
Python私活300元,爬虫批量获取新浪博客文章存储到Word文件
共 3895字,需浏览 8分钟
·
2022-02-14 08:48
前言
8号开了一天车从老家回来,昨天正在干家务,休息的时候看了一眼手机,蚂蚁在群里@我接单。结果因为没有及时看消息,发现的时候已经被别人接了。既然如此,本着练习的目的,我也打开文件看了一下需求,此时刚好收到信息说,此前接单的人已经放弃接单了,那还等什么,赶紧拿下。
需求分析
先看一下金主爸爸的需求:

简单分析下,大概是:
爬取1000多篇文章,保存为word word必须要有目录,目录为文章标题 每篇文章单独一页 要求提供原始代码
后来又新增了一个需求:
每篇文章要包括:题目、时间和内容
实施思路
分析网页,获取文章标题、链接和发布时间 将文章标题、发布时间写入word 根据文章链接获取每一页的数据,并将数据写入word 保存数据 用可视化工具处理word
实施步骤
网页分析,构造url,获取文章标题、链接和发布时间
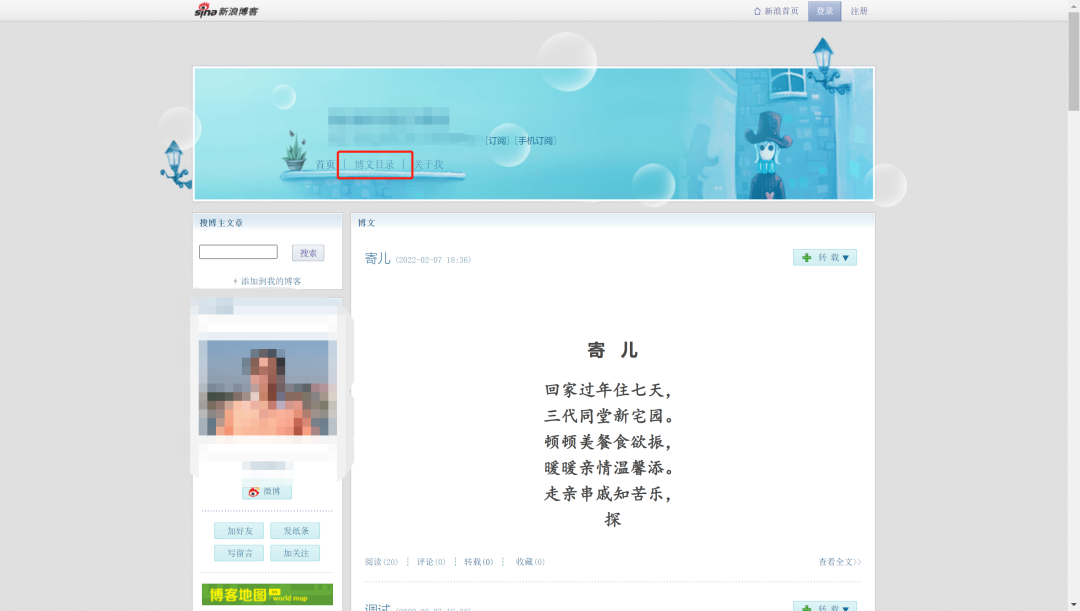
打开需求文档里的链接后,发现有“博文目录”标签,点击后开始分析url构成:
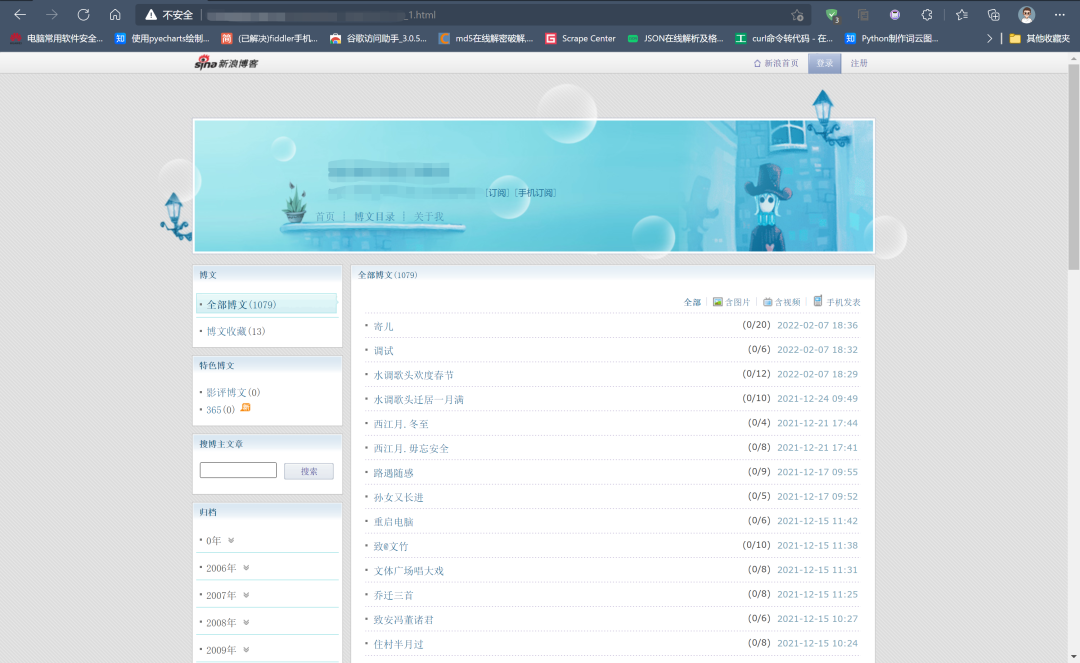
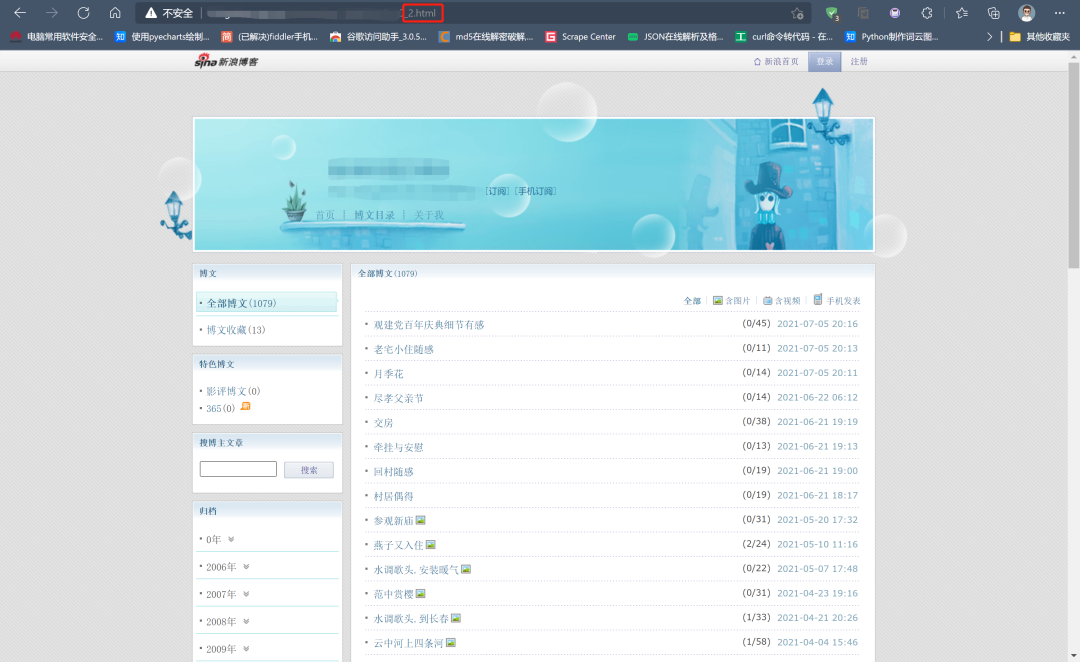
分析发现,网页的url变化的数据只有.html前一位,而且这个数字就是当前的页码,同时列表里包含文章标题、发布时间,那文章链接应该也有,进一步查看网页源代码:
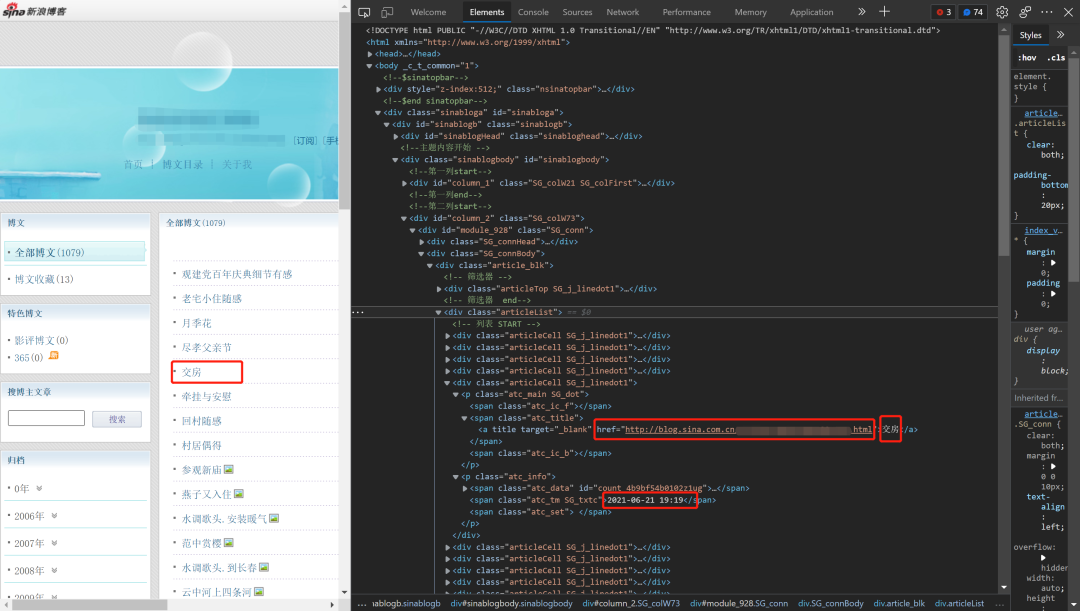
至此,第一步的代码就已经可以完成了:
import requests
from lxml import etree
for i in range(1, 23): # 共22页
counter = 0 # 计数器
url = f'http://blog.sina.com.cn/s/articlelist_**********_0_{i}.html' # 构造url
response = requests.get(url, headers=headers) # 发起请求
