
实时实例分割模型YOLACT
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
AI编辑:我是小将
本文作者:OpenMMLab @00007
https://zhuanlan.zhihu.com/p/376347955
本文已由原作者授权转载
0 前言
YOLACT 含义是 You Only Look At CoefficienTs,是一篇非常有创新性的实时实例分割算法。Mask R-CNN 一般被认为是实例分割的 baseline,分割性能是非常不错的,但是其存在的问题是速度较慢,且包括 RoIAlign 等层不容易部署,而 YOLACT 的贡献是没有在 Mask R-CNN 基础上小修小补,而是基于 one-stage 全卷积算法重新设计,虽然在精度上稍低于 Mask R-CNN,但是也满足大部分需求了,并且速度达到了实时,容易部署,广泛应用于各类落地场景。
YOLACT 的核心思想是并行预测当前图片的原型掩码(prototype mask) 和每个 bbox 实例的掩码系数(mask coefficients),然后通过将原型与掩模系数线性组合来生成实例掩码(instance masks)。由于并行预测,不需要 two-stage 的 roipool 等操作,可以保持高的输出分辨率,故分割精度比较高。如下图所示,假设所有待检测物体的每个像素点都可以采用长度为 4 (超参,论文中是 32 )的原型向量表征,则原型掩码 shape 是 (h, w, 4),相应的每个实例的掩码系数 shape 是 (n, 4),n 是检测物体个数,然后利用每个 bbox 预测的掩码系数向量去加权原型掩码即 (h, w, 4) @ (4, ), 从而得到 (h,w) 的 mask 输出,遍历每个 bbox 预测的掩码系数去加权当前图片的全局原型掩码,就可以得到每个 bbox 所对应的 mask。
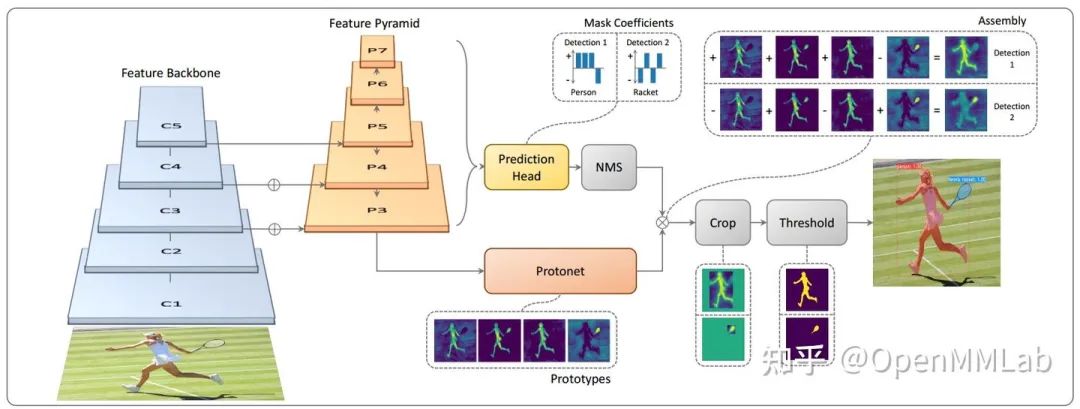
1 算法实现
和前系列解读一样,按照模块方式进行分析。
1.1 Backbone
作者选择的是标准的 ResNet 系列网络
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=-1, # do not freeze stem
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=False, # update the statistics of bn
zero_init_residual=False,
style='pytorch'), 需要注意的是:由于训练时长比较长,作者并没有采用常规的固定某些 stage 权重的做法,而且 backbone 层全部参与训练。
1.2 Neck
