
使用Python和YOLO检测车牌
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

计算机视觉无处不在-从面部识别,制造,农业到自动驾驶汽车。今天,我们将通过动手实践进入现代计算机视觉世界,学习如何使用YOLO算法检测车牌。

来自Pexels的mali maeder的照片应用于定制的YOLO车牌检测模型
传统计算机视觉方法使用vision方法进行检测。但由于阈值和轮廓检测的局限性,其算法在部分图像上有效,但无法推广。通过本次学习,我们将拥有可以在任何天气情况下用于检测车牌的强大模型。
我们有一个可靠的数据库,其中包含数百张汽车图像,但是在网上共享它是不道德的。因此,小伙伴必须自己收集汽车图像。我们将使用如下照片进行演示和验证:

我们还应该收集各种光照条件下的车牌图像,并从不同角度拍摄图像。在完成数据收集之后,我们将使用一个名为LabelIMG的免费工具来完成这项工作。
cd labelImg-masterbrew install qtbrew install libxml2make qt5py3python labelImg.py
从终端执行这些操作将打开此窗口:
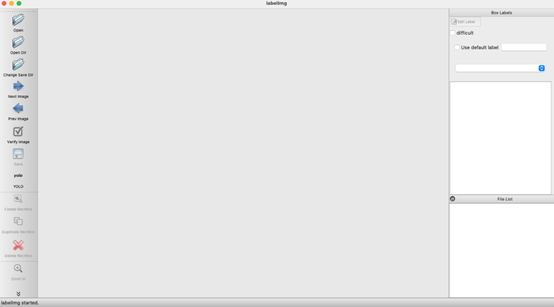
图2-启动LabelIMG
接下来,单击左侧菜单上的“打开目录”图标。找到存储汽车图像的文件夹。它会自动打开第一个图像:

图像3 -用LabelIMG打开图像(作者提供的图像)
左侧面板中的标签会显示YOLO。接下来,按键盘上的W键以打开RectBox 工具。在车牌周围绘制一个矩形,输入标签,然后单击“确定”:
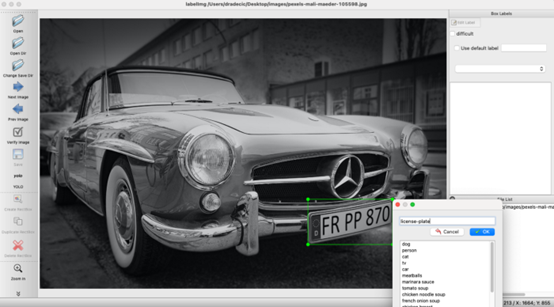
图4 -在板周围绘制矩形
按CTRL + S将板块坐标保存到文本文件。单个文件应如下所示:

图像5- LabelIMG生成的文本文件
该LabelIMG软件将保存的矩形框坐标文件对应于保存的每个图像。还将所有类的列表保存到名为classes.txt的文件中。我们打开它,其中可能列出了许多我们不感兴趣的内容。可以删除license-plate以外的所有内容。

