMs | gender_acc | beauty_acc | age_acc |
|---|---|---|---|---|---|---|
| baseline(rs50) | 256 | 5.7G | 31M | 0.970982143 | 0.897321429 | 0.790178571 |
| mbv2x0.5(mutil_head) | 256 | 127M | 2.66M | 0.904017857 | 0.834821429 | 0.725446429 |
二、蒸馏
mobilenetv2与resnest50在imagenet上的baseline大概相差8个点左右,所以我们自身的实验跑出来的结果也是在合理的范围内。为了进一步提升小模型的精度,选择用resnest50的模型来蒸馏mbv2x0.5的模型(ps:这里尝试过训练一个mbv2x2的模型,不过没有训的比resnest50高,所以还是使用resnest50)。蒸馏,采用的是传统的蒸馏方法,KL散度来作为损失,由于head相同,所以只需要考虑对logits蒸馏即可,KL散度代码如下:
class KLSoftLoss(nn.Module):
r"""Apply softtarget for kl loss
Arguments:
reduction (str): "batchmean" for the mean loss with the p(x)*(log(p(x)) - log(q(x)))
"""
def __init__(self, temperature=1, reduction="batchmean"):
super(KLSoftLoss, self).__init__()
self.reduction = reduction
self.eps = 1e-7
self.temperature = temperature
self.klloss = nn.KLDivLoss(reduction=self.reduction)
def forward(self, s_logits, t_logits):
s_prob = F.log_softmax(s_logits / self.temperature, 1)
t_prob = F.softmax(t_logits / self.temperature, 1)
loss = self.klloss(s_prob, t_prob) * self.temperature * self.temperature
return loss
训练, 对于分类的问题,一般情况只是蒸馏输出的logits即可,由于多任务有多个head,所以会有多个logits,分别蒸馏即可,整体框架如下:
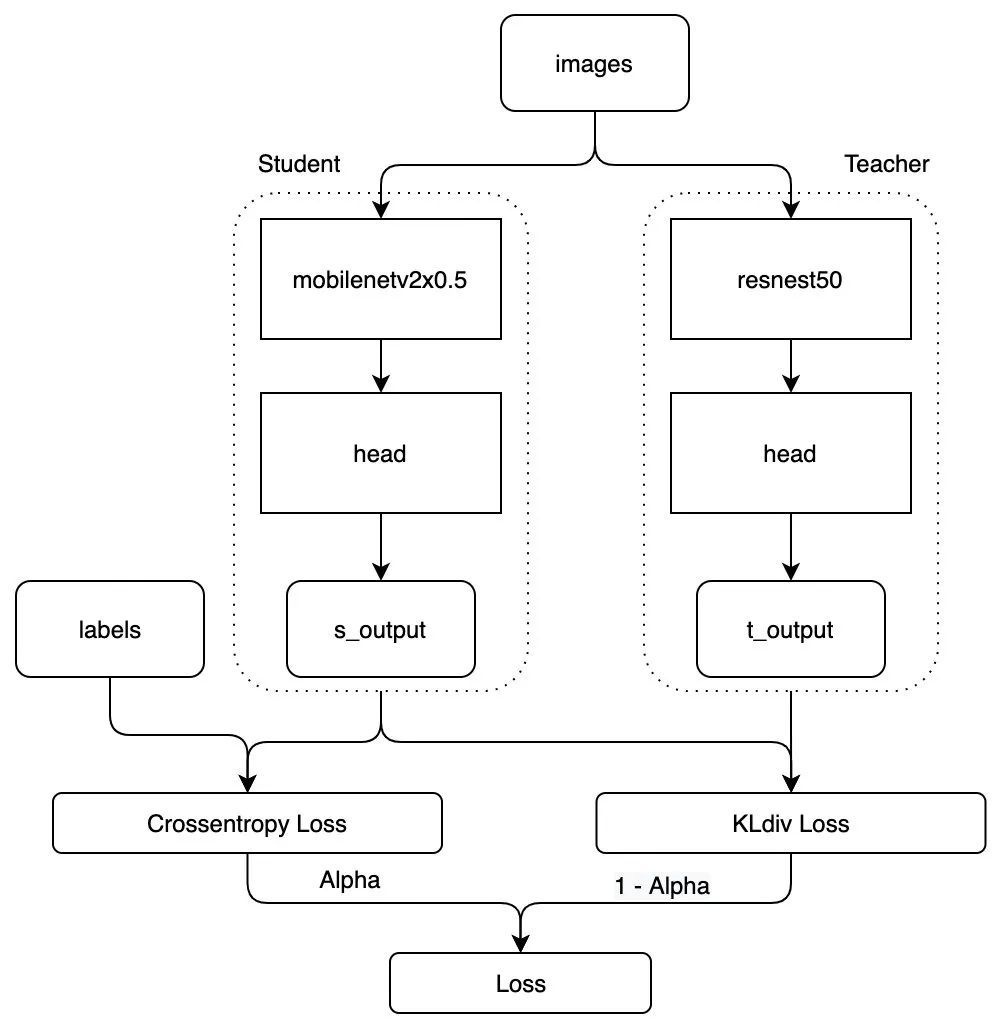
图4-蒸馏训练框架
蒸馏训练代码如下,由于学生和教师的网络差异性较大同时精度相差甚远,所以采用1:1的比例来进行训练,蒸馏的温度为25(T=5):
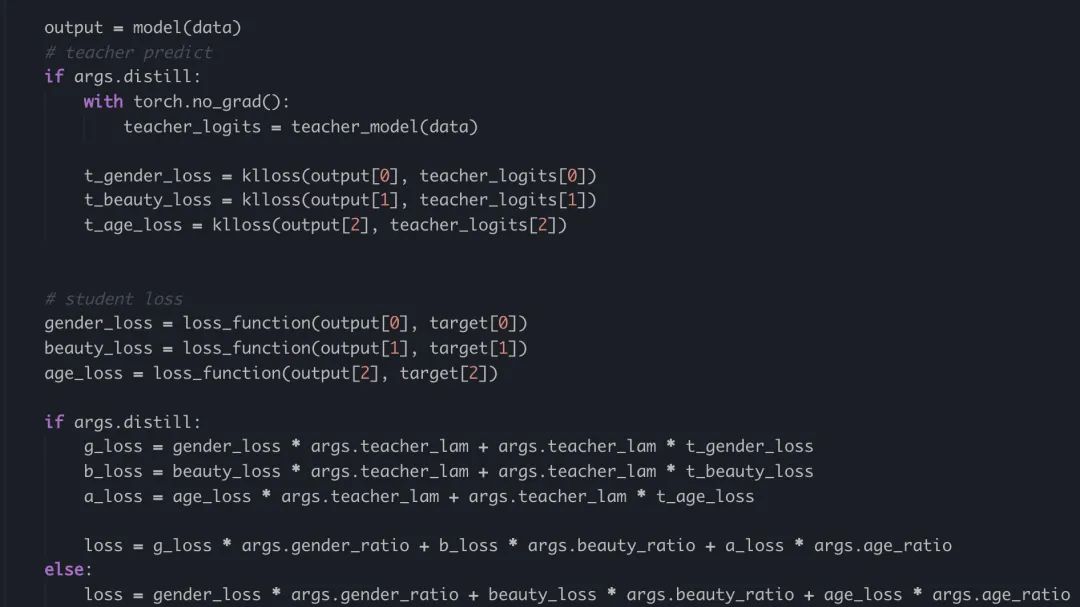
图5-蒸馏训练代码
结论,采用了3中不同的分辨率进行蒸馏实验,其中训练的size为224,推理为256的时候效果最好。
| 模型 | size | teacher | gender_acc | beauty_acc | age_acc |
|---|---|---|---|---|---|
| mbv2x0.5 | 224->256 | resnest50 | 0.966517857 | 0.89508929 | 0.75446429 |
| mbv2x0.5 | 192->224 | resnest50 | 0.950892857 | 0.89732143 | 0.765625 |