为了加强多层特征图之间的信息融合和引入多尺度预测,和 RetinaNet 一样也采用了 FPN 层
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_input',
num_outs=5,
upsample_cfg=dict(mode='bilinear')), # 上采样算子为双线性上采样1.3 Head
Head 网络实际上包括 3 个 Head
(1) 和 RetinaNet 一致的 bbox 分支,该分支包括 bbox 预测和类别预测分支,以及每个实例的掩码系数分支

输出实际上包括 3个预测分支,为了加速,对 RetinaNet 输出 Head 进行了适当修改,主要是
使用了更少的 anchor,每个位置都是 3 个 anchor
Bbox 分支 和 cls 分支共享卷积
额外多预测实例级别的掩码系数
(2) 原型掩码预测分支
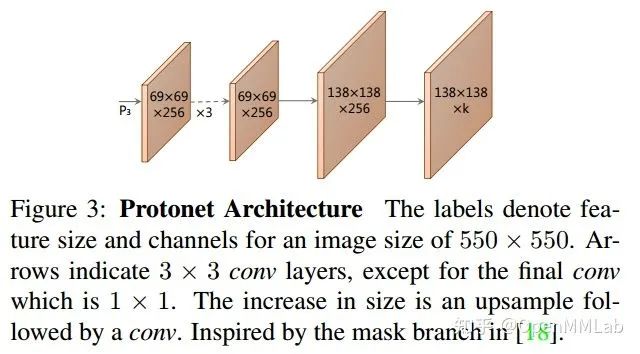
为了似的预测 mask 具备更多细节,作者采用比较大的输出图,对 FPN 输出的 P3 特征图还进行了额外的上采样操作,输出 mask 大小是 138x138
(3) 语义分割辅助训练分支
为了加速收敛和提高性能,作者还额外引入了全图的不区分实例的语义分割辅助训练分支,该分支在推理阶段可以直接删除,并且足够简单,只有一层卷积层而已。
1.4 训练流程
(1) bbox 分支
bbox_head=dict(
type='YOLACTHead',
num_classes=80, # 类别
in_channels=256,
feat_channels=256,
# 和 RetinaNet 一致,只不过 anchor 更少,参数也重新设计了
anchor_generator=dict(
type='AnchorGenerator',
octave_base_scale=3,
scales_per_octave=1,
base_sizes=[8, 16, 32, 64, 128],
ratios=[0.5, 1.0, 2.0],
strides=[550.0 / x for x in [69, 35, 18, 9, 5]],
centers=[(550 * 0.5 / x, 550 * 0.5 / x)
for x in [69, 35, 18, 9, 5]]),
# 编解码过程和 RetinaNet 一致
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
# ce loss,而没有采用 focal loss
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
reduction='none',
loss_weight=1.0),
# bbox loss
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.5),
