
【死磕NIO】— 阻塞IO,非阻塞IO,IO复用,信号驱动IO,异步IO,这你真的分的清楚吗?
通过上篇文章(【死磕NIO】— 阻塞、非阻塞、同步、异步,傻傻分不清楚),我想你应该能够区分了什么是阻塞、非阻塞、异步、非异步了,这篇文章我们来彻底弄清楚什么是阻塞IO,非阻塞IO,IO复用,信号驱动IO,异步IO。
要想彻底弄清楚这五种IO模型,我们需要先弄清楚几个基本概念。
基本概念
什么是IO
什么是IO?维基百科上面是这样解释的:
I/O(英语:Input/Output),即输入/输出,通常指数据在存储器(内部和外部)或其他周边设备之间的输入和输出,是信息处理系统(例如计算机)与外部世界(可能是人类或另一信息处理系统)之间的通信。输入是系统接收的信号或数据,输出则是从其发送的信号或数据。
这是IO一个完整的定义,不是特别好理解,要厘清IO这个概念,我们需要从如下两个视角来理解它。
计算机视角理解IO
冯•诺伊曼计算机的基本思想中有提到计算机硬件组成应为五大部分:控制器,运算器,存储器,输入和输出。其中输入是指将数据输入到计算机的设备,输出是指从计算机中获取数据的设备。对于计算机而言,任何涉及到计算机核心(CPU和内存)与其他设备间的数据转移的过程就是IO。
IO 对于计算机而言,有两层意思:
IO 设备。比如我们最常见的打印机、鼠标、键盘 对IO设备的数据读写
程序视角理解IO
程序视角我们关注的则是应用程序本身。我们知道应用程序只有加载到内存中作为一个进程才能运行,它需要时刻与计算机进行数据交换,比如读写磁盘、远程调用、访问内存等等,但是操作系统为了能够正常平稳地运行下去,它是不会运行应用程序随意访问计算机硬件部分,如内存、硬盘、网卡,应用程序必须通过操作系统提供的API来访问,以达到安全的访问控制。所以应用程序如果要访问内核管理的IO,则必须通过有操作系统提供的API来间接访问。所以 IO对应应用程序而言,强调的则是 通过向内核发起系统调用完成对I/O的间接访问。
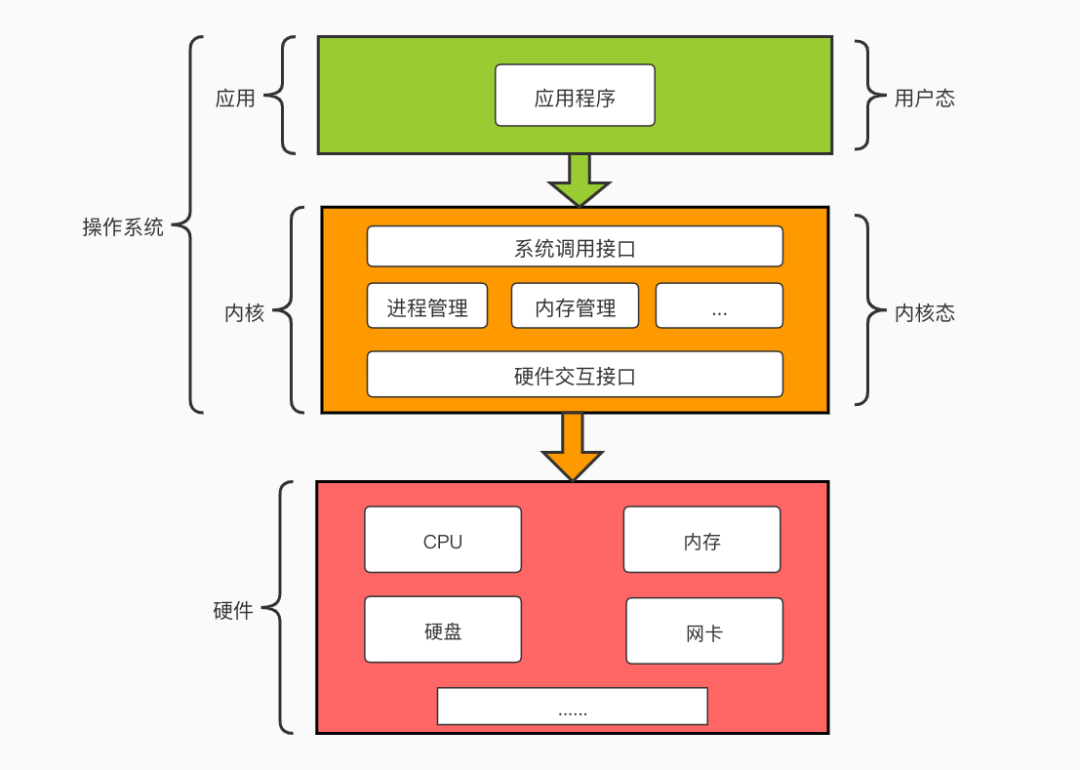
所以,换句话说应用程序发起一次IO访问是分为两个阶段的:
IO 调用阶段:应用程序向内核发起系统调用。 IO执行阶段:内核执行IO操作并返回。 数据准备阶段:内核等待IO设备准备好数据 数据拷贝阶段:将数据从内核缓冲区拷贝到用户空间缓冲区
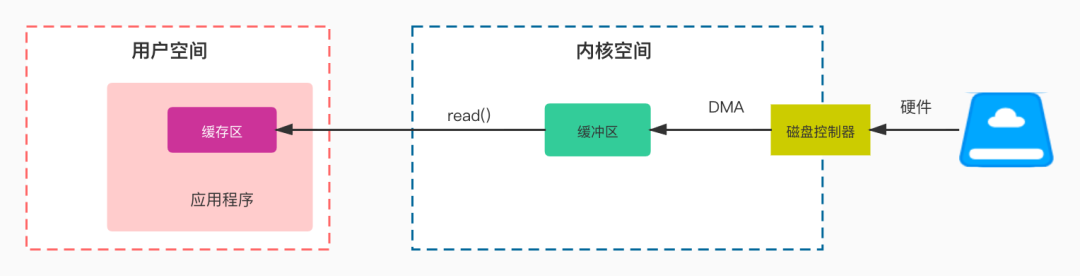
用户空间&内核空间
操作系统是利用CPU 指令来计算和控制计算机系统的,有些指令很温和,我们操作它不会对操作系统产生什么危害,而有些指令则非常危险,如果使用不当则会导致系统崩溃,如果操作系统允许所有的应用程序能够直接访问这些很危险的指令,这会让计算机大大增加崩溃的概率。所以操作系统为了更加地保护自己,则将这些危险的指令保护起来,不允许应用程序直接访问。
