
YOLO落地部署,一文尽览YOLOv5最新剪枝、量化进展,值得收藏!
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
以下文章来源于:集智书童
作者:小书童
链接:https://mp.weixin.qq.com/s/AzwdSKNs8SnIIRsdG0cZAg
本文仅用于学术分享,如有侵权,请联系后台作删文处理


在过去的几年中,大量的研究致力于改进YOLO目标检测器。自其推出以来,已经引入了8个主要版本的YOLO,旨在提高其准确性和效率。虽然YOLO的明显优点使其在许多领域得到广泛应用,但在资源受限的设备上部署它仍然存在挑战。
为了解决这个问题,已经开发了各种神经网络压缩方法,它们分为3大类:
网络剪枝 量化 知识蒸馏 利用模型压缩方法带来的丰硕成果,如降低内存使用和推理时间,使它们在将大型神经网络部署到硬件受限的边缘设备上成为受欢迎的选择,甚至是必要的选择。
在这篇综述中专注于剪枝和量化方法,因为它们相对独立。作者对它们进行分类,并分析将这些方法应用于YOLOv5的实际结果。通过这样做,作者确定了在适应剪枝和量化方法来压缩YOLOv5时的差距,并提供了在这一领域进一步探索的未来方向。
在众多版本的YOLO中,作者特别选择了YOLOv5,因为它在最新性和文献中的流行性之间取得了出色的平衡。这是第一篇专门从实现角度审视在YOLOv5上进行剪枝和量化方法的综述论文。作者的研究也适用于更新版本的YOLO,因为将它们部署到资源受限的设备上仍然存在同样的挑战。
本文面向那些对在YOLOv5上实际部署模型压缩方法以及探索可用于后续版本的YOLO的不同压缩技术感兴趣的人。
1、简介
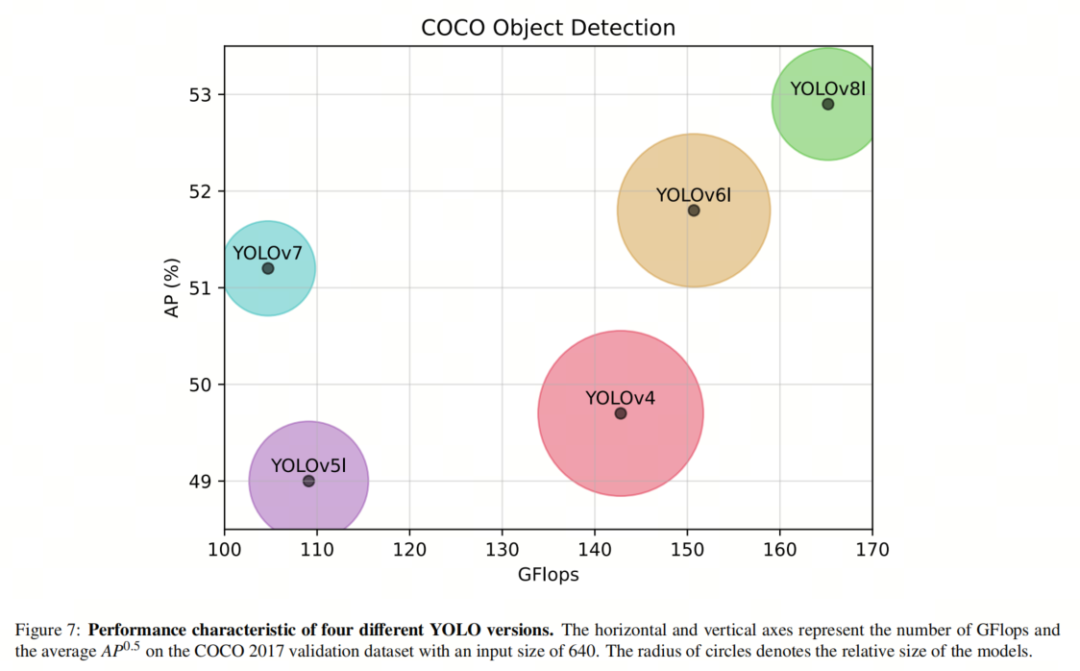
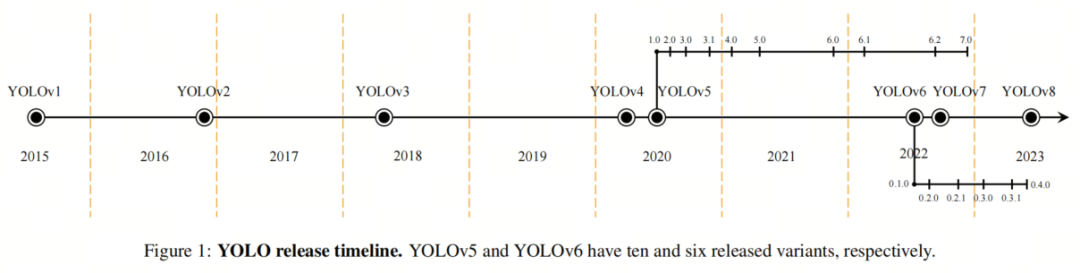
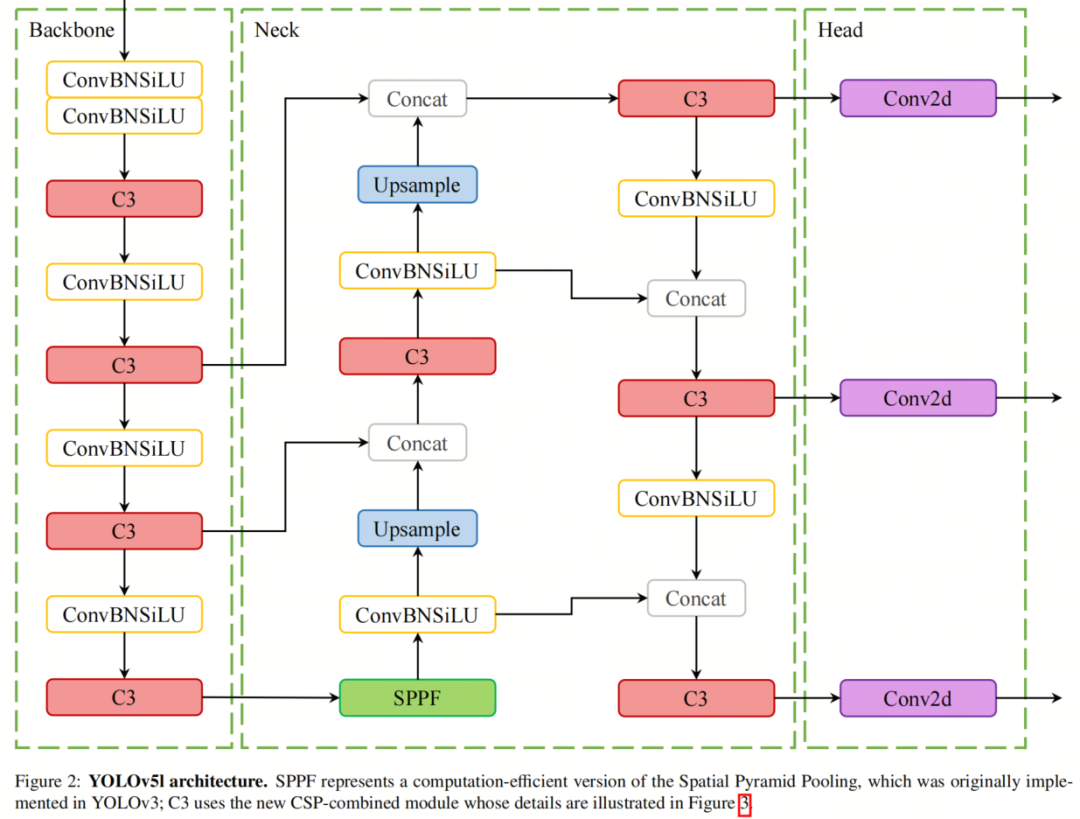
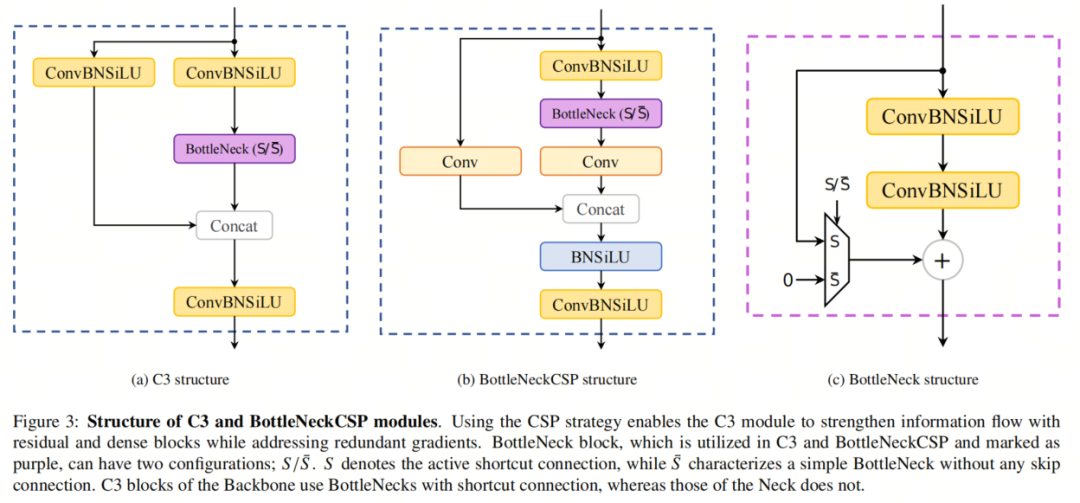
-
网络的成本:将图像数据传输到云端消耗了相对较大的网络带宽; -
对时间关键任务的延迟:访问云服务的延迟没有保证; -
可访问性:云服务依赖设备对无线通信的访问,在许多环境情况下可能会受到干扰。
2、剪枝
2.1. 剪枝的显著性标准
2.1.1. 范数
2.1.2. 特征图激活
2.1.3. 批归一化缩放因子(BNSF)
2.1.4. 一阶导数
