
大模型&ChatGPT对计算机视觉的影响
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
夕小瑶科技说 分享
来源 | CCF计算机视觉专委会
引言 随着ChatGPT热潮袭来,大模型如何在计算机视觉里发挥重要作用、如何应用大模型服务各种视觉任务、如何借助海量数据突破算法性能上界等一系列问题,成为学术界与产业界共同关注的热点。为此,RACV2023组织了“大模型与ChatGPT对计算机视觉影响”的专题研讨会,邀请相关领域的专家学者,共同对大模型及视觉未来的发展趋势、亟待解决的科学技术问题等做了充分的交流与讨论。
专题组织者:王井东、王兴刚、李弘扬
讨论时间:2023年7月24日
引导发言:陈熙霖、沈春华、代季峰、谢凌曦
参与讨论嘉宾(按发言顺序):卢湖川、王兴刚、山世光、王菡子、魏云超、林倞、黄高、王涛、胡事民、徐凯、谢凌曦、操晓春、吴小俊、陈宝权、金连文、查红彬、肖斌、毋立芳、刘静、代季峰、汤进、吴保元
文字整理:李弘扬、汪邦骏
校审发布:杨巨峰
本文得到CCF-CV专委会(公众号: CCF计算机视觉专委会)授权发布
主讲嘉宾发言实录
1.陈熙霖(中国科学院计算技术研究所)

我是第二次来RACV,想起一首歌叫‘笨小孩’,说的是 60 后,大概就是我们这一代人,所以有些事因为“笨”而想不清楚。今天借这个机会,向大家请教,集大家的智慧一起讨论。
查老师说我这个题目偷懒。为什么懒?前面加了个‘关于’,后面加了个‘思考’。先讲讲计算机视觉,这些年我们看到了一些喜忧参半的事情。为什么叫喜忧参半呢?
一方面大家看到文章很多,但另外一方面,回过头来看计算机视觉领域这些年到底在做什么?研究的问题被不断碎片化。我们这个领域的好处是开放开源,进入的门槛似乎很低。另一个是常常围绕榜单任务进行,到底为什么要做?有时候你问学生,学生讲因为有人做,因为有这么一个数据集,因为有这种测试,这实际上是一个不好的趋势。

但是现在我们看到一些新的变化,例如SAM。我不知道有多少人真正用它去跑了一些实验结果。如果你真正用它测试,结果可能不太一样。假期学生帮我跑了不少结果,每次我都能看到一些不一样的结果,其实远没有我们想象的这么好,甚至于一些做合成的大模型也没有那么好,但是它提供了一件可能。
本质上 SAM 提供的任意分割,是一个多尺度的分割,因为分割永远是具有逻辑含义的任务。而不是一个物理含义的任务,它提供了将碎片化任务收敛的机会。当然现在也有一些学者试图用类似于 ChatGPT 的方式把视觉任务都统一起来,但视觉任务到底能不能统一,这件事情值得思考。也有人说大模型来了以后是不是我们的研究就终结了?包括 SAM、CLIP等对我们领域的影响是终结性的?《三体》里有一句话“物理学好像不存在了”。是不是我们的领域也不存在了?

