
骚气的 Pandas 取数操作
共 2947字,需浏览 6分钟
·
2021-06-30 20:43
本文介绍如何在 Pandas 进行 DataFrame 类型数据的筛选和查看。因为Pandas中有各种花样来进行数据筛选,本文先介绍其中的一部分。
一、模拟数据
本文中各种例子基于一份模拟数据展开,在创建数据的时候引入了部分缺失值,通过 numpy 库来生成:
import pandas as pd
import numpy as np
df = pd.DataFrame({
"name":['小明','小王','张菲','关宇','孙小小','王建国','刘蓓'],
"sex":['男','女','女','男','女','男','女'],
"age":[20,23,18,21,25,21,24],
"score":[np.nan,600,550,np.nan,610,580,634], # 缺失两条数据
"address":["广东省深圳市南山区",
np.nan, # 数据缺失
"湖南省长沙市雨花区",
"北京市东城区",
"广东省广州市白云区",
"湖北省武汉市江夏区",
"广东省深圳市龙华区"]
})
df
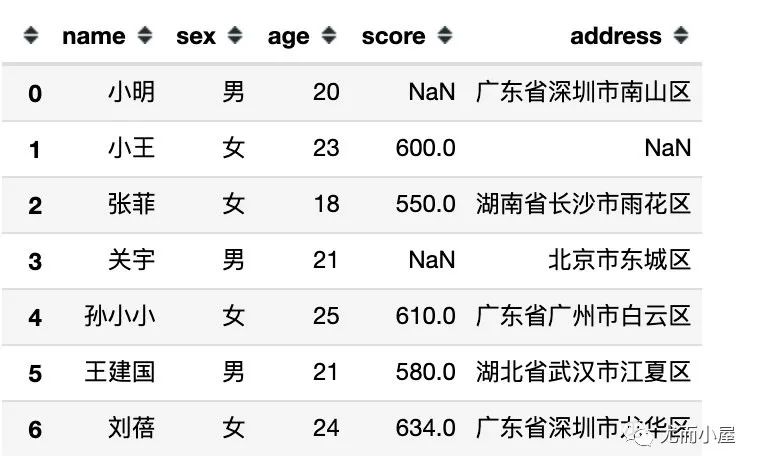
我们查看下各个字段的数据类型:3个字符类型,一个int64,一个float64类型

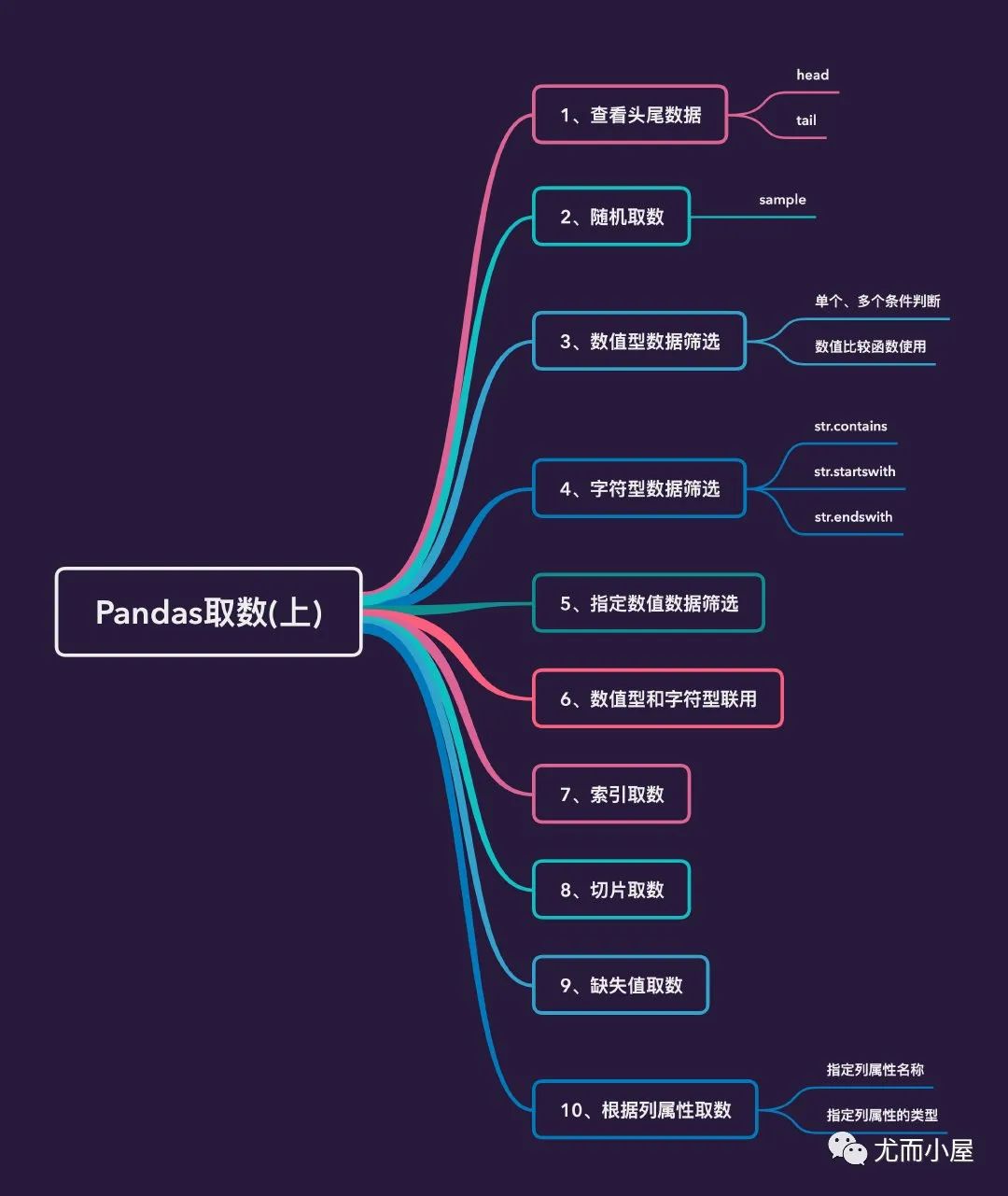
二、思维导图
下面导图中介绍的多种基础的取数方式:
三、查看头尾数据
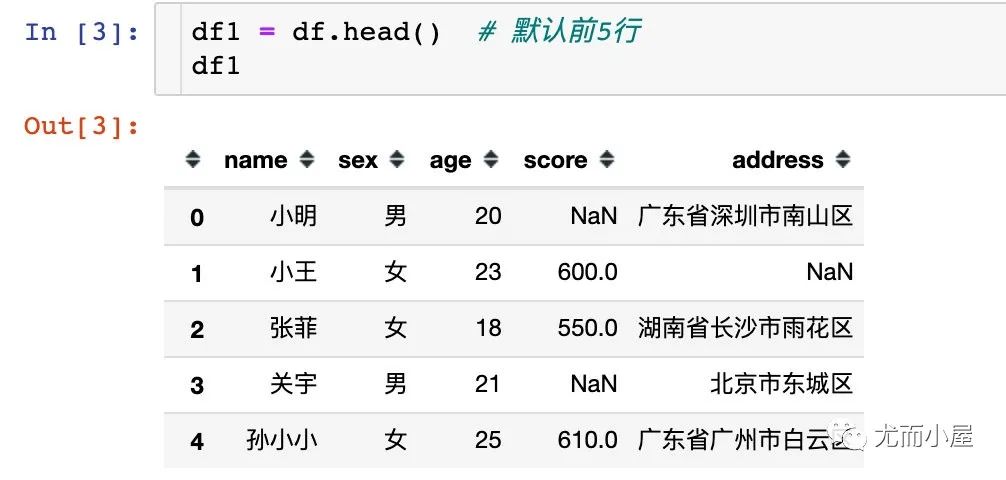
查看头尾数据,使用的是head和tail方法:
3.1 head
该方法默认是前5行