2.1.5. 互信息
2.2. 剪枝的粒度
2.2.1. 非结构化剪枝
2.2.2. 结构化剪枝
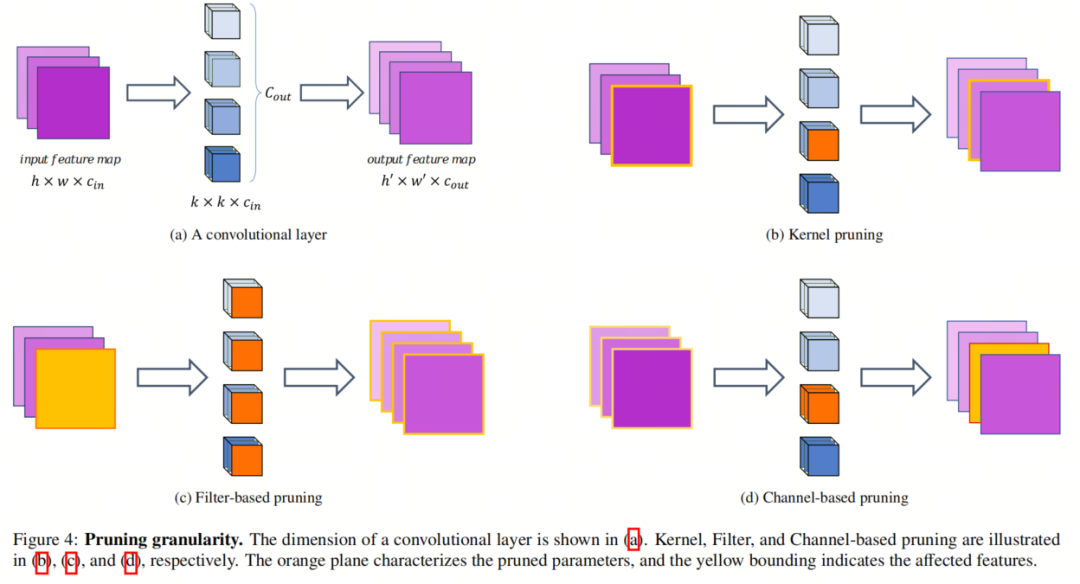
基于通道的剪枝
基于滤波器的剪枝
基于核的剪枝
2.3. 最近在剪枝的YOLOv5上的应用研究
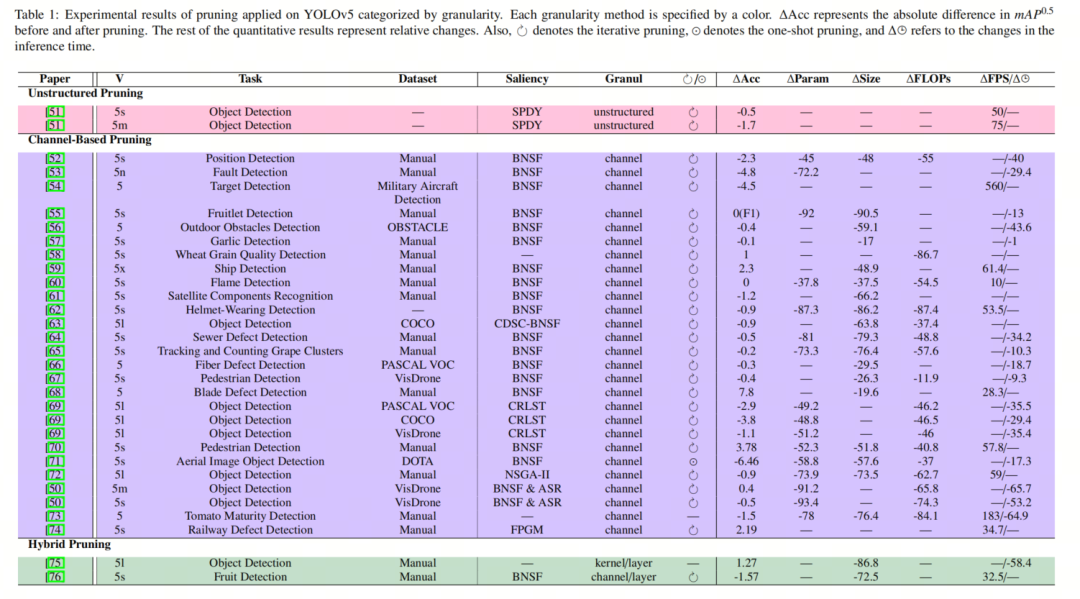
-
[ Compressed yolov5 for oriented object detection with integrated network slimming and knowledge distillation] 通过BNSF方法剪枝网络,但将微调与知识蒸馏相结合以节省训练时间,同时保持
准确性。
-
[An improved yolov5 real-time detection method for aircraft target detection] 中的作者用MobileNetV3替换了CSPDarknet Backbone网络,并在剪枝滤波器后使用TensorRT。
-
[Channel pruned yolo v5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning] 的工作着重于使用BNSF策略剪枝滤波器,并进行微调。
