国际千人基因组计划数据库怎么用起来?
国际千人基因组计划
项目起始。人类基因组计划耗费10多年后在2003年绘出人类的完整基因组图谱。作为某种延续,也得益于测序通量的提高,国际千人基因组计划(The 1000 Genomes Project, 1000G/1KGP)从2008年启动,到2012年即获得了超过1000人的基因组数据,是科学界首次实现千人规模以上的基因组对比分析(2012年)。

http://www.internationalgenome.org/
参与单位。华大基因是1000G的主要发起单位之一,承担了非洲人群和400个黄种人的全基因组测序。其它单位有英国桑格研究所和美国国立人类基因组研究所等。
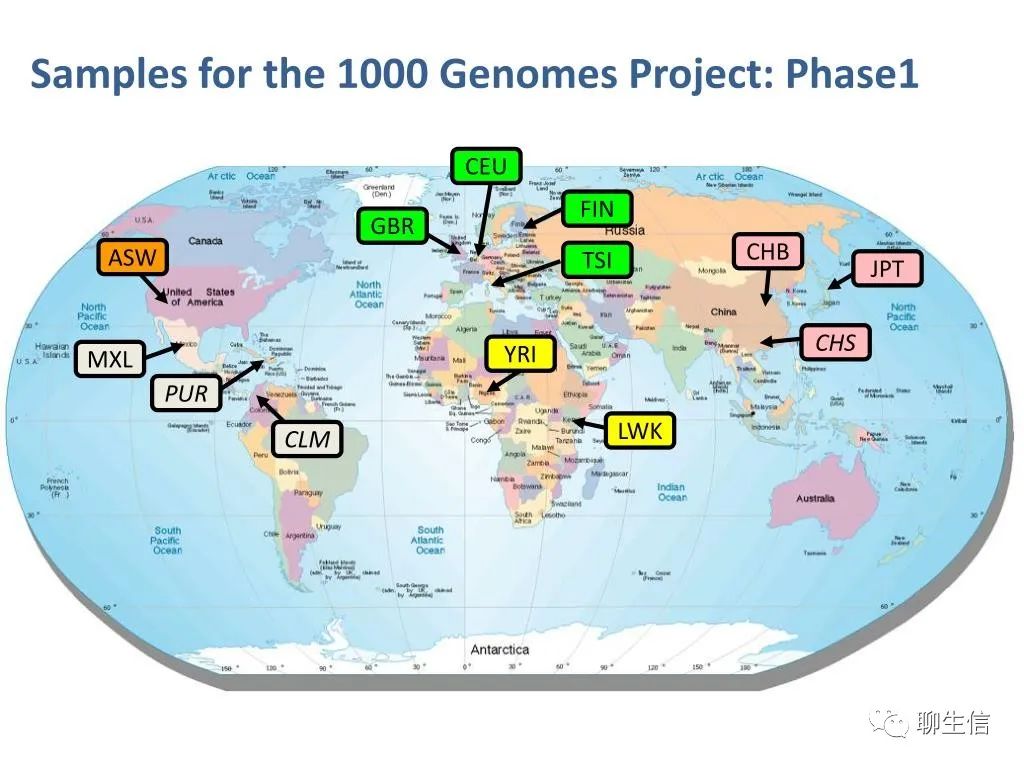
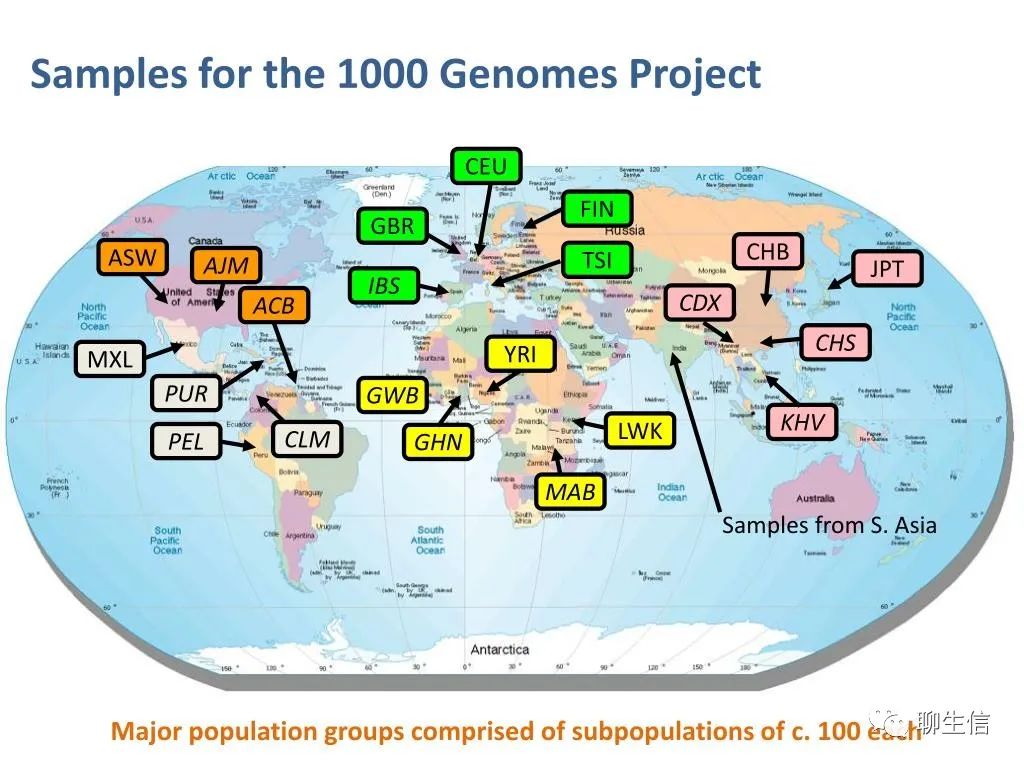
人群分布。每个亚群一般包含几十到一百多个健康人。例如:尼日利亚伊巴丹区域的约鲁巴人;肯尼亚Webuye的Luhya人和Kinyawa的Maasai人;居住于美国西南部的非洲人后裔;居住于东京的日本人;居住于北京的中国人;居住于丹佛的中国人;意大利的Toscani居民;美国犹他州的北欧和西欧人后裔;美国休斯顿的Gujarati印第安人;美国洛杉矶的墨西哥人后裔。项目后期的人群多样性有大幅增加。
1000G数据库的应用