这里提出十个与大家共同思考的问题。第一个就是现在的大模型,多大算大?我回想起当年讲大数据的一句话,什么叫大数据?超越当前设备处理能力上限的数据才叫大数据,我非常认可这个观点,今天我们的大模型是否也是这样。一个million参数,一个billion参数,还是10个billion参数,所以到底多大算大模型?我们今天在视觉领域所谈的大模型,到底是大模型还是‘大的模型’?我个人认为是‘大的模型’,因为预训练往往是针对少数任务的,我们现在讲的大模型,因为它把多个任务能够同时完成,或者找到了一个核心的任务,比如我们的姊妹领域语音识别,任务就相对统一。
我们今天讲的问题本质上遇到的困惑,大模型改变了没?如果大模型没改变,那大模型还能走多远?或者说大模型是不是在维数灾难发生以前就解决了问题?我们知道造房子无限制地加高,早晚是会倒的,如果只需要造一个 100 层的房子,会不会倒?大模型同样,是不是我们可以在维度灾难超越承受之重之前,已经能够完成我们的任务?
第三个问题,就是大模型复杂度的问题,复杂性和蛮力究竟谁先到边界?如果依靠蛮力已经到达问题的边界了,复杂性就不是问题。我们做100个数的排序,没有人会考虑排序算法的复杂度,但是如果对网络上的海量数据进行排序就要考虑了。
所以复杂性和蛮力究竟谁先到边界,我个人对模型复杂度的考虑:第一个是用算法的复杂程度来度量,第二个是需要的养成数据的规模。什么叫养成数据?养成数据主导了大多数大模型的性能,所以今天复现大模型,就算法本身已经几乎是公开的,但养成数据的规模和性能到底是什么关系,我觉得是要考虑的。
模型的成熟程度,什么时候模型能用?我定义了一个衡量模型成熟度的量--算力除以模型的复杂程度。如果成熟程度达到一定级别就可以走向规模应用,我分了四级,分别称为思考级、研究级、产业级、个人用户级。当模型成熟很低的时候只有研究者认识到它的价值,当它到了一定程度以后,学术界可以用,再到一定程度如今天的大模型,工业界就可以用,如果算力再往前涨一个数量级或两个数量级,也许可以很方便地普及到个人设备上。
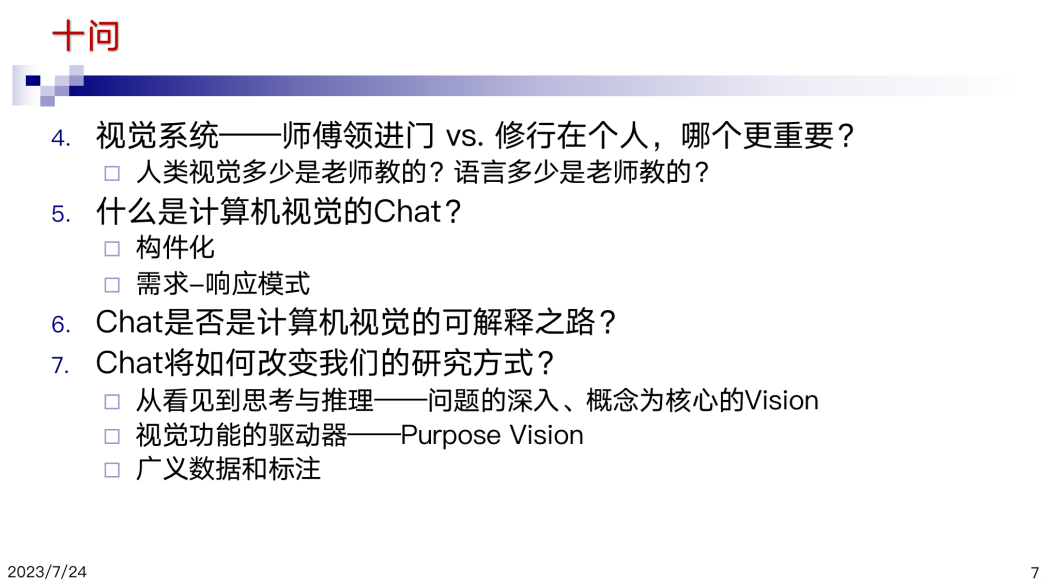
视觉和语言模型,我个人认为是不一样的,不能完全拿语言模型过来对比。语言是我们生下来以后被人教了很久才会的,可是我们的视觉是生下来睁眼即会。在这个意义上来讲,人类视觉有多少是靠师傅领进门的,应该基本还是靠自己学习的。而语言系统是反过来的。视觉任务到底是什么?如果我们仅仅考虑视觉,我一直认为视觉就是动物生存的支撑。
视觉是为生存而生的,只有动物才有视觉,植物不需要。为什么是为了生存?几个基本需求,第一是别让天敌吃了,第二是找到食物,第三不要碰到意外,这都需要视觉能力的支撑。
ChatGPT 核心是chat,那么什么是视觉的chat?在我看来,视觉的chat是一些基本的功能。这些功能是依任务而激活的,依响应而反应,是在一个 loop中的,大多数时候是处于不工作的状态,我们每天看了很多对象都视而不见,但是一旦威胁到生存或者有需求的驱动,我们就会去响应和处理。反过来讲,如果我们盲目地把在语言处理中的一套方法直接拿过来试图解决计算机视觉的问题是不是可以?所以我觉得视觉的“chat”可能是一个构件化的需求-响应模式,它是在一个智能体里,因为某种需要才采取的动作,所以它的基本功能相对很简单。 另外今天我们要的解释其实是基本的chat。一个就是讲 ChatGPT 对我们的改变,这里chat是不是ChatGPT?大概几类问题,一个是能够让我们从看见到思考,就是有了 ChatGPT以后,现在很多研究可以和ChatGPT连接起来。 今天早上林倞讲了一个重要的事情,是怎样形成loop。有了 chat 以后的loop和响应-需求模式本身是一个途径,ChatGPT也是一个loop。再一个就是视觉功能的驱动是什么?80年代末、90年代初就有研究者提出类似的概念—Purpose Vision。Chat的另外一个用途是能够帮助我们做广义的数据和标注,有了chat,就能把这件事情帮我们做得很好。

讨论的第8个问题是关于多模态的。模态之间的协同很重要,但是模态之间要不要有边界?模态的边界在哪里?比如单纯从视觉来讲,现在有时候把视觉任务无限制地扩张。如果从脑或者智能体来讲,扩大是正确的,但如果从视觉而言,边界在哪里?与其他模态之间什么地方是界,什么地方是协同? 因此,我觉得 AI 会有一个体系结构,是 AI 基本能力的界面或AGI的结构支撑。过去做 AI 的研究者大都只是局限在某一特定智能能力方面,今天需要做的智能体,是一个综合体,所以会有一些新的问题和挑战。
关于大模型和ChatGPT,我觉得它是AGI 之光,但是要注意一件事情,现在大模型带来一个最大的改变是什么?我们过去都在比谁把算法做得更精巧。今天的一个趋势,就是从构造越来越复杂的算法,到构造能够容纳复杂能力的算法,通用模型本身会趋向于简单化,只有这样才可能将能力不断放大。
ChatGPT 问世以后,对研究者无疑是一场巨大的冲击,以前的一些问题可能不需要再进行研究了,如同海平面的上升,这些问题已经成了水下的部分了,也可能仅仅是看起来解决了,如同海啸袭来,退潮之后问题还在。对我们来说,ChatGPT带来的到底是海啸还是海平面的上升?这是我们需要思考的问题。谢谢大家。
2.沈春华(浙江大学)
谢谢井东老师的邀请,非常高兴能在这里跟大家分享一下大模型和 ChatGPT 对视觉的影响。实际上有点赶鸭子上架,我不做ChatGPT,也不做大模型,基本上没做过什么大模型,虽然我很想做大模型。我就简单讲一下我的一些理解,我觉得ChatGPT从今年年初开始到现在对于做不管是视觉还是 NLP 还是 speech recognition,有巨大的影响。

一个影响是,通过大数据训练大模型,人们开始认识到这是实现人工通用智能(AGI)可能的一个较为可行的途径。目前我们已经看到在视觉任务方面的一些例子,陈老师也提到,这些都是在这个方向上的发展。如果我们能够通过大数据训练大模型,在图像理解等任务上取得最优结果,那么我们就不再仅仅局限于设计各种新的算法,因为这可能是一个进退维谷的做法。相反地,利用大数据和简单算法来实现最佳性能,可能是一条更为优秀的道路。
在我们视觉圈子里就在说这个:过去二三十年视觉的发展基本上就是数据集带来的发展。从最早的 MNIST 到后面 Pascal VOC 到ImageNet,统治了视觉很多年。2015 年 AlexNet的论文,当时就是 Jupiter 和他的几个学生, Alex 和Suscuva,他们最早是在 Pascal VOC 的数据集上去训神经网络。AlexNet 没有得到好的结果,因为这个数据集太小了。他去用了ImageNet,然后才有了 AlexNet 这篇论文。所以基本上就是数据集带来提升。