response.encoding = response.apparent_encoding # 设置编码格式
result = etree.HTML(response.text) # xpath解析
divs = result.xpath('//*[@id="module_928"]/div[2]/div[1]/div[2]/div')
for div in divs:
title = ("".join(div.xpath('./p[1]/span[2]/a/text()'))).replace("\xa0", "") # 获取文章标题
date = ("".join(div.xpath('./p[2]/span[2]/text()')))[:10] # 获取日期,不要时间
link = "".join(div.xpath('./p[1]/span[2]/a/@href')) # 获取文章链接
根据文章链接获取每一页的数据
这里是遇到的第一个问题,也耽搁了好久。博主最早的文章可以追溯到2006年,时间上跨越了16年之久,网页数据结构有差别,一开始为了简洁我用的是xpath,请求之后发现好多文章内容是空白,分析之后发现xpath的层级不一样,有好多种情况要做判断,多次尝试之后不得不放弃。但通过分析发现,所有文章内容都是在“class=articalContent newfont_family”或“class=articalContent ”下面,经过调试,最后决定使用BeautifulSoup的select方法获取class标签下所有文字。
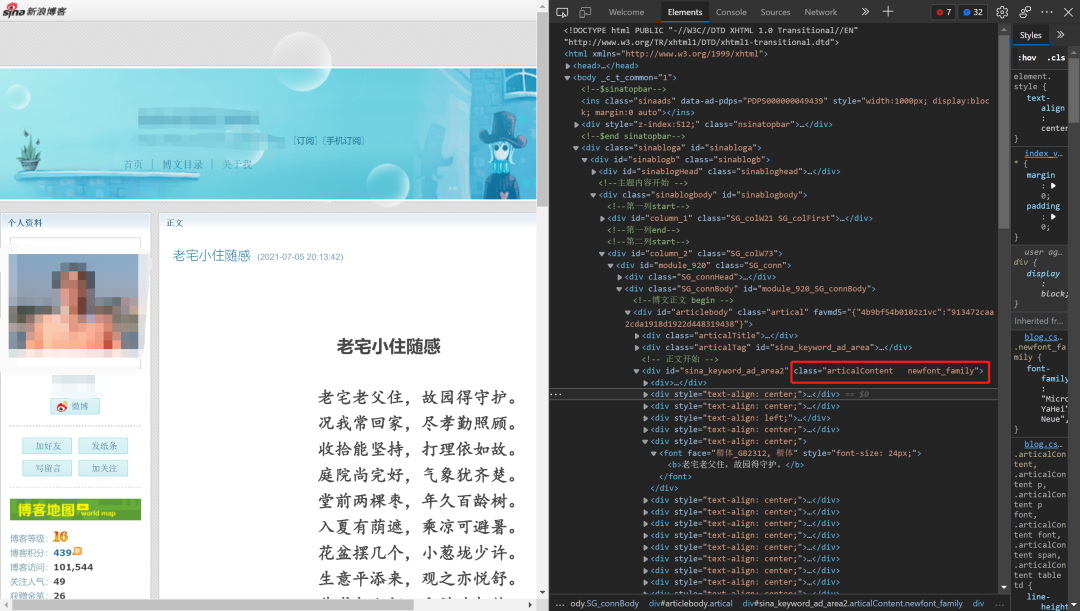
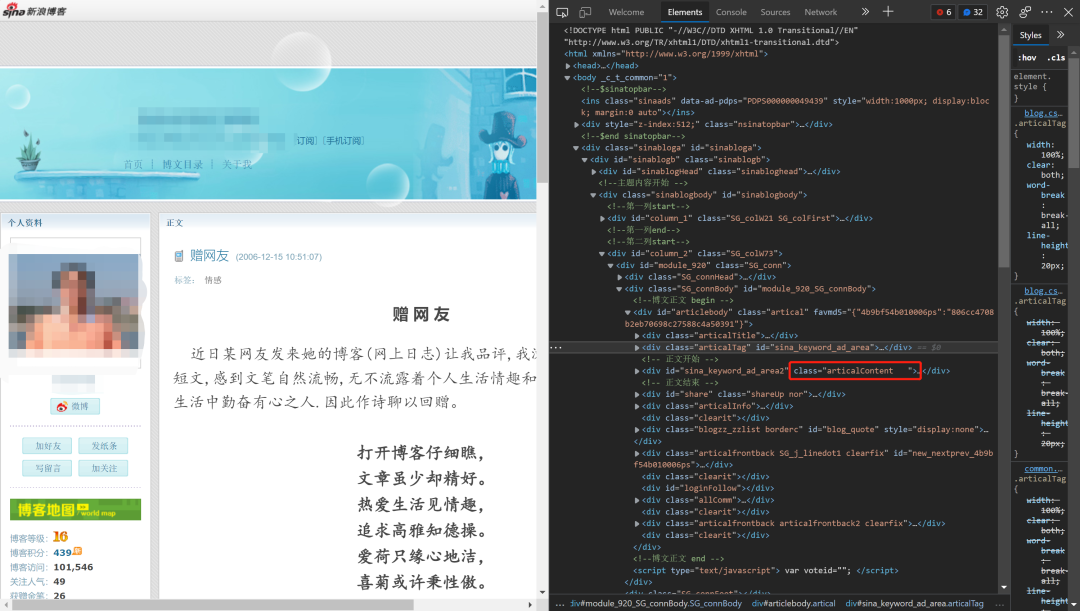
代码如下:
res_data = requests.get(link, headers=headers) # 发起请求
res_data.encoding = res_data.apparent_encoding # 设置编码
soup = BeautifulSoup(res_data.text, "html.parser") # 解析
