
爬虫实战!Python采集二手车数据并进行数据分析
前言
前段时间给朋友采集某子二手车平台的数据,虽然最后搞定了js加密,也通过价格对比短时间内算是搞定了字体反爬,但总是感觉很不完美,网站字体一共有5种对应关系,每次请求后都用价格对比,严重拖慢了系统运行速度不说,还容易出错。这次换一个平台,采集数据后进行简单的数据分析。
1.数据采集
1.1车辆列表页面分析
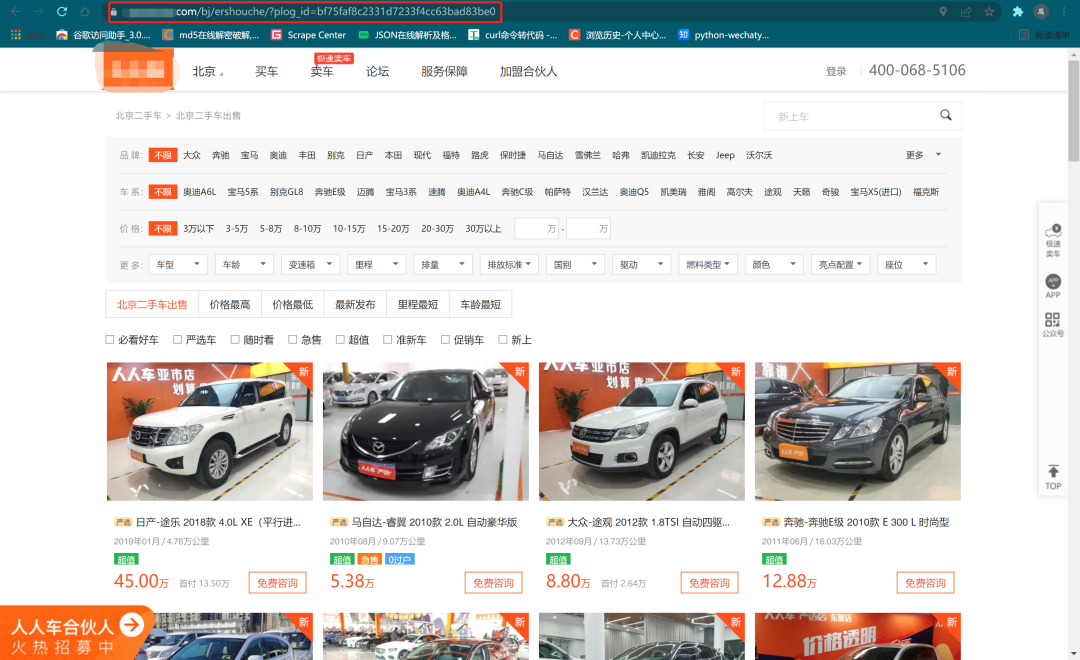
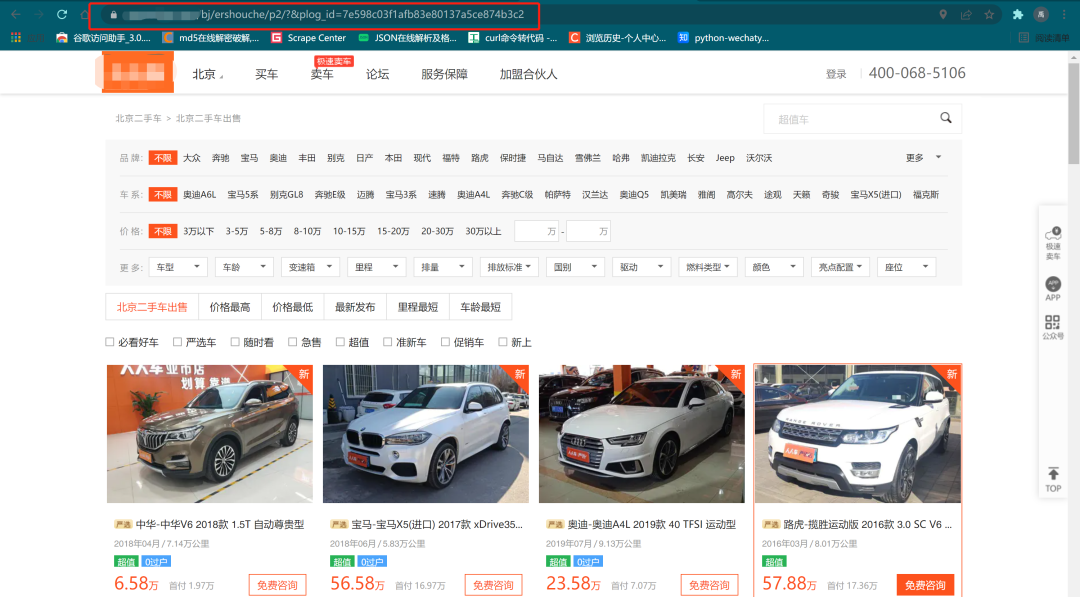
通过对网页的url分析发现,URL地址p后面的数字是用来的控制翻页,plog_id可以不用添加。继续分析网页源代码:
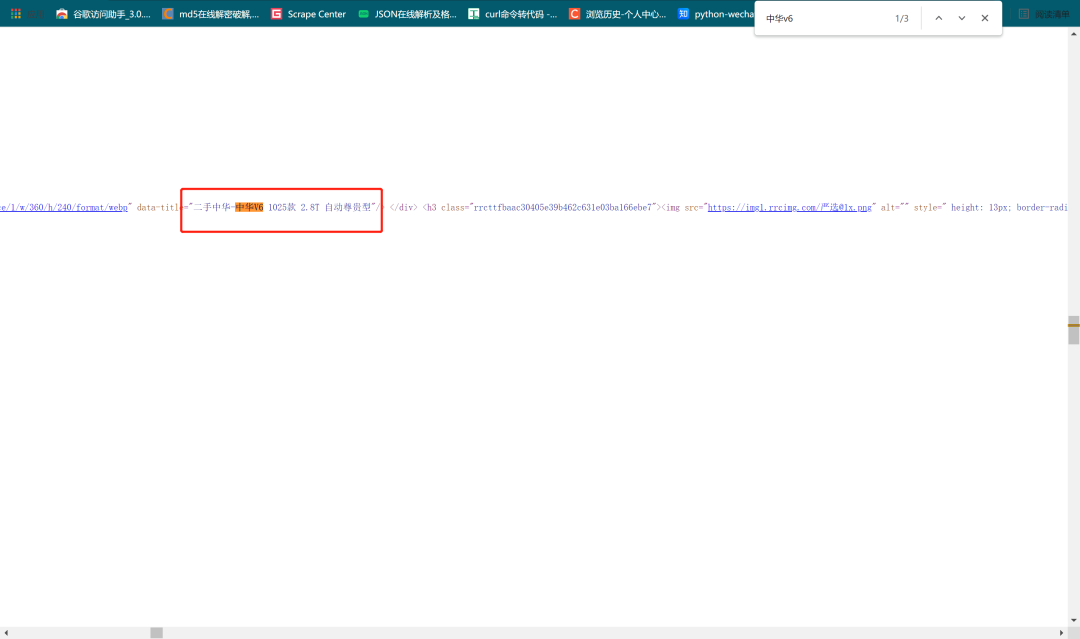
发现车辆的信息就在网页源代码里,同时也发现网页有字体反爬,继续在网页源代码里搜索网页字体的URL。

根据每辆车详情页面的分析,还要拿到每辆车的data-car-id。

1.2车辆详情页面分析
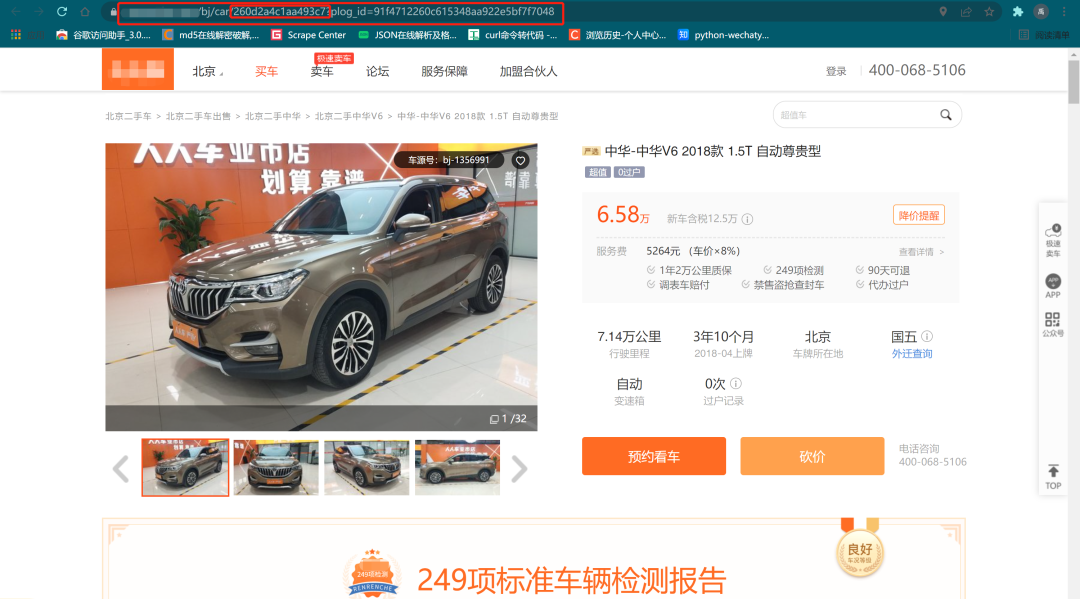
可以看到网页的URL地址拼接了车辆的data-car-id,同样后面的plog_id也可以省略。

同样所有的数据也都在网页源代码里,同样也有字体文件的URL。
1.3实施步骤
请求字体URL,手动建立对应关系 这里请求过程很简单,用requests的get方法就可以拿到文件,打开后观察字体的对应关系。

手动建立对应关系字典(根据观察,这个网站每天会更换一次字体对应关系,还没有瓜子那么BT)
# 字体对应关系
relation_table = {"zero": "0", "one": "2", "two": "1", "four": "3", "three": "4", "five": "8", "seven": "7",
"nine": "9", "six": "6", "eight": "5"}
请求列表页面,拿到车辆的data-car-id
def get_carid(index):
'''获取车辆id'''
response = session.get(f'https://www.renrenche.com/bj/ershouche/p{index}/', headers=headers)
html = etree.HTML(response.text)
car_id = html.xpath('//*[@id="search_list_wrapper"]/div/div/div[1]/ul/li/a/@data-car-id') # 获取车辆id列表
return car_id
需要注意的是,返回的car_id是一个列表。
处理字体,获取真实的对应关系,方便后续替换
def woff_font(font_url):
'''获取字体真实对应关系'''
newmap = {}
resp = session.get(font_url) # 请求字体链接