在训练大规模的模型时,确实需要足够的算力来处理大规模的数据集。根据一个PPT上的统计数据,从2012年到2018年的6年间,算力提升了30万倍。如果算力继续提升,我们可以预见未来会使用更大的数据集和更大的模型来进行训练。从另一份PPT中的数据也可以看到,在2012年到2018年的时间跨度中,训练模型所需的算力复杂度显著下降,即便与AlphaGo相比,现在的许多模型已经无法达到以前所需的复杂度。
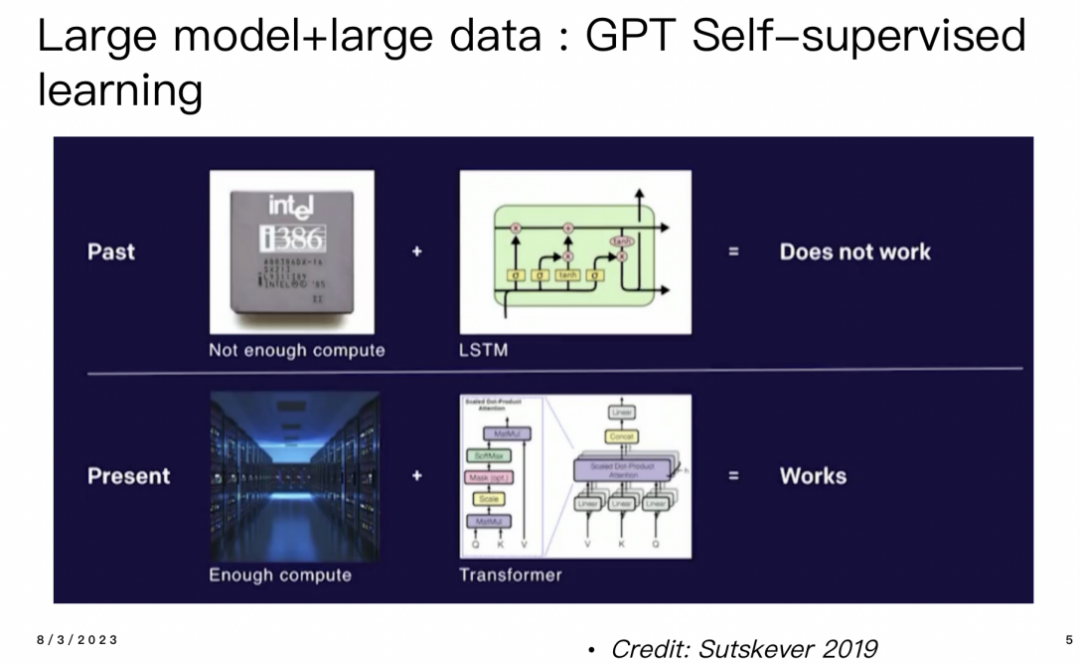
现在,回顾ChatGPT,最早的GPT模型采用了Transformer架构进行自监督学习,其训练方式是预测下一个单词。在早期,GPT的训练受限于算力和Transformer架构相对于LSTM较难并行化的问题,因此很难继续扩展。但是,ChatGPT的成功部分归功于预测下一个单词作为预训练的关键因素。
陈老师之前提到,在NLP中,文本与图像和其他传感器获取的数据最大的区别在于文本本身就是带有标注的,因为文本是可以记录下来的。而图像和其他数据则没有这种自带的标注,因此直接将ChatGPT的方法应用于图像领域是行不通的。图像数据是一种“智能传感器”,它本身不具备内在的语义标注,因此我们无法直接借鉴ChatGPT的方式。

最近实现的一种知识蒸馏的方法,在知识蒸馏的过程中,T球网络用于代表人类的知识,它原本应该去拟合概率分布,但现在由于缺少确切的概率信息,我们可以用一个delta函数来近似概率,从而实现预测下一个单词的目标。

对于视觉领域,与NLP不同的是,视觉问题需要解决多种不同的任务。而与GPT对NLP的广泛适用性不同,对视觉领域的模型来说,并没有一个统一的模型可以胜任所有任务。其中,DINO v2是一个无监督的self-supervised learning模型,它在视觉领域的许多下游任务上表现良好。即使只是将DINO v2的模型固定住,直接将其用于特征提取,再进行encoder和decoder的构建,也能在很多下游任务上表现出色。
第二类模型,像SAM这样的模型被称为任务特定的基础模型,它与特定任务相关。在视觉领域中,像图像校准这样的任务目前可能研究较少,而更重要的是进行像素级的预测,例如分割,以及其他一些任务如3D重建。

第三类模型可能介于两者之间,或者是一种弱监督学习模型。弱监督学习指的是很多像CLIP和captioning这样的模型,这些模型使用图像级别的监督信号来训练,通过图像的描述来完成任务。尽管使用了图像级别的监督信息,但它们实际上学习了像素级别的信息。特别是对于生成模型,其实它是学习像素级别的分布信息。DINO v2的内容我就不再详述,但可以明确的是,它在实验结果中表现非常出色。

SAM是Facebook今年的研究成果,他们使用了1000万张图片进行训练。21年时,我在亚马逊工作了一年,并尝试了一个类似的工作,收集了大约200万张图片并训练了一个SegFormer模型。不过遗憾的是,这个工作投了两年CVPR都被拒绝了,记得分数都是455。 尽管如此,这个工作的结果还是非常好的,尽管没有像SAM那样规模庞大(1000万张图片),并且当时的工作只涉及semantic segmentation,并未像SAM一样做 instance level的Instant segmentation。

