
CK03# ClickHouse日志存储设计点梳理
最近周末比较忙,卷的有点累,上周的文章掉了链子,这周赶一篇。本文主要梳理了使用ClickHouse作为日志存储的设计点,主要内容有:
应用日志存储时长定制 ClickHouse数据的冷热存储 ClickHouse数据迁移与删除 ClickHouse查询性能调优点
公司所有的应用存储日志时长统一设置固定存储时长,比如:1个月、2个月。
这种策略也常被公司采用,优点是整体设计简单。
缺点不能满足业务需要以及可能存在成本浪费。
有的业务场景日志存储3天,例如用户推荐、行为分析等。
很多应用要求存储7天,核心链路场景却希望存储1个月。
对于逆向退货场景类的却要2个月,甚至一些特殊场景要求3个月、6个月的。
小结:也就是说根据应用设置不同的存储时长,是一个不错的方案,即能满足不同场景需求也兼顾存储成本。
用ClickHouse做日志存储,通过冷/热盘来存储数据。
热盘可以使用ESSD,存储1~3天的数据。
冷盘可以使用普通盘,存储3天以上的数据。
通过TTL或者迁移命令将热盘数据迁移到冷盘去。
下面是日志平台简要架构图示。
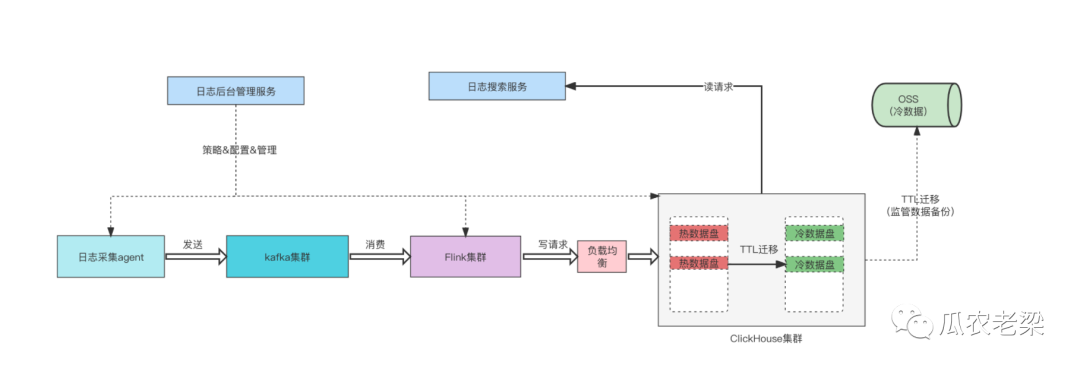
下面是ClickHouse配置冷热存储的配置。
<storage_configuration>
<disks>
<hot>
<path>/data1/clickhouse/hot/data/</path>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold>
<path>/data2/clickhouse/cold/data/</path>
</cold>
</disks>
<policies>
<ttl>
<volumes>
<hot>
<disk>hot</disk>
</hot>
<cold>
<disk>cold</disk>
</cold>
</volumes>
<move_factor>0.1</move_factor>
</ttl>
</policies>
</storage_configuration>
合并分区或者一次性写入的分区大小超过max_data_part_size_bytes,也会被写入到COLD卷中。
当存储磁盘空间小move_factor时,默认为0.1即磁盘小于10%时,数据会自动移动到下一个磁盘volume组。
也就是热盘磁盘剩余10%时,clickhouse会将热数据向冷盘迁移。
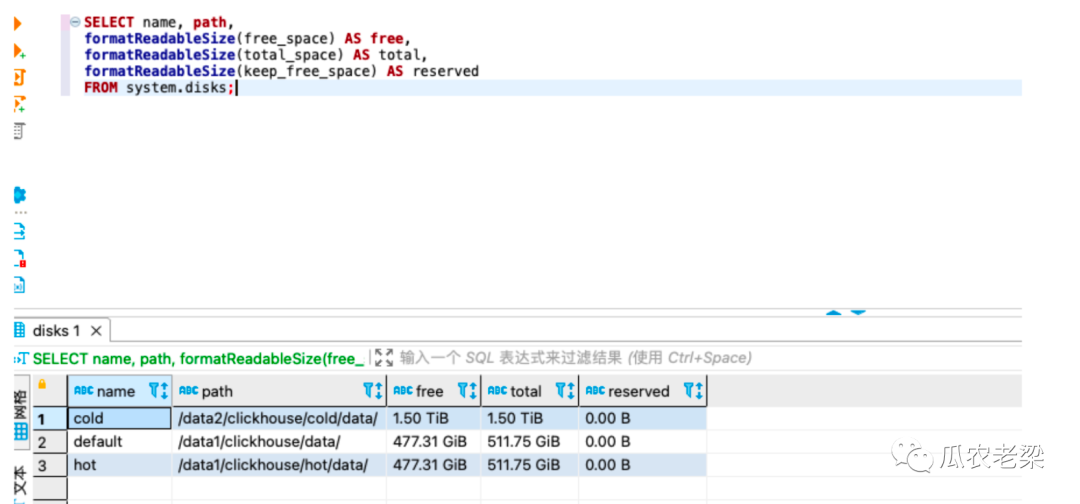
通过下面命令查看冷热存储策略以及对应的磁盘空间和剩余空间。
SELECT name, path, formatReadableSize(free_space) AS free, formatReadableSize(total_space) AS total, formatReadableSize(keep_free_space) AS reserved FROM system.disks;
运行结果图示
通过下面命令查看max_data_part_size以及move_factor的配置。
SELECT policy_name, volume_name, volume_priority, disks, formatReadableSize(max_data_part_size) AS max_data_part_size, move_factor FROM system.storage_policies;
运行结果图示

小结:通过冷热多路径存储策略,非常适合日志的场景。
尽管ClickHouse提供表级别和列级别的数据TTL迁移和数据过期策略。
然而在数据迁移和删除不可避免造成磁盘IO增加,影响集群的整体性能。
那我们在业务低峰期比如凌晨两点,定时执行指定的分区迁移,能将影响降到最小。
下面就走一把,如何通过命令来执行数据分区的迁移。
下面是查看分区所在磁盘的命令。
SELECT partition, name, disk_name FROM system.parts WHERE table='tb_logs_local';
可以看出,分区Part (000125d45a217a0d121f99b0cdfda94c_908003_1097483_4) 存储在hot磁盘中。

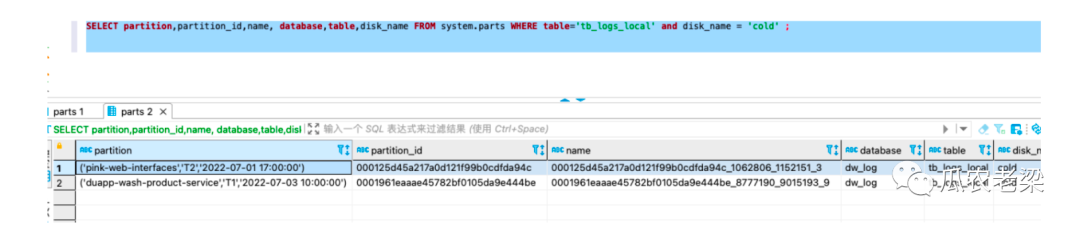
同样在system.parts还可以查询更多的信息,比如database
SELECT partition,name, database,table,disk_name FROM system.parts WHERE table='tb_logs_local';
执行结果图示

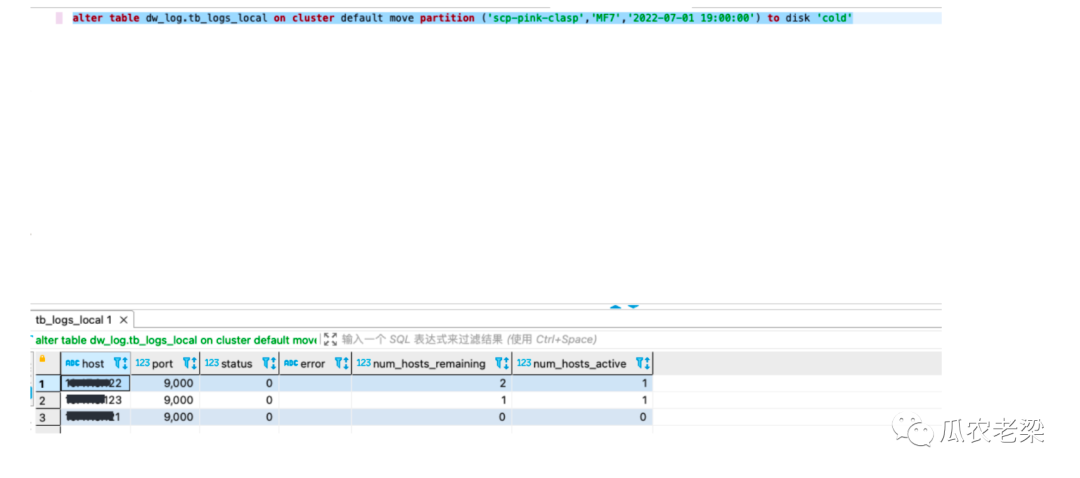
通过move命令将hot盘的分区迁移到冷盘中。
alter table dw_log.tb_logs_local on cluster default move partition ('xxx-clasp','xx','2022-07-01 19:00:00') to disk 'cold'
执行结果图示
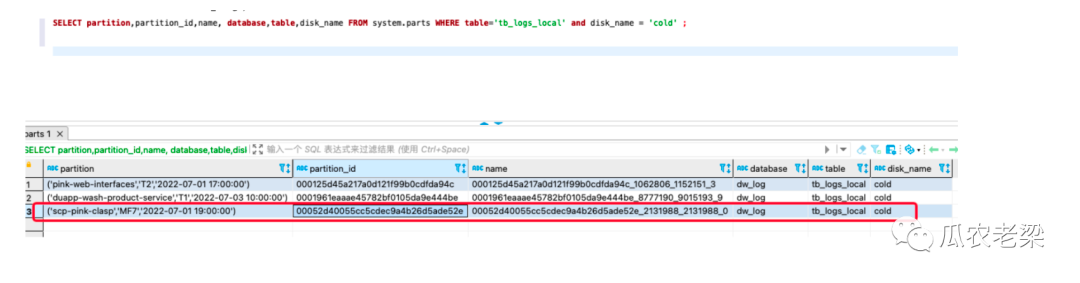
通过再次查看,该分区已被迁移到冷盘中了。
同样通过drop命令,可以将分区删除。
alter table dw_log.tb_logs_local on cluster default drop partition ('scp-pink-clasp','MF7','2022-07-01 19:00:00') ;
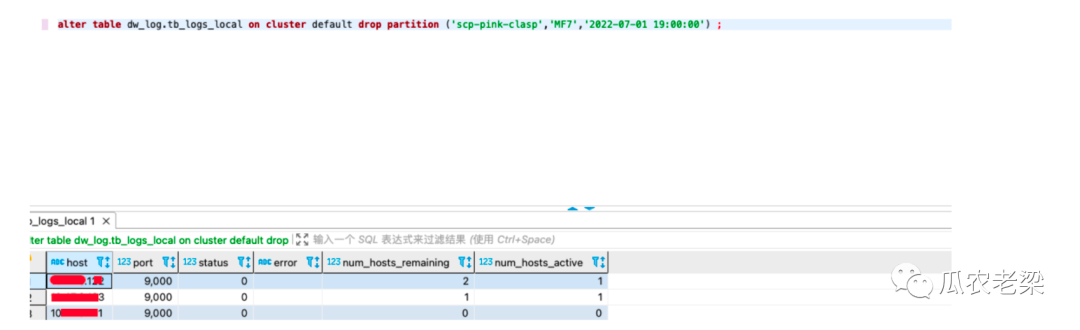
删除结果查询,该分区检索不到。
小结:在创建表时可以设置应用名称、日期为分区键,在system.parts有详细的应用以及创建日期,进而通过move/drop命令执行分区的转移和删除。
如何提高ClickHouse的查询性能?
优化方向一,一个超大集群切分两个中等规模集群。
优化方向二,通过对表字段设置合理的索引。
一级索引,通常primary key与order by定义相同。
MergeTree会根据index_granularity间隔为数据表生成一级索引保存在primary.idx文件中。
index_granularity默认8192行,也就是使用的是稀疏索引。
也就是数据被分割为 n=数据总行数/index_granularity 个区间,每一个区间一个索引。
二级索引又称跳数索引,主要有minmax、set、ngrambf_v1和tokenbf_v1四种类型。
二级索引共同参数granularity,指跳过几个区间再生成一条索引。
具体跳数索引的含义以及原理,再起一篇梳理。
下面是一个测试样例。
CREATE TABLE logs_demo
(
`application` String,
`environment` String,
`ip` String,
`filename` String,
`keys` Array(Nullable(String)) CODEC(ZSTD(1)),
`values_string` Array(Nullable(String)) CODEC(ZSTD(1)),
`values_number` Array(Nullable(Float64)) CODEC(ZSTD(1)),
`file_offset` Nullable(UInt32),
`message` String CODEC(ZSTD(1)),
`log_type` String,
`log_time` DateTime64(3),
INDEX environment environment TYPE SET(100) GRANULARITY 2,
INDEX message message TYPE tokenbf_v1(32768,
2,
0) GRANULARITY 2
)
ENGINE = MergeTree
PARTITION BY (application,
toStartOfHour(log_time))
ORDER BY (environment,
log_time,
ip,
file_offset)
SETTINGS allow_nullable_key = 1,
storage_policy = 'ttl',
index_granularity = 8192;
其中environment使用SET类型的跳数索引。
message使用了布隆过滤器tokenbf_v1类型的跳数索引。
小结:总之可通过调整跳数索引与集群规模来优化查询查询性能。