
重新认识 Java 中的内存映射(mmap)
共 2999字,需浏览 6分钟
·
2021-11-14 19:25
mmap 基础概念
mmap 是一种内存映射文件的方法,即将一个文件映射到进程的地址空间,实现文件磁盘地址和一段进程虚拟地址的映射。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read,write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
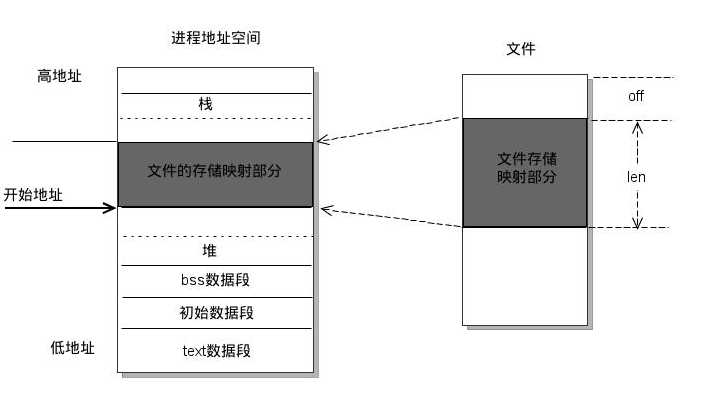
操作系统提供了这么一系列 mmap 的配套函数
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
int munmap( void * addr, size_t len);
int msync( void *addr, size_t len, int flags);
Java 中的 mmap
Java 中原生读写方式大概可以被分为三种:普通 IO,FileChannel(文件通道),mmap(内存映射)。区分他们也很简单,例如 FileWriter,FileReader 存在于 java.io 包中,他们属于普通 IO;FileChannel 存在于 java.nio 包中,也是 Java 最常用的文件操作类;而今天的主角 mmap,则是由 FileChannel 调用 map 方法衍生出来的一种特殊读写文件的方式,被称之为内存映射。
mmap 的使用方式:
FileChannel fileChannel = new RandomAccessFile(new File("db.data"), "rw").getChannel();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, filechannel.size();
MappedByteBuffer 便是 Java 中的 mmap 操作类。
// 写
byte[] data = new byte[4];
int position = 8;
// 从当前 mmap 指针的位置写入 4b 的数据
mappedByteBuffer.put(data);
// 指定 position 写入 4b 的数据
MappedByteBuffer subBuffer = mappedByteBuffer.slice();
subBuffer.position(position);
subBuffer.put(data);
// 读
byte[] data = new byte[4];
int position = 8;
// 从当前 mmap 指针的位置读取 4b 的数据
mappedByteBuffer.get(data);
// 指定 position 读取 4b 的数据
MappedByteBuffer subBuffer = mappedByteBuffer.slice();
subBuffer.position(position);
subBuffer.get(data);
mmap 不是银弹
促使我写这一篇文章的一大动力,来自于网络中很多关于 mmap 错误的认知。初识 mmap,很多文章提到 mmap 适用于处理大文件的场景,现在回过头看,其实这种观点是非常荒唐的,希望通过此文能够澄清 mmap 本来的面貌。
FileChannel 与 mmap 同时存在,大概率说明两者都有其合适的使用场景,而事实也的确如此。在看待二者时,可以将其看待成实现文件 IO 的两种工具,工具本身没有好坏,主要还是看使用场景。
mmap vs FileChannel
这一节,详细介绍一下 FileChannel 和 mmap 在进行文件 IO 的一些异同点。
pageCache
FileChannel 和 mmap 的读写都经过 pageCache,或者更准确的说法是通过 vmstat 观测到的 cache 这一部分内存,而非用户空间的内存。
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 4622324 40736 351384 0 0 0 0 2503 200 50 1 50 0 0
至于说 mmap 映射的这部分内存能不能称之为 pageCache,我并没有去调研过,不过在操作系统看来,他们并没有太多的区别,这部分 cache 都是内核在控制。后面本文也统一称 mmap 出来的内存为 pageCache。
缺页中断
对 Linux 文件 IO 有基础认识的读者,可能对缺页中断这个概念也不会太陌生。mmap 和 FileChannel 都以缺页中断的方式,进行文件读写。
以 mmap 读取 1G 文件为例, fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, _GB); 进行映射是一个消耗极少的操作,此时并不意味着 1G 的文件被读进了 pageCache。只有通过以下方式,才能够确保文件被读进 pageCache。
FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
MappedByteBuffer map = fileChannel.map(MapMode.READ_WRITE, 0, _GB);
for (int i = 0; i < _GB; i += _4kb) {
