
【06】无人驾驶的预测
1.简介
无人车在与多物体之间穿梭行驶,这些物体本身就是一直在移动的,比如汽车、自行车、行人等,无人车需要预测这些物体的行为,来帮助无人车做出最佳的决策。通常情况会生成一条路径来预测一个物体的行动轨迹,看下边这辆车,它所在的车道是匝道,并且在入口处有右转和减速的趋势,此时我们就可以判断他大概率是要下匝道了,因此车辆前方的箭头就是我们为车辆生成的一条预测轨迹。

在无人车行驶的过程中,我们对所有的物体做出类似的预测,在每一个时间段内,我们会为每一辆车重新计算预测他们新生成的路径,这些预测路径为我们无人车在规划阶段做出合理的路径规划提供了必要的支持。
预测路径有非常高实时性的要求,试想一下,假如一辆车以60km/h的速度行驶,那么每秒就是16.66米,所以系统稍微存在一些延迟就会产生很大的误差,因此预测路径对实效性的要求很高。
另一个要求就是准确性,以下图为例,我们同向车道上有一辆车,他有可能会直行也可能并入我方车道,不同的行驶方式会决定自车的行驶方式,正确的预测有助于车辆保持连续且平稳的行驶。

除了这些特性之外,预测功能还应该应用人工智能能力,自主学习新的行为,当路上有很多车的时候,情况变得复杂,开发出每种场景的静态模型是不可能完成的任务,因此就需要预测模块具备学习的能力,当我们使用多源的算法进行训练的时候,随着时间的推移,算法的预测能力能不断的提升。
2.不同的预测方式