现代操作系统都是采用虚拟存储器,操作系统为了保护危险指令被应用程序直接访问,则将虚拟空间划分为内核空间和用户空间。
内核空间则是操作系统的核心,它提供操作系统的最基本的功能,是操作系统工作的基础,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。 用户空间,非内核应用程序则运行在用户空间。用户空间中的代码运行在较低的特权级别上,只能看到允许它们使用的部分系统资源,并且不能使用某些特定的系统功能,也不能直接访问内核空间和硬件设备,以及其他一些具体的使用限制。
进行空间划分后,用户空间通过操作系统提供的API间接访问操作系统的内核,提高了操作系统的稳定性和可用性。
想要详细了解Linux 内核空间和用户空间,则可以关注如下两篇文章:
https://cloud.tencent.com/developer/article/1739264 https://developer.aliyun.com/article/297062
用户态和内核态进程切换
内核态: CPU可以访问内存所有数据, 包括外围设备, 例如硬盘,、网卡,CPU也可以将自己从一个程序切换到另一个程序。 用户态: 只能受限的访问内存, 且不允许访问外围设备。占用CPU的能力被剥夺, CPU资源可以被其他程序获取。
我们知道CPU为了保护操作系统,将空间划分为内核空间和用户空间,进程既可以在内核空间运行,也可以在用户空间运行。当进程运行在内核空间时,它就处在内核态,当进程运行在用户空间时,他就是用户态。开始所有应用程序都是运行在用户空间的,这个时候它是用户态,但是它想做一些只有内核空间才能做的事情,如读取IO,这个时候进程需要通过系统调用来访问内核空间,进程则需要从用户态转变为内核态。
用户态和内核态之间的切换开销有点儿大,那它开销在哪里呢?有如下几点:
保留用户态现场(上下文、寄存器、用户栈等) 复制用户态参数,用户栈切到内核栈,进入内核态 额外的检查(因为内核代码对用户不信任) 执行内核态代码 复制内核态代码执行结果,回到用户态 恢复用户态现场(上下文、寄存器、用户栈等)
所以,频繁的IO操作会频繁的造成用户态 —> 内核态 —> 用户态的切换,这严重会影响系统性能。后面小编会介绍IO的一些优化,重点就是减少切换。
好了,就到这里了,想要详细了解用户态和内核态,可以关注如下两篇文章:
https://www.cnblogs.com/shangxiaofei/p/5567776.html https://juejin.cn/post/6920621924791894023
五种IO模型
《UNIX网络编程》说得很清楚,5种IO模型分别是 阻塞IO模型、 非阻塞IO模型、 IO复用模型、 信号驱动IO模型、 异步IO模型。前4种为同步IO操作,只有异步IO模型是异步IO操作。
这里小编问个问题,为什么前四种是同步,而只有异步IO模型才是异步呢?