图6-类列表
仍然存在一个问题。我们只有一个类(license-plate),但是坐标文件中的类索引为15,我们只需查看图片5并自行验证即可。
我们将使用Python加载每个坐标文件,以通过将类索引更改为1来解决此问题。这是代码段:
import glob# Contains all .txt files except our listof classestxt_files = [file for file inglob.glob('images/*.txt') if file != 'images/classes.txt']# Read every .txt file and store it'scontent into variable currfor file in txt_files:with open(file, 'r') as f:curr = f.read()# Replace class index 15 with 1 and storeit in a variable newnew = curr.replace('15 ', '1 ')# Once again open every .txt file and makethe replacementfor file in txt_files:with open(file, 'w') as f:f.write(new)
到目前为止,我们已经完成了数据集收集和准备。接下来,我们需要压缩文件并进行模型训练。
我们已经有几百个带有标签的汽车图像。足够我们训练一个好的YOLO模型,接下来就是我们要做的。我们将在带有GPU后端的Google Colab上训练模型。我们的案例中,在Colab中训练模型大约需要2个小时,但是时间会有所变化,具体取决于GPU和数据集的大小。
我们将通过接下来的七个步骤来训练模型。
第1步-配置GPU环境
在新的笔记本中,转到运行时-更改运行时类型,然后在下拉列表中选择GPU:
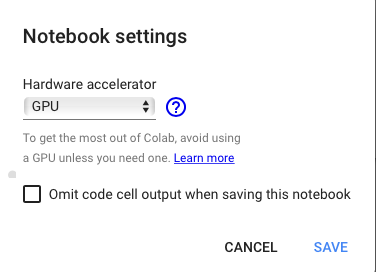
图7-切换到GPU运行时
第2步-挂载Google云端硬盘
在Google云端硬盘中,创建一个备份文件夹。我们将其命名为yolo-license-plates。这就是存储模型权重和配置的地方。在第一个单元格中,执行以下代码来安装Google云端硬盘:
from google.colab import drivedrive.mount('/content/gdrive')!ln -s /content/gdrive/My\ Drive/ /mydrive
步骤3 —下载并配置Darknet
Darknet是一个开源神经网络框架,具有YOLO对象检测系统。我们可以通过执行以下代码行来下载它:
!git clonehttps://github.com/AlexeyAB/darknet接下来,在darknet/Makefile中我们必须配置一些内容。在以下行上更改值:
第1行-从GPU=0到GPU=1
第2行-从CUDNN=0到CUDNN=1
第4行-从OPENCV=0到OPENCV=1
并保存文件。这些更改使我们可以在训练时使用GPU。我们现在可以编译Darknet
cd darknet!make
这需要等待几分钟,我们在编译完成后继续进行下一步。
步骤4 —配置设置文件
要知道如何设置YOLO配置文件,我们需要知道有多少个类。我们只有一个— license-plate,但这可能会根据我们正在处理的问题的类型而改变。
接下来,我们需要计算批次数和过滤器数。以下是计算公式:
批次=类数* 2000
过滤器=(类别数+ 5)* 3
在我们的例子中,值分别为2000和18。为了准确起见,请复制YOLO配置文件:
!cp cfg / yolov3.cfg cfg / yolov3-train.cfg并在cfg/yolov3-train.cfg中进行以下更改:
第3行-从batch=1到batch=64
第4行-从subdivisions=1到subdivisions=16
第20行-从max_batches=500200到max_batches=2000
603、689和776行-从filters=255到filters=18
610、696和783行-从classes=80到classes=1
保存文件。接下来,我们必须创建两个文件-data/obj.names和data/obj.data。这些文件包含有关类名和备份文件夹的信息:
!echo -e 'license-plate' >data/obj.names!echo -e 'classes = 1\ntrain =data/train.txt\nvalid = data/test.txt\nnames = data/obj.names\nbackup =/mydrive/yolo-license-plates' > data/obj.data
到现在,我们已经完成了配置,现在让我们上传并准备图像。
步骤5-上传和解压缩图像
我们只需将zip文件拖放到“文件”侧边栏菜单中即可。完成后应如下所示:
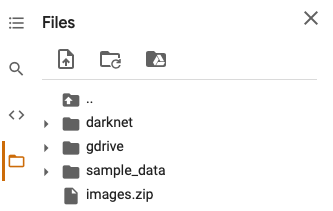
图8-zip文件上传后的Colab文件菜单
下一步是为图像创建一个文件夹并将其解压缩:
!mkdir数据/对象!unzip ../images.zip -d data / obj
现在data/obj文件夹应包含图像及其各自的文本文件。
步骤6-训练准备
接下来,我们要做的就是创建一个data/train.txt文件。它将包含所有训练图像的路径:
import globimages_list = glob.glob('data/obj/*.jpg')with open('data/train.txt', 'w') as f:f.write('\n'.join(images_list))
最后,我们必须下载预训练的Darknet卷积网络:
!wgethttps://pjreddie.com/media/files/darknet53.conv.74下载将花费几秒钟,但是一旦完成,我们便可以进入到模型训练阶段。
步骤7 —模型训练
现在,开始训练过程可以归结为一行shell代码:!./ darknet检测器火车数据/obj.datacfg / yolov3-train.cfg darknet53.conv.74 -dont_show
图9-Colab中的YOLO模型训练
现在,我们需要等待。训练过程可能需要几个小时,具体取决于图像的数量。权重每10到15分钟自动保存到您的Google云端硬盘备份文件夹中。在下一部分中,我们将创建一个脚本,用于在图像上查找和标记车牌。
