
单阶段实例分割综述
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
前言 本文比较全面地介绍了实例分割在单阶段方法上的进展,根据基于局部掩码、基于全局掩码和按照位置分割这三个类别,分析了相关19篇论文的研究情况,并介绍了它们的优缺点。
作者:Patrick Langechuan Liu
编译:CV技术指南
实例分割是一项具有挑战性的计算机视觉任务,需要预测对象实例及其每像素分割掩码。这使其成为语义分割和目标检测的混合体。

自 Mask R-CNN 以来,实例分割的SOTA方法主要是 Mask RCNN 及其变体(PANet、Mask Score RCNN 等)。它采用先检测再分割的方法,先进行目标检测,提取每个目标实例周围的边界框,然后在每个边界框内部进行二值分割,分离前景(目标)和背景。
除了检测然后分割(或逐检测分割)的自顶向下方法之外,还有其他一些实例分割方法。一个例子是通过将实例分割作为自底向上的像素分配问题来关注像素,就像在 SpatialEmbedding (ICCV 2019) 中所做的那样。但是这些方法通常比检测然后分割的 SOTA 具有更差的性能,我们不会在这篇文章中详细介绍。
然而,Mask RCNN 速度非常慢,许多实时应用场合无法使用。此外,Mask RCNN 预测的掩码具有固定的分辨率,因此对于具有复杂形状的大目标来说不够精细。由于anchor-free目标检测方法(例如 CenterNet 和 FCOS)的进步,已经出现了一波关于单阶段实例分割的研究。其中许多方法比 Mask RCNN 更快、更准确,如下图所示。
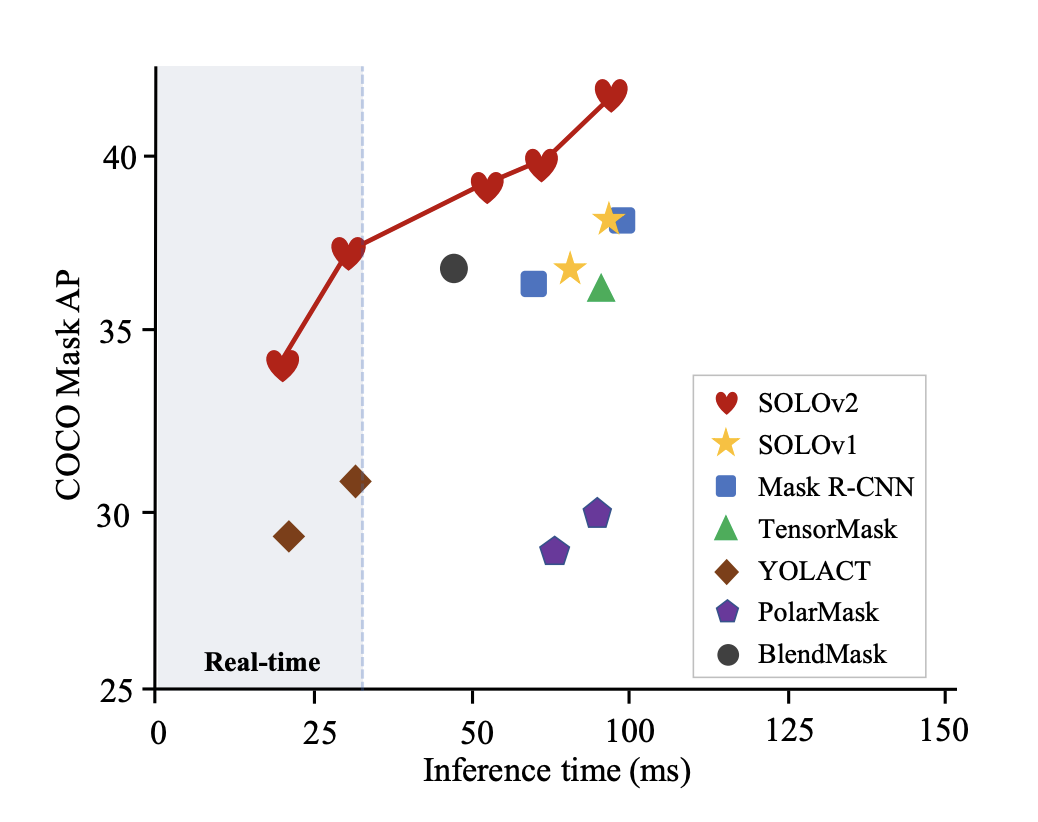
最近在 Tesla V100 GPU 上测试的单阶段方法的推理时间
本文将回顾单阶段实例分割的最新进展,重点是掩码表示——实例分割的一个关键方面。
局部掩码和全局掩码
在实例分割中要问的一个核心问题是实例掩码的表示或参数化——1)是使用局部掩码还是全局掩码,2)如何表示/参数化掩码。
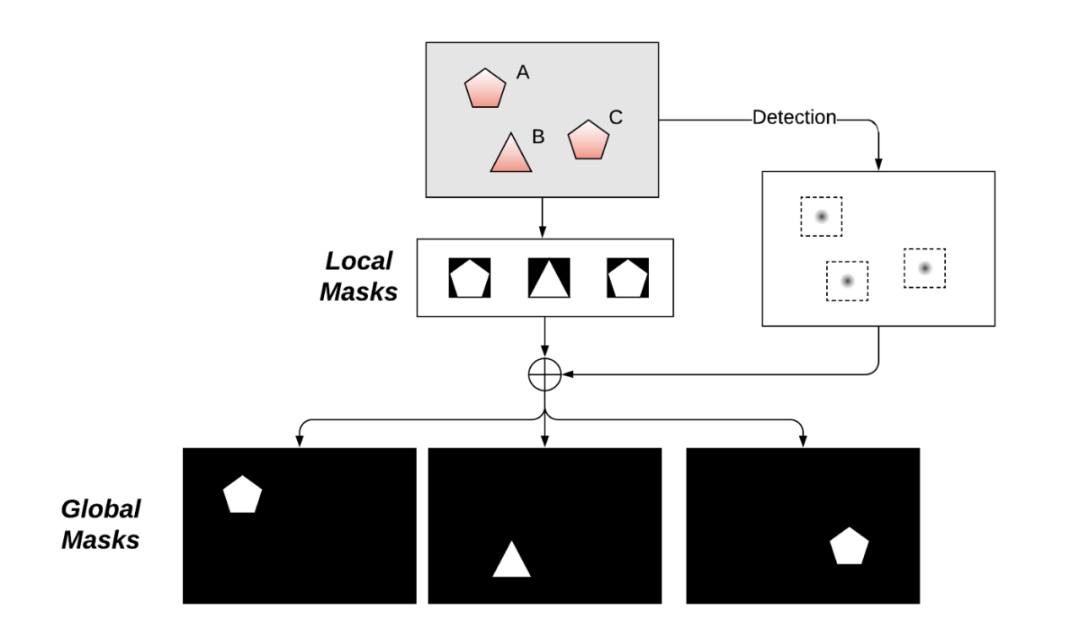
掩码表示:局部掩码和全局掩码
主要有两种表示实例掩码的方法:局部掩码和全局掩码。
全局掩码是我们最终想要的,它与输入图像具有相同的空间范围,尽管分辨率可能更小,例如原始图像的 1/4 或 1/8。它具有对大或小目标具有相同分辨率(因此具有固定长度特征)的天然优势。这不会牺牲更大目标的分辨率,固定分辨率有助于执行批处理以进行优化。
局部掩码通常更紧凑,因为它没有作为全局掩码的过多边界。它必须与要恢复到全局掩码的掩码位置一起使用,并且局部掩码大小将取决于目标大小。但是要执行有效的批处理,实例掩码需要固定长度的参数化。最简单的解决方案是将实例掩码调整为固定图像分辨率,如 Mask RCNN 所采用的那样。正如我们在下面看到的,还有更有效的方法来参数化局部掩码。
