
[CVPR 2021] 融合文本检测与相似度学习的场景文本检索
共 3932字,需浏览 8分钟
·
2021-04-29 14:27
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文简要介绍CVPR 2021录用论文“Scene Text Retrieval via Joint Text Detection and Similarity Learning”的主要工作。场景文本检索的目的是定位和搜索图像库中与给定查询文本相同或相似的所有文本实例图像。作者建立了一个端到端的可训练网络,共同优化了场景文本检测和跨模态相似性学习的过程,通过对检测到的文本实例的相似度进行排序来进行场景文本检索。数据集和代码将开源:https://github.com/lanfeng4659/STR-TDSL。

一、研究背景
场景文本检索[1]旨在从自然图像集合中搜索所有与给定的文本相同或相似的文本实例。与自然场景文本检测与识别不同,场景文本检索仅查找用户给出的感兴趣文本对应的图像。如图1所示,场景文本检索的目标是返回所有可能包含查询文本的图像及其边界框。从这个意义上讲,场景文本检索是一种跨模式检索/匹配任务,目的是缩小查询文本与每个文本图像之间的语义鸿沟。
二、方法原理简述
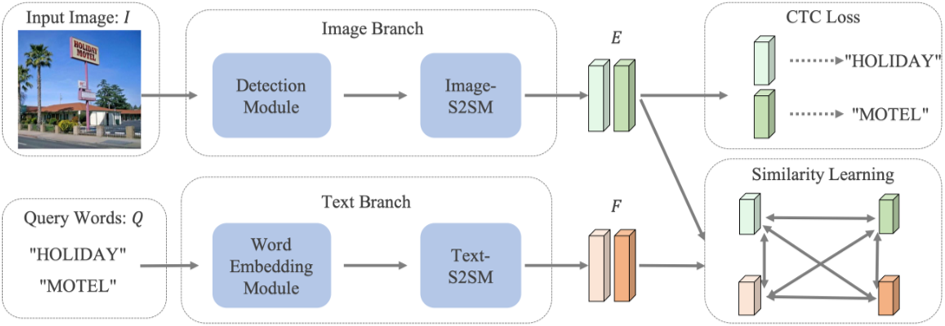 图2 网络整体框架图
图2 网络整体框架图
图2是这篇文章提出网络的整体结构,包括了图像分支和文本分支。图像分支提取所有可能的文本候选图片的特征E,文本分支将查询词Q转换为特征F。接着计算E和F的配对相似度并进行排序。
为了简化检测流程,文本检测模块(Detection Module)采用了[2]中提出的Anchor-free检测器,使用ResNet-50+FPN作为主干网络。与一般需要检测的目标不同,场景文本通常以字符序列的形式出现。因此,采用了一种序列到序列模块(Image-S2SM)用于增强每个文本候选框的内容信息,具体结构在表1中详细说明。
表1 Image-S2SM 和 Text-S2SM的结构
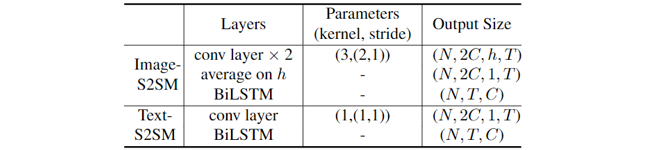
与图像不同,查询词是无法由神经网络直接处理的一组文本字符串。因此,采用词嵌入模块(Word Embedding Module)将查询词表达为特征。与Image-S2SM类似,同样嵌入后的文本特征经过了一个序列到序列模块(Text-S2SM),其具体结构在表1中详细说明。
在提取出文本候选图像和查询词的特征E和F之后,查询词Q与文本候选图像P的特征之间的配对相似度可以表示为相似度矩阵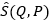 。在此,
。在此,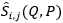 的值等于特征
的值等于特征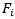 和
和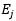 之间的余弦相似度,即通过下式计算:
之间的余弦相似度,即通过下式计算:
其中,V代表将二维矩阵变形到一维的操作。
在训练过程中,预测的相似度矩阵由目标相似度矩阵监督。每一个目标相似度矩阵S(Q,P)是对应词对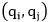 的归一化编辑距离,如下式定义:
的归一化编辑距离,如下式定义:
其中Distance是Levenshtein编辑距离[3],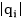 代表
代表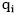 的字符个数。
的字符个数。
除了之外,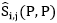 和
和 也被用于辅助训练。
也被用于辅助训练。
在推理阶段,和输入图像特征的相似度被用来进行排序。
损失函数包含三部分:
其中,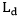 是[2]中的检测Loss。
