
MySQL 8.0 数据字典表
统一保存到 mysql 库的数据字典表中了。mysql 库中,除了 general_log、slow_log 2 个日志表,其它所有表的存储引擎都是 InnoDB,伴随而来的是 DDL 终于能够支持原子操作了。
以 DROP TABLE t1, t2 为例,不会出现 t1 表删除成功,t2 表删除失败的情况,而是要么都删除成功,要么都删除失败。
本文我们就来聊聊 MySQL 8.0 中的数据字典表。
本文内容基于 MySQL 8.0.29 源码。
目录
1. 概述
2. 数据字典表有哪些?
3. 数据字典表元数据在哪里?
4. 创建数据字典表
5. 打开数据字典表
6. 总结
正文
1. 概述
MySQL 8.0 重构数据字典之后,废除了 MySQL 5.7 中用于保存元数据的磁盘文件:.frm、.par、.TRN、.TRG、.isl、db.opt、ddl_log.log。
如果想要了解上面这些磁盘文件都保存了什么元数据,可以参照 MySQL 官方文档:
https://dev.mysql.com/doc/refman/8.0/en/data-dictionary-file-removal.html
这些文件被废除之后,原本保存到这些文件中的元数据,都保存到数据字典表中了。
数据字典表本身也大变样了:
数据字典表不再位于 InnoDB 系统表空间,而是迁移到 mysql 库中,mysql 库位于 mysql 表空间,磁盘文件为 mysql.ibd。SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS 这 4 个数据字典表也不再完全依赖硬编码在源码中的元数据了,而是和其它表一样,使用保存在 mysql 库的数据字典表中的元数据。
上面 4 个数据字典表的名字也发生了变化,后面会介绍。
2. 数据字典表有哪些?
按照官方文档的定义,MySQL 8.0 一共有 31 张数据字典表:
dd_properties
innodb_ddl_log
catalogs
character_sets
check_constraints
collations
column_statistics
column_type_elements
columns
events
foreign_key_column_usage
foreign_keys
index_column_usage
index_partitions
index_stats
indexes
parameter_type_elements
parameters
resource_groups
routines
schemata
st_spatial_reference_systems
table_partition_values
table_partitions
table_stats
tables
tablespace_files
tablespaces
triggers
view_routine_usage
view_table_usage
上面只是简单列出了数据字典表的表名,如果想了解每个表存放了什么内容,可以参照官方文档:https://dev.mysql.com/doc/refman/8.0/en/system-schema.html
默认情况下,我们是看不到数据字典表的,需要满足以下条件才能看到:
源码编译 Debug 版本 MySQL,以使用 cmake 编译为例,需要带上 -DCMAKE_BUILD_TYPE=Debug编译选项。连接 MySQL 之后,先执行下面的 SQL 告诉 MySQL 跳过数据字典表的权限检查:
SET SESSION debug = '+d,skip_dd_table_access_check'
满足以上 2 个条件之后,执行下面这条 SQL 就可以看到所有数据字典表了:
SELECT a.name AS db_name, b.*
FROM mysql.schemata AS a
INNER JOIN mysql.tables AS b ON a.id = b.schema_id
WHERE b.schema_id = 1 AND b.hidden = 'System'
ORDER BY b.id
执行上面的 SQL 列出来的表有 32 个,其中
innodb_dynamic_metadata表不属于数据字典表。
上面列出的数据字典表中,有 4 个需要重点介绍,因为不管是数据字典表本身,还是用户表,都离不开这 4 个表:
tables:存储表的元数据,包括表空间 ID、数据库 ID、表 ID、表名、表注释、行格式等信息,对应 MySQL 5.7 中的数据字典表SYS_TABLES。columns:存储表中字段的元数据,包括表 ID、字段 ID、字段名、字段注释、字段类型、是否自增等信息,对应 MySQL 5.7 中的数据字典表SYS_COLUMNS。indexes:存储表的索引元数据,包括表空间 ID、表 ID、索引 ID、索引名、索引注释、是否是隐藏索引等信息,对应 MySQL 5.7 中的数据字典表SYS_INDEXES。index_column_usage:存储索引中字段的元数据,包括索引 ID、字段 ID、字段在索引中的编号(从 1 开始)、索引字段长度(如果是前缀索引字段,则是前缀的长度)、索引字段排序、是否隐藏,共6个字段,对应 MySQL 5.7 中的数据字典表SYS_FIELDS。
这个表中没有包含更详细的字段信息,如果需要,可以通过字段 ID 到columns表获取。
index_column_usage 和 SYS_FIELDS 表不完全一样,有 2 点需要说明:
index_column_usage 包含 6 个字段,比 SYS_FIELDS 多 3 个字段: order:表示索引字段的排序。length:hidden =0时,表示索引字段长度,或前缀索引字段的前缀长度;hidden =1时,字段值为NULL。hidden:0表示索引中该字段由用户定义;1表示索引中该字段是 MySQL 给加上的。以下是一个测试表,图中
name是从 columns 表中连表查询得到的,其它都是 index_column_usage 表的字段。
CREATE TABLE `t5` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`str1` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8_general_ci NOT NULL DEFAULT '',
`i1` int NOT NULL DEFAULT '0',
`str2` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8_general_ci NOT NULL DEFAULT '',
`i2` int NOT NULL DEFAULT '0',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `idx_i1` (`i1`) USING BTREE,
KEY `idx_str1` (`str1`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
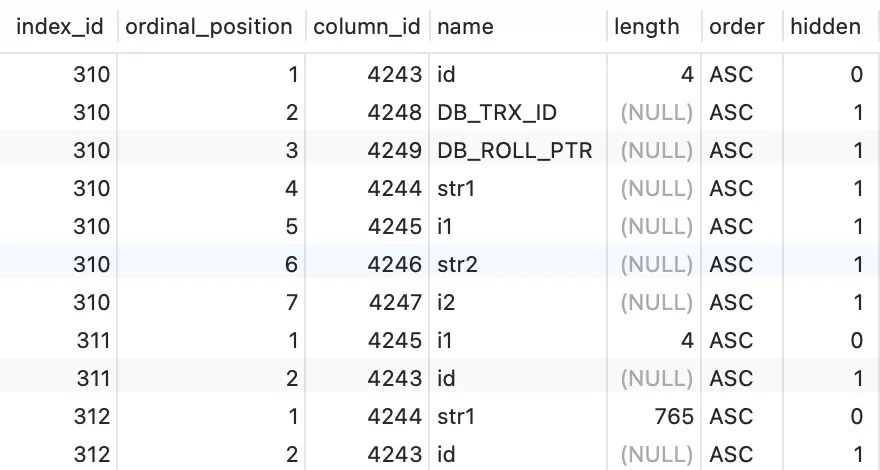
index_id = 310 是主键索引,hidden = 0 的记录是主键字段;hidden = 1 的记录是主键索引中的其它字段,也就是表中的字段。index_id = 312 是二级索引,其中 str1 是前缀索引字段,前缀长度为 255 * 3(utf8 一个字符最多占用的字节数) = 765,hidden = 0 表示 str1 是用户定义的二级索引字段;hidden = 1 的记录是 MySQL 自己增加到二级索引中的主键字段。
index_column_usage 表中的 ordinal_position表示编号,从 1 开始;SYS_FIELDS 中的POS表示序号,从 0 开始。
除了在 Debug 版本的 MySQL 中设置跳过数据字典表的权限检查之外,还可以通过 information_schema 数据库中的表或视图查看其对应的数据字典表:
| 数据字典表 | information_schema 表或视图 |
|---|---|
| tables | INNODB_TABLES |
| columns | INNODB_COLUMNS |
| indexes | INNODB_INDEXES |
| index_column_usage | INNODB_FIELDS |
| …… | …… |
3. 数据字典表元数据在哪里?
数据字典表用于存储用户表的元数据,这个比较好理解,因为创建用户表的时候,所有数据字典表都已经存在了,把用户表的各种元数据插入到相应的数据字典表就可以了。
数据字典表本身的元数据也会保存到数据字典表里,但是某个数据字典表创建的时候,有一些数据字典表还没有创建,这就有问题了。
我们以 columns、indexes 这 2 个数据字典表为例来说明:columns 表先于 indexes 表创建,columns 表创建成功之后,需要把索引元数据保存到 indexes 表中,而此时 indexes 表还没有创建,columns 表的索引元数据自然也就没办法保存到 indexes 表中了。
MySQL 解决这个问题的方案是引入一个中间层,用于临时存放所有数据字典表的各种元数据,等到所有数据字典表都创建完成之后,再把临时存放在中间层的所有数据字典表的元数据保存到相应的数据字典表中。
这里所谓的中间层实际上是一个存储适配器,源码中对应的类名为 Storage_adapter,这是一个实现了单例模式的类。
MySQL 在初始化数据目录的过程中,Storage_adapter 类的实例属性 m_core_registry 就是所有数据字典表元数据的临时存放场所。
4. 创建数据字典表
我们安装 MySQL 完成之后,想让 MySQL 运行起来,要做的第一件事就是初始化 MySQL,实际上就是初始化 MySQL 数据目录。
初始化过程会创建 MySQL 运行时需要的各种表空间、数据库、表,其中就包含数据字典表。
创建数据字典表的过程分为 3 个步骤进行:
第 1 步,把代表每个数据字典表的 Object_table 对象注册到 System_tables 类的实例属性 m_registry 中。
除了数据字典表,m_registry 中还包含了
mysql 库中的其它 MySQL 系统表。
第 2 步,循环 m_registry 中的所有表,通过 Object_table 得到数据字典表的 DDL,然后调用 dd::execute_query() 执行 DDL 语句创建数据字典表。
dd::execute_query() 创建数据字典表的过程中,会把表的元数据临时存放到 Storage_adapter 类的实例属性 m_core_registry 中,而不会保存到各种元数据对应的数据字典表中,这么做的原因在上一小节中介绍数据字典表的元数据在哪里时,已经介绍过了,这里不再赘述。
dd::execute_query() 执行完一个数据字典表的 DDL 语句之后,这个数据字典表在表空间中就已经存在了,m_registry 中的所有表都处理完成之后,所有数据字典表就都存在了。

第 3 步,循环 m_registry 中的所有表,把每个表本身的元数据(数据库 ID、表 ID、表名、注释、字段数量等)保存到 mysql.tables 数据字典表中,然后把表的字段、索引等元数据保存到对应的数据字典表中。
所有数据字典表的元数据都从
Storage_adapter类的实例属性m_core_registry中读取。
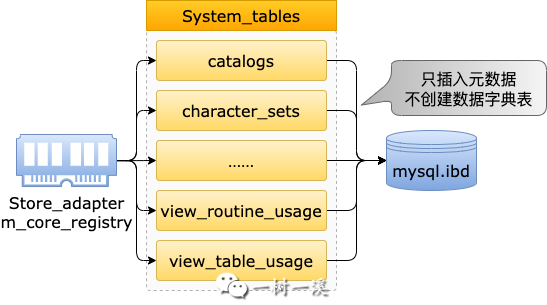
经过 3 个步骤的通力协作,所有数据字典表的元数据就都保存到数据字典表中了,这个鸡生蛋、蛋生鸡的问题,就这样通过引入外力(m_core_registry)解决了。
5. 打开数据字典表
数据字典表保存着 MySQL 运行过程中需要的一系列关键数据,使用频次很高,MySQL 启动过程中就会把数据字典表的元数据都加载到内存中,这就是打开表的过程。
也就是说,打开数据字典表是在 MySQL 启动过程中完成的。
前面我们介绍过,数据字典表的元数据也是保存在数据字典表中的。
MySQL 启动过程中,要先打开数据字典表才能拿到数据字典表的元数据,而要拿到数据字典表的元数据,又必须先打开数据字典表。
这个过程很绕,不是很好理解,我们来打个比方:数据字典表是一个房间,数据字典表的元数据是打开房间门的钥匙。
现在问题来了,因为 MySQL 把数据字典表的元数据保存在数据字典表中,这就相当于把打开房间门的钥匙落在房间里了。
要想打开房间,必须先拿到钥匙,而要想拿到钥匙又必须先打开房间,这样一转换,问题是不是更好理解点了?
我们先来想想怎么解决房间和钥匙问题,如果把打开房间的钥匙落在房间里了,有哪些办法可以解决?
我能想到的有以下 3 种解决方案:
暴力破解,把锁撬开。 找专业的开锁师傅把锁打开。 用备用钥匙开门。这个方法最好,但是有个 前提条件:已经提前准备好了备用钥匙。
MySQL 里没有前 2 种方案,而是留了一把备用钥匙,也就是第 3 种方案,接下来我们看看 MySQL 打开数据字典表的过程:
第 1 步,和创建数据字典表一样,把代表每个数据字典表的 Object_table 对象注册到 System_tables 类的实例属性 m_registry 中。
每个数据字典表的 Object_table 对象中,都定义了这个表的表名、字段、索引、外键等信息。
Object_table 对象中保存的并不是 DDL 语句,却类似于我们建表时的 DDL 语句。
下面这个例子是源码中表空间数据字典表 mysql.tablespaces Object_table 对象中定义的该表的信息:
Tablespaces::Tablespaces() {
// 表名
m_target_def.set_table_name("tablespaces");
// 字段
m_target_def.add_field(FIELD_ID, "FIELD_ID", "id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT");
m_target_def.add_field(FIELD_NAME, "FIELD_NAME", "name VARCHAR(268) NOT NULL COLLATE " + String_type(Object_table_definition_impl::name_collation()->m_coll_name));
m_target_def.add_field(FIELD_OPTIONS, "FIELD_OPTIONS", "options MEDIUMTEXT");
m_target_def.add_field(FIELD_SE_PRIVATE_DATA, "FIELD_SE_PRIVATE_DATA", "se_private_data MEDIUMTEXT");
m_target_def.add_field(FIELD_COMMENT, "FIELD_COMMENT", "comment VARCHAR(2048) NOT NULL");
m_target_def.add_field(FIELD_ENGINE, "FIELD_ENGINE", "engine VARCHAR(64) NOT NULL COLLATE utf8_general_ci");
m_target_def.add_field(FIELD_ENGINE_ATTRIBUTE, "FIELD_ENGINE_ATTRIBUTE", "engine_attribute JSON");
// 索引
m_target_def.add_index(INDEX_PK_ID, "INDEX_PK_ID", "PRIMARY KEY(id)");
m_target_def.add_index(INDEX_UK_NAME, "INDEX_UK_NAME", "UNIQUE KEY(name)");
// 如果有外键等其它信息,也会加在这里
}
第 2 步,循环 m_registry 中的所有表,通过 Object_table 得到数据字典表的 DDL,然后调用 dd::execute_query() 执行 DDL 语句创建数据字典表。
和创建数据字典表中的第 2 步不一样,dd::execute_query() 执行 DDL,并不会真正的创建表,只是为了生成数据字典表元数据,并把元数据保存到 Storage_adapter 类的实例属性 m_core_registry 中。
保存到 m_core_registry 中的数据字典表元数据,就是我们前面说的备用钥匙,有了这把备用钥匙,就能打开数据字典表了。
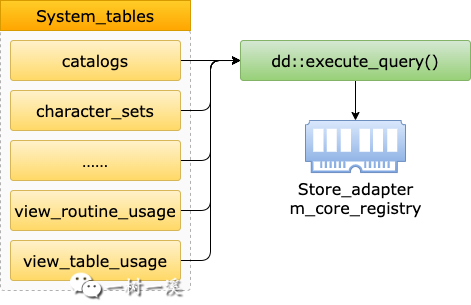
第 3 步,循环 m_registry 中的所有表,通过第 2 步生成的数据字典表元数据,去 mysql 表空间中(表空间文件:mysql.ibd)读取各个数据字典表的元数据。
这一步执行完成之后,所有数据字典表的元数据都被加载到内存中了,数据字典表都被打开了。
第 4 步,循环 m_registry 中的所有表,把数据字典表的元数据从 m_core_registry 删除。
第 5 步,循环 m_registry 中所有的表,把从表空间中读取出来的数据字典表的元数据存入 m_core_registry 中。
不过,这一步存入 m_core_registry 的并不是所有数据字典表的元数据,而是 22 个核心(CORE)数据字典表的元数据:
catalogs
character_sets
check_constraints
collations
column_statistics
column_type_elements
columns
foreign_key_column_usage
foreign_keys
index_column_usage
index_partitions
indexes
resource_groups
schemata
table_partition_values
table_partitions
tables
tablespace_files
tablespaces
triggers
view_routine_usage
view_table_usage
1 ~ 5 步执行完成之后,m_core_registry 中就只包含上面 22 个核心数据字典表的元数据了,有了这些表的元数据,就可以打开其它所有表了。
第 6 步,调用 dd::execute_query() 执行 FLUSH TABLES 关闭已经打开的所有数据字典表、非数据字典表,后续就可以用从数据字典表中读取出来的元数据来打开数据字典表和其它所有需要的表了。
到这里,打开数据字典表的大体流程就已经介绍完了,也许大家会有疑问:
第 2 步调用 dd::execute_query() 执行 DDL,已经拿到了数据字典表的元数据。
为了区分,把这里拿到的元数据叫作
备用元数据。
第 3 步根据备用元数据打开数据字典表,从表空间中读取到数据字典表的元数据。
同样为了区分,把这里拿到的元数据叫作
原配元数据。
第 4 步从 m_core_registry 中删除备用元数据。第 5 步把原配元数据存入 m_core_registry。
数据字典表的备用元数据和原配元数据不是一样的吗?为什么还要用原配元数据替换备用元数据,这是不是多此一举?
我没有逐个对比备用元数据和原配元数据是否完全一样,这是个不小的工程。不过,既然源码中这么实现,那应该是有它的原因,只是我还没有发现。如果后面发现其中的原因,我会再补充到我的博客中。
6. 总结
要理解 MySQL 8.0 中的数据字典表,核心是理解以下 2 点:
初始化数据目录时,数据字典表的元数据是怎么存放到数据字典表中的?
这主要是借助了 Storage_adapter 类实例的 m_core_registry 属性。
在创建数据字典表的过程中,先创建每个数据字典表,并把元数据临时存放到m_core_registry中,所有数据字典表都创建成功之后,最后再一次性把所有数据字典表的元数据保存到对应的数据字典表中。MySQL 启动时,怎么用数据字典表的元数据打开数据字典表?
这同时借助了硬编码在源码中的数据字典表定义,以及 Storage_adapter 类实例的m_core_registry属性。
MySQL 启动过程中,先通过 Object_table 得到创建数据字典表的 DDL,调用dd::execute_query()执行 DDL,拿到元数据(备用原数据),把备用元数据临时存放到 m_core_registry 属性中,再通过备用元数据打开数据字典表。
以上就是本文的全部内容了,如果本文对你有所帮助,还请帮忙 转发朋友圈、点赞、在看,谢谢 ^_^