woff_data = BytesIO(resp.content)
font = TTFont(woff_data) # 读取woff数据
cmap = font.getBestCmap() # 获取xml文件字体对应关系
font.close()
for k, v in cmap.items():
value = v
key = str(k - 48) # 获取真实的key
try:
get_real_data = relation_table[value]
except:
get_real_data = ''
if get_real_data != '':
newmap[key] = get_real_data # 将字体真实结果对应
return newmap
请求每辆车的详情页面,拿到所有数据,并写入csv文件
def get_data(url):
'''提取数据'''
resp = session.get(url, headers=headers)
html = etree.HTML(resp.text)
font_text = "".join(html.xpath('/html/head/style[2]/text()')).strip() # 获取字体链接
font_url = re.search(r"https.*?woff", font_text).group()
font = woff_font(font_url)
title = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[1]/h1/text()')).strip() # 获取原始标题
trans_title = "".join([i if not i.isdigit() else font[i] for i in title]) # 替换错误字体,获取真实标题
mil = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[4]/ul/li[1]/div/p[1]/strong/text()')) # 获取原始行驶里程
trans_mil = "".join([i if not i.isdigit() else font[i] for i in mil]) # 获取真实行驶里程
lice_time = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[9]/span[2]/text()')).strip() # 获取上牌时间
emi_level = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[4]/ul/li[4]/div/p[1]/strong/text()')).strip() # 获取排放等级
trans = "".join(html.xpath('//*[@id="basic-parms"]//tr[3]/td[2]/div[2]/text()')).strip() # 获取变速箱形式