在学术领域,我想强调一点,单纯地训练大型模型并不一定能确保论文容易发表。虽然我们的研究结果还不错,我们花了大半年的时间来完成这篇论文,并消耗了很多GPU资源,将它上传到了arXiv。但是,即便结果不错,论文发表也可能面临困难。除了这个,我还想提到另一个项目。我们在3D重建方面的研究,收集了大约1000万张图片。这个项目是由我之前的一个学生进行的。现在,大疆公司拥有GPU资源,他们也在进行类似的研究。尽管这个项目对技术要求很高,但在CVPR 23年投稿时遭到了拒绝,之后我们改进后在ICCV上获得了接收。
无论如何,我想说的是,确实我的方法本身并没有特别大的创新。主要是利用大数据来训练一个较大的模型。但从最后的结果来看,效果确实非常好。此外,我们训练的模型本身并不大,只是训练了一个ConvNeXt模型,并没有用到Transformer。所以,这也强调了大数据的重要性。即使训练一个相对较小的模型,借助大数据,性能也可以做得非常好。另外,第三类方法可以看作是介于unsupervised-learning 和像SAM这样的pixel level的模型之间。这种方法可以将image level的supervision信号用于学习pixel level的信息。

CLIP是一个非常好的例子,它也是OpenAI的研究成果。和ChatGPT之前的做法一样,CLIP的方法也是基于大数据,并将整个架构放在Transformer这样的框架中,类似于NLP里的GPT,采用了类似的sequence to sequence学习方法。因此,这个formulation非常简单,包括像stable AI的生成模型也是如此,整个做法都是非常直接的。

个人而言,我更倾向于第三种方法,即使用image level的注释来训练模型,并希望获得pixel level的信息。因为从理论上来说,这样的方法确实可以学习到pixel level的信息。

在21年,我们进行了dance share的工作,它实际上是一个unsupervised learning,旨在获得良好的pixel wise correspondence。因为许多数据任务最终都需要找到correspondence。今年我们做了一个使用diffusion model的工作,来处理大量生成的图像,并使用算法获得它们的pixel level的annotation。理论上来说,一旦获得大量这样的训练数据,就可以用于训练下游的视觉任务。这里面一个关键的观察是,diffusion mode或其他生成模型需要将像素分配标注出来。

没错,一旦将像素分布出来,理论上就可以获得更好的标注。我个人预测,像DINO v2这样的大规模自监督学习方法,可以在不需要标注数据的情况下训练大型模型,这可能会促使更多的研究工作涌现出来,因为DINO v2本身是非常有用的。但是是否会实现类似于视觉GPT这样的方法,现在还不清楚,也许会有,也许并不一定有必要。像SAM这样的specific 的foundation model,可能会在未来看到更多类似的工作,包括像3D重建、单目深度估计等模型,也可能会公开发布。
当然,我对如何利用weakly supervised learning也很感兴趣。使用 image level的标签来训练一个非常大的模型是一个有挑战的问题,因为训练数据本身缺乏pixel level的信息。但是通过训练,希望可以得到更丰富的像素级信息。
3.代季峰(清华大学)