根据是使用局部掩码还是全局掩码,单阶段实例分割在很大程度上可以分为基于局部掩码( local-mask-based )和基于全局掩码( global-mask-based )的方法。
基于局部掩码的方法
基于局部掩码的方法直接在每个局部区域上输出实例掩码。
显式编码的轮廓
Bounding box 在某种意义上是一个粗糙的掩码,它用最小的边界矩形来逼近掩码的轮廓。ExtremeNet(Bottom-up Object Detection by Grouping Extreme and Center Points,CVPR 2019)通过使用四个极值点(因此是一个具有8个自由度的边界框而不是传统的4个DoF)进行检测,并且这种更丰富的参数化可以自然地扩展通过在其对应边缘上的两个方向上的极值点延伸到整个边缘长度的 1/4 的一段,到八边形掩模。

从那时起,有一系列工作试图将实例掩码的轮廓编码/参数化为固定长度的系数,给定不同的分解基础。这些方法回归每个实例的中心(不一定是 bbox 中心)和相对于该中心的轮廓。
ESE-Seg(Explicit Shape Encoding for Real-Time Instance Segmentation,ICCV 2019)为每个实例设计了一个内圆心半径形状签名,并将其与切比雪夫多项式拟合。
PolarMask(PolarMask:Single Shot Instance Segmentation with Polar Representation,CVPR 2020)使用从中心以恒定角度间隔的光线来描述轮廓。
FourierNet(FourierNet:Compact mask representation for instance segmentation using differentiable shape decoders)引入了使用傅立叶变换的轮廓形状解码器,并实现了比 PolarMask 更平滑的边界。

各种基于轮廓的方法
这些方法通常使用 20 到 40 个系数来参数化掩码轮廓。它们推理速度快且易于优化。但是,它们的缺点也很明显。首先,从视觉上看,它们都看起来——老实说——非常糟糕。它们无法精确描绘掩码,也无法描绘中心有孔的物体。
这系列方法很有意思,但是前途渺茫。实例掩码的复杂拓扑或其轮廓的显式编码是难以处理的。
结构化 4D 张量
TensorMask (TensorMask: A Foundation for Dense Object Segmentation, ICCV 2019) 是通过预测每个特征图位置的掩码来展示密集掩码预测思想的首批作品之一。TensorMask 仍然通过感兴趣区域而不是全局掩码来预测掩码,并且它能够在不运行目标检测的情况下运行实例分割。
TensorMask 利用结构化的 4D 张量来表示空间域上的掩码(2D 迭代输入图像中的所有可能位置,2D 表示每个位置的掩码),它还引入了对齐表示和张量双锥体( aligned representation and tensor bipyramid )来恢复空间细节,但这些对齐操作使网络甚至比两阶段的 Mask R-CNN 还要慢。此外,为了获得良好的性能,它需要使用比标准 COCO 目标检测管道(6x schedule)长 6 倍的调度进行训练。