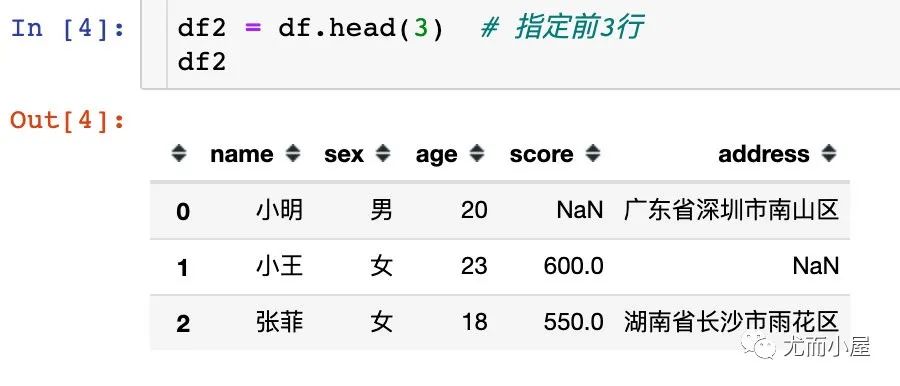
可以自己指定看多少行数据:
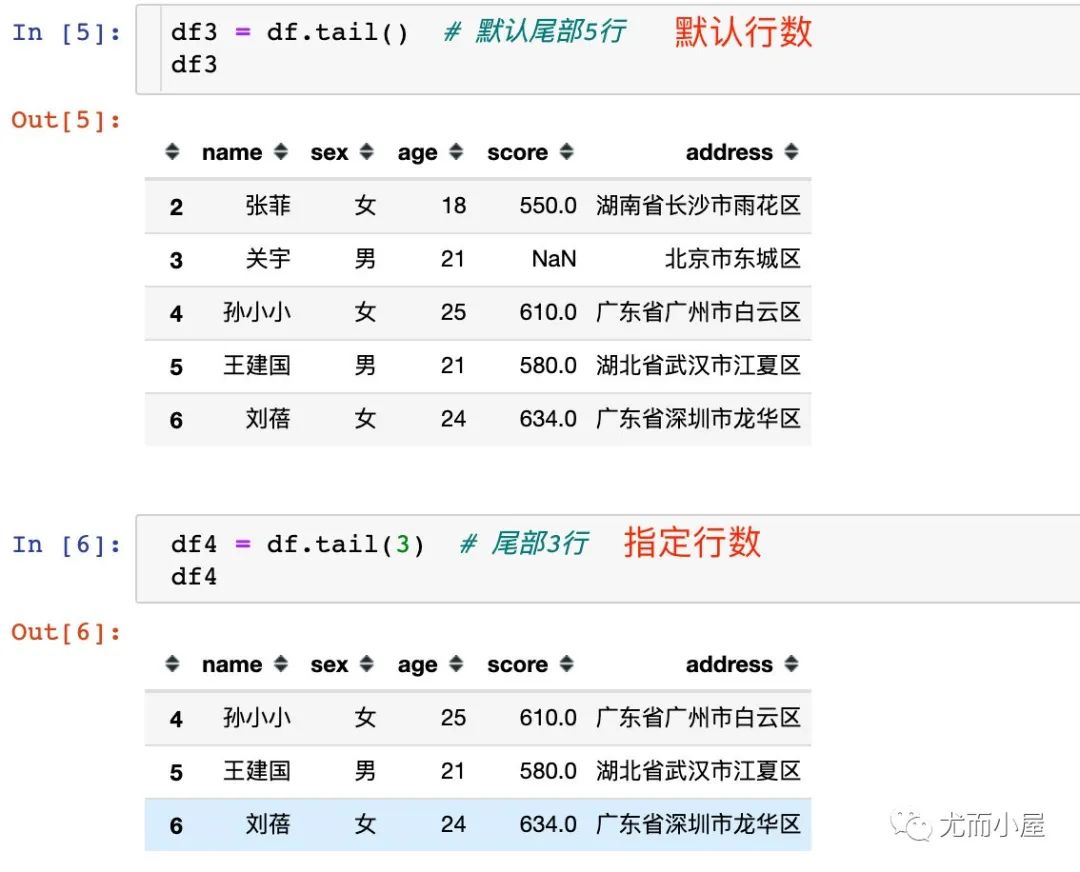
3.2 tail
tail使用方法是类似的:
默认尾部5行 指定查看行数
四、随机筛选
使用的是sample方法,默认是查看一行数据,也可以指定查看多少行:

五、数值型数据筛选
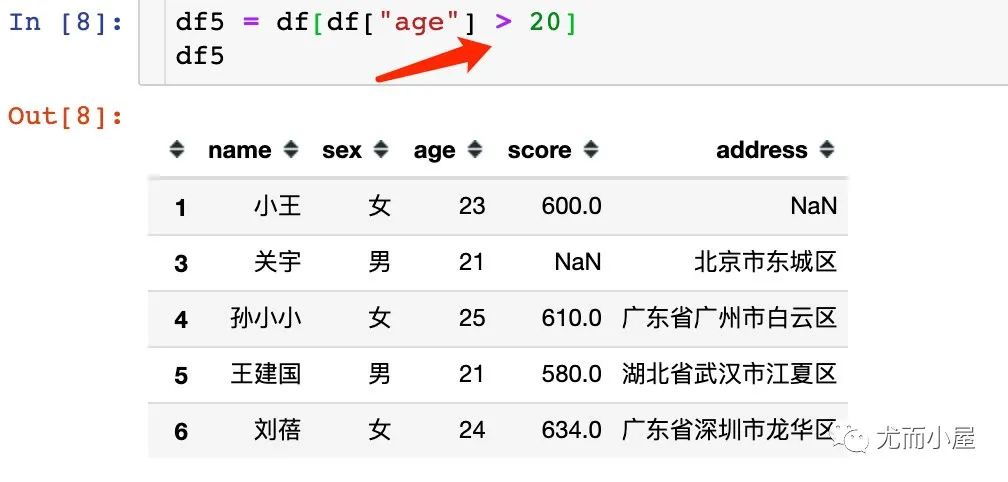
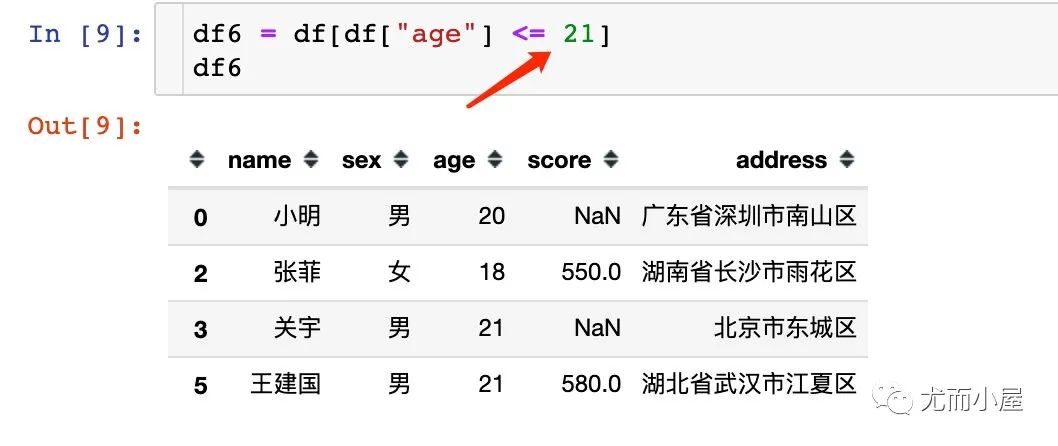
5.1 单个条件
1、数值型数据的筛选一般是根据大小比较来进行的:
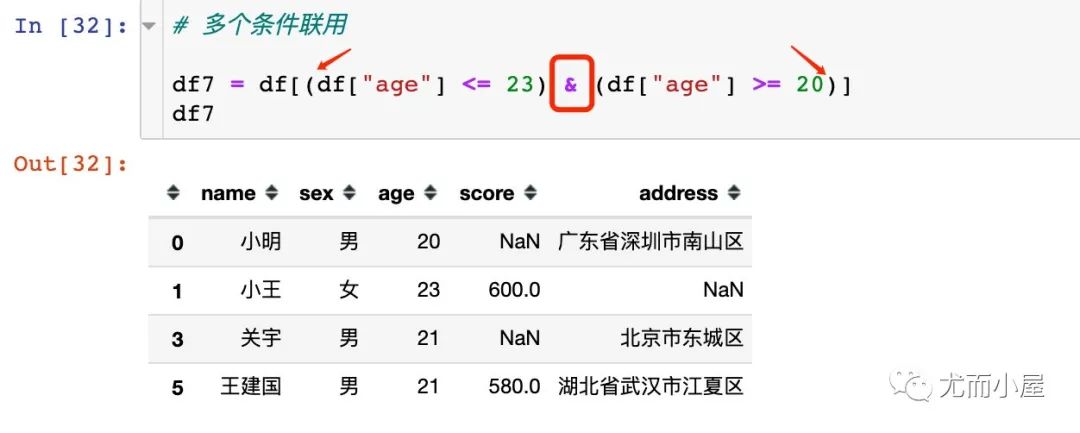
5.2 多个条件
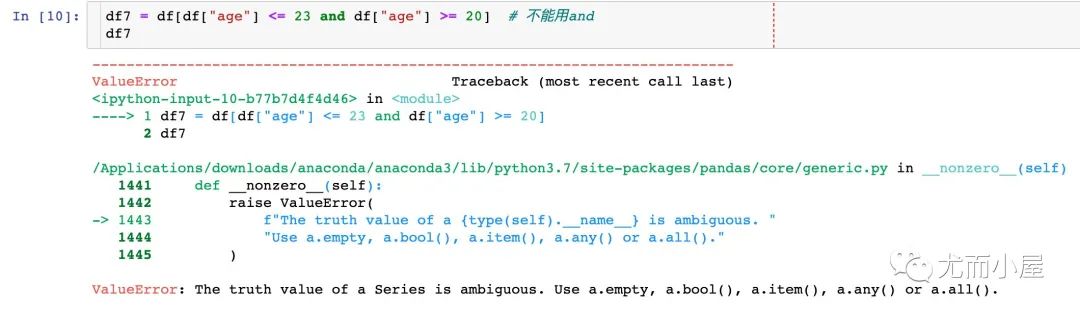
2、当我们存在多个比较条件的时候,需要注意:
表示“且”不能用and,使用&符号;表示“或”使用用竖线 |每个条件要使用小括号
下面是正确的写法:
5.3 使用数值函数
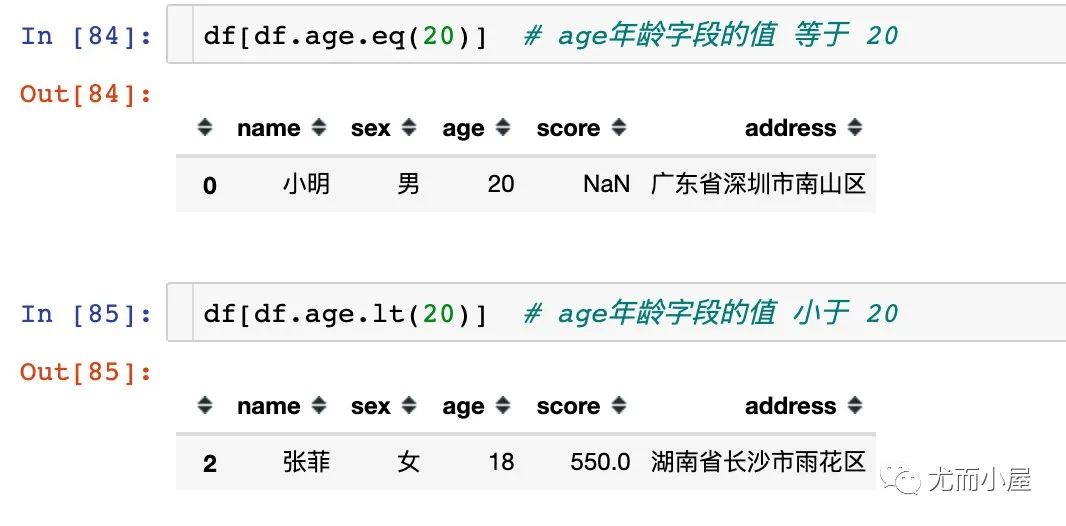
常用的数值比较函数如下:
df.eq() # 等于相等 ==
df.ne() # 不等于 !=
df.le() # 小于等于 >=
df.lt() # 小于 <
df.ge() # 大于等于 >=
df.gt() # 大于 >
1、使用单个数值函数筛选
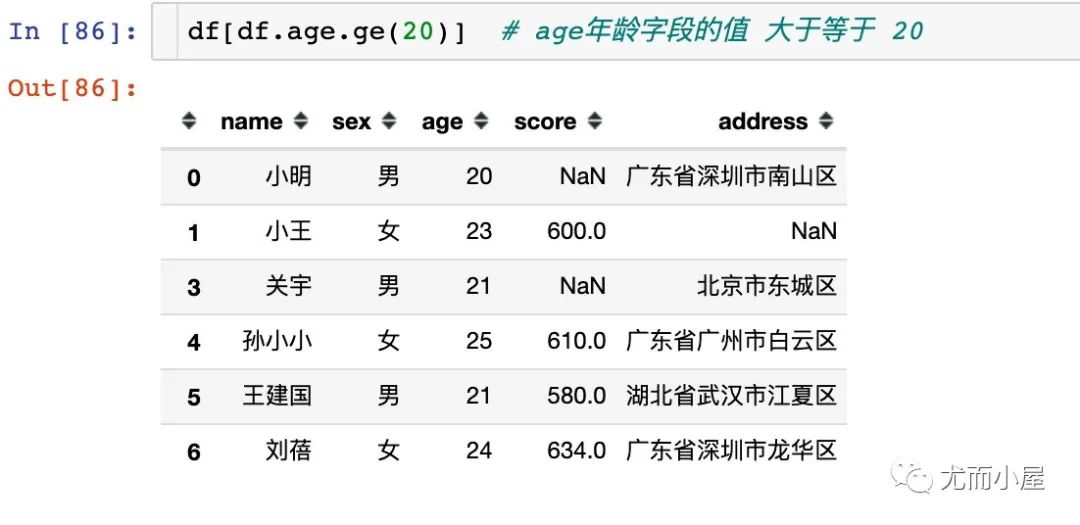
2、使用多个数值函数筛选;

六、字符型数据筛选
字符类型数据的筛选主要是通过python和pandas中相关函数;
包含:str.contains 开始:str.startswith 结束:str.endswith