今天非常高兴来分享我的报告,题目叫做"从感知基石模型到智能体基石模型"。最近大家一直在谈论大模型,但我觉得实际上这个概念应该叫做基石模型。最近,王乃岩也在一个帖子中提到了这个问题。我之前和他参加过一个panel,我们一直在谈论这个话题。实际上,大模型很多时候体现了智能的一种表现形式,它成为了基石模型这一更本质的概念。所谓基石模型,它指的是一个模型能够从海量的互联网数据中学到非常多有用的知识。同时,这个模型具有很强的通用性和泛化性,能够在许多下游任务中应用,并且能够在未见过的数据或任务上得到reasonable的结果。
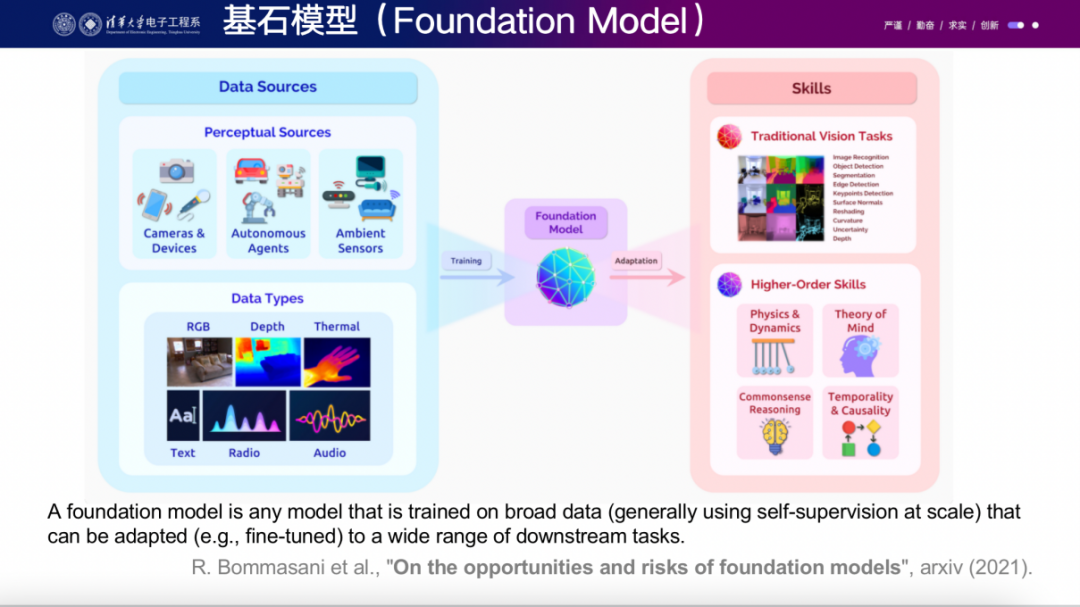
这是foundation model的一个非常重要的特征。不过,我暂时不深入讨论这里面的细节。我觉得21年opportunity and risk foundation models的定义还是相对超前的。举个例子,之前的BERT在预定义的NLP任务上表现非常出色,而后来的GPT系列在相同的对比实验中,在这些预定义任务上的性能可能不如BERT。但是GPT系列的强大之处在于其能够具备通用性,你可以向它问任何问题,这也是它为什么能够受到如此广泛关注的重要原因。
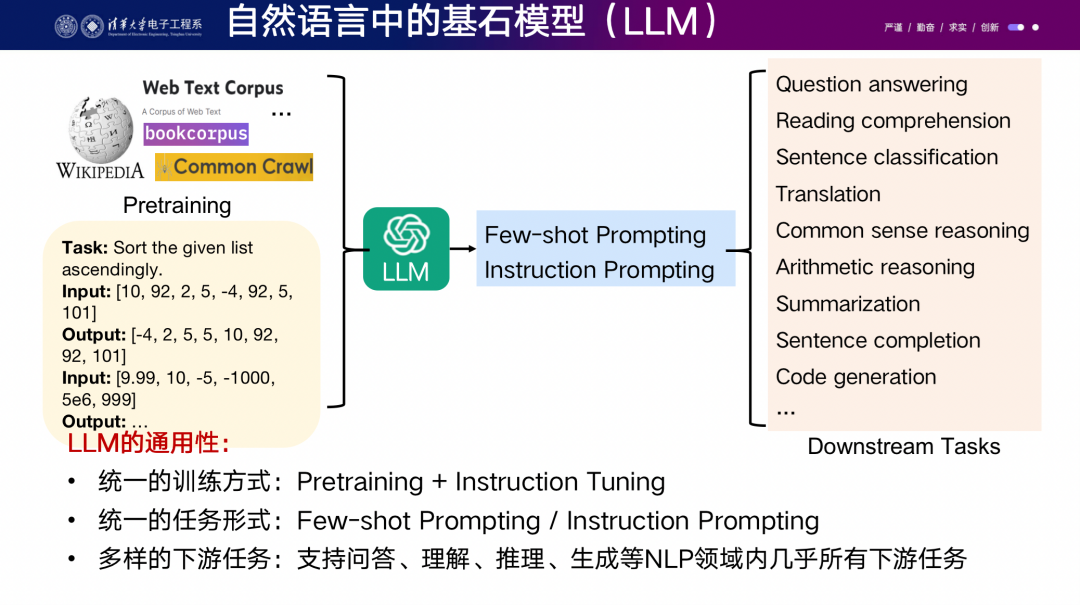
在自然语言领域,我们首先实现了一个目标,带来了巨大的生产力变化。训练一个大型模型的成本非常高,需要成千上万块GPU,比如OpenAI花费了大量资源。去年几十位精英研究员花费了数月时间管理数据标注,需要付高额工资给名校的研究员,这是一笔相当高昂的开支。然而,这样的投入带来的好处在于应用编辑成本非常低。因为当你问ChatGPT任何问题时,后台不需要再花费大量成本去标注新的数据或者训练新的模型,它直接在服务器上推理。
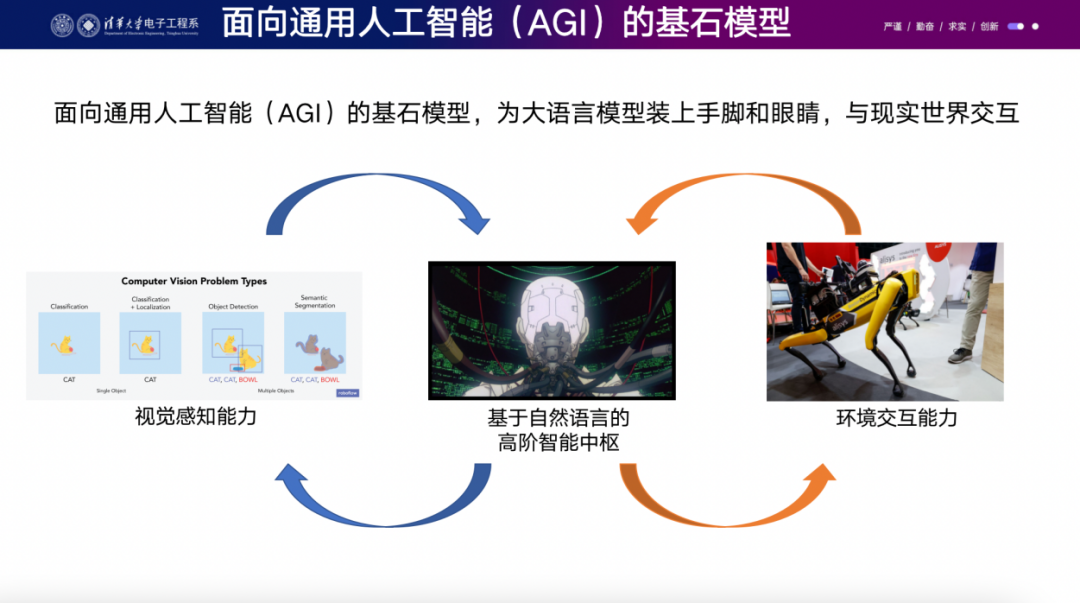
接下来,我们需要思考一下,如果像ChatGPT这样的模型具有通向AGI的潜力,我们如何能够扩大这种能力,将其应用到更多行业中?我们可以把ChatGPT类比为一个关在黑屋子里的聪明人,每次你递给他一张纸条,他会回复几张纸条。我们希望给他加上眼睛,让他看见这个世界,同时给他装上手和脚,让他与环境进行交互。
我可以部分回答之前熙霖老师提出的问题,不过现在时间有限,暂时不做展开。我们希望打造一个具身智能的机器人,让它在现实世界中运行。视觉就像语言一样,而我们的ChatGPT已经在人类所有的文字上实现了一个闭环,你可以训练它去回答任何问题并得到正确的答案,比如你可以问它“TOKEN是什么东西?”然而,在视觉领域,这些任务都是人为定义的特定case,而视觉的最终目标是让机器能够在现实世界中生存。
陈老师刚才总结得非常好,我就不再多说了。我认为大量的supervision信号应该来自与现实世界的交互,但是为了高效地进行实验,我们可以在虚拟环境中进行这些交互。目前计算机视觉还是特定于任务的反向传播,这也是为什么之前的一代AI公司一直在亏损的原因,因为它们的边际成本非常高。

