
微信从 0 到 1

这本书市面上暂时没有销售,龙哥只发行了几千本在圈内流通,未来会不会发行出来也不好说。
书小林还没看完,以后有时间跟大家分享下这本书的读书心得。
虽然小林是个开发者,但是对微信的产品观还是很有兴趣的,好奇龙哥设计的每一个功能背后是如何思考的。
一个东西从 0 到 1,我们要学习的不是最后的结果,而是学习是大佬们是经历过怎样的思考、抉择才做出来的,这份思考或许有助于我们应对自己的问题。
就好像前段时间小米的新 LOGO,经过大师之手感觉好像是没什么变化,从结果看只是正方形变成稍微椭圆的形状,但是大师为什么只变化这么一点,以及背后的设计理念,都是值得我们思考和学习的,换做是你,你又会如何设计?
微信从 2011 年至今,短短十年的时间,已经成为国民级别的 APP,每天面对每天的几亿,甚至几十亿的并发,作为开发者的我们,肯定相当好奇,微信的架构是怎么样?
这次就给大家介绍下,微信最早期后台的架构是如何从 0 到 1。
2 个月的开发时间,微信后台系统经历了从 0 到 1 的过程。
从小步慢跑到快速成长,经历了平台化到走出国门,微信交出的这份优异答卷,解题思路是怎样的?
阶段一:从无到有
2011.1.21 微信正式发布。这一天距离微信项目启动日约为 2 个月。
就在这 2 个月里,微信从无到有,大家可能会好奇这期间微信后台做的最重要的事情是什么?
我想应该是以下三件事:
1. 确定了微信的消息模型
微信起初定位是一个通讯工具,作为通讯工具最核心的功能是收发消息。
微信团队源于广硏团队,消息模型跟邮箱的邮件模型也很有渊源,都是存储转发。

上图展示了这一消息模型,消息被发出后,会先在后台临时存储;
为使接收者能更快接收到消息,会推送消息通知给接收者;
最后客户端主动到服务器收取消息。
2. 制定了数据同步协议
由于用户的帐户、联系人和消息等数据都在服务器存储,如何将数据同步到客户端就成了很关键的问题。
为简化协议,我们决定通过一个统一的数据同步协议来同步用户所有的基础数据。
最初的方案是客户端记录一个本地数据的快照(Snapshot),需要同步数据时,将 Snapshot 带到服务器,服务器通过计算 Snapshot 与服务器数据的差异,将差异数据发给客户端,客户端再保存差异数据完成同步。
不过这个方案有两个问题:
一是 Snapshot 会随着客户端数据的增多变得越来越大,同步时流量开销大;
二是客户端每次同步都要计算 Snapshot,会带来额外的性能开销和实现复杂度。
几经讨论后,方案改为由服务计算 Snapshot,在客户端同步数据时跟随数据一起下发给客户端,客户端无需理解 Snapshot,只需存储起来,在下次数据同步数据时带上即可。
同时,Snapshot被设计得非常精简,是若干个 Key-Value 的组合,Key 代表数据的类型,Value 代表给到客户端的数据的最新版本号。
Key 有三个,分别代表:帐户数据、联系人和消息。
这个同步协议的一个额外好处是客户端同步完数据后,不需要额外的ACK协议来确认数据收取成功,同样可以保证不会丢数据:
只要客户端拿最新的Snapshot到服务器做数据同步,服务器即可确认上次数据已经成功同步完成,可以执行后续操作。
例如清除暂存在服务的消息等等。
此后,精简方案、减少流量开销、尽量由服务器完成较复杂的业务逻辑、降低客户端实现的复杂度就作为重要的指导原则,持续影响着后续的微信设计开发。
