
模型压缩:量化、剪枝和蒸馏
👆关注“博文视点Broadview”,获取更多书讯

近年来,BERT 系列模型成了应用最广的预训练语言模型,随着模型性能的提升,其参数规模不断增大,推理速度也急剧提升,导致原始模型必须部署在高端的GPU 显卡上,甚至部分模型需要多块显卡才能正常运行。
在移动智能终端品类越发多样的时代,为了让预训练语言模型可以顺利部署在算力和存储空间都受限的移动终端,对预训练语言模型的压缩是必不可少的。本文将介绍针对BERT(以Transformer Block 堆叠而成的深度模型)的压缩方法。
想要深度压缩BERT,必须对模型各部分有更为深入的了解,前面的章节已经详细介绍过Transformer 和BERT 的结构,此处不再解释各模块的具体功能。
BERT 的结构拆分如图1 所示,根据具体的实现逻辑,可以分为Embedding 层、Linear before Attention 层、Multi-Head Attention 层、Linear after Attention 层和Feed Forward 层,后4 层属于Transformer Block 内的模块,所需存储空间和推理耗时都会随着层数的增多而增多。
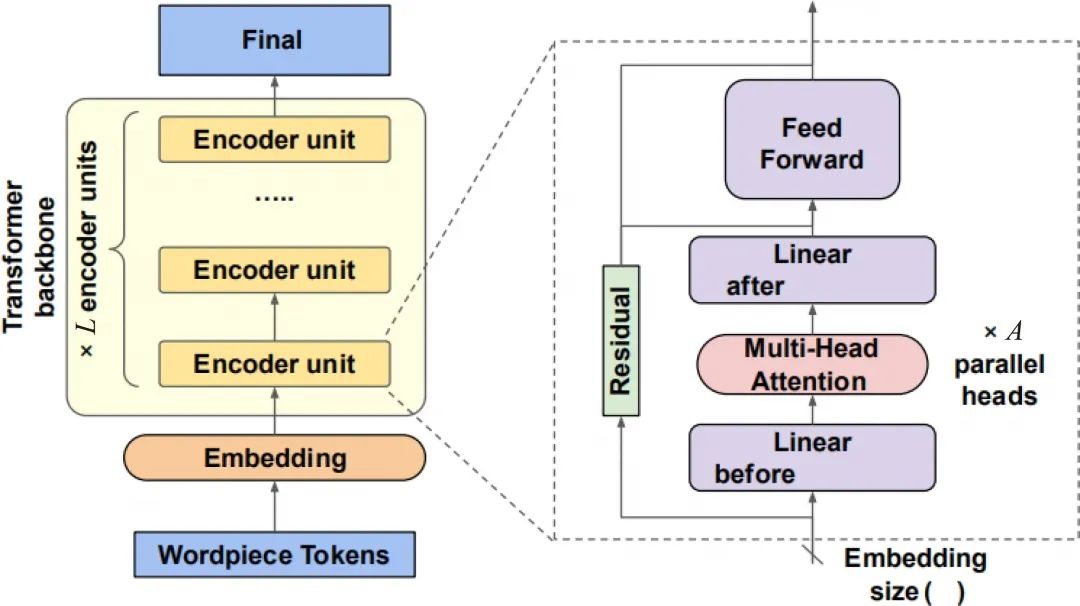
图1 BERT 的结构拆分
BERT 的大小可以用3 个超参数来衡量,即L、H 和A,其中L 表示Transformer Block 的层数,H 表示隐层向量的维数(等于Embedding 层输出向量的维数),A 表示Self-Attention 层的头数。
通过这3 个超参数,可以基本知晓BERT 的各模块大小,L 和H 决定了模型的宽度和深度,A 决定了模型Attention 的多样性。以
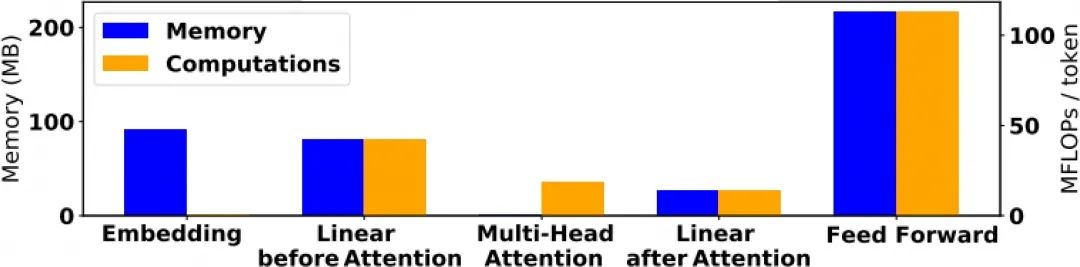
图2 BERTBASE 各层所占存储空间和算力
显然,在数据存储空间方面,Feed Forward 层占据了约一半的空间,Embedding层和Linear before Attention 层分别占据约四分之一的空间,而最核心的Multi-Head Attention 层几乎不占存储空间,这里所谓的存储空间可以等效为模型参数的数量。
在推理计算量方面,Feed Forward 层消耗了超过一半的计算资源,而Embedding 层几乎不需要算力。
