
模型压缩:模型量化打怪升级之路 - 工具篇
共 6571字,需浏览 14分钟
·
2021-03-14 22:10

极市导读
本文针对模型量化的工业级生产框架/工具进行一个大致的review,尝试整理和总结已有框架的特点和能力,结合一些落地经验提出下一代量化框架应该具备的特性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
掐指一算,距上篇文章发出刚刚好过去了一个月。几件事情提醒我是时候更新了。
哪几件事情呢?
最近发现一些还在学校读书的同学非常关注一个量化工作精度的高低,读过我上篇分享(龚睿昊:模型压缩:模型量化打怪升级之路 - 0 序章 https://zhuanlan.zhihu.com/p/349820682)的同学应该知道,部分学术界的工作与工业界的实用性是存在一定脱节的。我个人的看法是:除了部分比较本质的探究量化提升的研究工作之外,一套好用的、通用的、强大的模型量化工具是更值得我们去推动的一件事情。 恰逢PyTorch1.8.0发布,里面推出了一个非常惊喜又意料之中的模块:torch.fx (torch.fx - PyTorch 1.8.0 documentation https://pytorch.org/docs/stable/fx.html)。这个模块是干嘛的?它可以symbolic的trace一个PyTorch Module的forward,得到对应的graph,并支持对graph做一定的transformation,然后还支持一个python2python的code generation,生成一个新的forward代码。大家知道动态图特性一直是PyTorch的一大优势,而也恰恰成了它的一个短板:很难对计算图做一些变换和分析。因此相继有JIT、Torchscript和fx推出,有了这些我们可以干什么呢?一个很重要的方面是它使一些compilation相关的优化有了更多空间,此外还有一个我自己最最最最关心的是,它可以更好的方便我们"自动"插入量化节点。试图在PyTorch上做过 量化自动插入 的同学,应该知道这里面的痛。不得不说,这是一个好消息,但是有了它之后是否完备了呢?
目前看还是不够的。今天我们就来针对模型量化的工业级生产框架/工具进行一个大致的review,尝试整理和总结已有框架的特点和能力,结合一些落地经验提出我们认为的下一代量化框架应该具备的特性。
现有框架的特点和能力
开源的涉及模型量化的项目主要分为工业界主导、学术界主导和有志个人主导。
其中工业界会做量化工具并开源的主要有三类:深度学习框架厂商(Facebook/Tensorflow等)、硬件厂商(NVIDIA/Intel/Qualcomm等)以及一些致力于推进相关工具作为云服务附加值的厂商(Microsoft等),这些厂商所开源的工具与实际落地部署的贴合性受到其开发背景的影响,一般来说框架厂商和硬件厂商的项目是更加符合量化的实际情况的(也不绝对)。学术界开源的项目主要是一些从事相关领域的研究员开发,这些项目主要以复现学术算法为主,一般不能保证能在硬件上实际部署。此外,也有一些其他的民间研究者开发的相关项目,其中有一些是很实际的。
本文将会选择笔者所知道并看过的项目中的一部分重点进行分析。其他的欢迎大家一起分享和补充~
PyTorch::
PyTorch最早期在量化方面是非常空白的,自1.4.x开始,引入了非常初步的量化支持,定义了一些low level API,比如:fuse_modules之类的功能函数用于做一些量化相关的算子合并(实际上非常粗糙,是不考虑forward执行顺序的fuse);QuantStub/Observer/FakeQuantize之类的类方便用户拼接出自己的quantized model。为了降低大家的使用复杂度,甚至也推出了一套model zoo的quantization版本。可以明显看到的是,这个时期的量化支持是非常手工的,还远没有在graph层面做量化替换的工作。
由于那时候,我们已经做了一个叫"_Dirichlet"_的框架来做pytorch quantization的自动插入这件事情了,所以只是觉得PyTorch的API设计是很简洁清晰的,但距离更低成本的使用还有很大距离,因此没有过多的follow。而是针对Dirichlet本身仍存在的问题思考如何进一步改进和提升。
随着PyTorch推出了fx这一套,graph mode quantization的概念浮出水面。PyTorch官方也情理之中的对相关缺陷进行了补齐,看完fx __init__.py(https://github.com/pytorch/pytorch/blob/master/torch/fx/__init__.py)中对其功能的大概注释之后,我的心情非常复杂。万万没想到PyTorch官方会用这种方式来解决问题,因为大概2年前在我们自己的框架Dirichlet中就引入了类似的机制来做自动替换,这算是对我们选取的技术路线的一个官方肯定。但同时,在Dirichlet大量的业务落地检验中,发现这种方式还是有一些挑战需要解决的。因此对PyTorch引入这种机制之后的长远规划有了更进一步的好奇。