下图中的3个例子讲解了上面3个函数的使用方法:

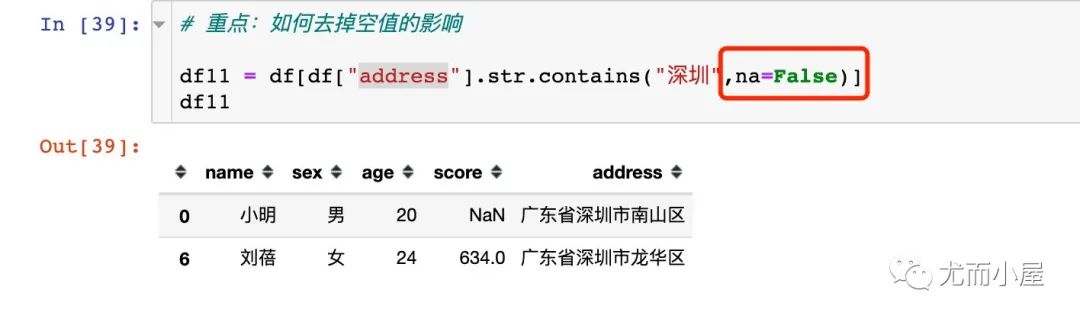
上面的例子中使用的字段本身都是没有空值的,如果字段中带有空值,该如何处理?比如我们想选出address带有“深圳”的同学:

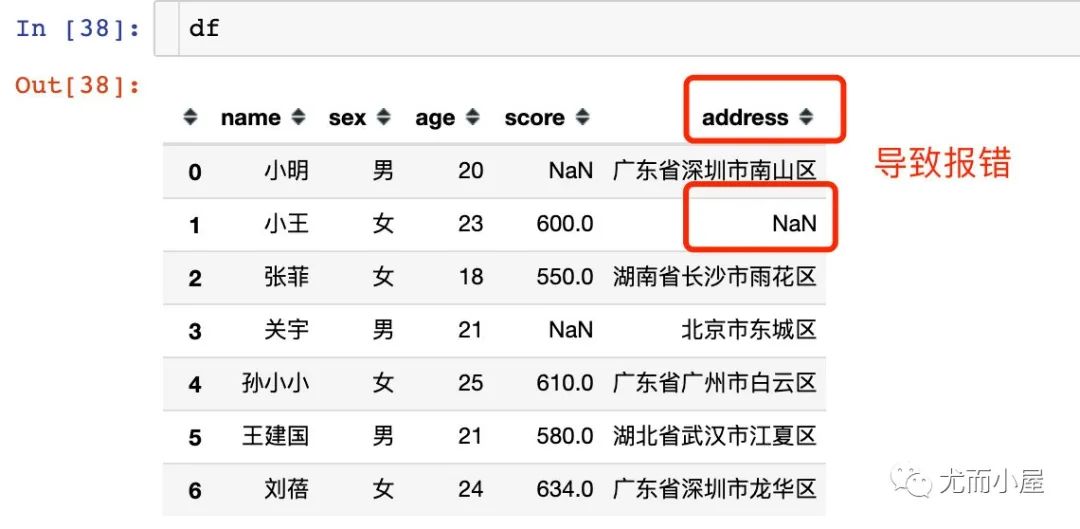
解决方法1:带上参数
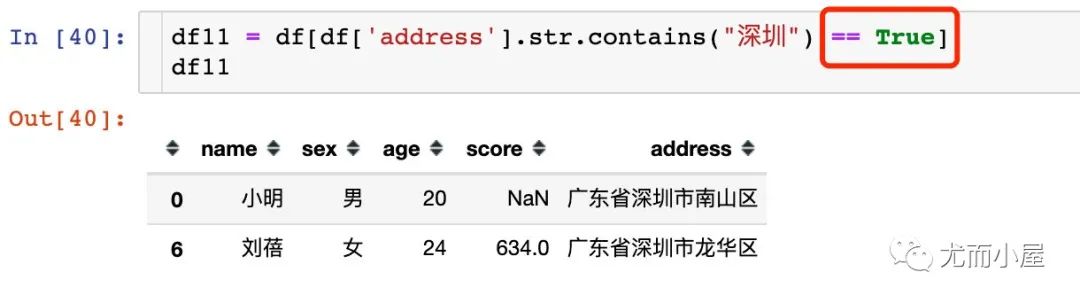
解决方法2:通过布尔值的比较判断
七、指定数据值筛选
通过指定某个字段的具体某个值来筛选数据:

八、数值型和字符型联用
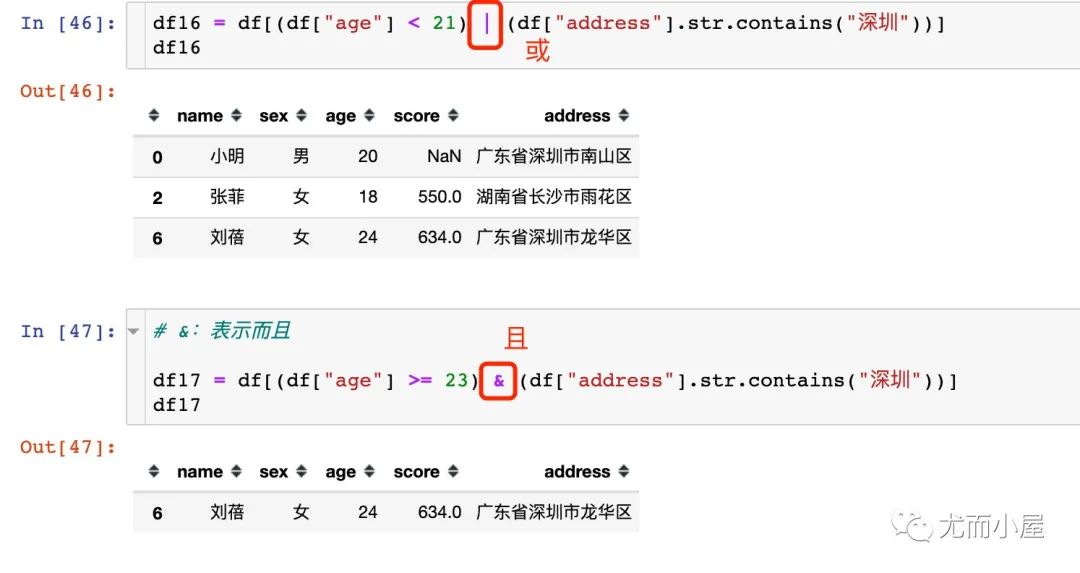
数值型的大小比较条件和字符相关条件的联合使用:
且:& 或:|
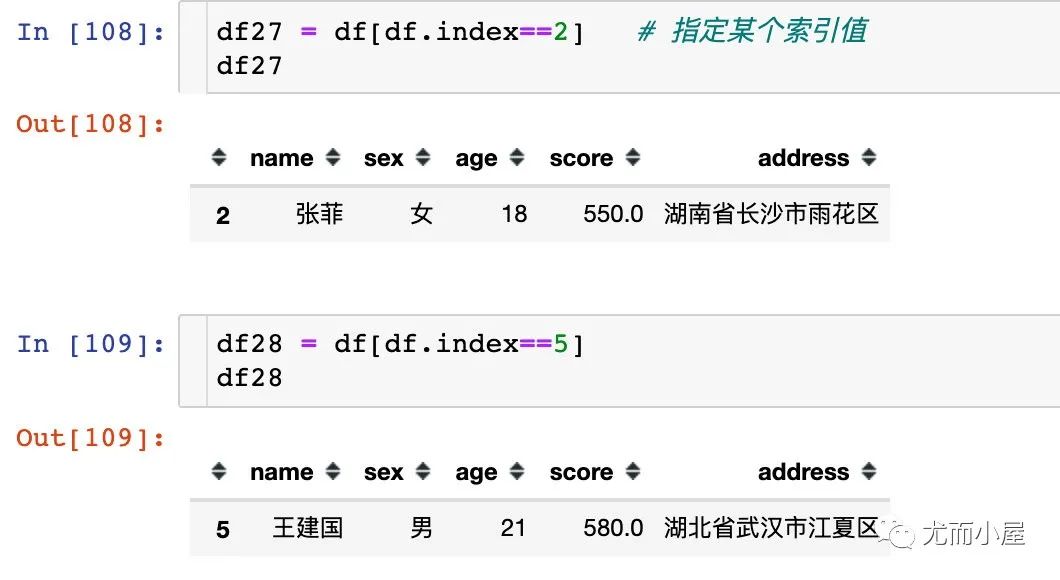