temp += map.get(i);
}
关于内存对齐的细节在这里就不拓展了,可以详见 java.nio.MappedByteBuffer#load 方法,load 方法也是通过按页访问的方式触发中断
如下是 pageCache 逐渐增长的过程,共计约增长了 1.034G,说明文件内容此刻已全部 load。
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 4824640 1056 207912 0 0 0 0 2374 195 50 0 50 0 0
2 1 0 4605300 2676 411892 0 0 205256 0 3481 1759 52 2 34 12 0
2 1 0 4432560 2676 584308 0 0 172032 0 2655 346 50 1 25 24 0
2 1 0 4255080 2684 761104 0 0 176400 0 2754 380 50 1 19 29 0
2 3 0 4086528 2688 929420 0 0 167940 40 2699 327 50 1 25 24 0
2 2 0 3909232 2692 1106300 0 0 176520 4 2810 377 50 1 23 26 0
2 2 0 3736432 2692 1278856 0 0 172172 0 2980 361 50 1 17 31 0
3 0 0 3722064 2840 1292776 0 0 14036 0 2757 392 50 1 29 21 0
2 0 0 3721784 2840 1292892 0 0 116 0 2621 283 50 1 50 0 0
2 0 0 3721996 2840 1292892 0 0 0 0 2478 237 50 0 50 0 0
两个细节:
mmap 映射的过程可以理解为一个懒加载, 只有 get() 时才会触发缺页中断 预读大小是有操作系统算法决定的,可以默认当作 4kb,即如果希望懒加载变成实时加载,需要按照 step=4kb 进行一次遍历
而 FileChannel 缺页中断的原理也与之相同,都需要借助 PageCache 做一层跳板,完成文件的读写。
内存拷贝次数
很多言论认为 mmap 相比 FileChannel 少一次复制,我个人觉得还是需要区分场景。
例如需求是从文件首地址读取一个 int,两者所经过的链路其实是一致的:SSD -> pageCache -> 应用内存,mmap 并不会少拷贝一次。
但如果需求是维护一个 100M 的复用 buffer,且涉及到文件 IO,mmap 直接就可以当做是 100M 的 buffer 来用,而不用在进程的内存(用户空间)中再维护一个 100M 的缓冲。
用户态与内核态
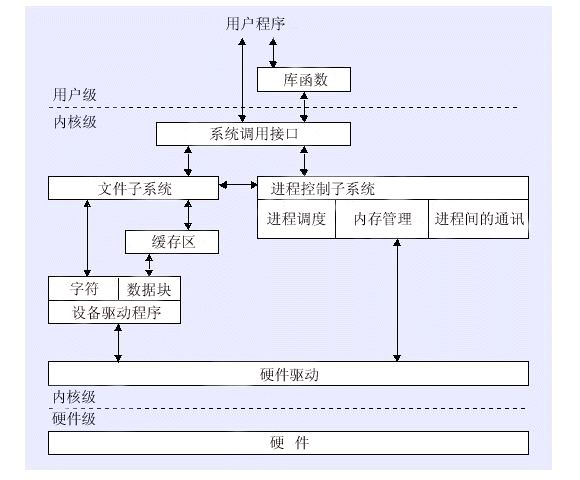
操作系统出于安全考虑,将一些底层的能力进行了封装,提供了系统调用(system call)给用户使用。这里就涉及到“用户态”和“内核态”的切换问题,私认为这里也是很多人概念理解模糊的重灾区,我在此梳理下个人的认知,如有错误也欢迎指正。
先看 FileChannel,下面两段代码,你认为谁更快?
// 方法一: 4kb 刷盘
FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_4kb);
for (int i = 0; i < _4kb; i++) {
byteBuffer.put((byte)0);
}
for (int i = 0; i < _GB; i += _4kb) {
byteBuffer.position(0);
byteBuffer.limit(_4kb);
fileChannel.write(byteBuffer);
}
// 方法二: 单字节刷盘
FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1);
byteBuffer.put((byte)0);
for (int i = 0; i < _GB; i ++) {
byteBuffer.position(0);
byteBuffer.limit(1);
fileChannel.write(byteBuffer);
}
使用方法一:4kb 缓冲刷盘(常规操作),在我的测试机器上只需要 1.2s 就写完了 1G。而不使用任何缓冲的方法二,几乎是直接卡死,文件增长速度非常缓慢,在等待了 5 分钟还没写完后,中断了测试。
使用写入缓冲区是一个非常经典的优化技巧,用户只需要设置 4kb 整数倍的写入缓冲区,聚合小数据的写入,就可以使得数据从 pageCache 刷盘时,尽可能是 4kb 的整数倍,避免写入放大问题。但这不是这一节的重点,大家有没有想过,pageCache 其实本身也是一层缓冲,实际写入 1byte 并不是同步刷盘的,相当于写入了内存,pageCache 刷盘由操作系统自己决策。那为什么方法二这么慢呢?主要就在于 filechannel 的 read/write 底层相关联的系统调用,是需要切换内核态和用户态的,注意,这里跟内存拷贝没有任何关系,导致态切换的根本原因是 read/write 关联的系统调用本身。方法二比方法一多切换了 4096 倍,态的切换成为了瓶颈,导致耗时严重。
阶段总结一下重点,在 DRAM 中设置用户写入缓冲区这一行为有两个意义:
方便做 4kb 对齐,ssd 刷盘友好 减少用户态和内核态的切换次数,cpu 友好
但 mmap 不同,其底层提供的映射能力不涉及到切换内核态和用户态,注意,这里跟内存拷贝还是没有任何关系,导致态不发生切换的根本原因是 mmap 关联的系统调用本身。验证这一点,也非常容易,我们使用 mmap 实现方法二来看看速度如何:
FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
MappedByteBuffer map = fileChannel.map(MapMode.READ_WRITE, 0, _GB);
for (int i = 0; i < _GB; i++) {
map.put((byte)0);
}
在我的测试机器上,花费了 3s,它比 FileChannel + 4kb 缓冲写要慢,但远比 FileChannel 写单字节快。
这里也解释了我之前文章《文件 IO 操作的一些最佳实践》中一个疑问:"一次写入很小量数据的场景使用 mmap 会比 fileChannel 快的多“,其背后的原理就和上述例子一样,在小数据量下,瓶颈不在于 IO,而在于用户态和内核态的切换。
mmap 细节补充
copy on write 模式
我们注意到 public abstract MappedByteBuffer map(MapMode mode,long position, long size) 的第一个参数,MapMode 其实有三个值,在网络冲浪的时候,也几乎没有找到讲解 MapMode 的文章。MapMode 有三个枚举值 READ_WRITE、READ_ONLY、PRIVATE,大多数时候使用的可能是 READ_WRITE,而 READ_ONLY 不过是限制了 WRITE 而已,很容易理解,但这个 PRIVATE 身上似乎有一层神秘的面纱。
实际上 PRIVATE 模式正是 mmap 的 copy on write 模式,当使用 MapMode.PRIVATE 去映射文件时,你会获得以下的特性:
其他任何方式对文件的修改,会直接反映在当前 mmap 映射中。 private mmap 之后自身的 put 行为,会触发复制,形成自己的副本,任何修改不会会刷到文件中,也不再感知该文件该页的改动。
俗称:copy on write。
这有什么用呢?重点就在于任何修改都不会回刷文件。其一,你可以获得一个文件副本,如果你正好有这个需求,直接可以使用 PRIVATE 模式去进行映射,其二,令人有点小激动的场景,你获得了一块真正的 PageCache,不用担心它会被操作系统刷盘造成 overhead。假设你的机器配置如下:机器内存 9G,JVM 参数设置为 6G,堆外限制为 2G,那剩下的 1G 只能被内核态使用,如果想被用户态的程序利用起来,就可以使用 mmap 的 copy on write 模式,这不会占用你的堆内内存或者堆外内存。
回收 mmap 内存
更正之前博文关于 mmap 内存回收的一个错误说法,回收 mmap 很简单
((DirectBuffer) mmap).cleaner().clean();
mmap 的生命中简单可以分为:map(映射),get/load (缺页中断),clean(回收)。一个实用的技巧是动态分配的内存映射区域,在读取过后,可以异步回收掉。
mmap 使用场景
使用 mmap 处理小数据的频繁读写
如果 IO 非常频繁,数据却非常小,推荐使用 mmap,以避免 FileChannel 导致的切态问题。例如索引文件的追加写。
mmap 缓存
当使用 FileChannel 进行文件读写时,往往需要一块写入缓存以达到聚合的目的,最常使用的是堆内/堆外内存,但他们都有一个问题,即当进程挂掉后,堆内/堆外内存会立刻丢失,这一部分没有落盘的数据也就丢了。而使用 mmap 作为缓存,会直接存储在 pageCache 中,不会导致数据丢失,尽管这只能规避进程被 kill 这种情况,无法规避掉电。
小文件的读写
恰恰和网传的很多言论相反,mmap 由于其不切态的特性,特别适合顺序读写,但由于 sun.nio.ch.FileChannelImpl#map(MapMode mode, long position, long size) 中 size 的限制,只能传递一个 int 值,所以,单次 map 单个文件的长度不能超过 2G,如果将 2G 作为文件大 or 小的阈值,那么小于 2G 的文件使用 mmap 来读写一般来说是有优势的。在 RocketMQ 中也利用了这一点,为了能够方便的使用 mmap,将 commitLog 的大小按照 1G 来进行切分。对的,忘记说了,RocketMQ 等消息队列一直在使用 mmap。
cpu 紧俏下的读写
在大多数场景下,FileChannel 和读写缓冲的组合相比 mmap 要占据优势,或者说不分伯仲,但在 cpu 紧俏下的读写,使用 mmap 进行读写往往能起到优化的效果,它的根据是 mmap 不会出现用户态和内核态的切换,导致 cpu 的不堪重负(但这样承担起动态映射与异步回收内存的开销)。
特殊软硬件因素
例如持久化内存 Pmem、不同代数的 SSD、不同主频的 CPU、不同核数的 CPU、不同的文件系统、文件系统的挂载方式...等等因素都会影响 mmap 和 filechannel read/write 的快慢,因为他们对应的系统调用是不同的。只有 benchmark 过后,方知快慢。
-- END --