| mbv2x0.5 | 160->224 | resnest50 | 0.959821429 | 0.890625 | 0.734375 |
三、剪枝
Slimming Prune,实验采用的剪枝方法是来自于Learning Efficient Convolutional Networks through Network Slimming,通过对BN的channel进行稀疏化来达到剪枝的效果(个人喜欢用比较简单稳定的方法,便于debug和修改)。
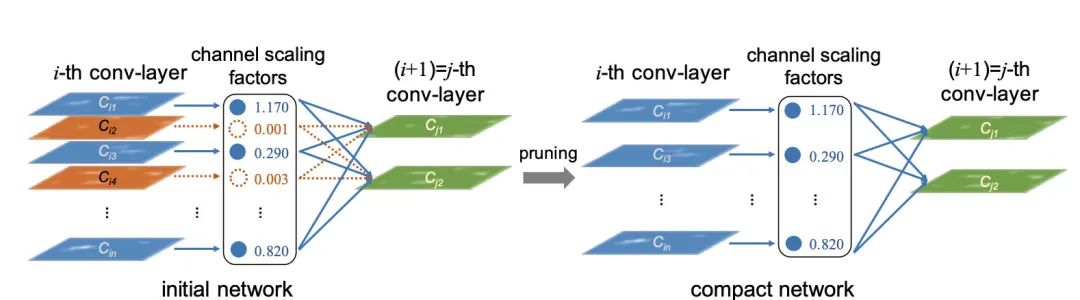
图5-Slimming
训练和剪枝
训练,训练代码很简单,只需要再更新权重之前进行稀疏化处理即可,
sr是超参,一般设置为1e-4,代码如下:optimizer.zero_grad()
loss.backward()
# use the slimming prune for training
if args.prune and args.use_sr:
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(args.sr * torch.sign(m.weight.data))
optimizer.step()剪枝, 由于模型结构是
mobilenetv2的结构,有DW存在,所以,在剪枝的时候需要注意groups的数量和channel需要保持一致,同时,为了方便移动端优化加速,要保证channel是8的倍数,剪枝代码逻辑如下:先设置一定的剪枝比例 p,如0.1,0.2,0.3...,按BN的channel总数从小到大来进行过滤。保留最大比例的最小阈值,防止prune过大,导致模型崩溃。 对于不满足8的倍数的 channel,按8的倍数补齐,补齐的方法是对prune过的channel排序,从大到小按差值补齐。保存除了第一个 InvertedResidual模块以外的所有模块剪枝后的channel数量,重构模型。测试结果,考虑是否进行finetune训练。
剪枝部分代码如下:
def prune_only_res_hidden(percent, model, keep_channel=True, channel_ratio=8, cuda=True):
"""only prune the inverResidual module first bn layer
"""
total = 0
highest_thre = []
for m in model.modules():
if isinstance(m, InvertedResidual):
# only prune the 3 conv layer
if len(m.conv) > 5:
for i in range(len(m.conv)):
if i == 1:
if isinstance(m.conv[i], nn.BatchNorm2d):
total += m.conv[i].weight.data.shape[0]
highest_thre.append(m.conv[i].weight.data.abs().max().item())
total += m.conv[i+3].weight.data.shape[0]
highest_thre.append(m.conv[i+3].weight.data.abs().max().item())
bn = torch.zeros(total)
index = 0
for m in model.modules():
if isinstance(m, InvertedResidual):
# only prune the 3 conv layer
if len(m.conv) > 5:
for i in range(len(m.conv)):
if i != len(m.conv) - 1:
if isinstance(m.conv[i], nn.BatchNorm2d):
size = m.conv[i].weight.data.shape[0]
bn[index:(index+size)] = m.conv[i].weight.data.abs().clone()
index += size
print(bn.size())
y, i = torch.sort(bn)
thre_index = int(total * percent)
thre = y[thre_index]
highest_thre = min(highest_thre)
# 判断阈值
if thre > highest_thre:
thre = highest_thre
print("the min thre is {}, the max thre is {}!!!!".format(thre, highest_thre))
pruned = 0
c = {}
cfg_mask = []
idx = 0
for m in model.modules():
if isinstance(m, InvertedResidual):
# only prune the 3 conv layer
if len(m.conv) > 5:
for i in range(len(m.conv)):
if i == 1:
if isinstance(m.conv[i], nn.BatchNorm2d):
weight_copy = m.conv[i].weight.data.clone()
if cuda:
mask = weight_copy.abs().gt(thre).float().cuda()
else:
mask = weight_copy.abs().gt(thre).float()
if keep_channel:
keep_channel_number = get_min_number(torch.sum(mask), channel_ratio)
if torch.sum(mask) < keep_channel_number:
n = int(keep_channel_number - torch.sum(mask))
mask_index = torch.where(mask==0)[0]
new_weight = weight_copy.abs()[mask_index]
_, weight_index = torch.sort(new_weight)
w_index = mask_index[weight_index[-n: ]]
mask[w_index] = 1.0
pruned = pruned + mask.shape[0] - torch.sum(mask)
# first conv + bn
m.conv[i].weight.data.mul_(mask)
m.conv[i].bias.data.mul_(mask)
# second conv + bn
m.conv[i+3].weight.data.mul_(mask)
m.conv[i+3].bias.data.mul_(mask)
c[idx] = int(torch.sum(mask))
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.format(idx, mask.shape[0], int(torch.sum(mask))))
idx += 1
print(c)
print(len(c))
print(len(cfg_mask))
# pruned_ratio = pruned / total
print('Pre-processing Successful!!!')