num_head_convs=1,
num_protos=32,
use_ohem=True), # 默认 cls loss 还采用了 ohem 策略,克服不平衡问题如果不考虑每个实例的掩码系数,那么这个分支的推理和训练流程和 RetinaNet 完全相同。如果不熟悉,请参考 RetinaNet 算法解读。
由于每个 bbox 的 mask 系数没有标签,故 bbox head 分支仅仅对 bbox 和 cls 分支计算 loss,mask 系数监督信息来自后面的原型掩码预测分支。
(2) 原型掩码预测分支
mask_head=dict(
type='YOLACTProtonet',
in_channels=256,
num_protos=32, # 核心超参
num_classes=80,
# 考虑到特征图很大,通道很多,为了防止实例过多而OOM,强制训练最大 100 个实例
max_masks_to_train=100,
loss_mask_weight=6.125), 为了方便大家理解该分支的训练流程,首先需要看下 mmdet/models/detectors/yolact.py 中的整个训练流
# 实例级 mask 转为 tensor
gt_masks = [
gt_mask.to_tensor(dtype=torch.uint8, device=img.device)
for gt_mask in gt_masks
]
# 特征提取,包括 FPN,输出是 5 个不同尺度的特征图
x = self.extract_feat(img)
# bbox 分支进行 forward
cls_score, bbox_pred, coeff_pred = self.bbox_head(x)
bbox_head_loss_inputs = (cls_score, bbox_pred) + (gt_bboxes, gt_labels,
img_metas)
#bbox 分支计算 loss,可以看出没有传入 coeff_pred
losses, sampling_results = self.bbox_head.loss(
*bbox_head_loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
# 额外的语义分割监督层
segm_head_outs = self.segm_head(x[0])
loss_segm = self.segm_head.loss(segm_head_outs, gt_masks, gt_labels)
losses.update(loss_segm)
# 原型掩码预测分支 forward,注意因为 mask 需要大的输出图,故作者直接采用了 P3 层而已,其余层没有使用。coeff_pred 和 gt_bboxes 传入,用于提取实例级别信息
mask_pred = self.mask_head(x[0], coeff_pred, gt_bboxes, img_metas,