九、索引取数
直接通过某个索引值来取数,这种情况很少用:
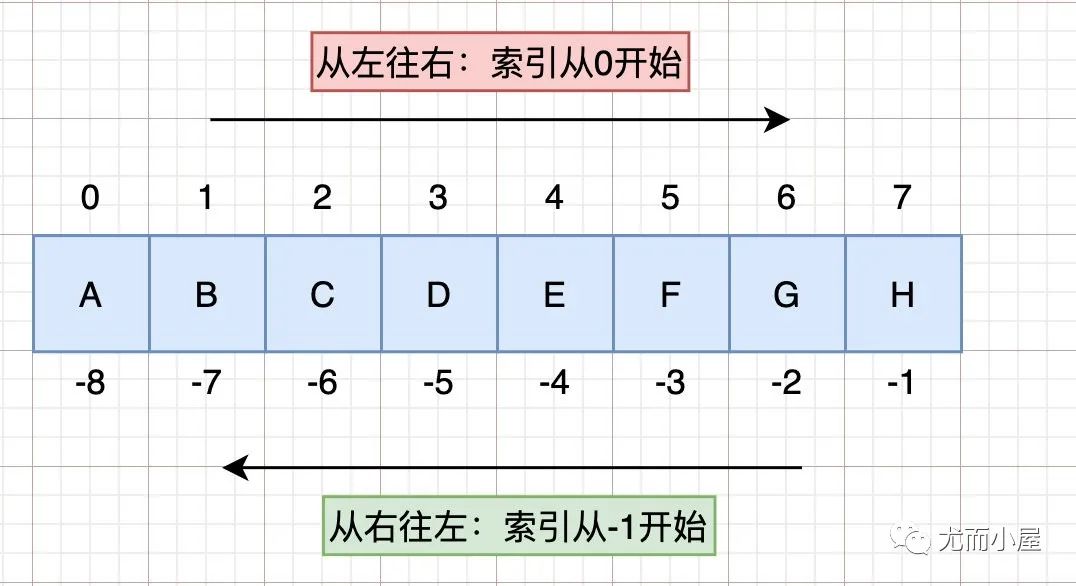
十、切片取数
pandas中切片取数和Python中是相同的:
左边索引从0开始计数,右边索引从-1开始计数 切片规则: start:stop:step,分别表示起始位置start,结束位置stop,步长step(可正可负)
不包含结束索引位置的元素:含头不含尾,请记住索引切片的重要规则!!!
使用切片的单个数值取数:

使用切片取数的多种案例:

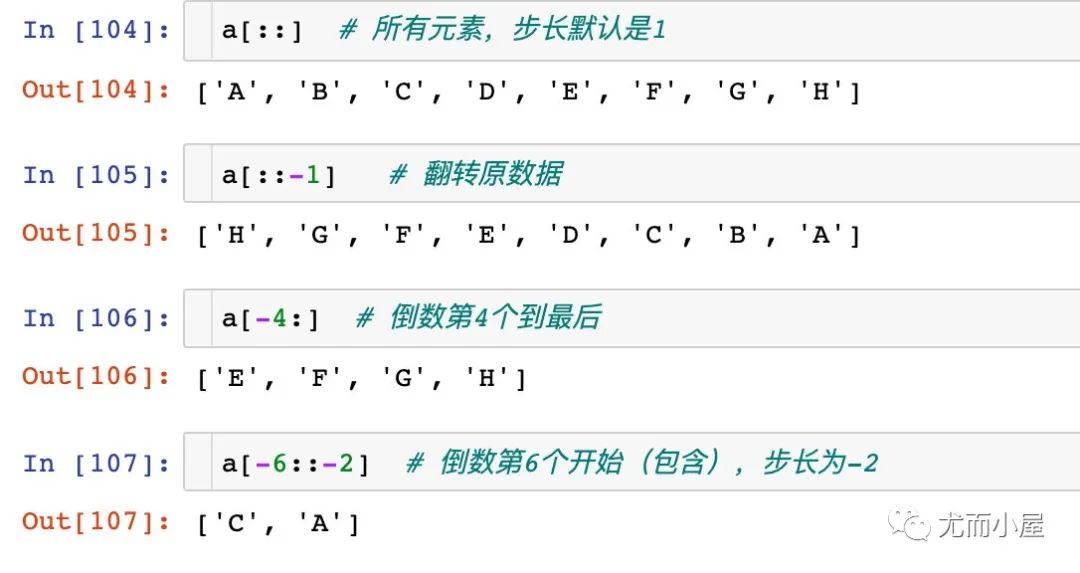
下面看看本文案例中的切片取数:
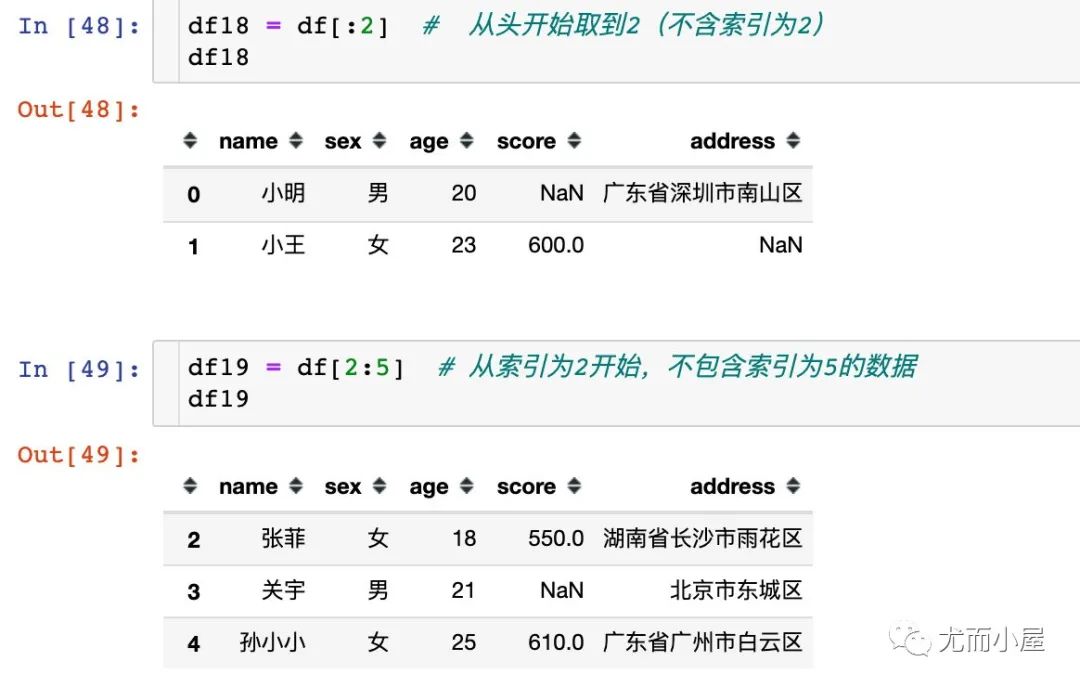
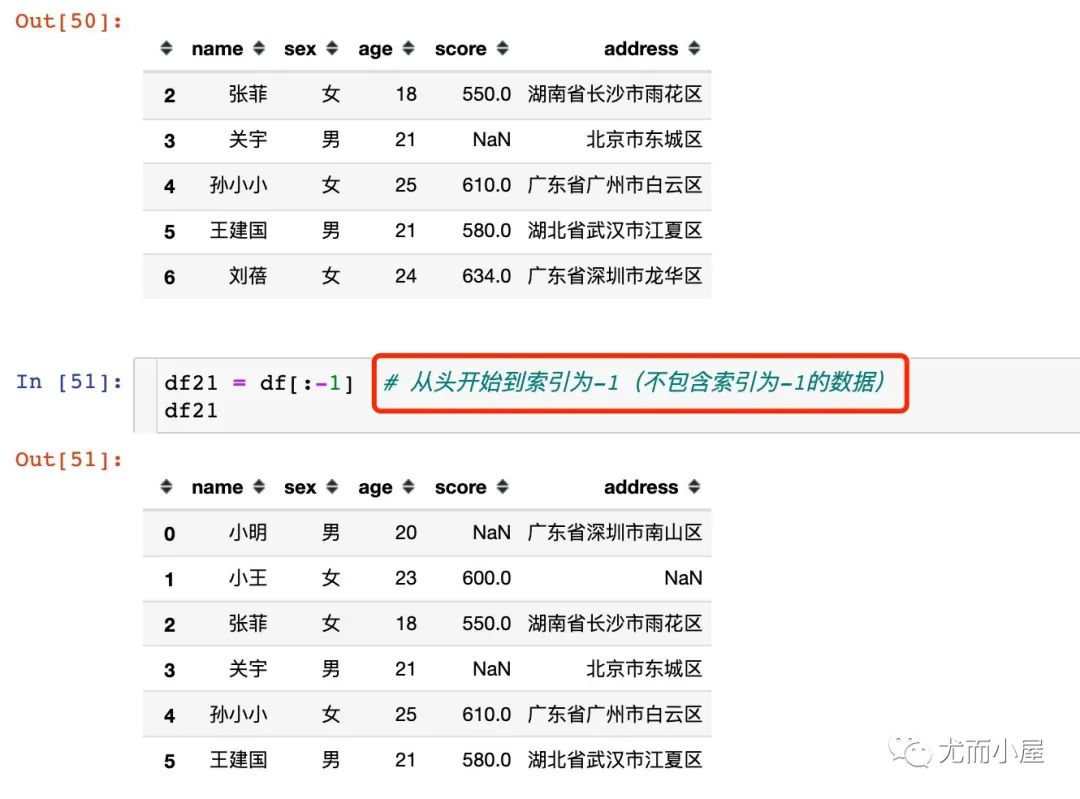