c_name = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[4]/ul/li[6]/p[1]/strong/text()')).strip() # 获取过户次数
colo = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[6]/span[2]/text()')).strip() # 获取车身颜色
fu_type = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[13]/span[2]/text()')).strip() # 获取燃料类型
out_time = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[11]/span[2]/text()')).strip() # 获取出厂日期
model = "".join(html.xpath('//*[@id="basic-parms"]//tr[2]/td[1]/div[2]/text()')).strip() # 获取车型
engine = "".join(html.xpath('//*[@id="engine"]//tr[2]/td[1]/div[2]/text()')).strip() # 获取发动机
struc = "".join(html.xpath('//*[@id="basic-parms"]//tr[4]/td[2]/div[2]/text()')).strip() # 获取车身结构
guid_price = "".join(html.xpath('//*[@id="zhimaicar-no-discount"]/div[1]/span/text()')).strip() # 获取指导价
price = "".join(html.xpath('//*[@id="zhimaicar-no-discount"]/p/text()')).strip() # 获取售价
if len(trans_title) != 0 and len(lice_time) == 10 and len(out_time) == 10:
print(trans_title, trans_mil, lice_time, emi_level, trans, c_name, colo, fu_type, out_time, model, engine, struc, guid_price, price)
csv_writer.writerow([trans_title, trans_mil, lice_time, emi_level, trans, c_name, colo, fu_type, out_time, model, engine, struc, guid_price, price]) # 写入csv文件
通过对请求后的数据分析,由于网页结构差异,有些返回的数据是空,容易导致写入错误数据,为了方便后期处理,加了判断。同时这里需要注意,Chrome浏览器tbody的坑。