记得有个比较经典的案例是:我们在微信 1.2 版实现了群聊功能,但为了保证新旧版客户端间的群聊体验,我们通过服务器适配,让 1.0 版客户端也能参与群聊。
3. 定型了后台架构
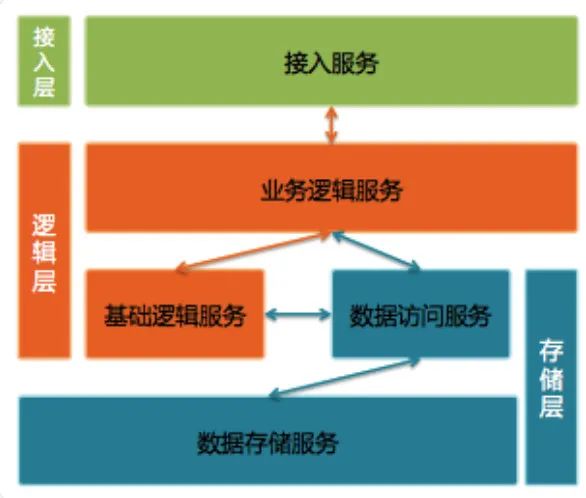
微信后台使用三层架构:接入层、逻辑层和存储层
接入层提供接入服务,包括长连接入服务和短连接入服务。
长连接入服务同时支持客户端主动发起请求和服务器主动发起推送;
短连接入服务则只支持客户端主动发起请求。
逻辑层包括业务逻辑服务和基础逻辑服务。
业务逻辑服务封装了业务逻辑,是后台提供给微信客户端调用的API。
基础逻辑服务则抽象了更底层和通用的业务逻辑,提供给业务逻辑服务访问。
存储层包括数据访问服务和数据存储服务。
数据存储服务通过 MySQL 和 SDB(广硏早期后台中广泛使用的 Key-Table 数据存储系统)等底层存储系统来持久化用户数据。
数据访问服务适配并路由数据访问请求到不同的底层数据存储服务,面向逻辑层提供结构化的数据服务。
比较特别的是,微信后台每一种不同类型的数据都使用单独的数据访问服务和数据存储服务,例如帐户、消息和联系人等等都是独立的。
微信后台主要使用 C++。后台服务使用 Svrkit 框架搭建,服务之间通过同步 RPC 进行通讯。
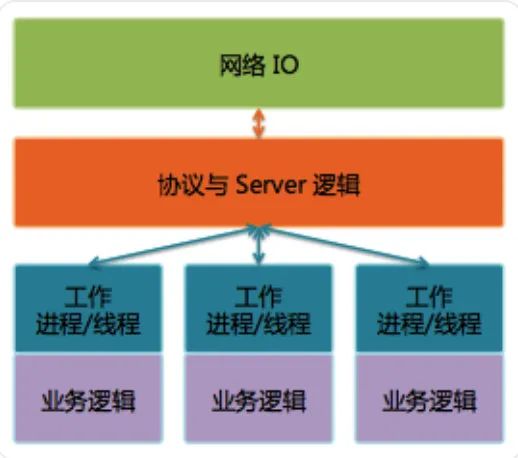
Svrkit 是另一个广硏后台就已经存在的高性能 RPC 框架,当时尚未广泛使用,但在微信后台却大放异彩。
作为微信后台基础设施中最重要的一部分,Svrkit 这几年一直不断在进化。我们使用 Svrkit 构建了数以千计的服务模块,提供数万个服务接口,每天 RPC 调用次数达几十万亿次。
这三件事影响深远,乃至于 5 年后的今天,我们仍继续沿用最初的架构和协议,甚至还可以支持当初 1.0 版的微信客户端。
这里有一个经验教训——运营支撑系统真的很重要。第一个版本的微信后台是仓促完成的,当时只是完成了基础业务功能,并没有配套的业务数据统计等等。
我们在开放注册后,一时间竟没有业务监控页面和数据曲线可以看。
注册用户数是临时从数据库统计的,在线数是从日志里提取出来的,这些数据通过每个小时运行一次的脚本(这个脚本也是当天临时加的)统计出来,然后自动发邮件到邮件组。
还有其他各种业务数据也通过邮件进行发布,可以说邮件是微信初期最重要的数据门户。
2011.1.21 当天最高并发在线数是 491,而今天这个数字是 4 亿。
阶段二:小步慢跑
在微信发布后的4个多月里,我们经历了发布后火爆注册的惊喜,也经历了随后一直不温不火的困惑。
这一时期,微信做了很多旨在增加用户好友量,让用户聊得起来的功能。
打通腾讯微博私信、群聊、工作邮箱、QQ/邮箱好友推荐等等。
对于后台而言,比较重要的变化就是这些功能催生了对异步队列的需求。
例如,微博私信需要跟外部门对接,不同系统间的处理耗时和速度不一样,可以通过队列进行缓冲;
群聊是耗时操作,消息发到群后,可以通过异步队列来异步完成消息的扩散写等等。
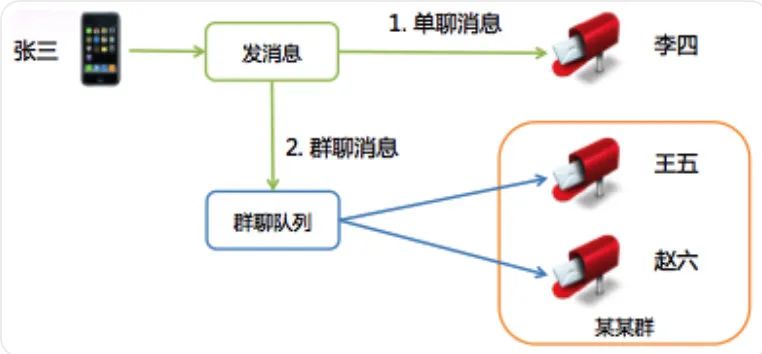
这是异步队列在群聊中的应用。微信的群聊是写扩散的,也就是说发到群里的一条消息会给群里的每个人都存一份(消息索引)。
微信的群聊为什么不是读扩散呢?