模型训练完成后,我们应该在Google云端硬盘备份文件夹中拥有三个文件:
权重文件— yolov3_training_final.weights
配置文件- yolov3_testing.cfg
类文件— classes.txt
将它们下载到计算机上的单个文件夹中,然后打开JupyterLab,我们可以从LicensePlateDetector下面的代码段中复制:
import cv2import numpy as npimport matplotlib.pyplot as pltclass LicensePlateDetector:def __init__(self, pth_weights: str, pth_cfg: str, pth_classes: str):self.net = cv2.dnn.readNet(pth_weights, pth_cfg)self.classes = []with open(pth_classes, 'r') as f:self.classes = f.read().splitlines()self.font = cv2.FONT_HERSHEY_PLAINself.color = (255, 0, 0)self.coordinates = Noneself.img = Noneself.fig_image = Noneself.roi_image = Nonedef detect(self, img_path: str):orig = cv2.imread(img_path)self.img = origimg = orig.copy()height, width, _ = img.shapeblob = cv2.dnn.blobFromImage(img, 1 / 255, (416, 416), (0, 0, 0),swapRB=True, crop=False)self.net.setInput(blob)output_layer_names = self.net.getUnconnectedOutLayersNames()layer_outputs = self.net.forward(output_layer_names)boxes = []confidences = []class_ids = []for output in layer_outputs:for detection in output:scores = detection[5:]class_id = np.argmax(scores)confidence = scores[class_id]if confidence > 0.2:center_x = int(detection[0]* width)center_y = int(detection[1]* height)w = int(detection[2] *width)h = int(detection[3] *height)x = int(center_x - w / 2)y = int(center_y - h / 2)boxes.append([x, y, w, h])confidences.append((float(confidence)))class_ids.append(class_id)indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.2, 0.4)if len(indexes) > 0:for i in indexes.flatten():x, y, w, h = boxes[i]label = str(self.classes[class_ids[i]])confidence =str(round(confidences[i],2))cv2.rectangle(img, (x,y), (x +w, y + h), self.color, 15)cv2.putText(img, label + ' ' +confidence, (x, y + 20), self.font, 3, (255, 255, 255), 3)self.fig_image = imgself.coordinates = (x, y, w, h)returndef crop_plate(self):x, y, w, h = self.coordinatesroi = self.img[y:y + h, x:x + w]self.roi_image = roireturn
此类有两种方法:
detect(img_path)–用于从输入图像中检测车牌并在其周围绘制一个矩形。crop_plate()–用于从图像中裁剪检测到的车牌。如果您想应用一些OCR来提取文本,则此方法可用。
lpd = LicensePlateDetector(pth_weights='yolov3_training_final.weights',pth_cfg='yolov3_testing.cfg',pth_classes='classes.txt')# Detect license platelpd.detect('001.jpg')# Plot original image with rectangle aroundthe plateplt.figure(figsize=(24, 24))plt.imshow(cv2.cvtColor(lpd.fig_image, cv2.COLOR_BGR2RGB))plt.savefig('detected.jpg')plt.show()# Crop plate and show cropped platelpd.crop_plate()plt.figure(figsize=(10, 4))plt.imshow(cv2.cvtColor(lpd.roi_image,cv2.COLOR_BGR2RGB))
上面的代码片段构成了LicensePlateDetector该类的一个实例,检测到车牌,并将其裁剪。这是可视化输出:

图10- YOLO模型和LicensePlateDetector类的评估
我们可以在过去几个小时(或几天)内完成的所有工作。YOLO模型可以完美运行,并且可以用于任何使用案例。
这是一篇很长的分享。祝贺小伙伴一次坐下来就可以完成实践。我们也是花了几天的时间才能了解YOLO的工作原理以及如何制作自定义对象检测器。使用相同的方法,小伙伴们可以构建任何类型的对象检测器。例如,我们重复使用具有不同文本标签的相同图像来检测汽车颜色和汽车品牌。期待小伙伴们的大显身手。
 End
End
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~