1.4爬虫部分全部代码
from lxml import etree
import requests
import re
from fontTools.ttLib import TTFont
from io import BytesIO
from multiprocessing import Queue
from concurrent.futures import ThreadPoolExecutor
import csv
queue_list = Queue()
session = requests.session()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
'Referer': 'https://www.renrenche.com/bj/ershouche/?plog_id=3978670bd754fae06b75b0bc33540592',
}
# 字体对应关系
relation_table = {"zero": "0", "one": "2", "two": "1", "four": "3", "three": "4", "five": "8", "seven": "7",
"nine": "9", "six": "6", "eight": "5"}
def get_carid(index):
'''获取车辆id'''
response = session.get(f'https://www.renrenche.com/bj/ershouche/p{index}/', headers=headers)
html = etree.HTML(response.text)
car_id = html.xpath('//*[@id="search_list_wrapper"]/div/div/div[1]/ul/li/a/@data-car-id') # 获取车辆id列表
return car_id
def woff_font(font_url):
'''获取字体真实对应关系'''
newmap = {}
resp = session.get(font_url) # 请求字体链接
woff_data = BytesIO(resp.content)
font = TTFont(woff_data) # 读取woff数据
cmap = font.getBestCmap() # 获取xml文件字体对应关系
font.close()
for k, v in cmap.items():
value = v
key = str(k - 48) # 获取真实的key
try:
get_real_data = relation_table[value]
except:
get_real_data = ''
if get_real_data != '':
newmap[key] = get_real_data # 将字体真实结果对应