-
[ Fast and accurate wheat grain quality detection based on improved yolov5] 中对Backbone网络进行剪枝,并且由于期望的物体大小相对相同,移除了PAN模块的最大特征图。此外,在neck中,提出了混合注意模块来提取最全面的通道特征。
-
[Fast ship detection based on lightweight yolov5 network] 采用t分布随机邻域嵌入算法来降低锚点帧预测的维数,并将其与加权聚类融合,以预测帧大小,以实现更准确的预测目标帧。随后,通过BNSF方法剪枝滤波器。
-
[Mca-yolov5-light: A faster, stronger and lighter algorithm for helmet-wearing detection] 在Backbone网络中使用了多光谱通道注意机制来生成更多的信息特征,并提高了对小物体的检测准确性。然后,使用BNSF过程剪枝模型的滤波器。
-
[ Real-time tracking and counting of grape clusters in the field based on channel pruning with yolov5s] 通过BNSF标准剪枝滤波器,并引入软非最大抑制,使模型能够检测重叠的葡萄簇而不是将它们丢弃。
-
[Research on defect detection in automated fiber placement processes based on a multi-scale detector] 使用空间金字塔扩张卷积(SPDCs)将不同感受野的特征图组合在一起,以在多个尺度上集成缺陷信息。它在neck中嵌入通道注意机制,在每个连接操作后将更多的注意力集中在有效的特征通道上。随后,通过BNSF基于通道的剪枝与微调来压缩模型。
-
[ Yolov5-ac: Attention mechanism-based lightweight yolov5 for track pedestrian detection] 对YOLOv5的结构进行了许多修改,例如在neck中添加了注意机制,并在Backbone网络中添加了上下文提取模型。至于剪枝,它使用BNSF标准删除滤波器。
-