阻塞IO模型
阻塞IO模型是最常见最简单的IO模型,图如下:
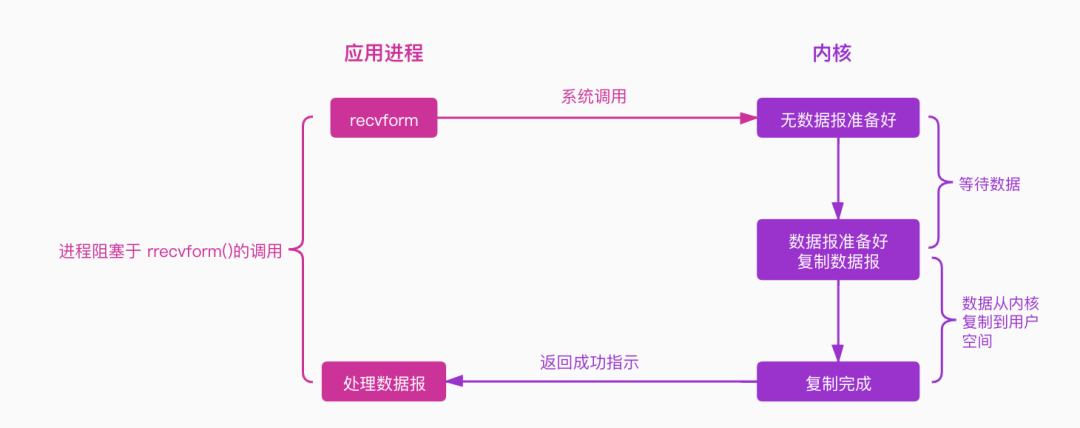
应用程序发起一个系统调用(recvform),这个时候应用程序会一直阻塞下去,直到内核把数据准备好,并将其从内核复制到用户空间,复制完成后返回成功提示,这个时候应用程序才会继续处理数据。
所以,阻塞IO模型在IO两个阶段都会阻塞。
优点 模型简单,实现难度低 适用于并发量较小的应用开发 缺点 整个过程都阻塞,进程一直挂起,程序性能较为低,不适用并发大的应用
场景
某天,你跟你女朋友(假如你有女朋友)去饭店吃饭,点完餐后,你就做坐那里一直等菜做好后,吃饱喝足才离开。这期间你和你女朋友由于担心不知道菜什么时候才能做好,所以这个期间你们就只能一直在座位上面等着,什么时候也不能干。
非阻塞 IO模型
非阻塞IO模型图例如下:
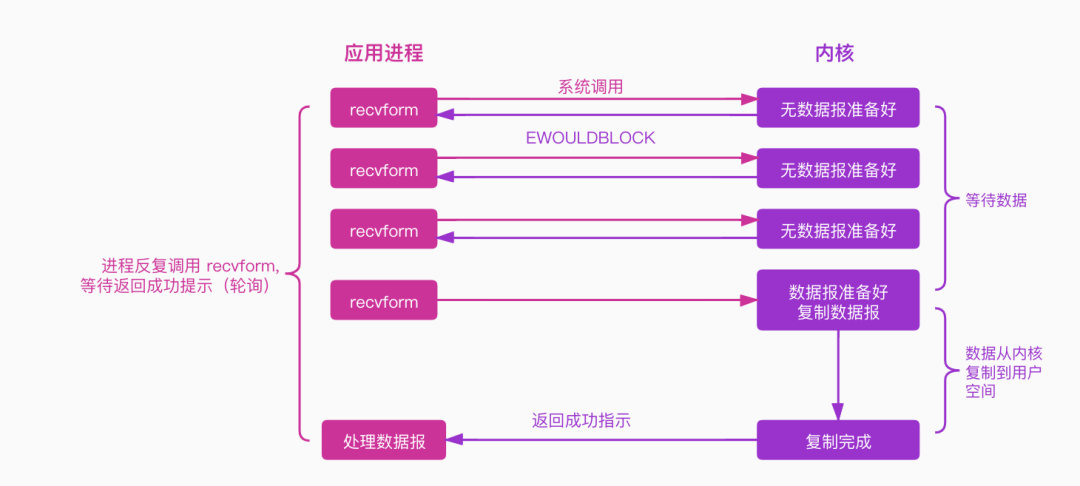
应用程序发起recvform系统调用,如果数据报没有准备会则会立即返回一个EWOULDBLOCK错误码,进程并不需要进行等待。进程收到该错误后,判断内核数据还没有准备好,它还可以继续发送 recvform,如果数据报已经准备好了,待数据从内核拷贝到用户空间返回成功指示后,进程则可以处理数据报了,
所以, 非阻塞IO模型需要应用进程不断地主动询问内核数据是否已准备好了。
优点 模型简单,实现难度低 与阻塞IO模型对比,它在等待数据报的过程中,进程并没有阻塞,它可以做其他的事情 缺点 轮询发送 recvform ,消耗CPU 资源 与阻塞IO模型一样,它也不适用于并发量大的应用程序
场景
一个星期后,你跟你女朋友还是去那家餐厅吃饭,点完菜后,你女朋友吸取上次教训,知道要在这里干等,所以还不如去逛逛,买点香水口红啥的。但是呢,由于你们担心会错过上菜,所以你们就每隔一段时间就来问下服务员,你们的菜准备好了没有,来来回回好多回,若干次后,终于问到菜已经准备好了,然后你们就开心的吃起来。