return newmap
def get_data(url):
'''提取数据'''
resp = session.get(url, headers=headers)
html = etree.HTML(resp.text)
font_text = "".join(html.xpath('/html/head/style[2]/text()')).strip() # 获取字体链接
font_url = re.search(r"https.*?woff", font_text).group()
font = woff_font(font_url)
title = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[1]/h1/text()')).strip() # 获取原始标题
trans_title = "".join([i if not i.isdigit() else font[i] for i in title]) # 替换错误字体,获取真实标题
mil = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[4]/ul/li[1]/div/p[1]/strong/text()')) # 获取原始行驶里程
trans_mil = "".join([i if not i.isdigit() else font[i] for i in mil]) # 获取真实行驶里程
lice_time = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[9]/span[2]/text()')).strip() # 获取上牌时间
emi_level = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[4]/ul/li[4]/div/p[1]/strong/text()')).strip() # 获取排放等级
trans = "".join(html.xpath('//*[@id="basic-parms"]//tr[3]/td[2]/div[2]/text()')).strip() # 获取变速箱形式
c_name = "".join(html.xpath('//*[@id="zhimaicar-detail-header-right"]/div[4]/ul/li[6]/p[1]/strong/text()')).strip() # 获取过户次数
colo = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[6]/span[2]/text()')).strip() # 获取车身颜色
fu_type = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[13]/span[2]/text()')).strip() # 获取燃料类型
