
一天star量破千,300行代码,特斯拉AI总监Karpathy写了个GPT的Pytorch训练库
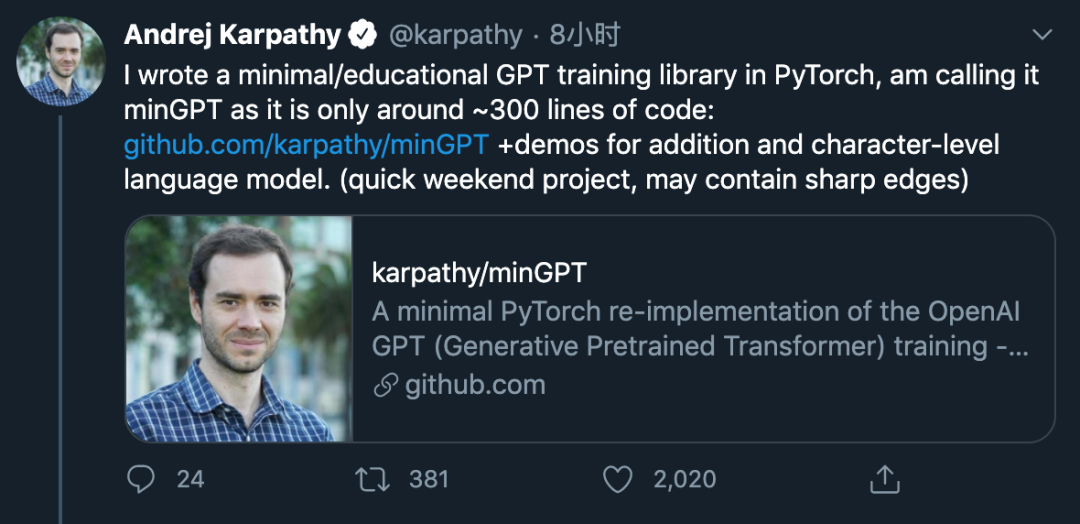
Karpathy 表示,这个 minGPT 能够进行加法运算和字符级的语言建模,而且准确率还不错。
不过,在运行 demo 后,Andrej Karpathy 发现了一个有趣的现象:2 层 4 注意力头 128 层的 GPT 在两位数加法运算中,将 55 + 45 的结果计算为 90,而其他加法运算则没有问题。

目前,该项目在 GitHub 上亮相还没满 24 小时,但 star 量已经破千。
minGPT 项目地址:
https://github.com/karpathy/minGPT

GPT 并非一个复杂的模型,minGPT 实现只有大约 300 行代码,包括样板文件和一个完全不必要的自定义因果自注意力模块。
Karpathy 将索引序列变成了一个 transformer 块序列,如此一来,下一个索引的概率分布就出现了。剩下的复杂部分就是巧妙地处理 batching,使训练更加高效。
核心的 minGPT 库包含两个文档:mingpt/model.py 和 mingpt/trainer.py。
前者包含实际的 Transformer 模型定义,后者是一个与 GPT 无关的 PyTorch 样板文件,可用于训练该模型。相关的 Jupyter notebook 则展示了如何使用该库训练序列模型:
play_math.ipynb 训练一个专注于加法的 GPT;
play_char.ipynb 将 GPT 训练成一个可基于任意文本使用的字符级语言模型,类似于之前的 char-rnn,但用 transformer 代替了 RNN;
play_words.ipynb 是 BPE(Byte-Pair Encoding)版本,目前尚未完成。
OpenAI gpt-2 项目提供了模型,但没有提供训练代码(https://github.com/openai/gpt-2);
OpenAI 的 image-gpt 库在其代码中进行了一些类似于 GPT-3 的更改,是一份不错的参考(https://github.com/openai/image-gpt);
Huggingface 的 transformers 项目提供了一个语言建模示例。它功能齐全,但跟踪起来有点困难。(https://github.com/huggingface/transformers/tree/master/examples/language-modeling)
论文地址:
https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf

论文地址:
https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
GPT-2 将 LayerNorm 移动每个子模块的输入,类似于预激活残差网络,并在最后的自注意力模块后添加了一个额外的层归一化。
此外,该模型还更改了模型初始化(包括残差层初始化权重等)、扩展了词汇量、将 context 规模从 512 个 token 增加到 1024、使用更大的批大小等。具体实现细节参见下图:

论文地址:https://arxiv.org/pdf/2005.14165.pdf


2016 年,Karpathy 加入 OpenAI 担任研究科学家。2017 年,他加入特斯拉担任人工智能与自动驾驶视觉总监。如今,Karpathy 已经升任特斯拉 AI 高级总监。
他所在的团队负责特斯拉自动驾驶系统 Autopilot 所有神经网络的设计,包括数据收集、神经网络训练及其在特斯拉定制芯片上的部署。



参考链接:
https://news.ycombinator.com/item?id=24189497
戳↓↓“阅读原文”小七送你AI大礼包哦!