紧凑型掩码编码
自然的目标掩码不是随机的,类似于自然图像,实例掩码位于比像素空间低得多的内在维度。
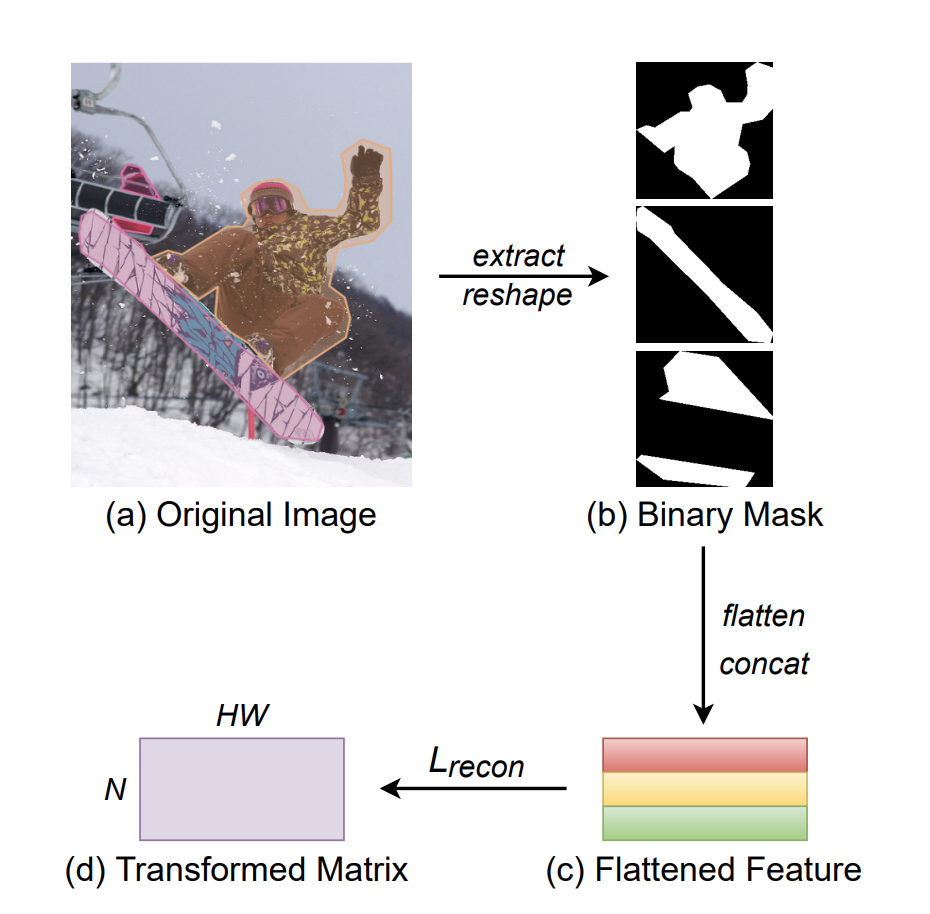
MEInst(Mask Encoding for Single Shot Instance Segmentation,CVPR 2020)将掩码提炼为紧凑且固定的维度表示。通过使用 PCA 进行简单的线性变换,MEInst 能够将 28x28 的局部掩码压缩为 60 维的特征向量。 该论文还尝试在单级目标检测器(FCOS)上直接回归 28x28=784-dim 特征向量,并且在 1 到 2 个 AP 点下降的情况下也得到了合理的结果。
这意味着直接预测高维掩码(以每个 TensorMask 的自然表示)并非完全不可能,但很难优化。 掩码的紧凑表示使其更容易优化,并且在推理时运行速度也更快。 它与 Mask RCNN 最相似,可以直接与大多数其他目标检测算法一起使用。
基于全局掩码的方法
基于全局掩码( Global-mask-based )的方法首先基于整个图像生成中间和共享特征图,然后组合提取的特征以形成每个实例的最终掩码。这是最近的单阶段实例分割方法中的主流方法。
原型和系数( Prototypes and Coefficients )
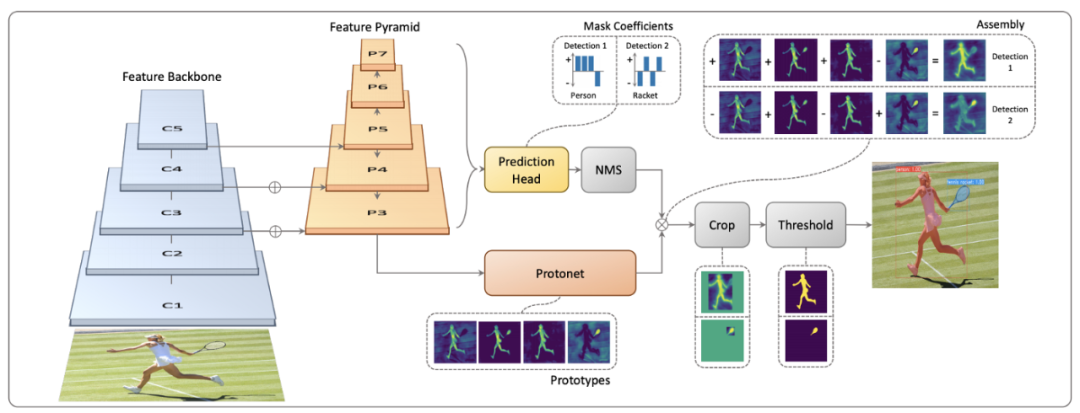
YOLACT(YOLACT:实时实例分割,ICCV 2019)是最早尝试实时实例分割的方法之一。YOLACT 将实例分割分解为两个并行任务,生成一组原型掩码并预测每个实例的掩码系数。
原型掩码( prototype masks )是用 FCN 生成的,可以直接受益于语义分割的进步。系数被预测为边界框的额外特征。这两个并行步骤之后是组装步骤:通过矩阵乘法实现的简单线性组合和对每个实例的预测边界框的裁剪操作。裁剪操作减少了网络抑制边界框外噪声的负担,但如果边界框包含同一类的另一个实例的一部分,仍然会看到一些泄漏。
回顾 InstanceFCN(Instance-sensitivefully Convolutional Networks,ECCV 2016)和 MSRA 的后续研究 FCIS(Fully Convolutional Instance-aware Semantic Segmentation,CVPR 2017),它们似乎是 YOLACT 的一个特例。InstanceFCN 和 FCIS 都利用 FCN 生成多个实例敏感的分数图,其中包含目标实例的相对位置,然后应用组装模块输出目标实例。位置敏感的分数图可以被视为原型掩码,但 IntanceFCN 和 FCIS 使用一组固定的空间池操作来组合位置敏感的原型掩码,而不是学习线性系数。
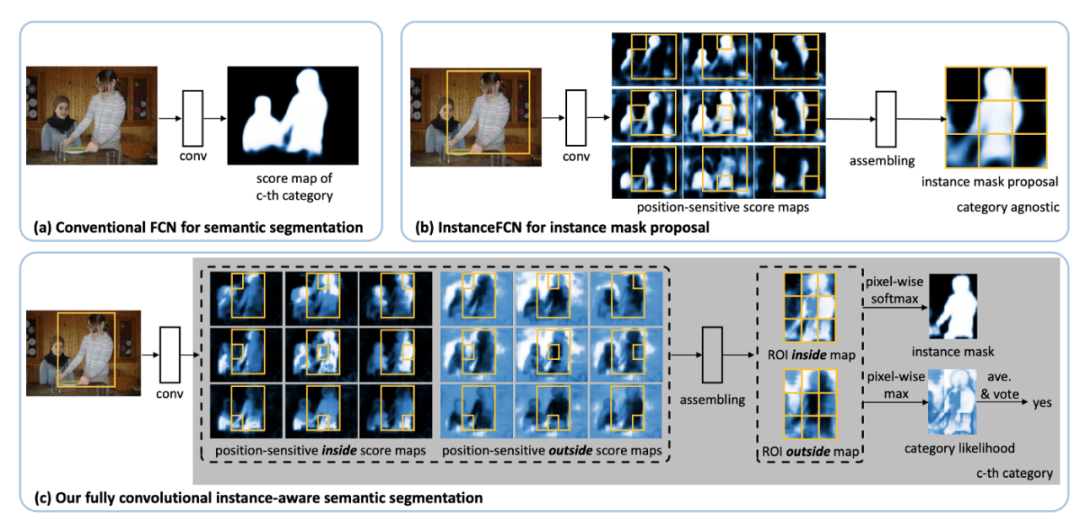
InstanceFCN [b] 和 FCIS [c] 使用固定池操作进行实例分割
BlendMask (BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation, CVPR 2020) 建立在 YOLACT 之上,但不是为每个原型掩码预测一个标量系数,BlendMask 预测一个低分辨率 (7x7) 注意力图来混合其中的掩码边界框。该注意力图被预测为附加到每个边界框的高维特征 (7x7=49-d)。有趣的是,BlendMask 使用的原型掩码是 4 个,但它甚至只对 1 个原型掩码起作用。
CenterMask(CenterMask:single shot instance segmentation with point representation,CVPR 2020)的工作方式几乎完全相同,并明确使用 1 个原型掩码(命名为全局显着图)。
CenterMask 使用 CenterNet 作为主干,而 BlendMask 使用类似的anchor-free和单级 FCOS 作为主干。
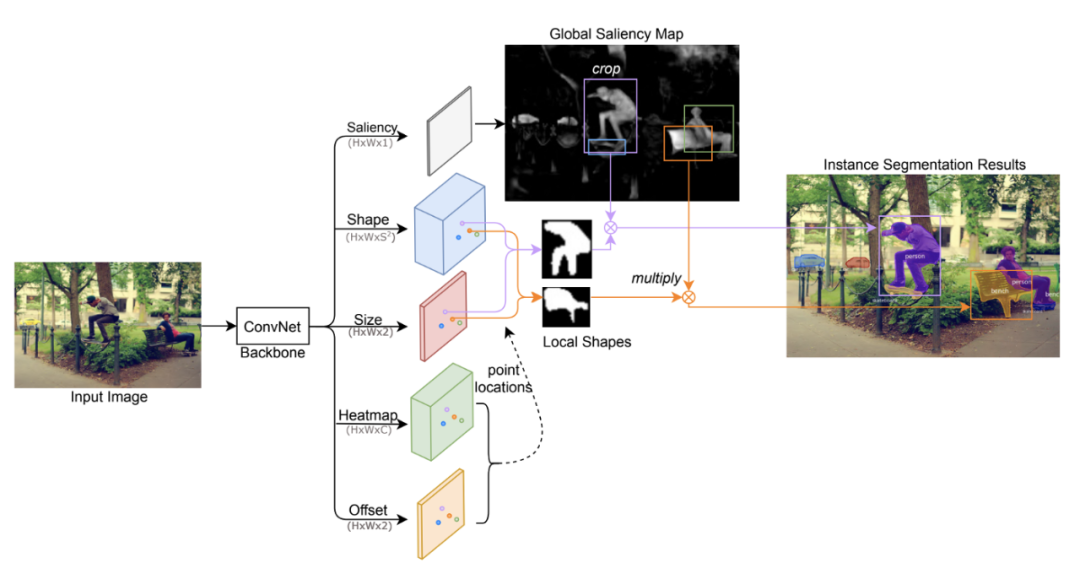
CenterMask 的架构。BlendMask 有一个极其相似的管道。
请注意,BlendMask 和 CenterMask 都进一步依赖于检测到的边界框。在与裁剪的原型蒙版混合之前,注意力图或掩码大小必须缩放到与边界框相同的大小。
CondInst (Conditional Convolutions for Instance Segmentation) 更进一步,完全消除了对边界框的任何依赖。它没有组装裁剪的原型掩码,而是借用了动态过滤器的思想并预测了轻量级 FCN 头部的参数。FCN头部共有三层,共有169个参数。令人惊奇的是,作者表明,即使原型掩码是单独的 2-ch CoordConv,网络也能在 COCO 上达到 31 个 AP。我们将在下面的隐式表示部分讨论这个。
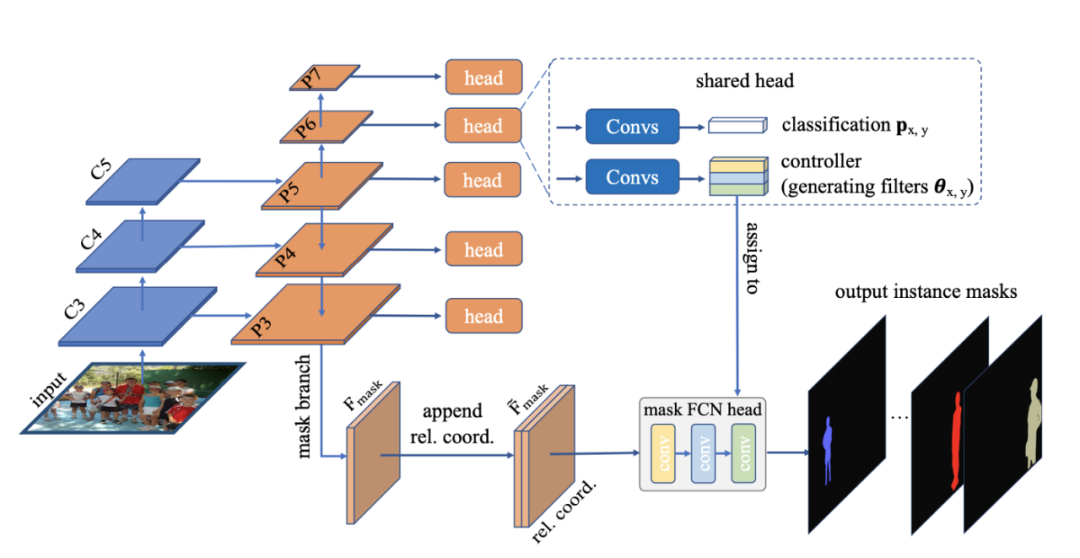
BlendMask /CenterMask 和 CondInst 都是 YOLACT 的扩展。
BlendMask/CenterMask 正在尝试将裁剪的原型掩码与每个 bbox 中的细粒度掩码混合。YOLACT 是 BlendMask 或 CenterMask 的一种特殊情况,其中注意力图的分辨率为 1x1。
CondInst 正在尝试将裁剪的原型掩码与由动态预测过滤器组成的更深层次的卷积混合在一起。YOLACT 是 CondInst 的一种特殊情况,其中 FCN 是 1 1x1 conv 层。
使用分支来预测原型掩码允许这些方法受益于使用语义分割的辅助任务(通常在 AP 中提升 1 到 2 个点)。它也可以自然地扩展到执行全景分割( panoptic segmentation )。
关于表示每个实例掩码所需的参数,下面列出了一些技术细节。这些具有全局掩码和系数的方法每个实例掩码使用 32、196、169 个参数。
YOLACT使用32个原型掩码+32-dim掩码系数+框裁剪;
BlendMask 使用 4 个原型掩码 + 4 个 7x7 注意力图 + 框裁剪;
CondInst 使用 coordConv + 3 1x1 动态 conv(169 个参数)
SOLO 和 SOLOv2:按位置分割目标
SOLO 是其中一种,值得拥有自己的部分。这些论文很有见地,而且写得很好。它们对我来说是一件艺术品(就像另一个我最喜欢的 CenterNet)。
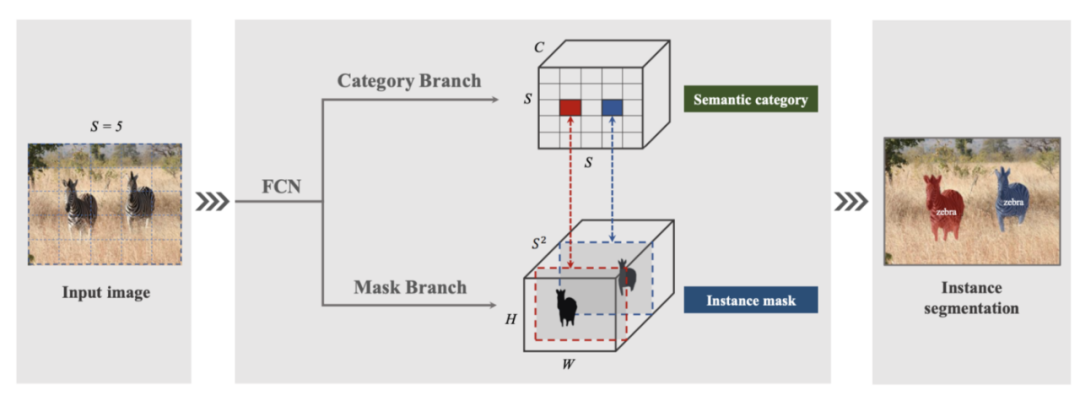
SOLOv1 的架构
论文第一作者在知乎上回复了SOLO的动机,我引用如下:
“语义分割预测图像中每个像素的语义类别。类似地,例如分割,我们建议预测每个像素的“实例类别”。现在关键的问题是,我们如何定义实例类别?”
如果输入图像中的两个目标实例具有完全相同的形状和位置,则它们是同一个实例。任何两个不同的实例要么具有不同的位置或形状。由于形状一般难以描述,我们用尺寸近似形状。
因此,“实例类别”由位置和大小定义。位置按其中心位置分类。SOLO 通过将输入图像划分为 S x S 单元格和 S² 类的网格来近似中心位置。通过将不同大小的目标分配到特征金字塔 (FPN) 的不同级别来处理大小。因此对于每个像素,SOLO 只需要决定将像素(和相应的实例类别)分配给哪个 SxS 网格单元和哪个 FPN 级别。所以SOLO只需要执行两个像素级别的分类问题,类似于语义分割。
现在另一个关键问题是掩码是如何表示的?
实例掩码直接由堆叠到 S² 通道中的全局掩码表示。这是一个巧妙的设计,可以同时解决许多问题。首先,许多先前的研究将 2D 掩码存储为扁平向量,当掩码分辨率增加导致通道数量激增时,这很快变得难以处理。全局掩码自然地保留了掩码像素内的空间关系。其次,全局掩码生成可以保持掩码的高分辨率。第三,预测掩码的数量是固定的,与图像中的目标无关。这类似于原型掩码的工作线,我们将在 SOLOv2 中看到这两个流如何合并。
SOLO 将实例分割制定为仅分类问题,并删除任何依赖于回归的问题。这使得 SOLO 自然独立于目标检测。SOLO 和 CondInst 是直接操作全局掩码的两个作品,是真正的无边界框方法。

SOLO 预测的全局掩码。掩码是冗余的、稀疏的并且对目标定位错误具有鲁棒性。
分辨率权衡( Resolution tradeoff )
从 SOLO 预测的全局掩码中,我们可以看到掩码对定位误差相对不敏感,因为相邻通道预测的掩码非常相似。这带来了目标定位的分辨率(以及精度)和实例掩码之间的权衡。
TensorMask 的 4D 结构化张量的想法在理论上很合理,但在当前 NHWC 张量格式的框架中很难在实践中实现。将具有空间语义的二维张量展平为一维向量不可避免地会丢失一些空间细节(类似于使用全连接网络进行语义分割),并且即使表示 128x128 的低分辨率图像也有其局限性。位置的 2D 或掩模的 2D 必须牺牲分辨率。大多数先前的研究都认为位置分辨率更重要并且对掩码尺寸进行下采样/压缩,从而损害了掩码的表现力和质量。TensorMask 试图取得平衡,但繁琐的操作导致训练和推理缓慢。SOLO 意识到我们不需要高分辨率的位置信息,并通过将位置压缩为粗略的 S² 网格来借用 YOLO。这样,SOLO 就保持了全局掩码的高分辨率。
我天真地认为 SOLO 或许可以通过将 S² x W x H 全局掩码预测为附加到 YOLO 中每个 S² 网格的附加扁平 WH 维特征来工作。我错了——以全分辨率而不是扁平矢量来制定全局掩码实际上是 SOLO 成功的关键。
Decoupled SOLO 和 Dynamic SOLO
如上所述,SOLO 在 S² 通道中预测的全局掩码非常冗余和稀疏。即使在 S=20 的粗分辨率下,也有 400 个通道,而且图片中的对象也不可能太多以至于每个通道都包含一个有效的实例掩码。
在Decoupled SOLO 中,形状为 H x W x S² 的原始 M 张量被两个形状为 H x W x S 的张量 X 和 Y 替换。对于位于网格位置 (i, j) 的对象,M_ij 近似为 逐元素乘法 X_i ⊗ Y_j。这将 400 个通道减少到 40 个通道,实验表明性能没有下降。
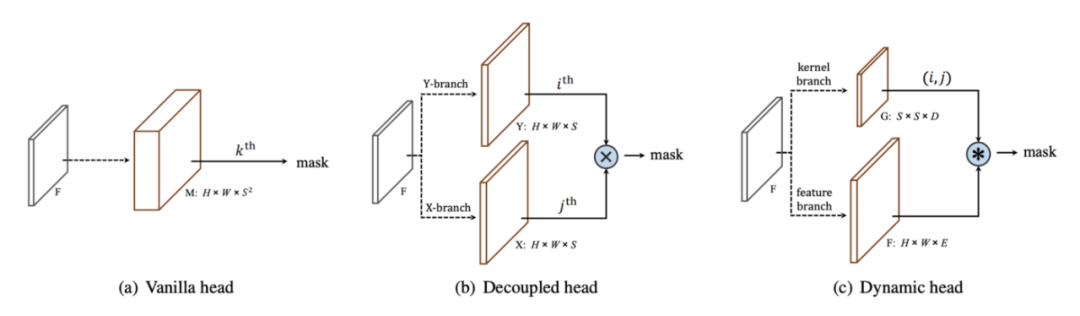
SOLO vs Decoupled SOLO vs SOLOv2
现在很自然地会问,我们是否可以通过预测更少的掩码并预测每个网格单元的系数来组合它们来借鉴 YOLACT 的原型掩码想法?SOLOv2 正是这样做的。
在 SOLOv2 中,有两个分支,一个特征分支和一个内核分支。特征分支预测 E 原型掩码,内核分支在每个 S² 网格单元位置预测大小为 D 的内核。正如我们在上面的 YOLACT 部分中看到的那样,这种动态过滤器方法是最灵活的。当 D=E 时,是原型掩码(或 1x1 conv)的简单线性组合,与 YOLACT 相同。该论文还尝试了 3x3 conv kernels(D=9E)。这可以通过预测轻量级多层 FCN 的权重和偏差(例如在 CondInst 中)更进一步。

现在,由于全局掩码分支与其专用位置解耦,我们可以观察到新的原型掩码表现出比 SOLO 中的更复杂的模式。它们仍然对位置敏感,并且更类似于 YOLACT。
掩码的隐式表示
CondInst 和 SOLOv2 中使用的动态滤波器的想法起初听起来很棒,但如果将其视为用于线性组合的系数列表的自然扩展,则实际上非常简单。
还可以认为我们使用系数或注意力图对掩码进行了参数化,或者最终将其参数化为用于小型神经网络头部的动态滤波器。最近在 3D 学习中也探索了使用神经网络动态编码几何实体的想法。传统上,3D 形状要么使用体素、点云或网格进行编码。Occupancy Networks (Occupancy Networks: Learning 3D Reconstruction in Function Space, CVPR 2019) 提出将形状编码为神经网络,将深度神经网络的连续决策边界视为 3D 表面。网络接收 3D 中的一个点并判断它是否在编码的 3D 形状的边界上。这种方法允许在推理期间以任何分辨率提取 3D 网格。