out_time = "".join(html.xpath('//*[@id="report"]/div/div[3]/div[2]/ul/li[11]/span[2]/text()')).strip() # 获取出厂日期
model = "".join(html.xpath('//*[@id="basic-parms"]//tr[2]/td[1]/div[2]/text()')).strip() # 获取车型
engine = "".join(html.xpath('//*[@id="engine"]//tr[2]/td[1]/div[2]/text()')).strip() # 获取发动机
struc = "".join(html.xpath('//*[@id="basic-parms"]//tr[4]/td[2]/div[2]/text()')).strip() # 获取车身结构
guid_price = "".join(html.xpath('//*[@id="zhimaicar-no-discount"]/div[1]/span/text()')).strip() # 获取指导价
price = "".join(html.xpath('//*[@id="zhimaicar-no-discount"]/p/text()')).strip() # 获取售价
if len(trans_title) != 0 and len(lice_time) == 10 and len(out_time) == 10:
print(trans_title, trans_mil, lice_time, emi_level, trans, c_name, colo, fu_type, out_time, model, engine, struc, guid_price, price)
csv_writer.writerow([trans_title, trans_mil, lice_time, emi_level, trans, c_name, colo, fu_type, out_time, model, engine, struc, guid_price, price]) # 写入csv文件
if __name__ == '__main__':
f = open('renrenche1.csv', 'w', encoding='utf-8', newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(['车型', '行驶里程', '上牌时间', '排放等级', '变速箱形式', '过户次数', '车身颜色', '燃料类型', '出厂日期', '车型', '发动机型号', '车身结构', '新车含税价', '到手价'])
for i in range(1, 51):
car_id = get_carid(i)
for id in car_id:
car_url = f"https://www.*********.com/bj/car/{id}"