articles = soup.select(".articalContent") # 取值
for article in articles:
content = article.text.strip() # 获取文本内容
数据写入和保存
docx库的写入相对来说比较容易理解,写入的过程可以根据每一步写入的需要融合进代码中。这里需要注意的是,百度的时候不要搜索“python docx库”直接搜“docx库”。
完整代码
import requests
from lxml import etree
import docx
from docx.oxml.ns import qn # 用于中文字体
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36',
'Referer': 'http://blog.sina.com.cn/********',
}
doc = docx.Document() # 新建word文档
doc.styles['Normal'].font.name = u'宋体' # 设置全局字体
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
for i in range(1, 23):
counter = 0 # 计数器
url = f'http://blog.sina.com.cn/s/articlelist_**********_0_{i}.html' # 构造url
response = requests.get(url, headers=headers) # 发起请求
response.encoding = response.apparent_encoding # 设置编码格式
result = etree.HTML(response.text) # xpath解析
divs = result.xpath('//*[@id="module_928"]/div[2]/div[1]/div[2]/div')
for div in divs:
title = ("".join(div.xpath('./p[1]/span[2]/a/text()'))).replace("\xa0", "") # 获取文章标题
doc.add_heading(title, 1) # 添加文章标题为一级标题
date = ("".join(div.xpath('./p[2]/span[2]/text()')))[:10] # 获取日期,不要时间
doc.add_paragraph(date) # 添加日期
print(f"正在写入文章 {title}……")
link = "".join(div.xpath('./p[1]/span[2]/a/@href')) # 获取文章链接
res_data = requests.get(link, headers=headers) # 发起请求
res_data.encoding = res_data.apparent_encoding # 设置编码
soup = BeautifulSoup(res_data.text, "html.parser") # 解析
articles = soup.select(".articalContent") # 取值
for article in articles:
content = article.text.strip() # 获取文本内容
doc.add_paragraph(content) # 写入
doc.add_page_break() # 增加分页
counter += 1
print(f"第{i}页,已写入 {counter} 篇文章。")
doc.save("随缘即福新浪博客文章.docx")
整理前效果展示

格式调整、交付
docx库平常使用的比较少,以上代码仅限于拿到数据和实现基本的写入和分页的要求,剩下的格式调整、目录生成与其百度去搜索和代码调试,我更愿意使用wps office等可视化工具去处理,方便、专业、高效,最终效果如下:


写在最后
至此,跨越16年的1090篇文章全部拿下,word写入共1790页,近30万字,由衷地钦佩老先生知识储备之丰富,文采之飞扬。同时也感谢雇主在沟通过程中给予的理解,感谢蚂蚁老师提供的平台,最后也感谢一下A0-Vinson小辰。
最后,推荐蚂蚁老师的《Python爬虫课》限时优惠69元: