
基于机器视觉的缺陷检测的原理与方法
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
基于统计分类的方法:
(1)基于KNN方法(最近邻法):利用相似度,找出k个训练样本,然后打分,按得分值排序。
(2)基于Naive Bayes算法:计算概率,构建分类模型。
引导:
医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
一、KNN分类器
1.1.1最近邻算法
定义:计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本类别的唯一依据。
缺陷:对噪声数据过于敏感。
措施:将被决策样本周边的多个最近样本计算在内,扩大参与决策的样本量,以避免个别数据直接决定决策结果。
1.1.2K-最近邻算法(KNN)
基本思路:选择未知样本一定范围内的K个样本,该K个样本中某一类型出现的次数最大,则未知样本判定为该类型。
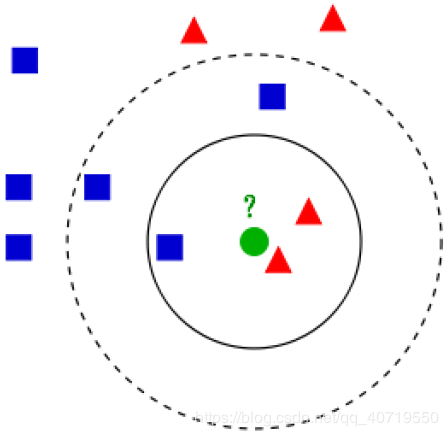
举例说明:
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
算法执行步骤:
(1)输入测试集。
(2)设定参数k。
(3)遍历测试集,对于测试集中每个样本,计算该样本(测试集中)到训练集中每个样本的距离;取出训练集中到该样本(测试集中)的距离最小的k个样本的类别标签;对类别标签进行计数,类别标签次数最多的就是该样本(测试集中)的类别标签。
(4)遍历完毕,输出测试集的类别。
1.1.3 知识补充
距离度量表示的是两样本之间的相似程度。
常用距离度量方式:
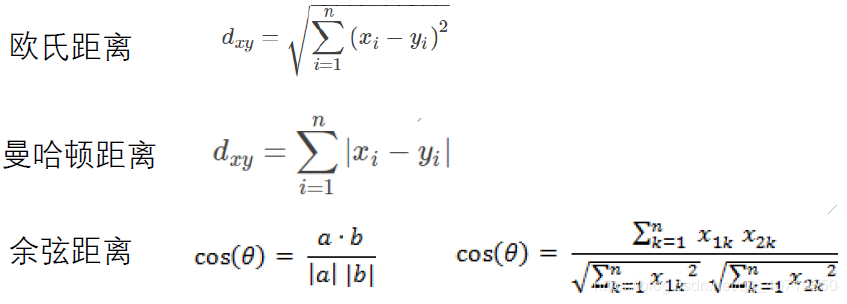
二、朴素贝叶斯分类器
2.1贝叶斯公式
贝叶斯公式理解
(怎样用非数学语言讲解贝叶斯定理(Bayes’s theorem)?)
2.2朴素贝叶斯分类器
2.2.1基本思想
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。

2.2.2朴素贝叶斯“公式”

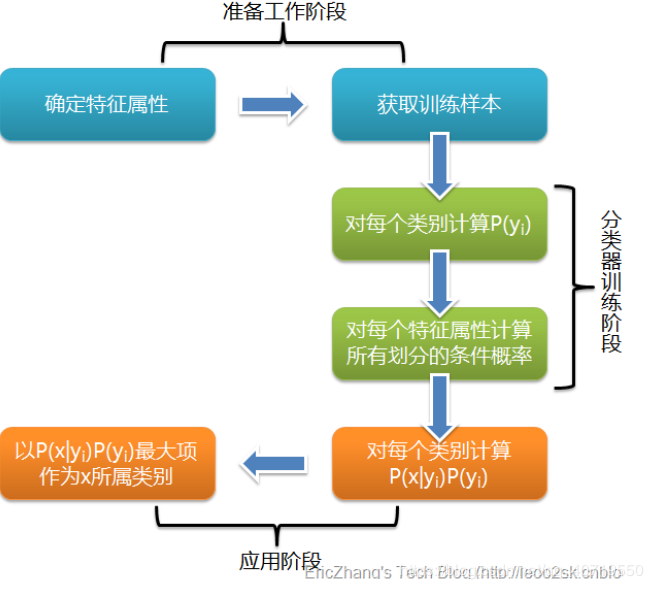
2.2.3朴素贝叶斯分类器

三、瑕疵缺陷检测
检测方法:
(1)瑕疵缺陷图像特征的选择与提取。
(2)计算缺陷图像与标准图像关于灰度的差值。
(3)通过差值与设定阈值比较判断是否存在缺陷。
3.1缺陷图像差分法
3.1.1基本原理

3.1.2基本流程
(1)有效检测区域的设定
(2)图像配准与剪裁
(3)设定差分阈值
(4)缺陷位置的判别
3.2缺陷图像特征的选择与提取
3.2.1特征提取方法
(1)灰度值特征
(2)灰度差特征
(3)直方图特征
(4)变换系数特征
(5)线条和角点的特征
(5)灰度边缘特征
(6)纹理特征
3.2.2特征选择(数据降维)
降维的原因:在机器学习中,如果特征值即维度过多,会引发维度灾难。维度灾难最直接的后果就是过拟合现象,进而导致分类识别的错误,因此我们需要对所提的特征进行降维处理。
基本原理:特征选择是将原始空间进行变换,重新生成一个维数更小各维之间更独立的特征空间。
降维面临的问题:
(1)降维后数据应该包含更多的信息?
(2)降维后会损失多少信息?
(3)降维后对分类识别效果有多大影响?
数据降维后的好处:
(1)进行数据压缩,减少数据存储所需空间以及计算所需时间。
(2)消除数据间的冗余,以简化数据,提高计算效率。
(3)去除噪声,提高模型性能。
(4)改善数据的可理解性,提高学习算法的精度。
(5)将数据维度减少到2维或者3维,进行可视化。
常用方法:主成分分析,随机映射,非负矩阵分解。
3.2.3主成分分析(PCA)
方法概述:此方法目标是找到数据中最主要的元素和结构,去除噪音冗余,将原有的复杂数据降维,揭露出隐藏在复杂数据背后的简单结构。主成分分析就是试图在力保数据信息丢失最少的原则下,对这种多变量的数据表进行最佳综合简化。这些综合指标就称为主成分,也就是说,对高维变量空间进行降维处理,很显然,识辨系统在一个低维空间要比在一个高维空间容易得多。从线性代数角度来看,PCA目标是找到一组新正交基去重新描述得到的数据空间,这个维度就是主元。
3.3灰度形态学的缺陷检测
3.3.1概述
灰度数学形态学的基本运算有膨胀、腐独、开启和关闭,其中利用膨胀和腐蚀的组合可构成开启和关闭,而利用开启和关闭又可构成形态滤波器。
在灰度图像的形态分析中,结构元素可以是何的三维结构,常用的有圆锥、圆柱、半球或抛物线。模板尺寸总是奇数,这样檬板中心正好对应一个像素。
3.3.2 形态操作对图像影响
(1)膨胀灰度图像的结果是,比背景亮的部分得到扩张,而比背景暗的部分受到收缩。
(2)腐蚀灰度图像的结果是,比背景暗的部分得到扩张,而比背景亮的部分受到收缩。
(3)开启一幅图像可消除图中的孤岛或尖峰等过亮的点。
(4)关闭一幅图可将比背景暗且尺寸比结构元素小的结构除掉。
(5)形态滤波器是非线性信号滤波器,它通过变换来局部地修改信号的几何特征。将开运算和闭运算结合起来可消除噪声。
(6)如果用一个小的结构元素先开启再闭合一幅图像,就有可能将图像中小于结构元素的类似噪声结构除去。
3.3.3实例说明
电路板布线的缺陷检测:对于一幅大小为1100×870、灰度级为256的电路板灰度图像,其布线缺陷分为断线和毛刺,利用灰度形态学检测这些缺陷。取结构元素为5×5的半球模板,首先对原图灰度开启,消除比邻域亮且尺寸比结构元素小的区域;然后对原图灰度闭合,消除比邻域暗且尺寸比结构元素小的区域,两次结果差异即为缺陷。

四、划痕检查
概述:划痕检测的基本分析过程分为两步首张,确定检测产品表面是否有划痕,其次,在确定被分析图像上存在划痕之后,对划痕进行提取。由于在工业检测中图像的多样性,对于每一种圈像,都要经过分析综合考虑各种手段来进行处理达到效果。一般来说,划痕部分的灰度值和周围正常部分相比要暗,也就是划痕部分灰度值偏小,而且大多都是在光滑表面,所以整幅图的灰度变化总体来说非常均匀,缺乏纹理特征。
基本方法:基于统计的灰度特征或者阈值分割的方法将划痕部分标出。
版权声明:本文为CSDN博主「橡皮人生」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40719550/java/article/details/84030419
本文仅做学术分享,如有侵权,请联系删文。