步长不为1和索引为负数的情况:
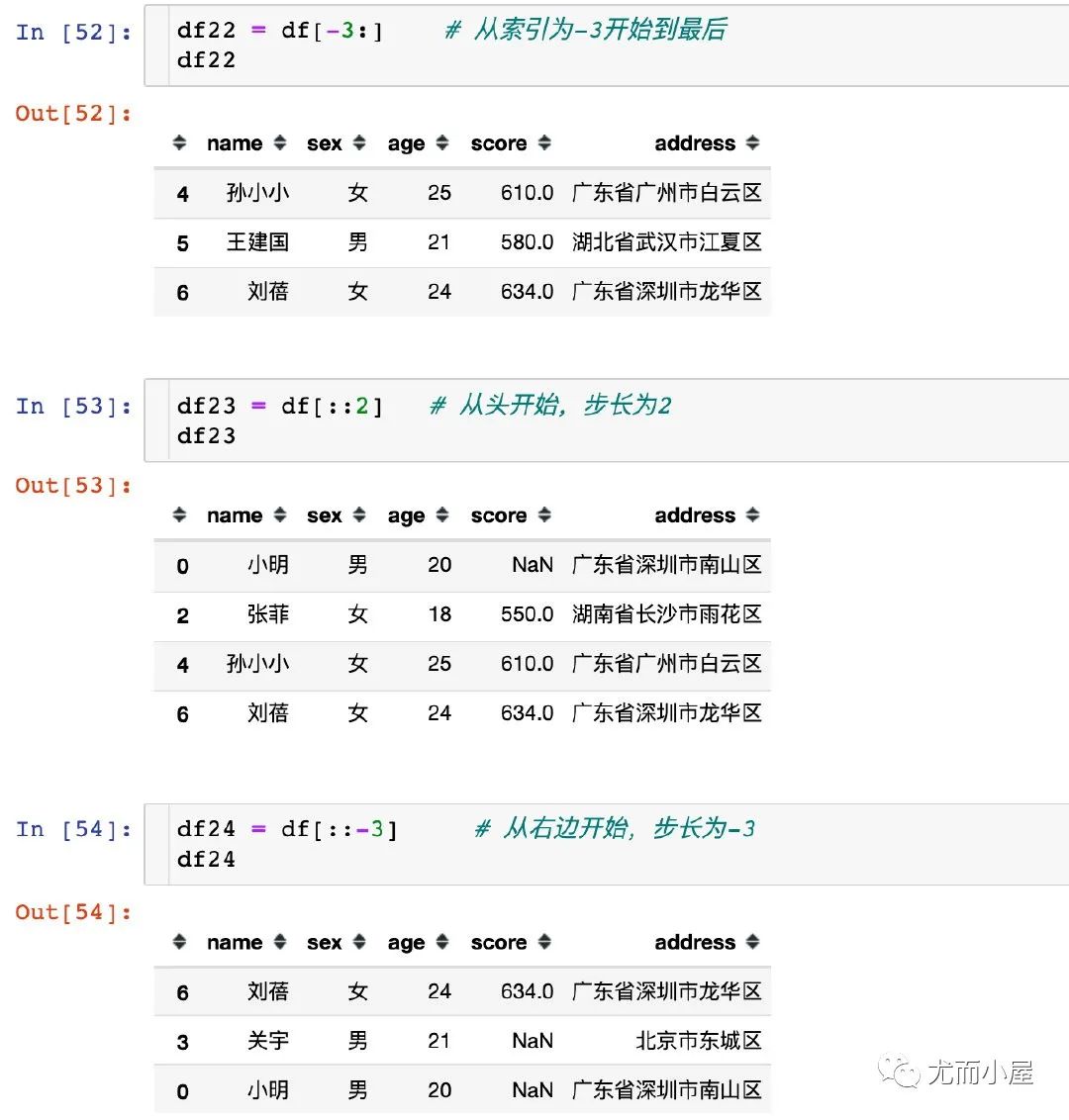
十一、缺失值筛选
本文中使用的案例缺失值情况为:
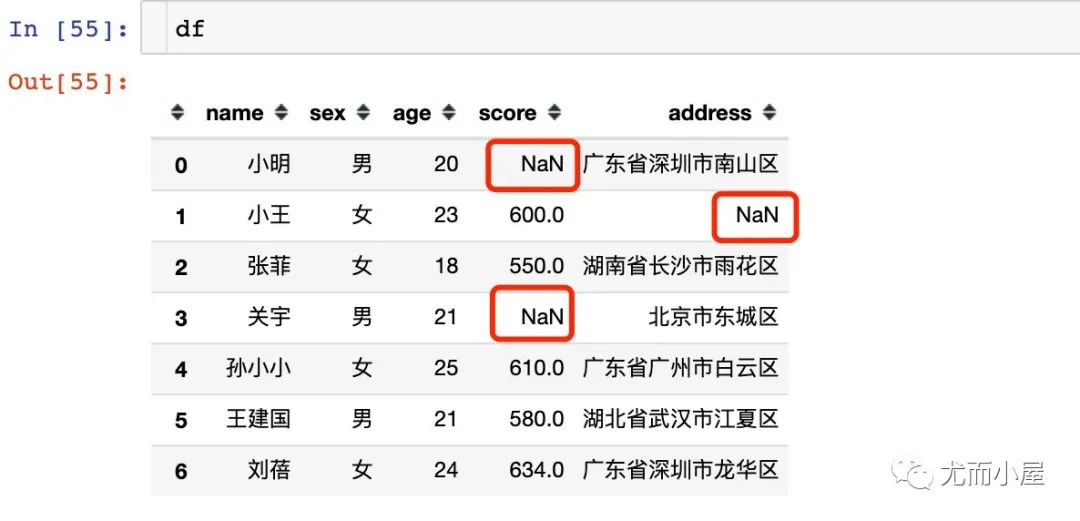
11.1 查看缺失值
df.isnull()
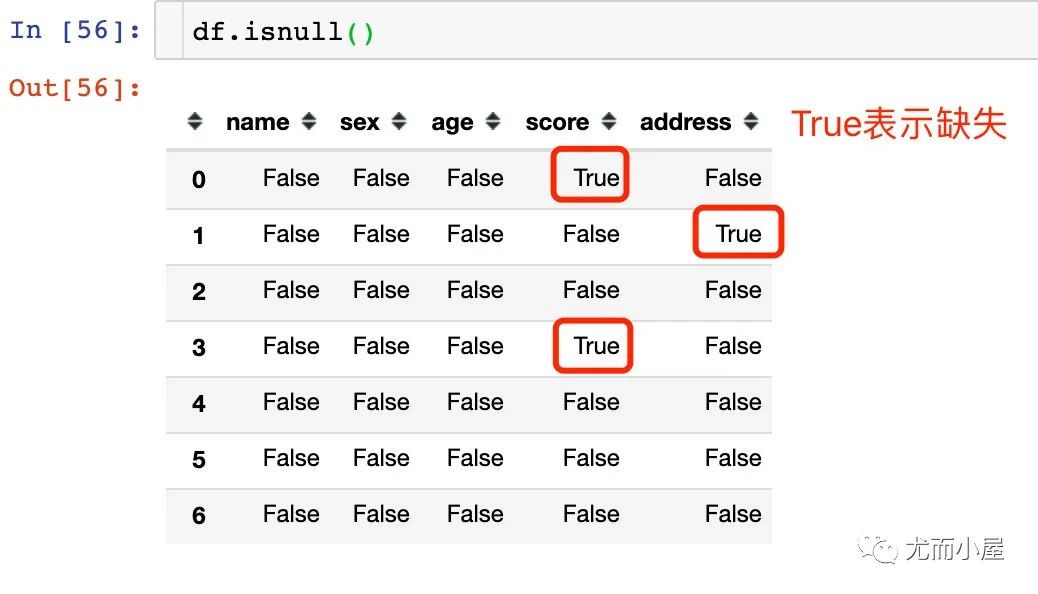
11.2 查看字段缺失值
df25 = df.isnull().any() # 列中是否存在空值
df25

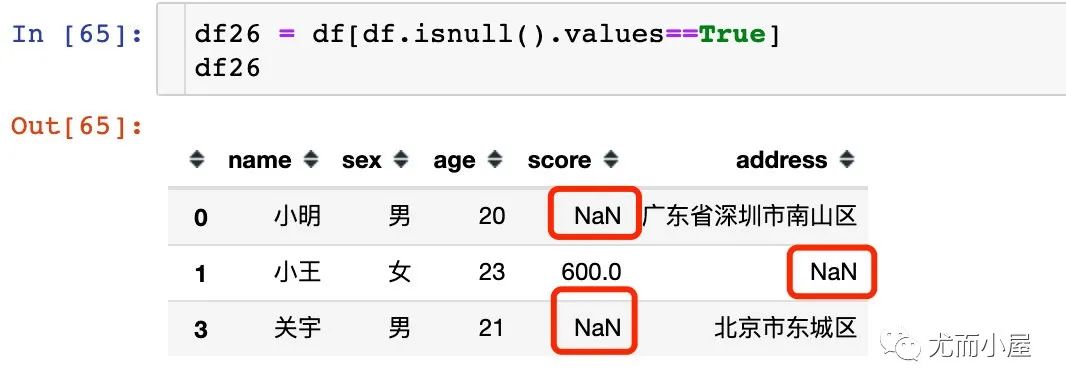
11.3 锁定缺失值存在的行
df26 = df[df.isnull().values==True]
df26
十二、列属性取数
12.1 指定属性名
第一种是我们直接指定列属性的名称,在这种情况下取出来的是Series类型数据