我们介绍两种不同的预测方式。基于模型的预测与基于数据驱动预测。
假如我们在一个丁字路口,我们看到左边有一辆车行驶而来,如下图所示:

此时我们还不知道这辆车是要右转还是要直行,用基于模型的方法,我们可以为这个场景创建两个候选的预测模型,一个模型描述了该车进行右转弯,在下图中用绿色轨迹描述,另一份模型描述了该车继续直行,我们用蓝色轨迹描述,在此刻我们认为两种轨迹发生的概率是相同的:
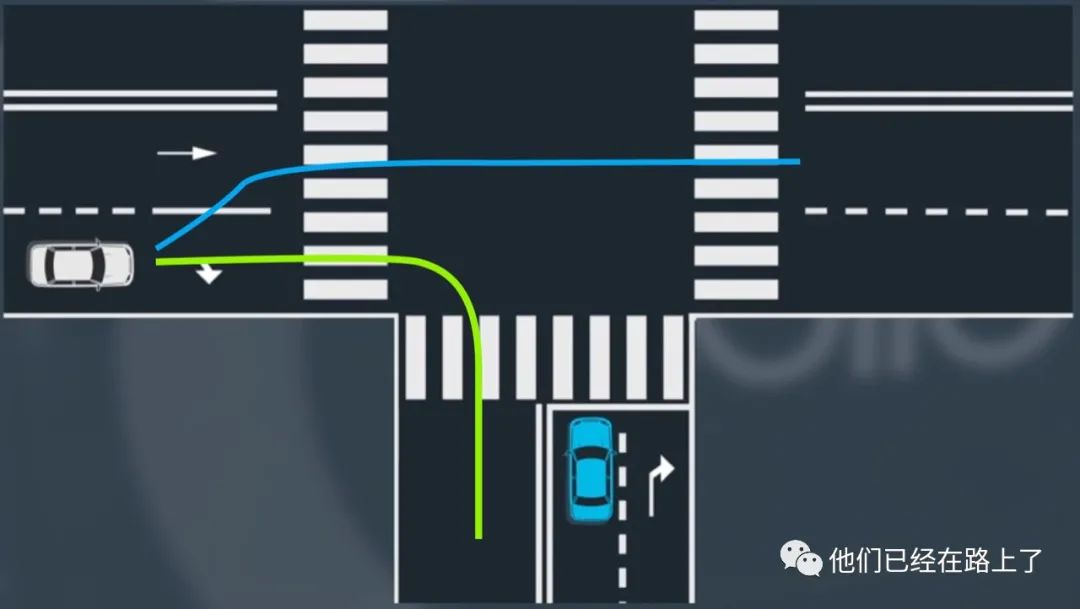
因此此时我们有两个候选模型,每个模型都有自己的轨迹,我们继续观察白色车辆的移动,继续预测他的行为,看和哪一条轨迹更加匹配,如果我们看到车辆开始向左变道,我们就可以更加确信车辆最终会直行,但如果我们看到车在左右转弯的车道继续保持着前行,我们则会预测车辆会进行右转,这就是基于模型预测方法的工作原理。
另一种预测方法是数据驱动预测,数据驱动预测使用机器学习算法,通过观察结果来训练模型,一旦机器学习模型训练好,我们就可以在现实世界中利用此模型去做出预测,数据驱动方法的优点是训练数据越多,模型效果越好。而基于模型的方法的优点在于它的直观,并且它结合了我们现有的物理知识以及交通法规还有人类行为多方面知识。
3.基于车道的预测
3.1 方法简介
这里我们讲讲百度Apollo带来的预测方式,它提供了一种基于车道序列的方法,来实现预测。为了建立车道序列,我们首先将道路分成多个部分,如下图所示:
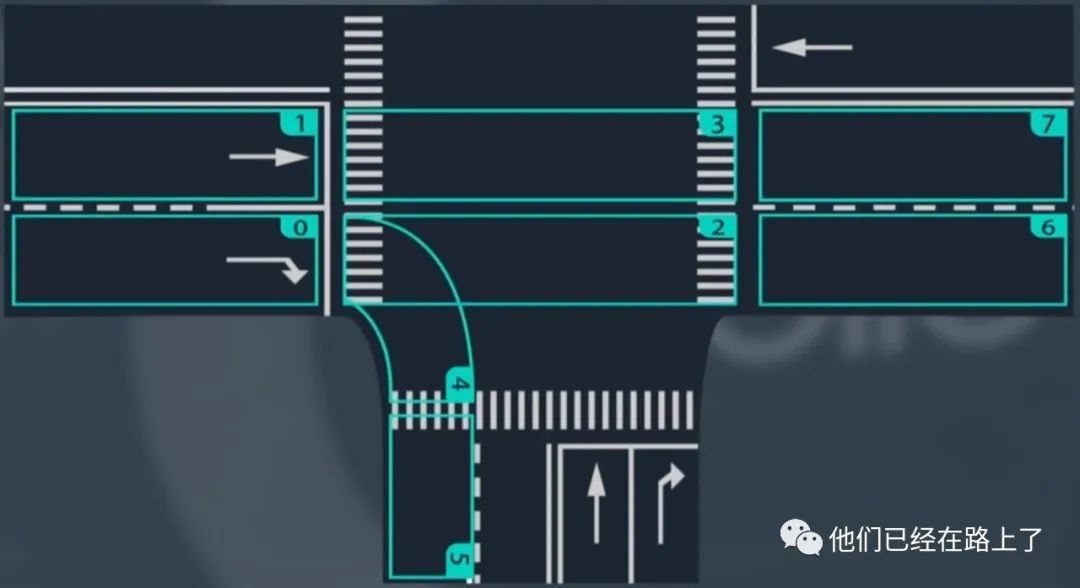
每一个部分都覆盖了一个易于描述车辆运动的区域,如上图所示的十字路口,为了预测,我们更关系车辆如何在这些区域内转换,而不是车辆在某个区域内的具体行为,我们可以将车辆的行为划分为一组有限的模式组合,并将这些模式组合描述为车道序列,例如车辆直行的运动可以描述为车道序列是0-1-3-7,如下图所示:

这就是基于车道的预测。
3.2 障碍物的状态
为了预测物体的运动,我们就需要知道物体的状态,当我们开车时,作为人类,我们通过观察一个物体的朝向、位置、速度和加速度来预测它接下来的行为,这种思路也是无人车观察物体状态的方式,除了上述四个参数之外,无人车还需要考虑车道段内物体的位置,例如预测模块会考虑物体到车道线段边界的纵向和横向距离,也就是车辆在路段内的位置,除此之外,预测模块还包含之前时间间隔的状态信息,以便做出更加准确的预测。
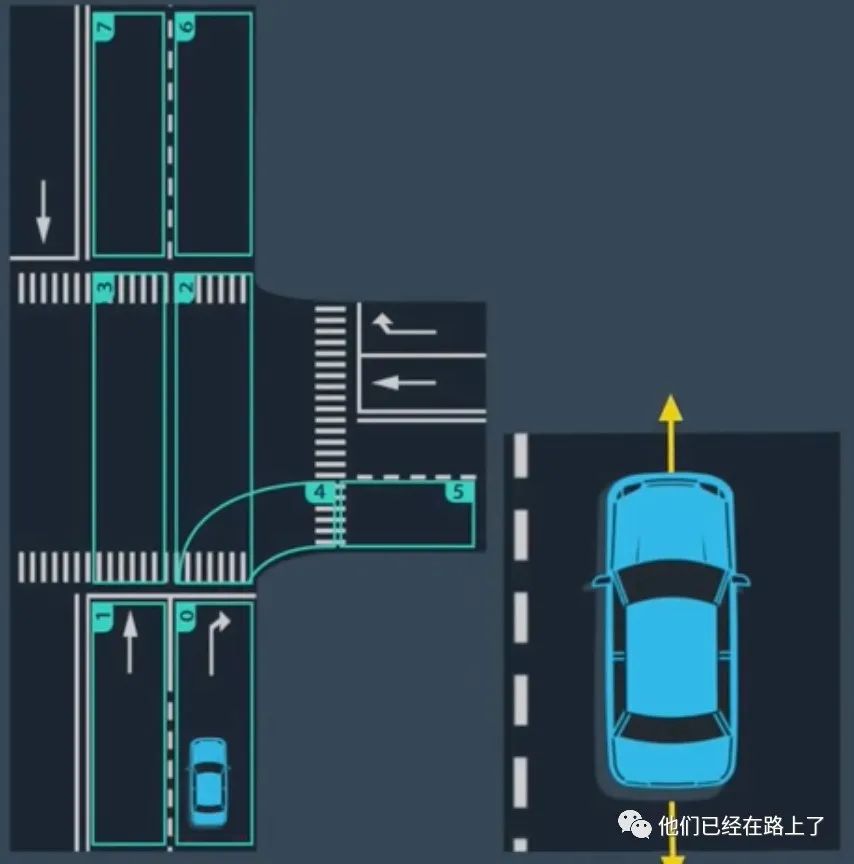
3.3 预测目标车道
我们使用车道序列框架的目标是为道路上的物体生成预测轨迹,这是一个非常复杂的过程,我们先从一个稍微简单的问题开始,我们会预测车道线段之间的过渡,假如我们在车道段0中检测到一辆车,我们要预测在接下来的几个时间段中它将如何行驶,现在有两个显而易见的情况,它可能会在0车道继续行驶,然后右转,或者可能转向车道段1然后直行,如图所示:
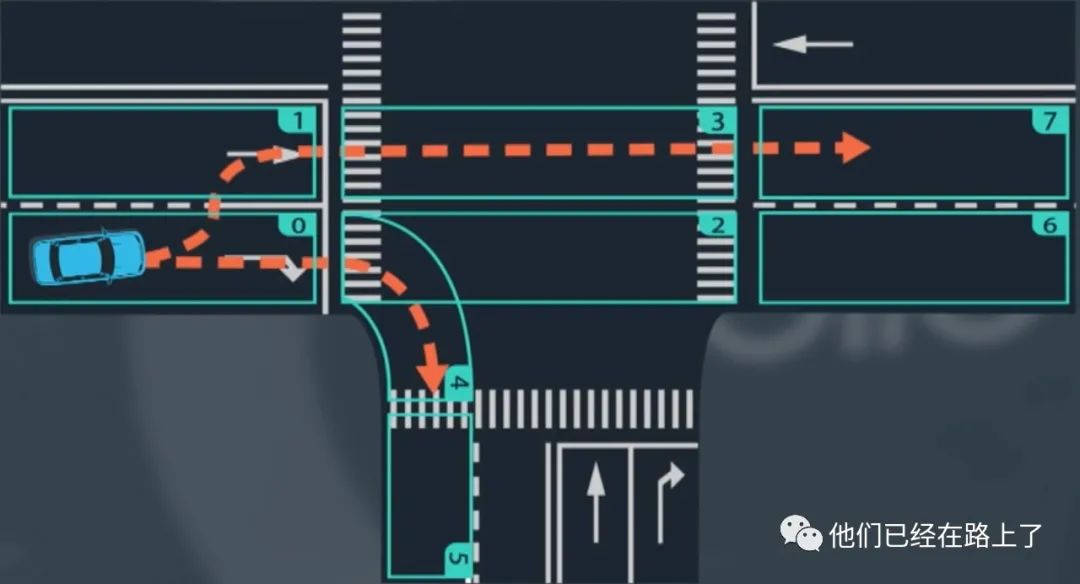
这个过程就已经将一个预测问题简化为了一个选择问题,可下来我们要做的就是选择车辆最有可能采取的车道顺序,我们可以通过计算每个车道序列的概率来进行选择,我们需要一个模型,将车辆状态和车道段作为输入,该模型用于提供车辆可能采用的每个车道序列的概率,我们希望我们的模型能否学习新的行为,因此应该使用观测数据对模型进行经验性训练,在训练中,我们将真实的车辆行为提供给模型,真实车辆行为的数据不仅包括车道段和对象的状态,还包括对象最终选择哪条车道序列,随着记录和时间的增加,模型可以自我迭代和更新,精确度不断提升,每个记录结果中包括观察对象跟随的车道段序列和对象的相关状态,在每个时间点,对象对应一段记录结果并具有特定的状态,整个记录由一系列车道段和对象的相关状态组成。
4.递归神经网络
递归神经网络(RNN)是一种利用时间序列数据特征的预测方法,在我们了解CNN之前,我们先来回顾一下之前提到过的神经网络。
神经网络是可训练的多层模型,神经网络从输入,提取高级特征,并使用这些特征来计算得到输出,例如现在有一个神经网络来分类图像是否包含汽车,网络的中间层将提取诸如车轮、窗户之类的特征,最终来实现识别。神经网络有许多结构,一个基本的神经网络首先得到输入,然后将数据通过隐藏层,然后经过处理的到输出,这种结果有时也被称作多层感知网络或MLP。