queue_list.put(car_url) # get_data(car_url,font)
pool = ThreadPoolExecutor(max_workers=30)
while queue_list.qsize() > 0:
pool.submit(get_data, queue_list.get())
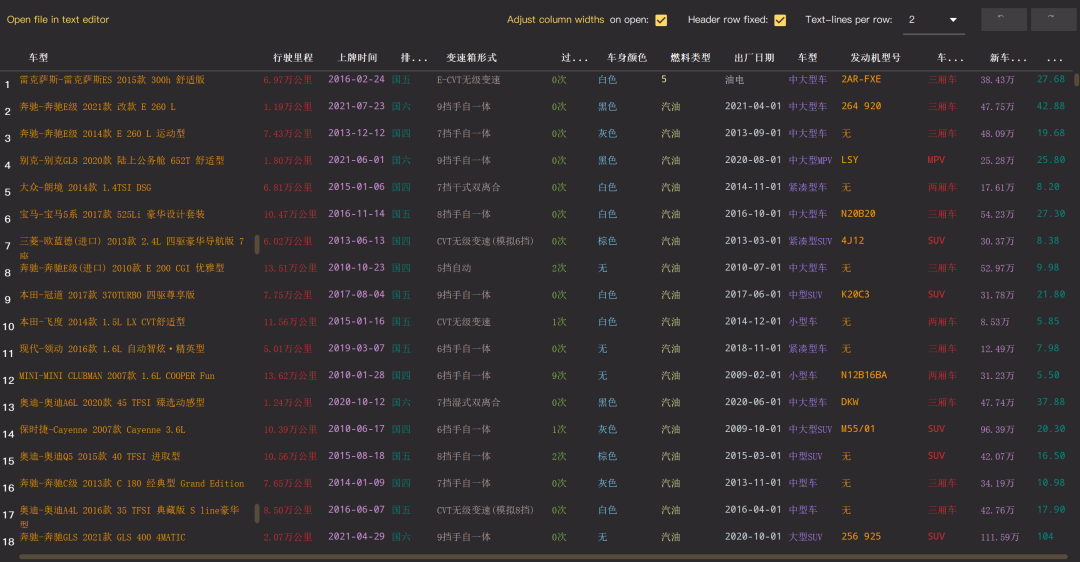
1.5获取的文件
2.简单的数据分析
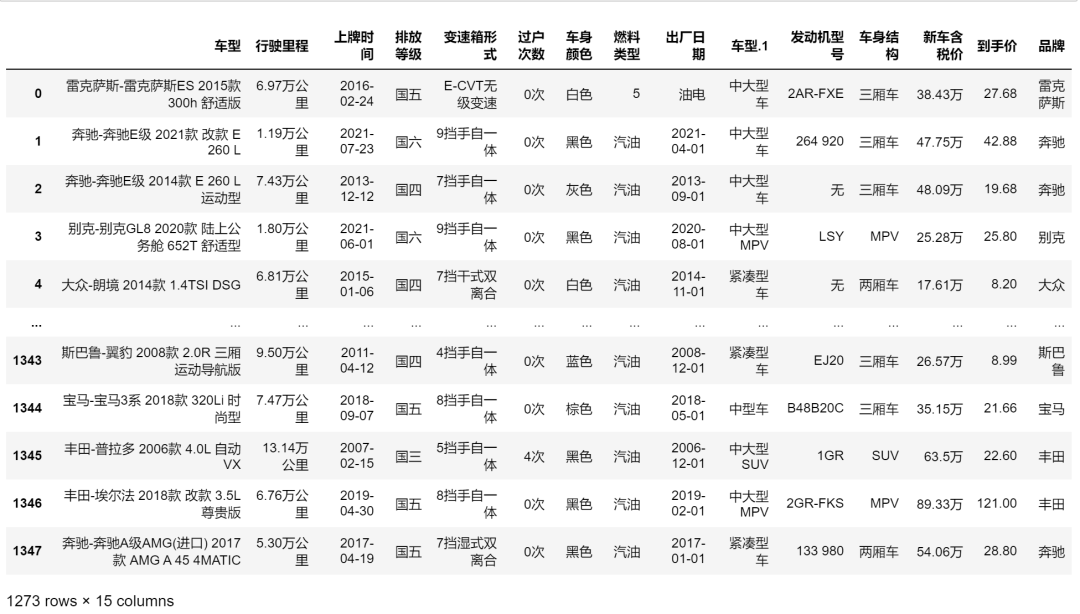
2.1数据清洗
# 新增品牌列
df["品牌"] = df["车型"].apply(lambda x : x.split("-")[0])
df.duplicated().value_counts() # 查找重复数据
#False 1330
#True 18
#dtype: int64
df.drop_duplicates(inplace=True) # 删除重复数据
df.duplicated().value_counts() # 检查重复数据
#False 1330
#dtype: int64
df.dropna(axis=0,how="any",inplace=True) # 删除重复值
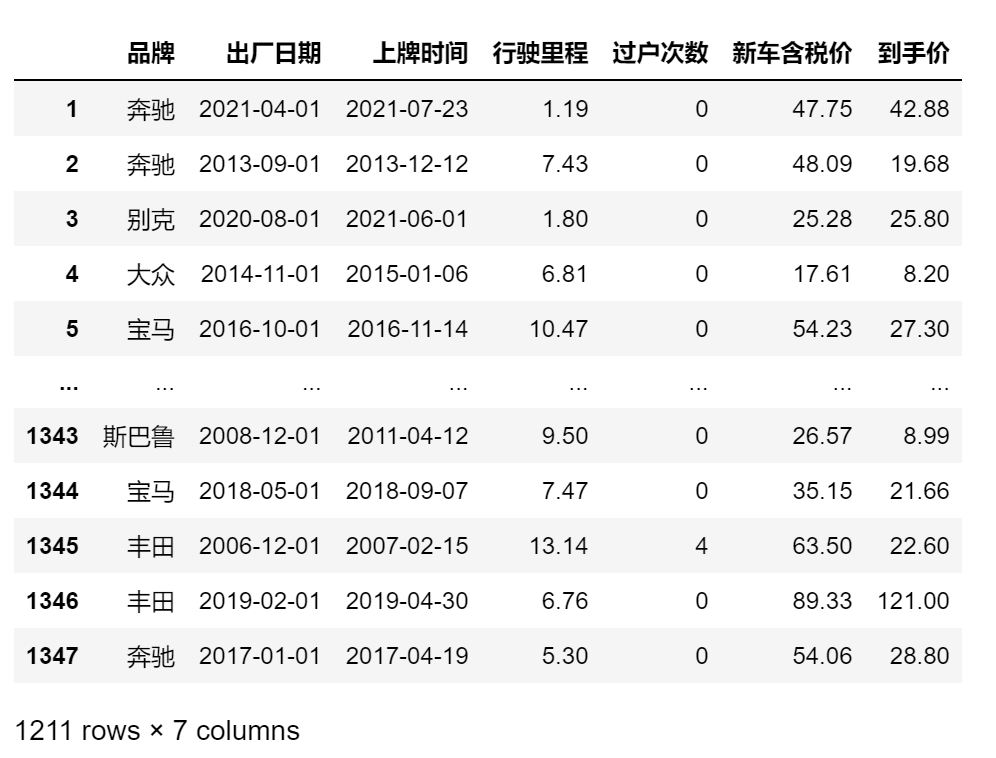
2.2选择数据,并进行数据处理
df_new = df[['品牌','出厂日期','上牌时间','行驶里程','过户次数','新车含税价','到手价']]
# 清理出厂日期和上牌时间列的异常值
time1 = df_new['出厂日期'].map(lambda x : len(x)==10)
time2 = df_new['上牌时间'].map(lambda x : len(x)==10)
df_1 = df_new[time1&time2]
# 转换行驶里程等列的数据格式
df_1.loc[:,"行驶里程"] = df_1["行驶里程"].map(lambda x : float(x.replace("万公里","")))
df_1.loc[:,"过户次数"] = df_1["过户次数"].map(lambda x : int(x.replace("次","")))
df_1.loc[:,"新车含税价"] = df_1["新车含税价"].map(lambda x : float(x.replace("万","")))
df_1['出厂日期'] = pd.to_datetime(df_1['出厂日期'])
df_1['上牌时间'] = pd.to_datetime(df_1['上牌时间'])
2.3数据分析
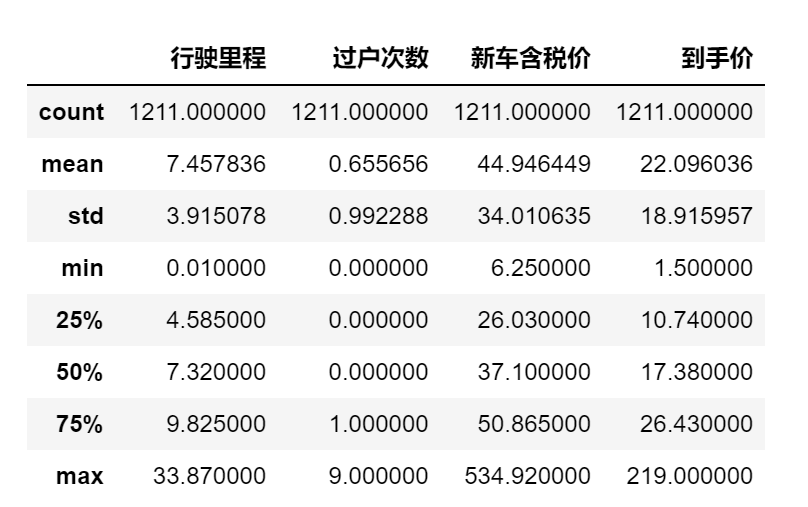
Describe
df_1.describe()
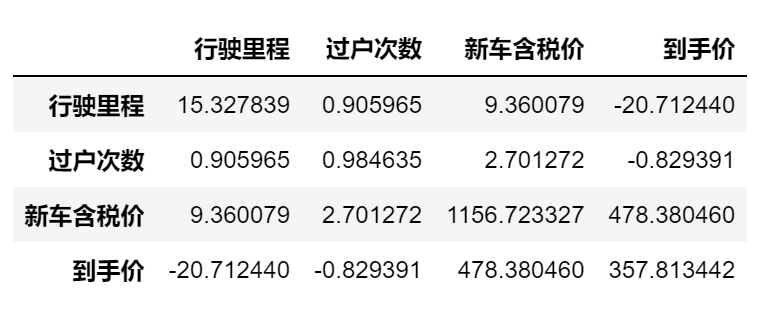
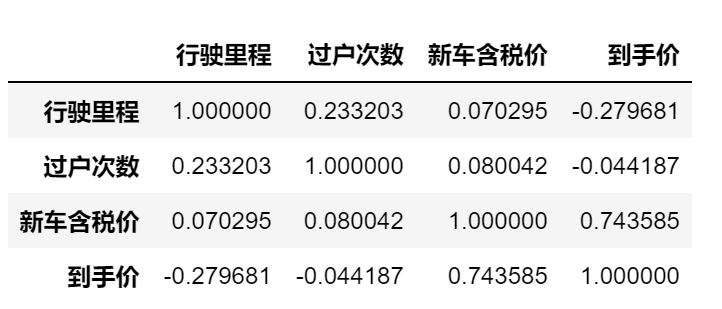