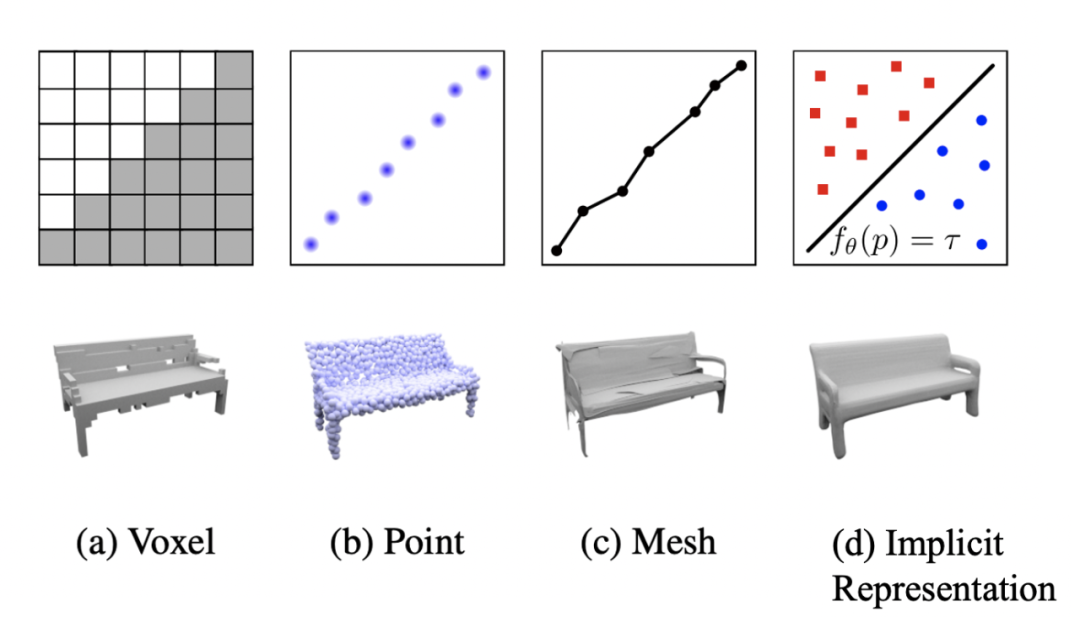
Occupancy Networks 中提出的隐式表示
我们能否学习一个由每个目标实例的动态过滤器组成的神经网络,以便网络接收 2D 中的一个点并输出该点是否属于该目标掩码?这自然会输出一个全局掩码,并且可以具有任何所需的分辨率。
回顾 CondInst 的消融研究,证明即使没有原型掩码,也只有 CoordConv 输入(用于执行均匀空间采样)。由于此操作与原型掩码的分辨率分离,因此以更高分辨率单独输入 CoordConv 以获得更高分辨率的全局掩码以查看这是否会提高性能会很有趣。我坚信实例掩码的隐式编码是未来。

只有 CoordConv 输入没有原型掩码,CondInst 也可以预测不错的性能
最后一句
大多数单阶段实例分割工作都是基于anchor-free目标检测,如CenterNet和FCOS。也许不出所料,上述许多论文都来自阿德莱德大学创建 FCOS 的同一个实验室。他们最近在 https://github.com/aim-uofa/AdelaiDet/ 上开源了他们的平台。
最近的许多方法都很快,并且可以实现实时或接近实时的性能 (30+ FPS)。NMS 通常是实时实例分割的瓶颈。为了实现真正的实时性能,YOLACT 使用 Fast NMS,SOLOv2 使用 Matrix NMS。
后记
预测实例掩码的高维特征向量是棘手的。几乎所有的方法都集中在如何将掩码压缩成低维表示。这些方法通常使用 20 到 200 个参数来描述一个掩码,取得不同程度的成功。我认为这是对表示掩码形状的最少参数数量的基本限制。
手工设计的参数化轮廓并不是很有前途。
局部掩码本质上取决于目标检测。希望能看到更多直接生成全局掩码的研究。
掩码的隐式表示是富有表现力的、紧凑的并且可以以任何分辨率生成掩码。CondInst 有可能通过利用隐式表示的力量生成更高分辨率的全局掩码。
SOLO 很简单,而 SOLOv2 又快又准。希望能看到更多沿着这条路线的未来研究。
1. SOLO: Segmenting Objects by Locations, Arxiv 12/2019
2. SOLOv2: Dynamic, Faster and Stronger, Arxiv 03/2020
3. YOLACT: Real-time Instance Segmentation, ICCV 2019
4. PolarMask: Single Shot Instance Segmentation with Polar Representation, CVPR 2020 oral
5. ESE-Seg: Explicit Shape Encoding for Real-Time Instance Segmentation, ICCV 2019
6. PointRend: Image Segmentation as Rendering, CVPR 2020 oral
7. TensorMask: A Foundation for Dense Object Segmentation, ICCV 2019
8. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation, CVPR 2020
9. CenterMask: single shot instance segmentation with point representation, CVPR 2020
10. MEInst: Mask Encoding for Single Shot Instance Segmentation, CVPR 2020)
11. CondInst: Conditional Convolutions for Instance Segmentation, Arxiv 03/2020
12. Occupancy Networks: Learning 3D Reconstruction in Function Space, CVPR 2019
13. FCOS: Fully Convolutional One-Stage Object Detection, ICCV 2019
14. Mask R-CNN, ICCV 2017 Best paper
15. PANet: Path Aggregation Network for Instance Segmentation, CVPR 2018
16. Mask Scoring R-CNN, CVPR 2019
17. InstanceFCN: Instance-sensitive Fully Convolutional Networks, ECCV 2016)
18. FCIS: Fully Convolutional Instance-aware Semantic Segmentation, CVPR 2017
19. FCN: Fully Convolutional Networks for Semantic Segmentation, CVPR 2015
20. CoordConv: An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution, NeurIPS 2018
21. Associative Embedding: End-to-End Learning for Joint Detection and Grouping, NeuRIPS 2017
22. SpatialEmbedding: Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth, ICCV 2019
原文链接:
https://towardsdatascience.com/single-stage-instance-segmentation-a-review-1eeb66e0cc49
----版权声明----
仅用于学术分享,若侵权请联系删除
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