是[2]中的检测Loss。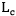 是文本转译任务的CTC[4] Loss。
是文本转译任务的CTC[4] Loss。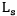 是跨模态相似学习的Loss,并使用Smooth-L1 Loss
是跨模态相似学习的Loss,并使用Smooth-L1 Loss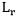 做回归。损失函数被定义为:
做回归。损失函数被定义为:
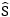 和S是预测相似度矩阵及其对应的目标相似度矩阵。2N和K分别是增广后的查询词数和文本实例数。
和S是预测相似度矩阵及其对应的目标相似度矩阵。2N和K分别是增广后的查询词数和文本实例数。三、主要实验结果及可视化结果
 图3 在STR数据集上检索关键词“Coffee”
图3 在STR数据集上检索关键词“Coffee”
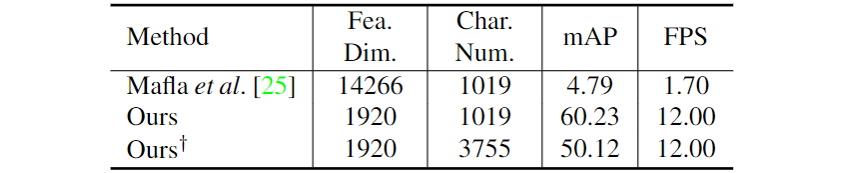
表2 在不同数据集上与不同方法的mAP指标对比
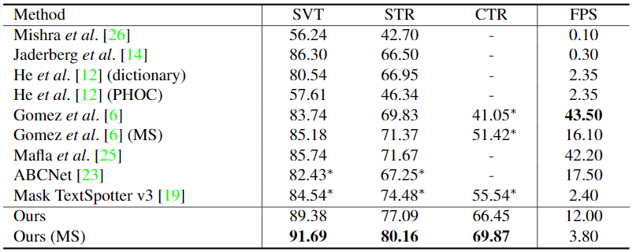
图3展示在STR数据集上检索关键词“Coffee”后的8个结果。表1通过在SVT(Street View Text)[5]、STR(Scene Text Retrieval)[1]、CTR(Coco-Text Retrieval)[6]数据集上与其他先进的方法进行对比,证明了本文提出方法的优越性。

图4 CSVTR数据集的样例
除此之外,作者还提出了一个中文街景文本检索数据集CSVTR(Chinese Street View Text Retrieval),如图4所示。
表3 在中文街景文本检索数据集CSVTR上的对比实验结果
四、总结及讨论
五、相关资源
论文原文下载地址:
https://arxiv.org/abs/2104.01552
本文开源代码及中文街景文本检索数据集CSVTR下载地址(尚未更新): https://github.com/lanfeng4659/STR-TDSL
SVT(Street View Text)数据集下载地址:
http://vision.ucsd.edu/~kai/svt/
参考文献
[2] David Aldavert, Marçal Rusiñol, Ricardo Toledo, and Josep Lladós. Integrating visual and textual cues for query-by-string word spotting. In ICDAR, 2013.
[3] Ladimir Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet physics doklady, volume 10, pages 707-710, 1966
[4] Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. InICML, 2006.
[5] Kai Wang, Boris Babenko, and Serge J. Belongie. End-to-end scene text recognition. In ICCV, 2011.
[6] Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, and Serge Belongie. Coco-text: Dataset and benchmark for text detection and recognition in natural images. arXiv preprint arXiv:1601.07140, 2016.
原文作者: Hao Wang, Xiang Bai, Mingkun Yang, Shenggao Zhu, Jing Wang, Wenyu Liu
审校:连宙辉
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看