IO复用模型
基于非阻塞IO模型,我们知道,它需要进程不断地轮询发起recvform系统调用,在整个过程中,轮询会占据很大一部分过程,而且不断轮询是很消耗CPU的。而且我们又不是只有一个进程在这里发起recvform系统低调用,有可能是几万几十万个。
我们可以想象这样一个场景,你是喜茶服务员,每个人点好奶茶后,都会过来问你他的奶茶好了没有,三五个人你顶得住,那几十上百个人呢?而且他们又不是只问一次,而是每隔几分钟就来问你一次,就问你烦不烦?我估计你都会怀疑人生了。那有办法解决没有呢?这么多人来问你受不了,一个人问不就可以解决了?奶茶做好了,由他来通知你们不就可以了?
IO复用模型采用的就是这种方式,不需要所有进程轮询来发起recvform来查询数据是否已经准备好了,而是有人帮忙来询问,这个帮忙的人就是select。
IO复用模型图例如下:
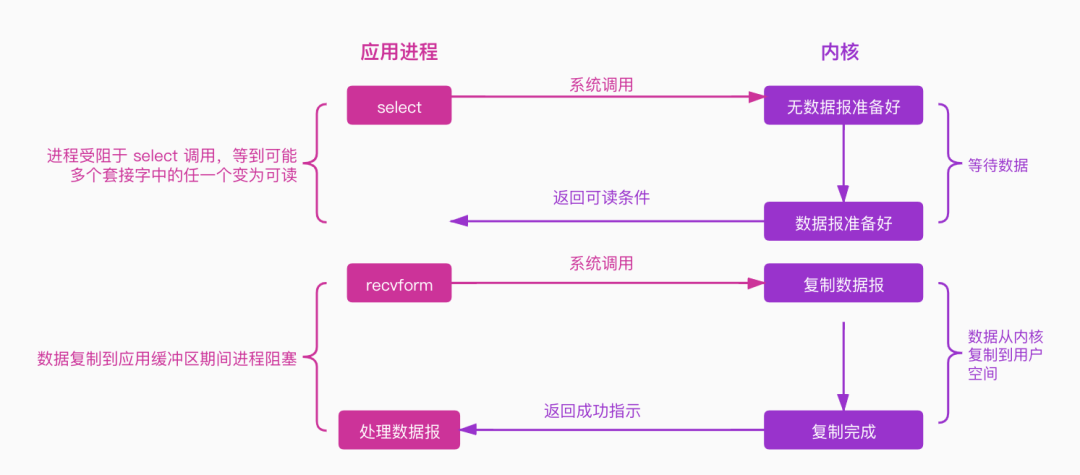
多个进程的IO注册到一个复用器(select)上,然后用一个进程监听该 select,select 会监听所有注册进来的IO。如果内核的数据报没有准备好,select 调用进程会被阻塞,而当任一IO在内核缓冲区中有数据,select调用就会返回可读条件,然后进程再进行recvform系统调用,内核将数据拷贝到用户空间,注意这个过程是阻塞的。
优点 一个进行负责状态监听,性能较好。 适用于高并发应用程序 缺点 模型复杂,实现、开发难度较大
场景
还是那家餐厅,开始的时候,大家都是在那里等,服务员只需要等菜做好,端上来就可以了,某天有些小伙伴发现你跟你女朋友竟然利用等菜的空闲时间去逛街(虽然累,但好歹也买了几件东西对吧),然后他们也采用了这种方式,这个时候服务员就受不了了,你们隔一段时间就来问,隔一段时间就来问,烦都烦死了,于是他想了一个办法,说,你们派一个人来问就可以了,我这边做了由他来告诉你们菜是否已经做了好。
后面小编会有专门的一篇文章来分析IO多路复用,敬请期待!!