之前的视觉模型,无论设计多少个Backbone网络,我觉得都不能构成所谓的foundation model,因为当应用于下游的任何新任务时,都需要特定于任务的微调和解码器。这导致随着任务数量的增加,模型参数不断增加,无法直接共享处理不同任务的参数。
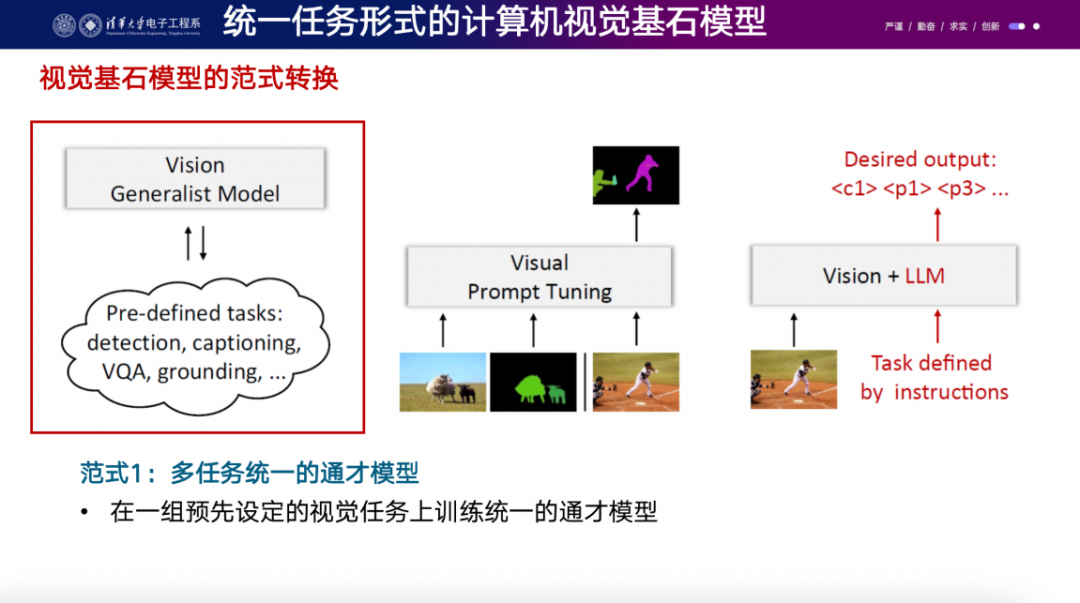
理解视觉的foundation model有很多特点,其中一个是它需要通用的解码器,这样就可以包含各种视觉任务。你可以在一组预先定义的视觉任务上进行训练,但同时也可以在编译的视觉任务上进行训练。然而,如果要处理新的任务,可能仍需要一些人工工作。这些方法可能比ChatGPT之前的方法更早一些,我们也进行了一些尝试。还有一些其他的工作,如软件工作中台、perceiver、reperceiver等,都是比较不错的尝试
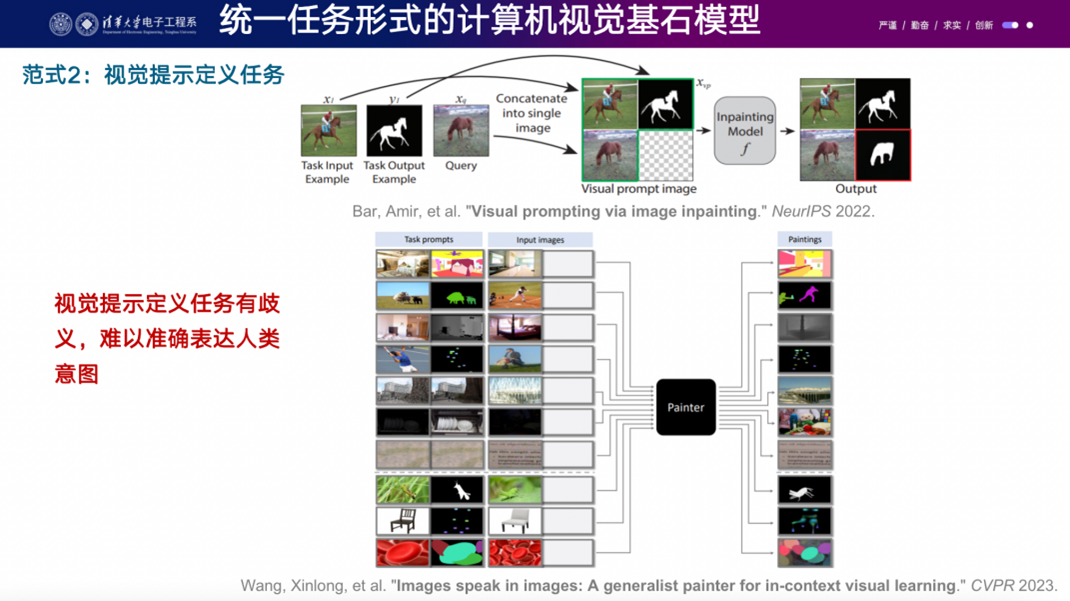
另外一个技术路线是直接将自然语言处理中的prompt engineering方法应用到视觉领域。在自然语言处理中,prompt engineering是一个很好的方法,它解决了不再需要finetune的问题。他们的想法是将这个概念直接复制到视觉领域。比如,训练了一个模型后,给它一个提示,比如一个原始自然图像和羊的分割结果,然后再给它一个新的人的图片,它应该得到足够的提示来分割出人物。这样的方法已经在一些工作中得到了应用,比如谷歌在2022年的visual-prompt image impainting和王鑫龙博士的image speak in image等。但是在当前技术条件下,这条路线仍处于比较早期的阶段,因为我们对视觉建模的能力还不是很清楚。
但是另外一个相对实用一些的技术路线是将大型语言模型和视觉模型进行强耦合。现在我们可以直接用自然语言来定义视觉任务,并用自然语言来输出我们想要的结果。具体而言,我们可以教给一个强大的视觉backbone model这样的主干网络,让它理解我们的任务定义,并用自然语言来描述任务的输入和输出。我们在这个方向上的工作比较多,这个方法被称为"Vision LLM",我们觉得效果还是挺不错的。