有两个原因:
群的人数不多,群人数上限是 10(后来逐步加到 20、40、100,目前是 500),扩散的成本不是太大,不像微博,有成千上万的粉丝,发一条微博后,每粉丝都存一份的话,一个是效率太低,另一个存储量也会大很多;
消息扩散写到每个人的消息存储(消息收件箱)后,接收者到后台同步数据时,只需要检查自己收件箱即可,同步逻辑跟单聊消息是一致的,这样可以统一数据同步流程,实现起来也会很轻量。
异步队列作为后台数据交互的一种重要模式,成为了同步RPC服务调用之外的有力补充,在微信后台被大量使用。
KVSvr
微信后台每个存储服务都有自己独立的存储模块,是相互独立的。
每个存储服务都有一个业务访问模块和一个底层存储模块组成。
业务访问层隔离业务逻辑层和底层存储,提供基于RPC的数据访问接口;底层存储有两类:
SDB
MySQL
SDB 适用于以用户 UIN(uint32_t) 为 Key 的数据存储,比方说消息索引和联系人。
优点是性能高,在可靠性上,提供基于异步流水同步的 Master-Slave 模式,Master 故障时,Slave 可以提供读数据服务,无法写入新数据。
由于微信账号为字母+数字组合,无法直接作为 SDB 的 Key,所以微信帐号数据并非使用 SDB,而是用 MySQL 存储的。
MySQL 也使用基于异步流水复制的 Master-Slave 模式。
第 1 版的帐号存储服务使用 Master-Slave 各1台。
Master 提供读写功能,Slave 不提供服务,仅用于备份。
当 Master 有故障时,人工切读服务到 Slave,无法提供写服务。
为提升访问效率,我们还在业务访问模块中加入了 memcached 提供 Cache 服务,减少对底层存储访问。
第 2 版的帐号存储服务还是 Master-Slave各1台,区别是Slave可以提供读服务,但有可能读到脏数据,因此对一致性要求高的业务逻辑,例如注册和登录逻辑只允许访问Master。
当 Master有故障时,同样只能提供读服务,无法提供写服务。
第 3 版的帐号存储服务采用1个 Master 和多个 Slave,解决了读服务的水平扩展能力。
第 4 版的帐号服务底层存储采用多个 Master-Slave 组,每组由1个 Master 和多个 Slave 组成,解决了写服务能力不足时的水平扩展能力。
最后还有个未解决的问题:单个 Master-Slave 分组中,Master 还是单点,无法提供实时的写容灾,也就意味着无法消除单点故障。
另外 Master-Slave 的流水同步延时对读服务有很大影响,流水出现较大延时会导致业务故障。
于是我们寻求一个可以提供高性能、具备读写水平扩展、没有单点故障、可同时具备读写容灾能力、能提供强一致性保证的底层存储解决方案,最终 KVSvr 应运而生。
KVSvr 使用基于 Quorum 的分布式数据强一致性算法,提供 Key-Value/Key-Table 模型的存储服务。
传统 Quorum 算法的性能不高,KVSvr 创造性地将数据的版本和数据本身做了区分。
将 Quorum 算法应用到数据的版本的协商,再通过基于流水同步的异步数据复制提供了数据强一致性保证和极高的数据写入性能。
另外 KVSvr 天然具备数据的 Cache 能力,可以提供高效的读取性能。
KVSvr 一举解决了我们当时迫切需要的无单点故障的容灾能力。
除了第 5 版的帐号服务外,很快所有 SDB 底层存储模块和大部分MySQL 底层存储模块都切换到 KVSvr。
随着业务的发展,KVSvr 也不断在进化着,还配合业务需要衍生出了各种定制版本。
现在的 KVSvr 仍然作为核心存储,发挥着举足轻重的作用。
你好,我是公子龙,毕业于中科院,前大型计算机竞赛冠军,现算法工程师,拿过九家大厂的 offer 。
北漂七年,从小白到计算机竞赛冠军,读研时通过实习和比赛收入 50 万,点击蓝字查看我的编程之路。