[ Object detection method for grasping robot based on improved yolov5] 通过层和核剪枝来压缩YOLOv5的neck和Backbone网络。
-
[ Lightweight tomato real-time detection method based on improved yolo and mobile deployment] 用MobileNetV3替换YOLOv5的Backbone网络,并通过基于通道的剪枝来剪枝neck网络。
3、量化
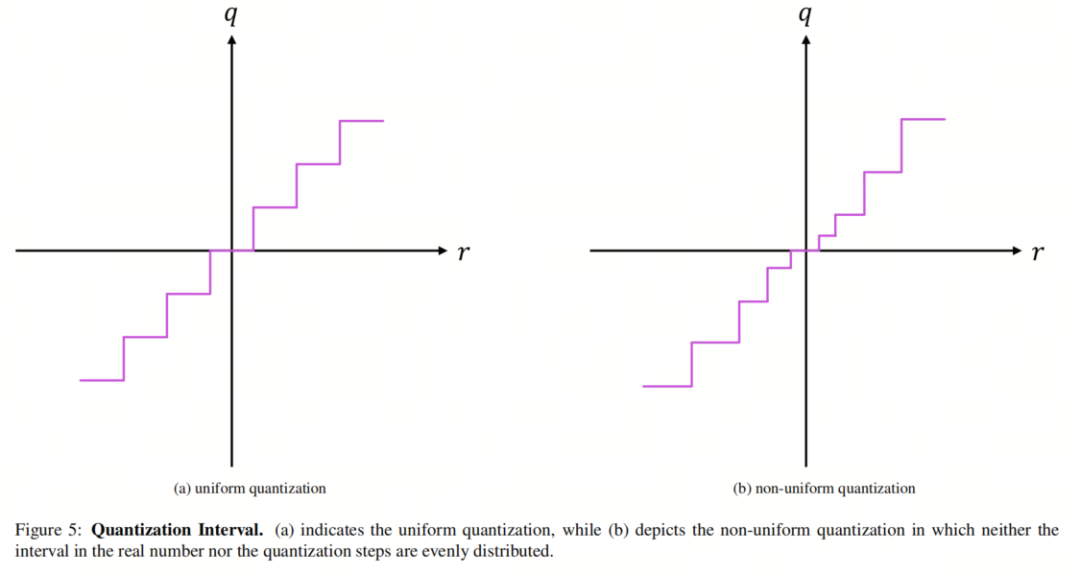
3.1. 量化间隔:均匀和非均匀
3.2. 静态量化和动态量化
3.3. 量化方案:QAT和PTQ
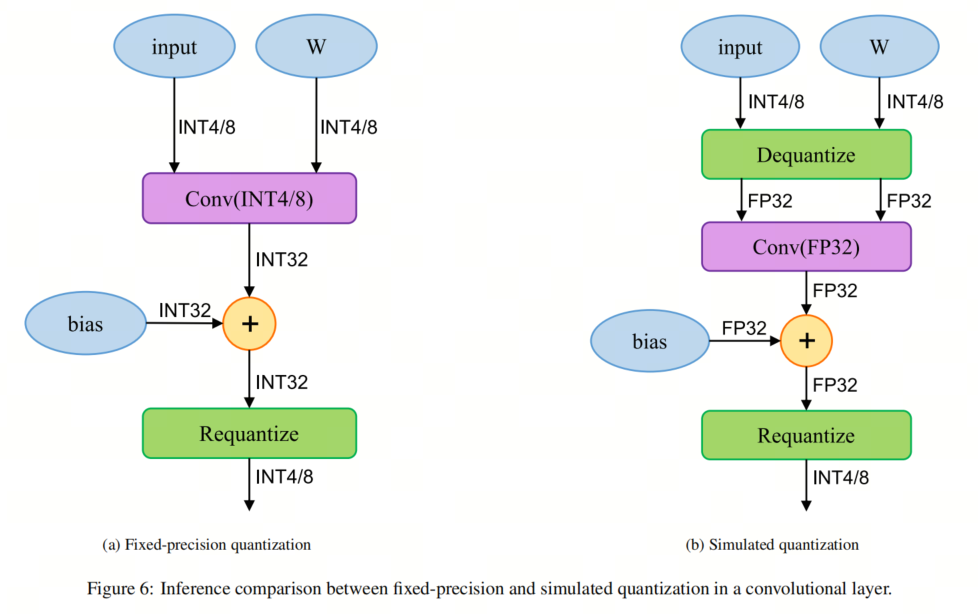
3.4. 量化部署方案
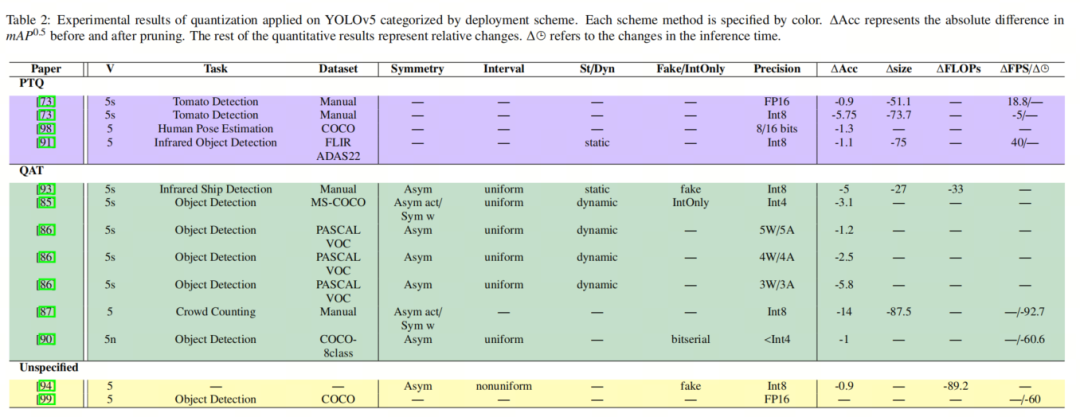
3.5、量化YOLOv5的应用研究
4、总结
4.1. 剪枝挑战和未来方向
4.2. 量化挑战和未来方向
5、参考
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。