发现罕见的基因变异。1000G可以帮助发现一些携带者占总人口比例不到1%的基因变异。这些罕见基因变异或许与疾病有关,例如可能增加心脏病或癌症的患病风险。对基因变异进行研究有助于开发预防、治疗相关疾病的方法。
作为人群对照。可以帮助研究者不再泛泛地找一些人的基因组(几个或几十个)用于对比,而是直接调阅他们长期生活区域的人群基因组数据,开展更加有针对性的比较。
应用汇总。发现疾病发病机理、疾病的易感性、对药物和环境因素的反应性;常见疾病的诊断、个性化预测、预防和治疗;在大的范围内定位人群突变基因、帮助发现人类遗传疾病的相关基因、鉴定特定遗传病人群中的罕见致病基因、更精确地定位已发现的遗传风险因素、挖掘出更多未知的致病遗传因素;药物基因组学、人类群体遗传学、人类进化史。
样本列表的选择和下载
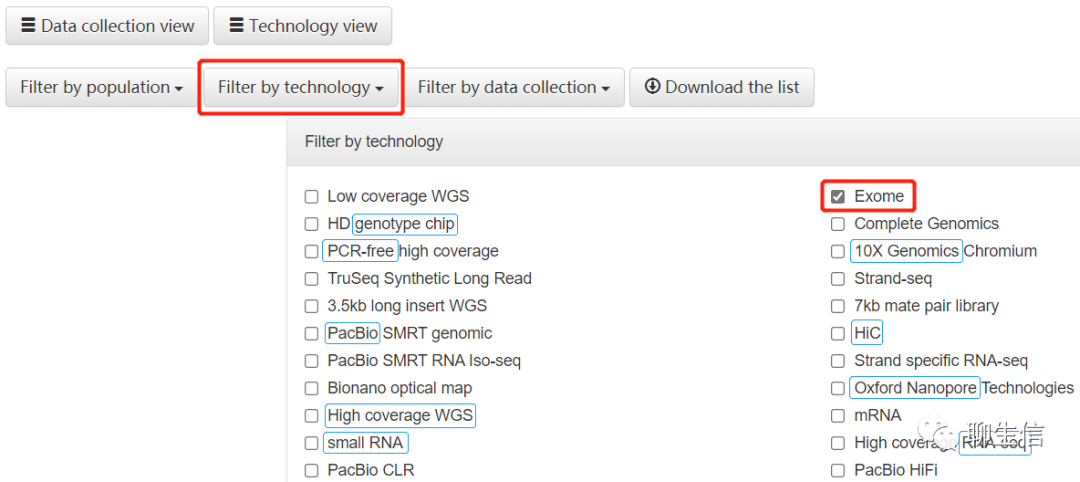
另有全基因组、小RNA、Nanopore、PacBio和单细胞测序,及基因型芯片数据
最后选择数据集合:
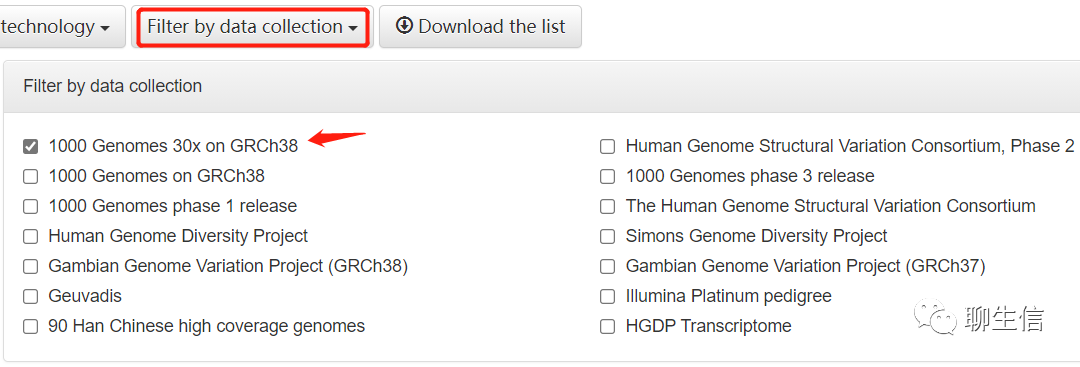
先选择了外显子组(Exome);人群:CHB(北京,n=103);CHS(南方汉族人群,n=113);数据集合:30x on GRCh38。最终有216个样本符合。
点击Download the list下载得到样本名称:

撰写:宋红卫
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集