sampling_results)
# 计算 loss
loss_mask = self.mask_head.loss(mask_pred, gt_masks, gt_bboxes,
img_metas, sampling_results)
losses.update(loss_mask) 需要特意注意原型掩码预测分支 forward 的输入参数。需要明白:既然认为是实例分割,由于 target 也是每个 bbox 实例的 mask,那么该分支就需要想办法通过 forward 得到实例的 mask,而原型预测分支仅仅输出全图的原型掩码,需要利用预测的每个实例掩码系数来提取。
对于原型掩码 protonet 分支,由于直接的标签,且无法用预测 bbox 来裁剪(前期不稳定),但是我们有 实例 mask 标注,故训练时候输入的 bbox 是 gt bbox,然后利用 anchor 匹配时候的匹配规则即特征图点上哪些 anchor 负责预测该 gt bbox (如果不做处理,直接采用所有 gt bbox 去 crop,可能会存在 bbox 分支和 protonet 分支监督点不一致问题),基于这些正样本 anchor,然后采用 gt bbox 去裁剪对应的预测 mask 图,就可以得到实例级别 mask,后续算 loss 就是自然的事情了。
原型掩码 protonet 分支的训练过程有点点绕,不知道有没有说清楚,举个例子,假设 5个输出层所有特征图 h,w,k 进行拉伸,可以得到 (N,4) 个预测框,也可以得到 (N,32) mask 系数,其中只有部分预测框属于正样本,因为测试时候是基于预测框和 prototype 相乘,为了保持训练和推理一致,在训练时候需要采用 gt bbox 代替,利用前面 anchor 匹配规则计算出的正样本索引来提取 bbox 相关的 prototype 信息,此时就可以得到正样本索引所对应的 gt bbox 和 预测 mask 系数得到 mask 预测图,然后就可以采用 bce 进行 mask 训练了。由于 mask 系数和 protonet 联合得到的最终mask,故 mask 系数分支也得到了监督。
prototypes = self.protonet(x)
prototypes = prototypes.permute(0, 2, 3, 1).contiguous()
# idx 表示图片索引
cur_sampling_results = sampling_results[idx]
# 找出正样本索引
pos_assigned_gt_inds = \
cur_sampling_results.pos_assigned_gt_inds