协方差矩阵和相关系数矩阵
df_1.cov() # 协方差矩阵
df_1.corr() # 相关系数矩阵
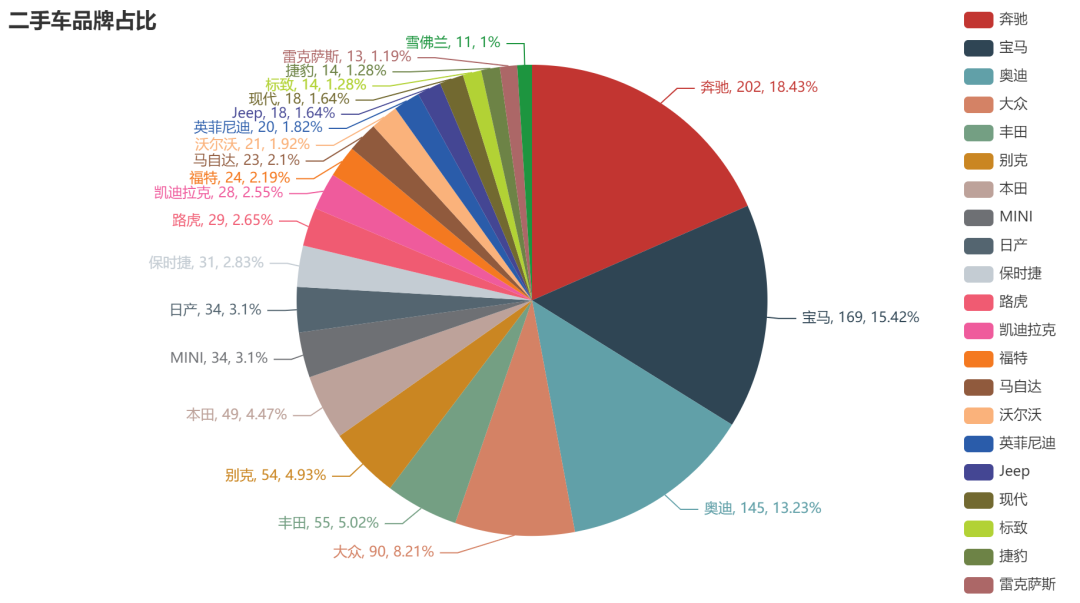
品牌占比分析
p_num = df_1["品牌"].value_counts()
p_num = p_num[p_num.values>10] # 选择数量大于10的品牌
from pyecharts import options as opts
from pyecharts.charts import Pie
datas = list(zip(p_num.index.to_list(), p_num.to_list()))
pie = Pie()
pie.add("",
datas,
radius=[0,200],)
pie.set_global_opts(
title_opts= opts.TitleOpts(title="二手车品牌占比"),
legend_opts = opts.LegendOpts(pos_right="right")
)
pie.set_series_opts(label_opts= opts.LabelOpts(formatter="{b}, {c}, {d}%"))
pie.render_notebook()
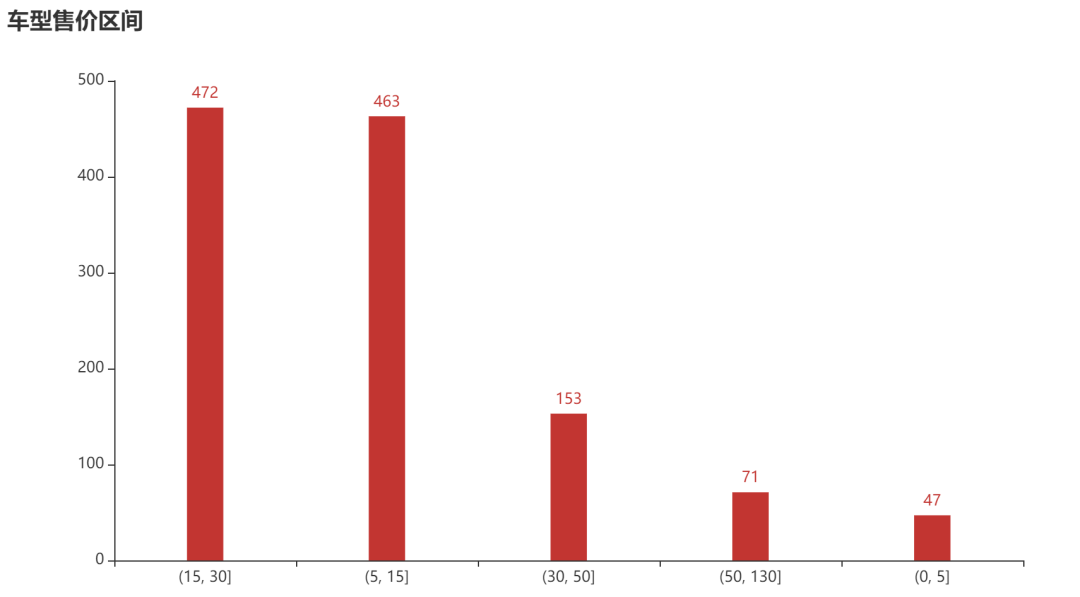
价格分析
bins = [0,5,15,30,50,130]
s_bar = pd.cut(df_1.到手价,bins).value_counts()
from pyecharts.charts import Bar
x_num = [str(i) for i in s_bar.index]
bar=(
Bar()
.add_xaxis(x_num)
.add_yaxis(
"",
s_bar.values.tolist(),
bar_width='20%',
)
.set_global_opts(
title_opts=opts.TitleOpts(title="车型售价区间"),
datazoom_opts=opts.DataZoomOpts(type_="inside")
)
)
bar.render_notebook()
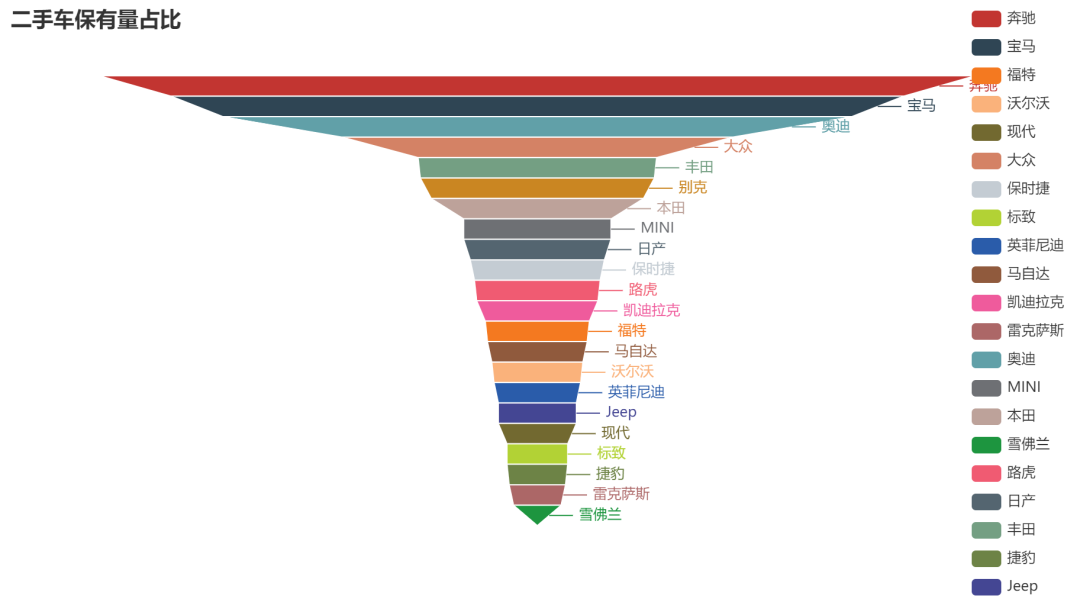
半成品漏斗图
from pyecharts.charts import Funnel
funnel = Funnel()
funnel.add("", datas)
funnel.set_global_opts(
title_opts= opts.TitleOpts(title="二手车保有量占比"),
legend_opts = opts.LegendOpts(pos_right="right")
)
funnel.render_notebook()
推荐蚂蚁老师的全套Python课程
先保存图片,然后抖音打开扫码购买,提供代码、课件、答疑服务

评论