
执行count(1)、count(*) 与 count(列名) 到底有什么区别?

阅读本文大概需要 2.8 分钟。
来自:BigoSprite blog.csdn.net/iFuMI/article/details/77920767
1. count(1) and count(*)
从执行计划来看,count(1)和count(*)的效果是一样的。
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多!
当数据量在1W以内时,count(1)会比count(*)的用时少些,不过也差不了多少。
如果count(1)是聚集索引时,那肯定是count(1)快,但是差的很小。
因为count(*),会自动优化指定到那一个字段。所以没必要去count(1),使用count(*),sql会帮你完成优化的
因此:在有聚集索引时count(1)和count(*)基本没有差别!
2. count(1) and count(字段)
两者的主要区别是
count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。 即不统计字段为null 的记录。
3. count(*) 和 count(1)和count(列名)区别
执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略为NULL的值。 count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略为NULL的值。 count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是指空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快 列名不为主键,count(1)会比count(列名)快 如果表多个列并且没有主键,则 count(1 的执行效率优于 count(*) 如果有主键,则 select count(主键)的执行效率是最优的 如果表只有一个字段,则 select count(*)最优。
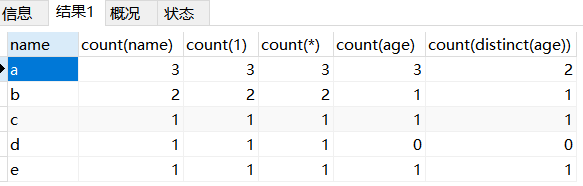
实例分析
create table counttest
(name char(1),
age char(2));
insert into counttest values
('a', '14'),
('a', '15'),
('a', '15'),
('b', NULL),
('b', '16'),
('c', '17'),
('d', null),
('e', '');
select name,
count(name),
count(1),
count(*),
count(age),
count(distinct(age))
from counttest
group by name;
结果如下:
推荐阅读:
当字节跳动在美国输出中国式996...|
记一次找因redis使用不当导致应用卡死bug的过程
互联网初中高级大厂面试题(9个G) 内容包含Java基础、JavaWeb、MySQL性能优化、JVM、锁、百万并发、消息队列、高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper......等技术栈!
⬇戳阅读原文领取! 朕已阅