# cur_bboxes 是 gt bbox,(M,4)
bboxes_for_cropping = cur_bboxes[pos_assigned_gt_inds].clone()
pos_inds = cur_sampling_results.pos_inds
# cur_coeff_pred 是 正样本索引所对应的 mask 系数预测值 (M,32)
cur_coeff_pred = cur_coeff_pred[pos_inds]
# 每个实例对应的 mask 预测图 (138,138,M)
mask_pred = cur_prototypes @ cur_coeff_pred.t()
mask_pred = torch.sigmoid(mask_pred)
# 基于 bbox 裁剪出 mask 图
mask_pred = self.crop(mask_pred, bboxes_for_cropping)
# 后面就可以计算 bce loss 了如果觉得上述过程还是难以理解,请先阅读后续的推理流程,再反过来阅读训练流程,就会轻松很多。
(3) 语义分割辅助训练分支
为了进一步提高性能,作者还额外引入了一个简单的卷积层,命名为语义分割层,因为有语义分割标注,故可以采用 bce 进行监督。语义分割 head 分支,输入 shape 是 69,即 FPN 输出的最大 size 层,然后将对应分割 标注双线性插值到 69,coco 类别是80,故分割图通道是 80,然后采用 bce 进行监督即可。推理时候直接删除本分支即可。
segm_head=dict(
type='YOLACTSegmHead',
num_classes=80,
in_channels=256,
loss_segm=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)), 1.5 推理流程
输入图片固定是 550x550,ResNet 输出 3 个输出特征图,strdie 分别是 8/16/32,输出特征图大小是 69/35/18,然后经过 FPN 特征融合并扩展了两个高语义层输出,一共输出 5 个特征图,特征图大小是69/35/18/9/5,即一共 5 个输出预测层。
和 RetinaNet 流程一致,先利用 5个输出层进行 bbox 和类别检测,同时输出每个 bbox 相关的 mask 系数,由于 anchor 个数为3,故分类预测图通道为 81x3(softmax模式),bbox 预测图通道为 4x3,mask 系数通道为 32x3,即每个 bbox 需要采用 32 长度的向量来表征。
Bbox 后处理流程和 RetinaNet 思想相同,大概流程是遍历每个预测输出层,对每个层先利用 nms_pre 参数过滤到指定数目的框;对这些框进行解码操作;最后对所有结果采用 nms 进行抑制得到指定数目的 bbox 和对应类别、mask 系数值,默认最多是100,即经过本步骤,输出bbox 的 shape 是 (N,4),类别的 shape 是 (N,),mask 系数的 shape 是 (N,32)。