首先简单介绍一下我们的做法:
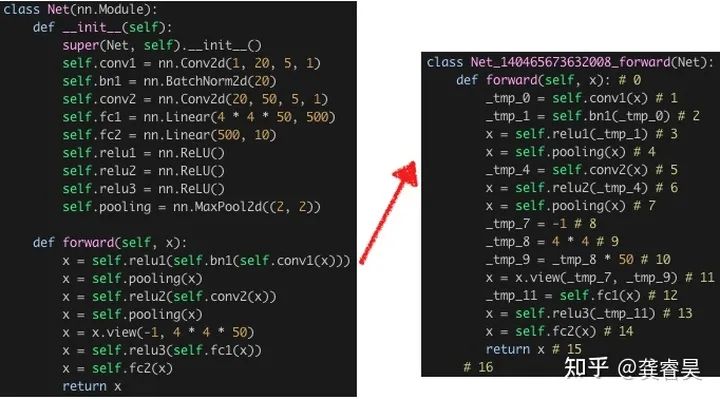
上图是我们的代码替换机制,实际上这一步主要是为了做一些elementwise的提取和替换,看过torch.fx文档的同学应该发现了,跟其中的样例非常像。此外我们同时还有一个借助PyTorch JIT trace进行图匹配和变换的模块,两者配合完成模型的自动量化插入。其实从思想上跟当前的PyTorch官方思路已经非常一致了,不过我们主要是针对量化的一些场景进行了设计,没有像当前的fx一样非常严格的抽象成一个单独的模块。可以看到PyTorch现在抽象出一个单独的fx模块,应该不仅仅是考虑量化的,能够预想到其未来应该会针对广义的模型压缩技术(pruning/nas)扩展更多的支持。加上PyTorch团队专注于框架开发,因此在稳定性以及与框架的协同发展上肯定是更有保证的。不过即便如此,基于Dirichlet的大量业务实践,我们认为仍有几个挑战需要PyTorch在未来解决:
这样一个code parse和generation的能力是有边界的,如何定义清楚这个边界,并让用户习惯和接受,是有一定难度的。举一个量化的例子,如果在一个写法比较放飞自我的模型定义上,自动量化插入崩了,用户其实是很难受的,他并不知道怎么改,尤其是在面临不同的量化硬件量化插入模式可能还不一样的情况下。 一些特殊的模型定义不容易保证插入语义的正确性。比如目标检测里经常出现的share head。即head中的conv权重是共享的,会在多个分支中forward多次,但是由于处理的输入不同,他们的量化参数应该是每个分支独享的。shared head定义一般是for loop形式,如fx文档所说,这是目前所不支持的。 对于分布式的扩展性和支持。
虽然还有很多挑战,但是PyTorch的发力思路是清晰的,只不过没有经过大量业务场景的打磨,很多细节需要补齐,更多的量化硬件支持需要补齐,不过整体来说我对PyTorch量化的未来是持乐观态度的。
TensorFlow
TensorFlow算是框架层面支持量化的鼻祖了,从whitepaper(https://arxiv.org/abs/1806.08342)开始,Google算是把量化推向工业级实用的关键角色,其静态图特性决定了框架层面的量化支持没有太多阻碍。加上Tensorflow Lite的推理支持,是端到端打通的典范了。当然他的特点也是主要针对自家的推理实现进行支持,不过很多硬件厂商会主动支持tf格式的量化模型的导入,这就是另一回事了。
NNCF
NNCF是intel推出的专门针对OpenVINO的模型压缩框架,也有一篇专门的tech report(https://arxiv.org/abs/2002.08679)对其进行介绍。个人认为这是目前看到的最多的考虑了实用性并经过了较多打磨的一个库,不足之处是他忽略了一个非常重要的特性,不支持QAT中的merge BN。大概说一下NNCF的特点:
模仿PyTorch JIT自行扩展了一套trace机制,用于控制context和灵活的量化插入。 量化模块设计为节点模式,便于灵活的量化插入和导出。 维护了compression controller和context,甚至能够处理shared head问题。 能够导出带Quantize Node的onnx模型,进一步部署到自家的OpenVINO上跑。 有硬件量化模式定义的json配置,理论上可扩展硬件种类支持和配置量化位置。 一些模拟量化操作使用了cuda优化。
其中很多是我们之前也做过的,比如自己实现一套trace,实现一些模拟量化的cuda extension,所以在PyTorch fx系列出来之前,PyTorch上做量化,我们是最服NNCF的。当然它也有一些问题,比如扩展OP支持需要熟悉源代码,不支持QAT中的merge BN,仅重点支持OpenVINO的量化推理。量化算法部分,只集成了hawq和一些learning based方法。
AIMET
AIMET是高通推出的模型压缩工具,对应的推理库是SNPE。AIMET使用的量化节点插入方式是module替换,这一点从设计先进性上来说,是弱于NNCF的。其中支持了一些自家研究员提出的算法如:Bias Correction,Weight Equalization,AdaRound等。
TensorRT-PyTorch-Quantization
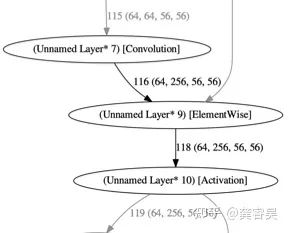