通常,参数越多,所需算力越大,此处较为特殊的是Embedding 层和Multi-Head Attention 层,前者是因为Embedding 操作本质上是查表操作,所以占据较大的存储空间,却不需要算力,而后者是因为计算不同词的
理论计算所需的运行耗时和实际推理时间并不完全一致,在英伟达Titan X GPU 上运行
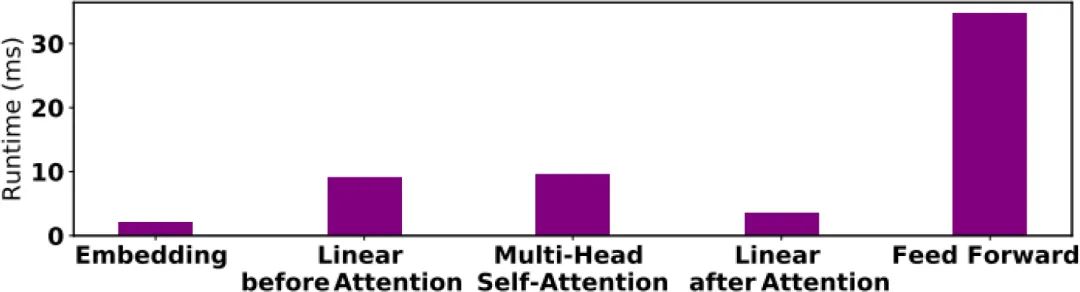
图3 BERTBASE 推理所占时间分析
实际推理时间大致与各层所需算力正相关,但Multi-Head Attention 层所需的实际运行耗时远大于其理论值,这是因为
通过分析
模型量化是指将模型权重参数用更少的比特数存储,以此来减少模型的存储空间和算力消耗。
例如,BERT 原本是以fp32 精度(float precision 32bit,单精度4 字节浮点数)运行的,若转换成fp16 精度(float precision 16bit,半精度2 字节浮点数),则存储空间立刻减少一半,在针对fp16 精度优化的运算设备上(如英伟达T4/V100 GPU 或FPGA 平台),运行速度也可以得到显著提升。
量化是一种通用的压缩方法,适用于几乎所有的深度模型,学术界已经证实,全连接层是对量化操作十分友好的结构,而BERT 中大部分模块都由全连接层组成,因此BERT 对于量化操作是比较友好的。
值得注意的是,Embedding 层(并不属于全连接层)对于量化操作较为敏感,在实际操作中应避免对Embedding 层做量化操作。
数据精度降低之后,模型的质量肯定也会有所下降,一般可以通过量化后训练(Quantization Aware Training,QAT)来缓解。
具体而言,在对模型参数进行直接量化操作或精度截断之后,用训练数据继续训练量化后的模型,以缓解量化造成的精度损失,这是常见的量化压缩流程。
正常的均匀量化可以通过TensorFlow Lite Toolkit 或其他量化工具实现。
除此之外,还可以通过
模型剪枝是指去除模型参数中冗余或不重要的部分,这个过程与哺乳动物幼年神经突触消失的过程极为相似。
剪枝是提高推断效率的方法之一,它可以高效地生成规模更小、内存利用率更高、能耗更低、推断速度更快的模型。
就BERT 的剪枝而言,可以大致分为以下两类:元素剪枝(Elementwise Pruning,EP)和结构剪枝(Structured Pruning,SP)。
元素剪枝又被称为稀疏剪枝,聚焦于模型单个参数元素。
若单个参数元素绝对值过小或对模型不重要,则可以通过将其置为0 元素来减小存储空间,缩短推理时间。