现在我们可以通过定义一个强大的视觉backbone模型来处理各种视觉任务,就像以前我们靠object detector或segmentation网络来处理任务一样。现在我们通过自然语言来定义任务,并用自然语言来输出我们想要的结果。这个方法在一些工作中得到了应用。
你可以用自然语言来告诉这个智能体你想让它做什么。比如,你可以告诉它要检测一个小孩在吃什么,用什么坐标系来表达图片,然后它会给你输出一个结果,还可以做一些复杂的推理问题。这种方法在一些实验中得到了应用,非常有趣。
在这个技术路线中,还有一些人尝试同时使用语言和视觉提示来定义任务,以提高任务定义的准确性。在虚拟环境中进行实验可以极大地增强实验效率。
以前的智能体是基于强化学习的,比如Alpha Go、打星际争霸、打dota等。但是当它们面对开放世界的推进时,遇到了巨大的泛化性挑战。比如,玩一个简单的游戏俄罗斯方块,训练好后,如果将整个像素向上移动几个像素,训练出的模型就完全不知道该怎么玩了。这表明在这样的任务中,强化学习面临着一些困难。

我们尝试使用大语言模型来解决这个问题。首先,我们选择了世界上销量最大、最开放的游戏"Minecraft",因为在这个游戏中,玩家可以创造世界、建造城市,甚至创建CPU和存储等。我们的基本想法是将一个大型语言模型放置在虚拟环境中,因为它已经见过全世界的语料,所以具有一定的类似AGI的能力。然后,我们在这个环境中给它一些提示和指令,看它能否在虚拟环境中表现出色。
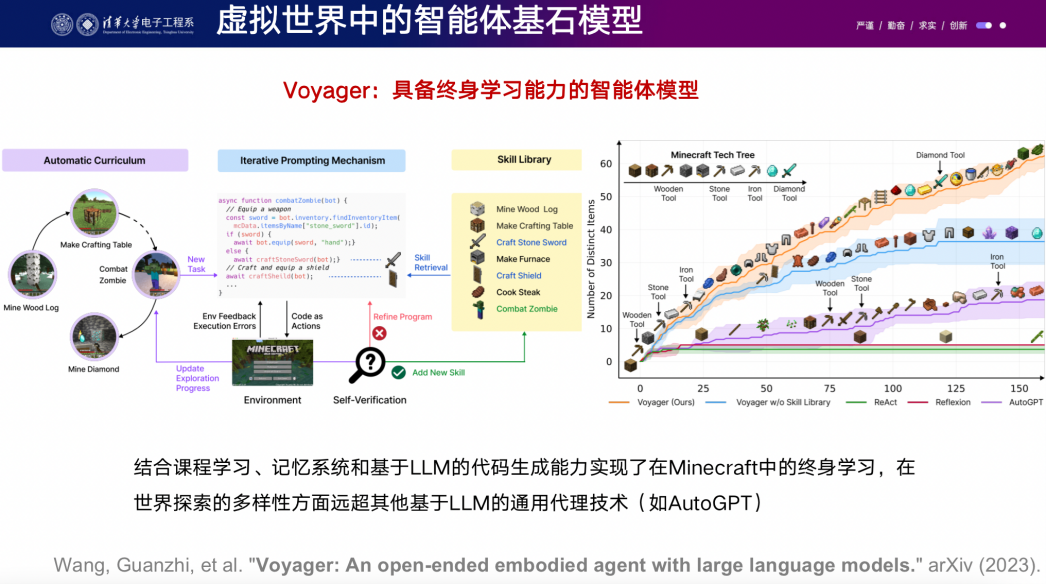
在这个方向上,有两篇相关工作。其中一篇是由英伟达提出的"Voyager",它将指令输出为控制智能体的代码,相比以前纯使用强化学习算法的智能体,它有了巨大的进步。另一篇是我们的工作"Ghost in the Minecraft",我们输出稍微高级一些的文字指令,需要一些更多的engineering,但换来的是更好的性能。我们的方法在测试中取得了3.7倍的性能提升,而之前使用强化学习的方法则需要大量的计算资源,并且能力有限。

最后要提及的是通用具身机器人,谷歌的"Palm-E"工作可能是代表性的。它将图像、动作、姿势等内容转换成TOKEN,并在预训练的大型语言模型上进行微调,用于控制机器人。这样的方法取得了很有趣的demo。 通过使用自然语言与机器人进行对话,比如让它将不同颜色的块放到不同的位置,经过训练后,机器人可以执行这样的任务,并且具有泛化能力。一旦学会了一些任务,你可以让它去做一些新的任务,它有可能表现得非常好。这是它的一个demo。以上就是我今天的报告内容,谢谢大家。
4. 谢凌曦(华为)

大家好,我是谢凌曦。很高兴能在这里与大家分享我们最近的心得体会。我之前在VALSE上做过一次报告,题目是“走向计算机视觉的通用人工智能”。虽然标题没有改变,但它非常贴合今天的主题,所以我将再次分享一下。
我今天的报告将分为几个部分。首先,我会简要介绍AGI和NLP在这个领域的进展和成就。接着,我将深入探讨CV领域为什么在实现AGI方面看起来还很遥远,面临的主要困难是什么,以及目前的解决方法以及其中隐藏的真正本质困难是什么。最后,我将简要分享一下我个人对于如何解决这些困难的看法。