第二种情况下取出来的是DataFram e类型数据:
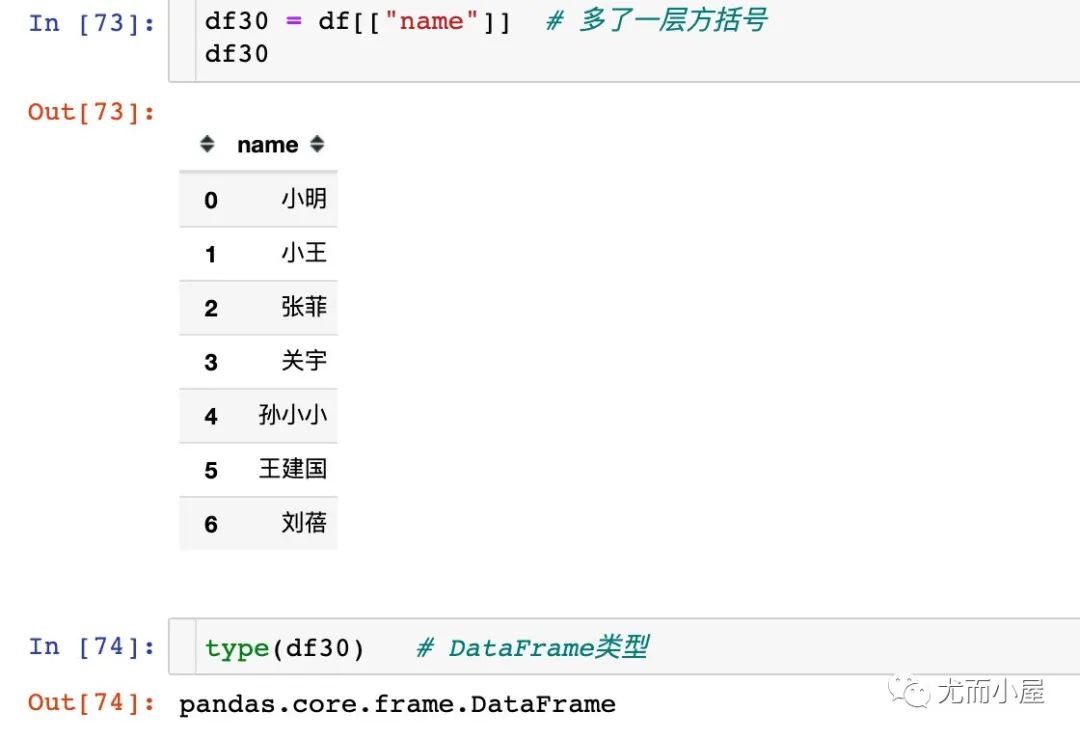

12.2 指定字段属性的类型
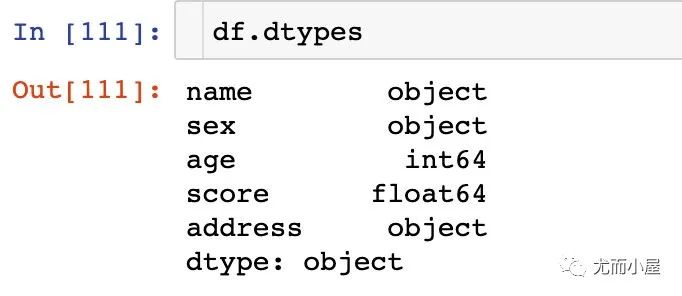
本文案例的数据字段类型为:
1、取出包含object类型的数据:
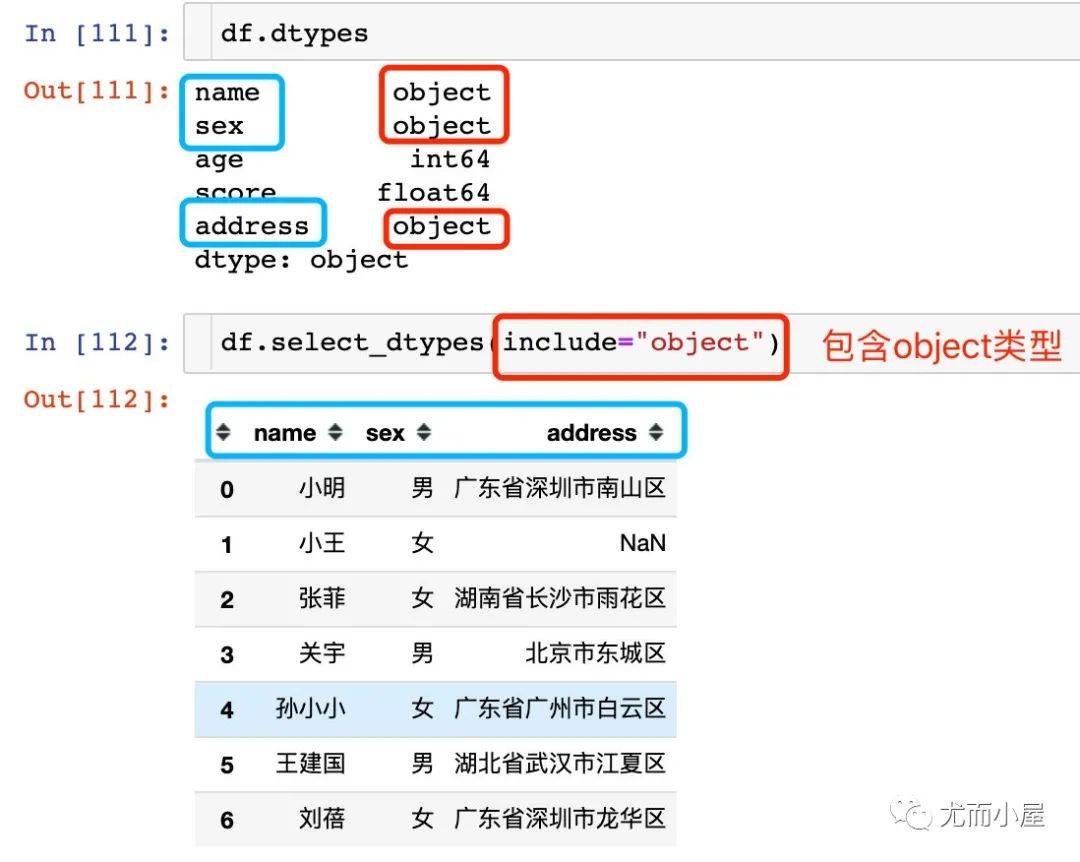
如果是想取出包含多种类型的数据:
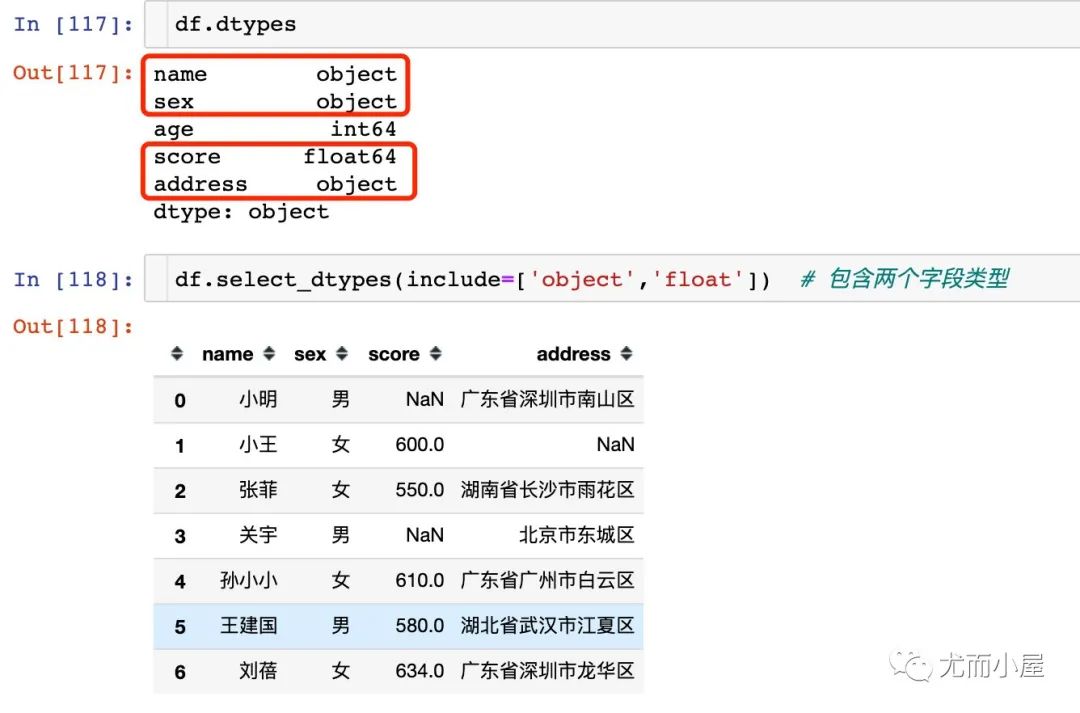
2、取出不包含object类型的数据:

十三、总结
Pandas中取数的方式真的是五花八门,有很多方式能够取到我们想要的数据。本文中介绍的多种方式算是比较基本,比如头尾部数据、基于条件判断的筛选、切片筛选等,后续将会介绍更多Pandas中取数技巧,敬请期待!