对模型不重要的定义可以是对目标函数影响小,也可以是对梯度更新影响小等自定义的客观衡量标准。
元素剪枝对全连接层相对友好,因此BERT 使用元素剪枝可以获得不俗的压缩比,同时可以保证一定的精度。
结构剪枝聚焦于去除模型结构的冗余,以精简模型结构来减小模型的存储空间,满足算力需求。
结构剪枝更具有针对性,不同于元素剪枝适用于所有模型,对于不同的模型结构,结构剪枝可以设计不同的剪枝策略。以BERT 为例,一般有两种结构剪枝策略:Attention 头剪枝和层剪枝。
(1)Attention 头剪枝:BERT 的Multi-Head Attention 层在推理时间中占比排第二。有研究表明,Multi-Head Attention 层存在较大的冗余,因此BERT 的12-Head Attention 可以通过剪枝变为4-Head 甚至更少,这样的剪枝操作可以大大缩短Multi-Head Attention 层的推理时间。
(2)层剪枝:BERT 是由多层Transformer Block 堆叠而成的,层数越多,模型所需的存储空间越大,推理时间也越长。训练时常用的Dropout 操作有助于模型收敛得更稳定,故通过删除个别不重要的层来减少模型参数,加速推理是完全可行的。不重要的层可以通过比较目标函数值大小和L1 正则化值的大小等方法来定位。
剪枝操作也会对模型带来精度损失。
一般而言,根据剪枝流程的位置,可以将剪枝操作分为两种:训练时剪枝和后剪枝。
训练时剪枝其实和训练时使用Dropout 操作较为类似,训练时剪枝会根据当前模型的结果,删除不重要的结构,固化模型再进行训练,以后续的训练来弥补部分结构剪枝带来的不利影响,避免模型因为剪枝操作而造成的精度陡降。
后剪枝则是在模型训练完成后,根据模型权重参数和剪枝测试选取需要剪枝的部分,比较粗暴,但与训练时剪枝所需的额外计算量和控制流程相比,后剪枝是较为简单的做法。
Keras 模型的剪枝操作可以通过2019 年发布的Tensor-Flow Model Optimization Toolkit 工具实现。PyTorch 模型的剪枝操作可以通过torch.nn.utils.prune 工具实现。
量化和剪枝是最常用的模型压缩方法,有成熟的配套工具,但为了保证一定精度,其压缩比一般较小,还不足以让BERT 在移动设备的芯片上运行。
蒸馏的全称为知识蒸馏(Knowledge Distillation,KD),是2015 年由深度学习开山鼻祖Hinton 提出的一种模型压缩方法,是一种基于教师-学生网络思想的训练方法。
蒸馏已经成为压缩模型的主流方法之一,可以与量化和剪枝叠加使用,达到可观的压缩比。
在知识蒸馏使用的教师-学生(Teacher-Student)网络中,教师模型是“知识”的输出者,学生模型是“知识”的接受者,整个过程分为两个阶段。
(1)教师模型训练:教师模型一般为参数量巨大,结构相对复杂的待压缩的模型,简称为Model-T。教师模型一般由大量数据训练而成,性能指标高于蒸馏后的学生模型。
(2)学生模型训练:学生模型一般为参数量很小,结构相对简单的模型,简称为Model-S,其训练过程以学习Model-T 为主,而不是学习数据的真实标签。
根据学生模型学习的目标,可以将BERT 的蒸馏方法分为以下三类:基于输出概率蒸馏、基于隐层蒸馏和基于Attention 层蒸馏。
下面通过两个经典的BERT 蒸馏模型讲解蒸馏的思想和具体实现。
1. Distilled BiLSTM
Distilled BiLSTM是一个从BERT 蒸馏得到的双向LSTM 模型,即教师模型为精调后的
具体模型结构根据任务类型分为两种:输入为单句文本的模型(如图4 所示)和输入为句对文本的模型(如图5 所示)。
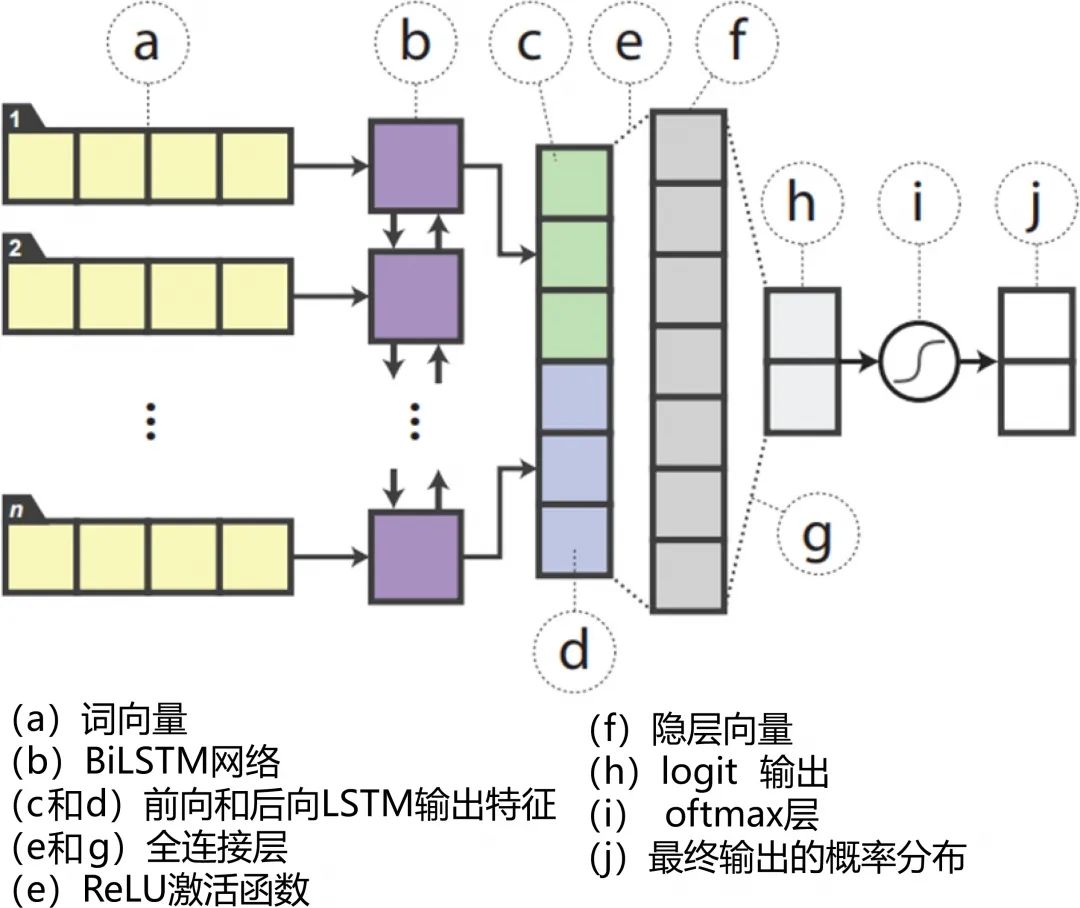
图4 Distilled BiLSTM 的模型结构
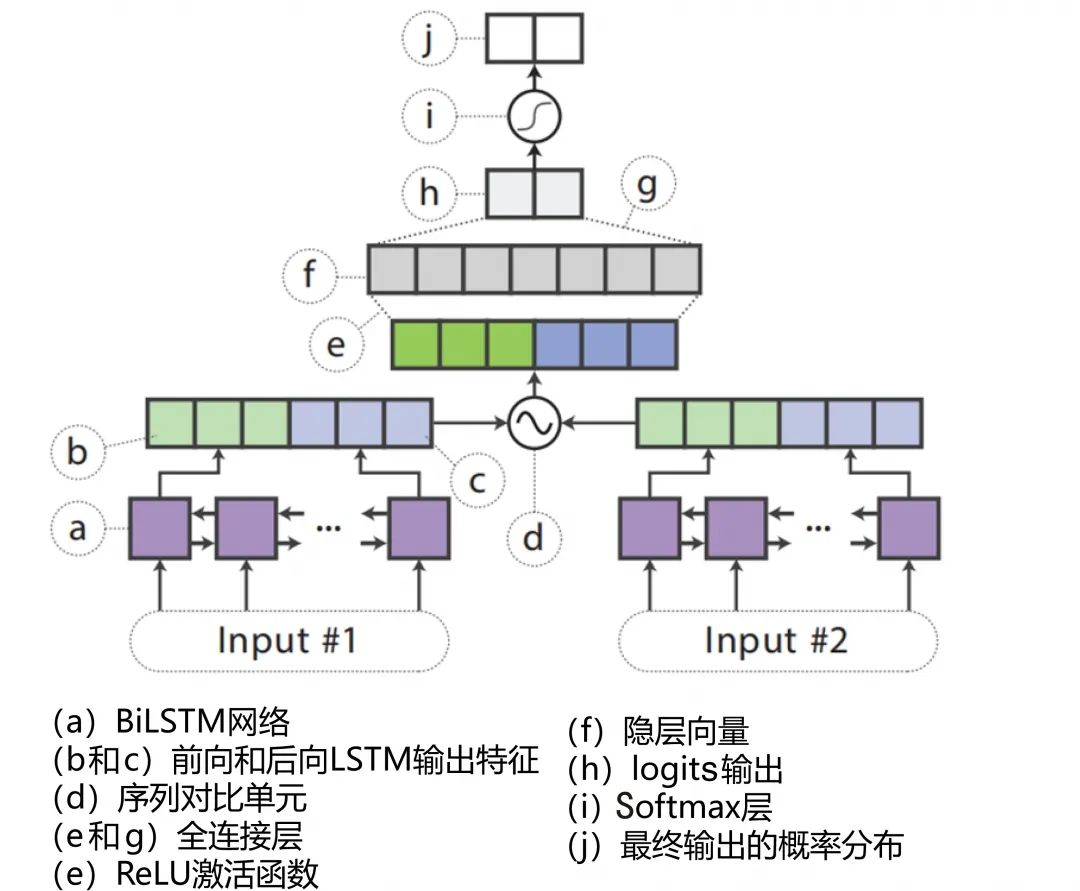
图5 Distilled BiLSTM 的模型结构2
由于BERT 和LSTM 的模型结构差异太大,只能通过基于输出概率蒸馏的方法进行知识传递,具体公式如下:
其中,
其中,
从结果看,在BERT 和LSTM 的模型结构差异过大的情况下,用LSTM模型作为学生模型来蒸馏BERT 的知识,取得了不错的效果,在下游任务的表现上远超用BiLSTM 直接训练得到的模型,说明蒸馏模型学会了浅层模型不容易学会的拟合泛化能力。
虽然Distilled BiLSTM 相较于BERT 有不少性能损失,但是其模型体积相较于BERT 压缩了约99.7%,推理速度快了400 倍,压缩力度之大远超想象。
2. MobileBERT
一般的知识蒸馏都会使用与教师模型结构相似的学生模型,模型结构不是变浅就是变窄,MobileBERT就是把BERT 变窄,作为学生模型的经典模型之一。
MobileBERT 采用和
由于原始的BERT 不存在bottleneck 层,为了顺利进行知识蒸馏,需要先通过训练得到一个特殊设计的教师模型,即一个包含Inverted-bottleneck 结构的