需要注意的是:为了达到实时,作者对常规 nms 进行了修改,在尽量不降低太多性能情况下提出加速 nms 版本 fast nms。其核心思想是在一次抑制过程中,运行已经被移除的 bbox 去抑制其余 bbox,从而迅速移除大量 bbox,从而加速 nms。
对于原型分支 Protonet,为了使得 mask 更加精确,作者只选择了 FPN 后输出的最大尺度特征图 size 为 (69,69) 预测全局原型,输出 shape 为 (138,138,32),特征图上面每个位置都采用长度为 32 的 prototypes来表征,然后将 N 个预测框和 prototypes 矩阵进行乘加操作即 (138,138,32) @ (32,N) 输出 shape 为 (138,138,100),即可得到每个 bbox 对应的 mask,然后利用 bbox 坐标去 mask 图上进行切割即可得到对应的mask图,最后利用二值化,插值函数将 bbox 和 mask 都还原到原始图尺度,最终得到实例分割结果。
1.6 可视化分析
为了更加容易理解掩码系数和原型掩码,我特意挑选一种简单背景的图片(meinvtu),该图片来自 COCO 验证集,如下所示。

原型掩码 shape 是 (138, 138, 32),可以直接将这 32 个 tensor 进行展开按照索引顺序显示,如下所示,可以发现还是存在很多冗余信息的,由于没有直接的监督信号,输出的 tensor 并没有特定顺序。
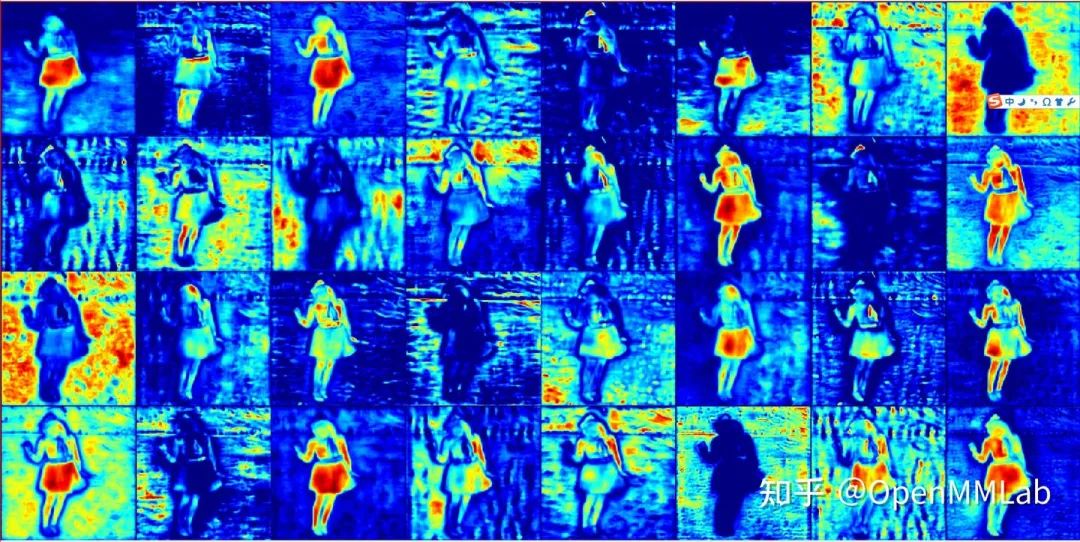
然后提取 bbox 坐标和对应的实例掩码系数,可视化如下所示
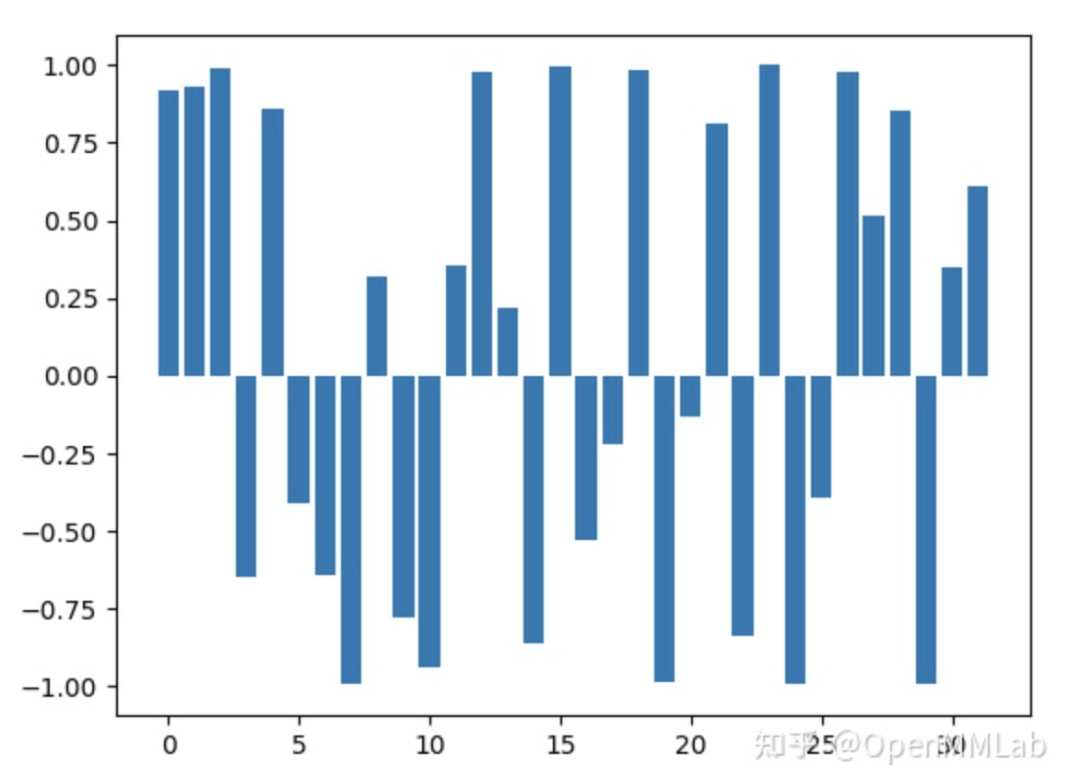
将上述两个 tensor 进行加权求和,可以得到最终的 mask,如下所示
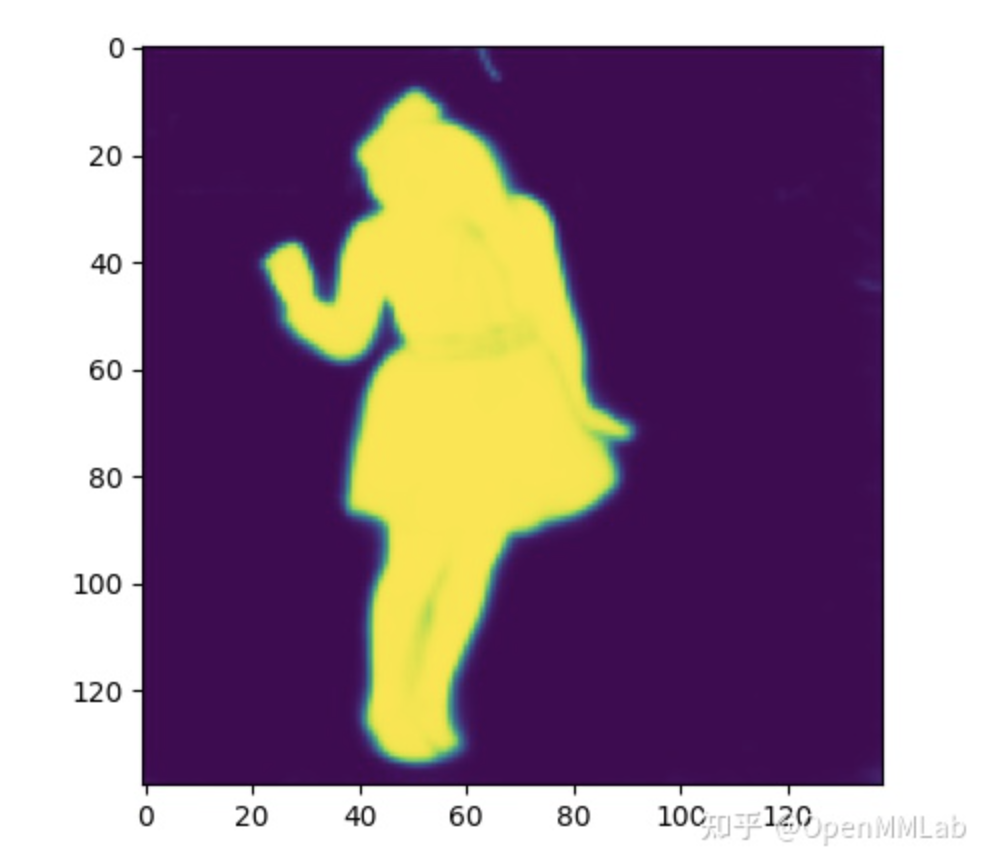
看起来效果还是蛮好的,掩码系数学的还是蛮准确的,所有冗余背景位置的系数都是负数。注意看头顶,可以发现其实 mask 预测很准确,但是 bbox 不是很准确,导致最终的 mask 头部有缺失。下图是最终的可视化效果。

2 总结
YOLACT 算法实现是非常有创新性的,抛弃了 Mask R-CNN 那套繁杂的设计,整个流程非常简洁优雅,并行预测当前图片的原型掩码(prototype mask) 和每个 bbox 实例的掩码系数(mask coefficients),然后通过将原型与掩模系数线性组合来生成实例掩码(instance masks),思想独特,是一篇不可多得的问题,值得学习学习。
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