信号驱动IO模型
IO 复用模型在第一个阶段和第二个阶段其实都有阻塞,第一个阶段阻塞于 select 调用,第二个阶段阻塞于数据复制,那有没有办法在第一个阶段或者第二个阶段不阻塞,进一步提升性能呢?信号驱动IO模型。图例如下:
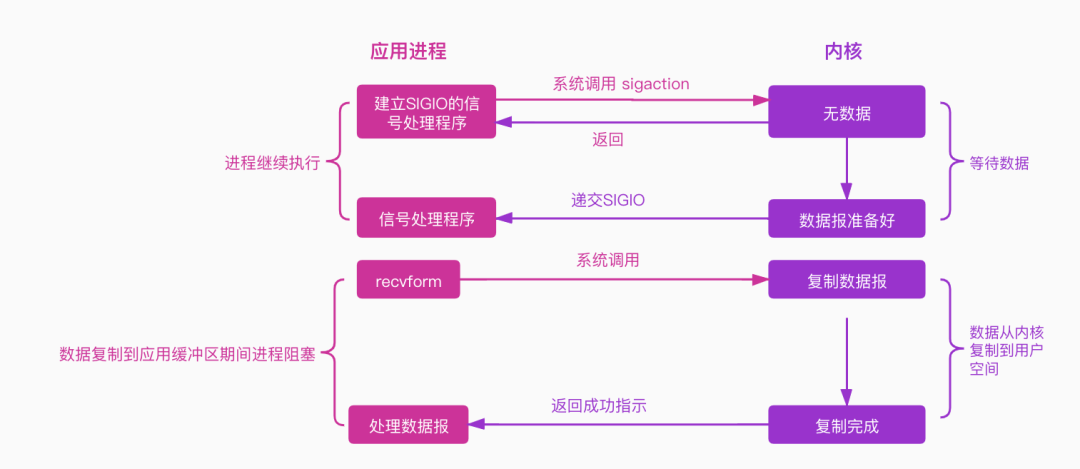
进程发起一个IO操作,会向内核注册一个信号处理程序,然后 立即返回不阻塞,当内核将数据报准备好后会发送一个信号给进程,这时候进程便可以在信号处理程序中调用IO处理数据报。它与IO复用模型的主要区别是等待数据阶段无阻塞。
优点 采用回调机制,等待数据阶段无阻塞 适用于高并发应用程序 缺点 模型较为复杂,实现起来有点儿困难
场景
有人帮你问,其实也不是那么好,因为你还是要等他来告诉你,而且他是只要你们当中有一个人的菜做好了就告诉你们所有人。于是,你们又想了一种方案,我点完菜后,我告诉服务员,我留我的微信在你这里,菜做好后,你告诉我就可以了。这样你女票就可以利用这个空余时间逛更久了。
异步IO模型
信号驱动IO模型,进一步优化了IO操作流程,经过了三轮优化,它终于不用在数据等待阶段阻塞了,但是在数据复制节点依然是阻塞的,所以如果我们需要进一步优化的话,只需要把第二个阶段也进一步优化为异步,我们就大功告成了,也就变成了真正的异步IO了。