随后,将训练得到的
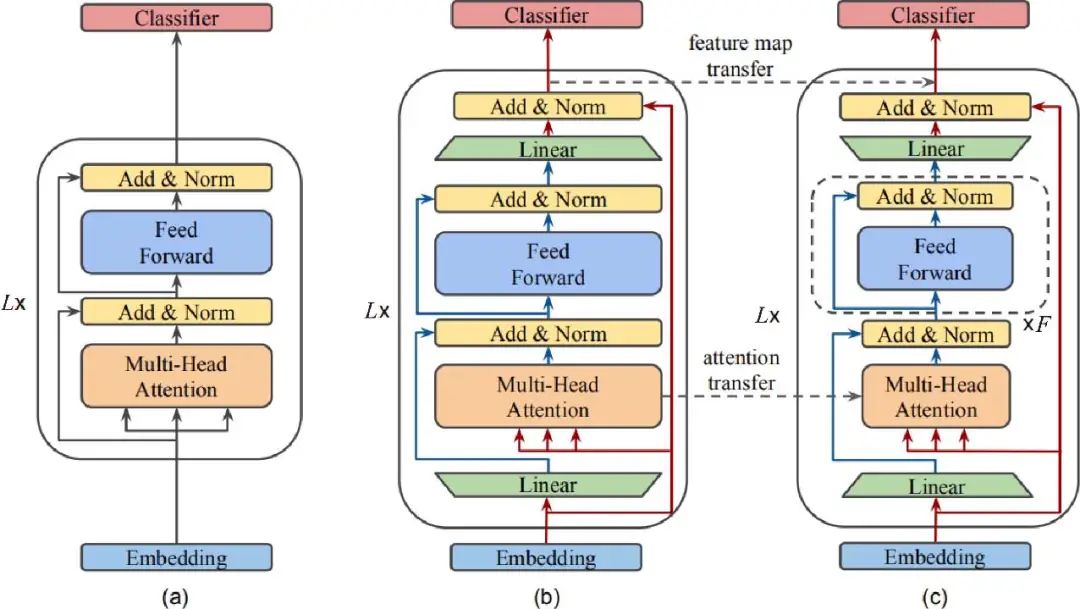
图6 三个模型的结构
bottleneck 层本质上就是一个变换特征向量维度的全连接层,结合图6,很容易理解MobileBERT 的模型结构,如表1所示,body 模块中的Linear 层就是新增的bottleneck 层,其余部分与BERT 一致。
表1 几个模型的参数规模对比

从参数规模上看,
训练MobileBERT 这样既深又窄的深度网络是很困难的任务。为了让蒸馏训练更稳定,MobileBERT 采用了阶梯式层级训练法,如图7所示。

图7 MobileBERT 的阶梯式层级训练法
先自下而上逐层训练学生模型,当学生模型的每一层输出都与教师模型接近时,才训练下一层。逐层蒸馏根据训练目标的不同也分为基于隐层蒸馏和基于Attention 层蒸馏。
具体而言,基于隐层蒸馏被称为特征映射迁移(Feature Map Transfer,FMT),将MobileBERT 的每一层Transformer Block 的输出都与
其中,
同理,
基于Attention 层蒸馏被称为Attention 迁移(Attention Transfer,AT)。
由于BERT 最重要的结构就是Self-Attention,所以Attention 迁移能让学生模型学习教师模型的Self-Attention 层特征,从而辅助学生模型增强文本语义理解方面的能力。
在具体实现上,将MobileBERT 和
其中,
MobileBERT 在逐层蒸馏的过程中使用了特征映射迁移和Attention 迁移。为了加快模型的推理速度,相比于BERT,MobileBERT 还做了以下两个改动:
(1)用线性层归一化代替原有的层归一化,即取消原有层归一化中的非线性操作,以得到加速推理的效果。
(2)用ReLU 激活函数代替GeLU 激活函数,简化激活函数换取推理加速。
总体而言,MobileBERT 作为任务无关的BERT 压缩模型,压缩比高达10 倍,配合量化可以达到40 倍,最关键的是其在多数文本理解任务上的性能与
得益于小体积和极快的推理速度,MobileBERT 可以轻松运行在各类终端移动设备上。
除了常见的量化、剪枝和蒸馏,还有一些与模型结构强依赖的压缩方法,这些方法不会更改模型的结构,故归为结构无损的压缩方法。
本节将简单介绍以下三类结构无损的压缩方法:参数共享、低秩分解和注意力解耦。