在训练的过程中,会有很多训练数据输入模型,每一个数据都由原始的数据和对应的标签组成,例如输入数据是一张图片,而标签就是一个包含汽车的符号或者其他符号。神经网络从数据中学习的方式叫做后向传播,首先神经网络通道输入并产生输出,然后计算机比较输出与真值之间的误差,接着这种误差通过后向传回到整个神经网络,中间的隐藏层会根据观察到的这种差别调整其中的中间值或者叫权重,这样可以提到神经网络的准确率。该过程如下图:
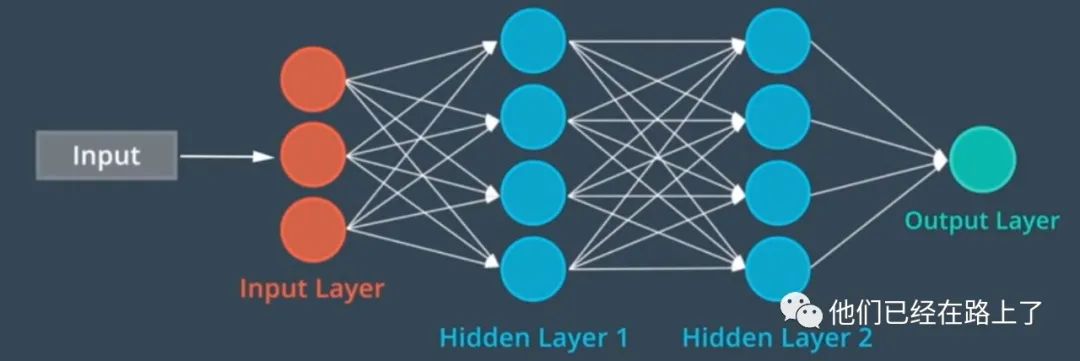
图 输出结果
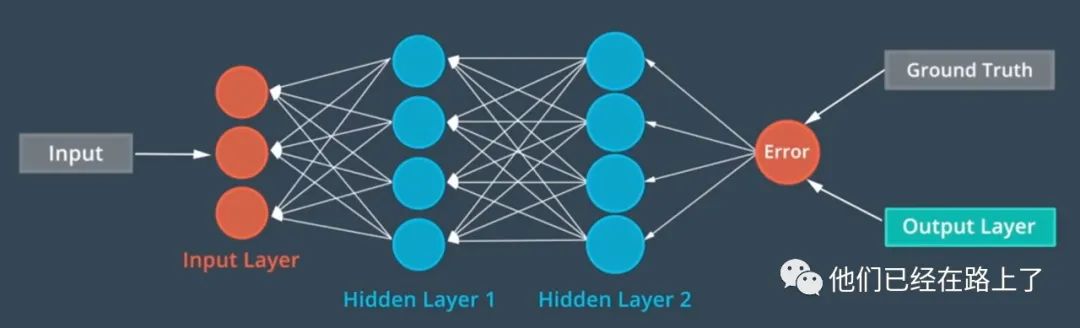
图 结果反向传播
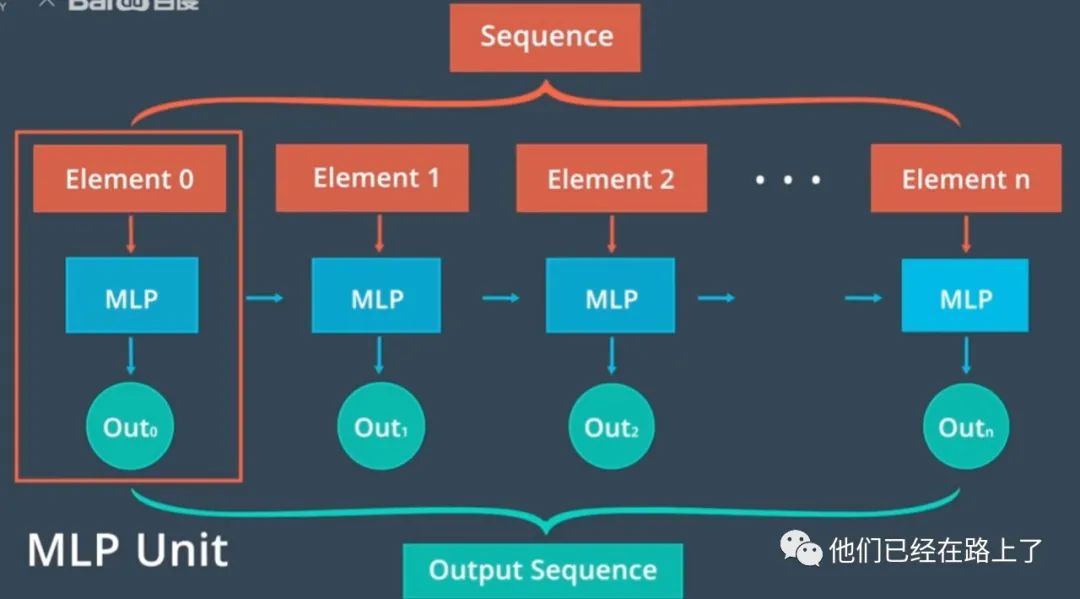
我们可以建立像这样的多重结构的递归神经网络,我们称之为MLP单元,从数据序列中提取出高级特征,每个MLP单元将序列的一个元素作为输入,并预测序列的下一个元素作为输出,为了对元素之间的顺序关系建立模型,我们在每个单元之间建立一个额外的连接,这意味着每个单元根据原始输入和前一个单元的输出进行预测,这就是RNN的基本结构。
5.递归神经网络在车道线预测的应用