return model, cfg_mask, c
直接保存模型后测试,对比结果如下:
| 模型 | ratio | FLOPs | Params | gender | beauty | age |
|---|---|---|---|---|---|---|
| mobilenetv2x0.5 | 0.24 | 111.95M | 2.54M | 0.957589286 | 0.892857143 | 0.741071429 |
| mobilenetv2x0.5 | 0.3 | 107.51M | 2.51M | 0.959821429 | 0.892857143 | 0.741071429 |
| mobilenetv2x0.5 | 0.4 | 79.57M | 2.46M | 0.609375 | 0.533482143 | 0.098214286 |
| mobilenetv2x0.5 | 0.5 | 79.56M | 2.46M | 0.609375 | 0.533482143 | 0.098214286 |
再次使用resnest50进行蒸馏后,对比结果如下:
| 模型 | ratio | FLOPs | Params | gender | beauty | age |
|---|---|---|---|---|---|---|
| mobilenetv2x0.5 | 0.24 | 111.95M | 2.54M | 0.96875 | 0.901785714 | 0.75 |
| mobilenetv2x0.5 | 0.3 | 107.51M | 2.51M | 0.957589286 | 0.883928571 | 0.738839286 |
| mobilenetv2x0.5 | 0.4 | 79.57M | 2.46M | 0.957589286 | 0.881696429 | 0.741071429 |
添加2w标注的业务数据,总计训练数据37w,蒸馏后的结果如下:
| 模型 | ratio | FLOPs | Params | gender | beauty | age |
|---|---|---|---|---|---|---|
| mobilenetv2x0.5 | 0.24 | 111.95M | 2.54M | 0.975446429 | 0.901785714 | 0.752232143 |
| mobilenetv2x0.5 | 0.3 | 107.51M | 2.51M | 0.96875 | 0.890625 | 0.761160714 |
| mobilenetv2x0.5 | 0.4 | 79.57M | 2.46M | 0.966517857 | 0.892857143 | 0.723214286 |
针对性能的需求,考虑用0.3的版本,如果速度要求更快的话,考虑0.4的版本。
四、TODO
训练一个基于 BYOL的pretrain模型。把没有标注的数据,用模型打上伪标签后参与训练。 训练一个更大的teacher模型。 使用百度的 JSDivLoss作为蒸馏损失。
五、结论
对于移动端的任务来说,蒸馏和剪枝是必不可少的,尤其是要去训练一个比较好的teacher,这里的teacher可以同结构也可以异结构,只要最后logits一致即可。 由于移动端会根据X8或者X4的倍数优化,所以剪枝的时候尽量保持 channel的倍数,建议常备一种便于修改的剪枝代码。小模型具备成长为大模型的潜质,只要训练方法适当。
结束语
本人才疏学浅,以上都是自己在做项目中的一些方法和实验,以及一些粗浅的思考,并不一定完全正确,只是个人的理解,欢迎大家指正,留言评论。
参考文献
mobilenetv2 https://export.arxiv.org/pdf/1801.04381 resnest https://export.arxiv.org/pdf/2004.08955 Slimming prune https://arxiv.org/pdf/1708.06519.pdf
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。