参数共享和低秩分解在介绍ALBERT 时已经讲解过,参数共享是指模型共享所有Transformer Block 层参数,以达到减小存储空间的目的,而低秩分解特指Embedding 层通过因式分解变成更小的Embedding 层和一个线性层,达到减小参数规模的目的,具体介绍见《预训练语言模型》一书的6.8 节。
值得注意的是,这两个方法只能减小模型的存储空间,并不能加速推理过程。
注意力解耦适用于句对任务,因为在原始的BERT 中,输入文本为两个句子时,每个词都需要与其他的词做Self-Attention 运算,即句子A 中的词需要与句子B 中的词做矩阵运算。这时会产生运算冗余,因为句对任务最后依赖于标签[CLS] 的输出特征,而在逐层抽象语义特征的过程中,句子A的语义抽取过程不需要与句子B 产生关联,即可以通过Self-Attention 运算的解耦达到减少运算量的目的,加快推理过程。
同样值得注意的是,Multi-Head Attention 层不占用存储空间,所以注意力解耦虽然不会减小模型体积,但是可以加快模型推理速度。
▼
参考文献:
[1] GANESH P, CHEN Y, LOU X, et al. Compressing large-scale transformerbased models: A case study on bert[J]. arXiv preprint arXiv:2002.11985,2020.
[2] TANG R, LU Y, LIU L, et al. Distilling task-specific knowledge from bert into simple neural networks[J]. arXiv preprint arXiv:1903.12136, 2019.
[3] SUN Z, YU H, SONG X, et al. Mobilebert: a compact task-agnostic bert for resource-limited devices[J]. arXiv preprint arXiv:2004.02984, 2020.
以上内容节选自《预训练语言模型》一书!


▊《预训练语言模型》
邵浩 刘一烽 编著
梳理预训练语言模型的发展历史、基本概念
剖析具有代表性的预训练语言模型的实现细节,配代码
预训练语言模型的评测、应用及趋势分析
(京东限时活动,快快扫码抢购吧!)
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,获取本书详情~