我们可以使用RNN建立模型来预测车辆的目标车道,这个过程需要两个RNN模型,为车道序列提供一个RNN模型,为相关对象状态提供另一个RNN模型,连接这两个RNN的输出并将他们馈送到另一个神经网络,该神经网络会顾及每个车道序列的概率,具有最高概率的车道序列是我们预测目标车辆将遵循的序列,这个过程如下图:

为了训练这个网络,我们使用现有的记录,每条记录都包含一个车道序列、相关的对象状态和一个标签,该记录用于指示对象是否遵循此特定的车道序列,在训练中,我们比较网络输出和真值标记,并反向传播来训练网络。
6.轨迹生成
讲了这么多,最后一步就是预测的结果,输出一段轨迹。一旦我们预测到物体的车道序列,我们就可以预测物体的轨迹,在任何两个点A和B之间,物体的行驶轨迹有无限种可能:
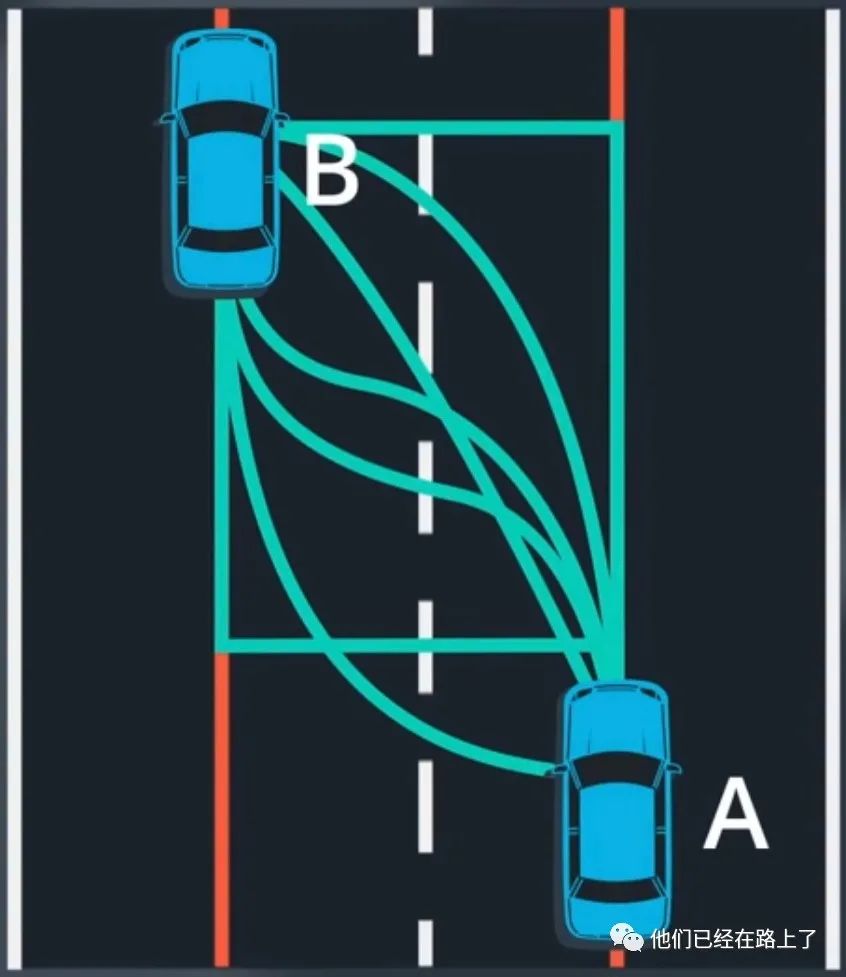
我们如何预测最有可能的轨迹,我们可以先通过设置约束条件,来去除大部分的候选轨迹。
首先,我们假设汽车将于目标车道的中心对齐,这就能轻易排除掉上图中右上角的三条路线。我们继续去去除一些车辆无法实际执行的轨迹,例如左下角的两条轨迹,我们通过车辆的当前速度和加速度,从剩下的最后两条最中间的轨迹中进行选择,这就相对容易很多了。从上图中来看,我们其实并没有列出所有可能的轨迹,相反我们只是在数学理论上来应用这个想法,注意车辆在两点的位置和方位,这两个姿势表示运动模型的初始状态和最终状态,我们可以使用这两个条件来拟合一个多项式模型,在大多数情况下,这种多项式足以进行预测。