TensorRT官方提出的在PyTorch层面做量化支持的工具,支持量化参数的导出以写入TensorRT engine中。不禁想起了当年的TensorRT对齐经历,做PyTorch模拟量化在不确定很多硬件底层实现细节的情况下,是非常非常难做到对齐的。包括后来的NNIE量化对齐,让我养成了对齐虐我千百遍,我待对齐如初恋的良好工具人意识。这里抛出一个小问题,如下的计算图局部,TensorRT是如何插入量化节点的?欢迎知道的在评论区留言~
Distiller
Distiller是比较早开源的模型压缩项目,由Intel Habana实验室开发。其最早相对是没有那么贴近部署的,不过发展过程中逐渐扩展了merge BN,quantize onnx export支持,还贴心的添加了与PyTorch quantize onnx的相互转化。其中支持了DoReFa、PACT、自家研究员发明的LAPQ等算法。整体上相比兄弟单位的NNCF在落地和设计上略逊一筹。
Vitis / Brevitis
VITIS-AI是Xilinx针对自家FPGA的一套模型压缩推理工具套件,Brevitis是QAT模块。不难看出,这套工具其实是深鉴的班子被Xilinx收购后持续推进的结果。其中的量化工具部分在去年5月份还比较粗糙,不支持量化参数的外部写入,去年中旬发布的新版本(不记得确切的版本号了)开始首次支持。主要是针对自家hardware,去年5月份我摸这套工具的时候,可以猜出其量化方案采用的是比较老旧的Ristretto方案,不知道后续有没有升级。
TVM
TVM是由以陈天奇大佬发起的深度学习编译器项目,其中也有int8 甚至int4/2/1 kernel的编译支持。我们也做过大规模测试,其中一些kernel的性能表现还是不错的。这里重点想讲的是其中的量化算法支持。可以看到TVM支持的离线量化算法是比较少的,主要有KL divergence的校准。QAT算法目前主要靠其他框架的量化模型导入。个人认为这一块其实是可以进一步提升的,很早就看到社区ziheng对更加自动化的离线量化的RFC,前段时间终于看到了PR和对应的tech report(https://github.com/apache/tvm)。最近也有UC berkeley的HAWQ-V3使用TVM进行了测试。我们自己也在持续跟进TVM社区的进展,并已经贡献了一些小修小补的PR,剧透一下后续会有更大的一些PR提出来,希望为社区贡献一份力量。
PaddleSlim
依托PaddlePaddle的模型压缩算法库,其中有一些基于Paddle生态的算法复现,也注意了典型硬件比如TensorRT的对齐和导出。
Condensa
也是NV推出的,但是非常不符合实际量化部署的一套库。这就可以看出,像NV这样的核弹厂,确实有很多团队在重复造轮子,抬手就可以列出一堆:NVIDIA/sampleQAT、Post Training Quantization (PTQ),但是目前没有看到比较系统完整又出色的出来。
NVIDIA/sampleQAT:https://github.com/NVIDIA/sampleQAT
Post Training Quantization (PTQ):https://nvidia.github.io/TRTorch/tutorials/ptq.html
下一代量化框架还有多长的路要走?
上面只是列举出了一些工业界推出的框架,可以看到大有百花齐放的态势,针对PyTorch的量化,其中从设计来说个人最为看好的是PyTorch官方的方案和NNCF的方案。当然其他有几个也有很大的发展空间。遗憾的是,所有这些框架和工具都只能解决一部分问题。我们距离下一代量化框架,到底还有多长的路要走?个人看来,一个优秀的量化框架应该具备以下几个特点:
同时具有针对developer的low level API和针对小白用户的high level API。 灵活、鲁棒、可靠的量化插入和替换机制。 可扩展、可配置的多种量化硬件支持,包括NNIE/DSP/GPU/CPU/ASIC等等等等。 强大的PTQ和QAT算法支持,以及灵活的量化pipeline控制机制,最大化算法潜力。 大量的应用场景模型量化实践打磨,包括多种任务和多种模型。
其中的1、2已经通过PyTorch官方和NNCF衍生出了两种技术方案,未来大概率会逐渐收敛。而3、4、5是已有框架解决的不够好的,本质上的原因还是他们离应用场景还不够近,只会聚焦一部分需求。这方面我们其实是有天然优势的。因此我们也会一方面吸收开源社区的优秀设计模式,同时整理我们自己的落地和算法经验,推动下一代量化框架的开花和结果。
推荐阅读
2021-02-03

2021-01-02
2020-12-15

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