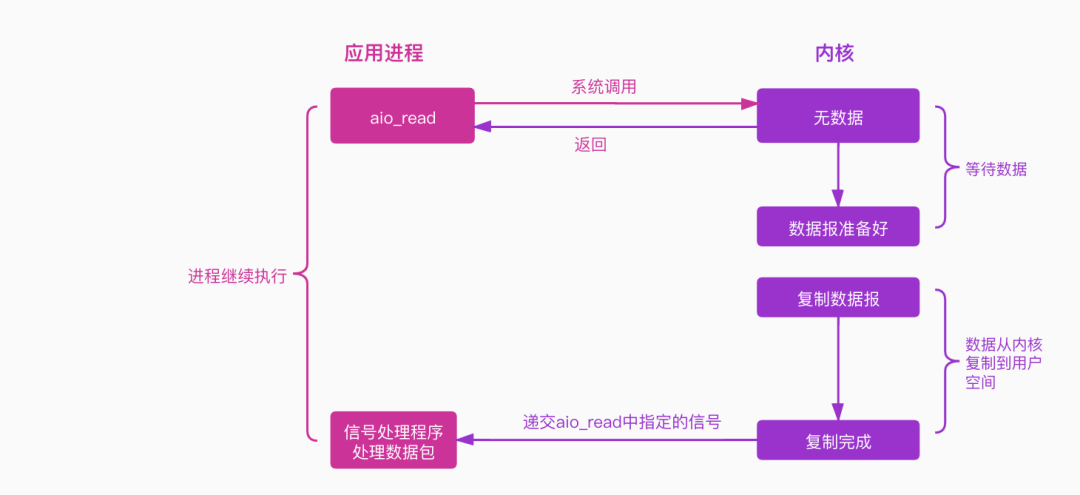
当进程发送一个IO操作,进程会立刻返回(不阻塞),但是也不能发挥结果,内核会把整个IO数据报准备好后,再通知进程,进程再处理数据报。
场景经过了前面四次的
优点 整个过程都不阻塞,一步到位 非常使用高并发应用 缺点 需要操作系统的底层支持,LINUX 2.5 版本内核首现,2.6 版本产品的内核标准特性 模型复杂,实现、开发难度较大
场景
虽然留电话的方式不错,你只需要留一个微信就可以了,瞬间解放了,后面你又发现了一个问题,你到了餐厅后,还不能立刻吃饭,因为他们还要上菜,这个过程你还是要等,如果你到店后立刻就可以吃难道不是更爽么?所以你服务员沟通说,你做好菜后,直接上,完成后再微信通知你,你到店后就直接吃了。这样你是不是更加爽了?
总结
五种IO模型,层层递进,一个比一个性能高,当然模型的复杂度也一个比一个复杂。最后用一张图来总结下
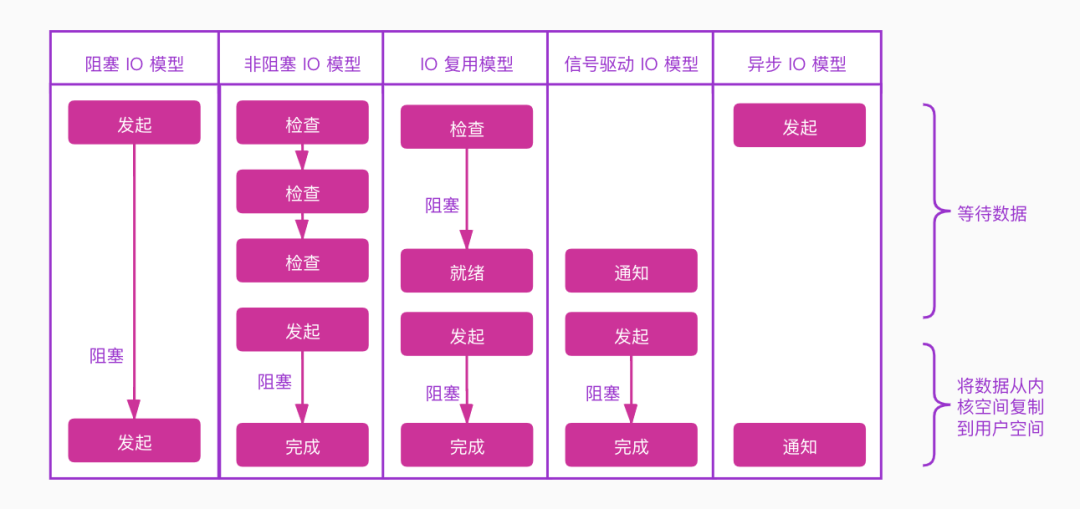
通过这张图,我想你应该可以回答文章前面的那个问题了。
参考
https://cloud.tencent.com/developer/article/1684951
https://www.jianshu.com/p/486b0965c296