在探讨AGI之前,我们需要明确其含义。AGI是人工智能的最高理想,可以被定义为一种能够达到或超越人类和动物能力的系统。从较为正式的角度来看,我们可以采用2007年AGI一书中的定义,将AGI定义为在一个环境中与其互动,通过采取行动来最大化奖励的系统或算法。在这样的定义下,AGI是非常通用的,因为它不知道具体环境是什么,环境中包含什么内容,以及需要完成什么任务。
近年来,随着深度学习的发展,AGI取得了很大的进展。深度学习是一种通用的方法论,只要给定输入和输出,就可以用统一的方法来建模输入与输出之间的关系。因此,在深度学习的推动下,我们能够用统一的方法来解决CV、NLP和强化学习等一系列问题。但是,距离真正的AGI还有相当大的距离要走。
在NLP领域,ChatGPT和GPT-4的出现让我们看到了AGI的曙光。国外的一些研究者称其为AGI的“火花”,因为GPT系列可以完成各种通用任务,甚至可以作为逻辑连接器将不同模块连接在一起。
举个我自己使用的例子,我用ChatGPT来写一段强化学习程序,虽然我没有学过强化学习,但它帮助我写出了程序,并回答了我的问题,比如为什么模块没有正确运行等等。通过几次交互,我成功地运行了程序并得到了期望的结果。这表明ChatGPT或GPT-4已经成为一个通用的问题解决程序,而不仅仅是我们在计算机视觉领域经常见到的toy example。
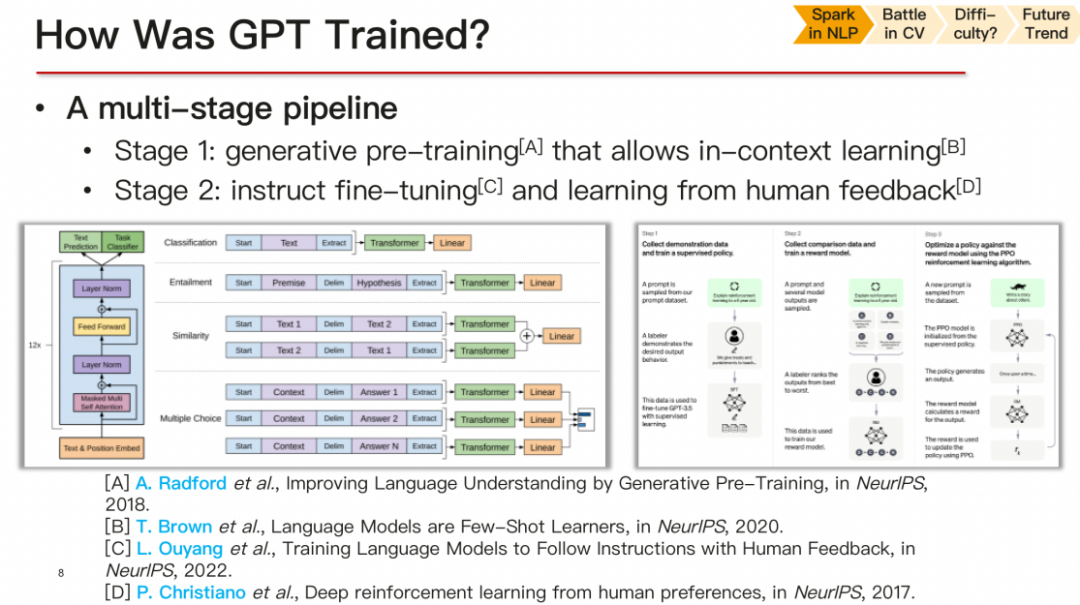
关于GPT的训练过程,它分为两个阶段。首先,在大规模的无标签语料库上进行无监督学习,掌握数据分布。然后,在带有标签的语料库上进行指令微调,以完成特定任务。这是一个两步走的过程,大家可能都比较熟悉,所以我就不再详细解释了。
在CV领域,与NLP相比,虽然NLP已经看到了AGI的曙光,但CV仍然面临着一些挑战。CV问题更加复杂,涉及的解决方案更加多样化。每个CV下游任务,如检测、追踪和分割,可能需要不同的方法和微调,与AGI目标相去甚远。因此,CV领域需要迈向统一性,即大一统或统一化。目前业界已经提出了五类走向,旨在实现CV的统一。第一个是,通过开放域的视觉识别实现形式上的统一,引入其他模态来实现视觉识别的统一化。第二类是,SAM的出现成为一种基座,从而实现各种下游任务的相对统一。第三类:统一视觉编码,通过编码的方式将不同的视觉任务定义成相似或相同的形式,使得一个模型可以处理多样的视觉任务。第四点是统一逻辑,通过大语言模型提供逻辑支持,从中发现视觉复杂任务的逻辑,并调用基本模块来解决它。第五类是统一交互方式,通过统一的交互方式使得CV系统更加灵活和智能。尽管CV领域的统一性面临着挑战,但这些工作的出现以及不断的努力,将有望推动CV领域向着更加统一和通用的方向发展。
从识别和对话等任务的角度来看,计算机视觉在识别细粒度信息和抽取图片中的内容方面表现不错。然而,回到AGI的定义,即在与环境互动并最大化reward的环境中实现通用智能,我们目前还无法做到这一点。为什么目前无法实现AGI呢?这涉及到计算机视觉目前面临的本质困难。尽管CV的发展迅速,但仍然面临着很大的瓶颈。我们需要分析一下,为什么这些方法不能完全通用,本质困难是什么?
在这个分析过程中,结论是GPT给我们带来的最大启发不在于它的预训练和微调的方法,而在于对对话这一任务的思考。进一步解释,GPT的最大启发在于对对话任务本身的探索。虽然GPT采用了预训练和微调的方法,但这并不是其最大的启发。对话任务的本质让我们开始思考如何在计算机视觉中实现更加通用的方法。因此,我们需要从对话任务中汲取启示,以解决计算机视觉面临的本质困难。
对话任务在NLP中是一个非常完美的任务,因为它使得我们可以通过对话来实现非常复杂的行为。假设我们生活在一个纯文本的世界中,对话就成为了一个可以学习任何东西并达成任何想要做的事情的完备任务。但是对于CV,我们需要思考什么样的任务能够实现类似对话任务的完备性。
回顾AGI的定义,它要求能够与环境进行互动并最大化奖励,这样才能实现通用人工智能。然而,CV目前还没有实现这一点。几十年前,David Marr等人已经提出过,CV必须构建一个世界的模型,并与之进行交互,才能实现广泛的识别和通用性。然而到目前为止,这个构建通用环境的想法还没有得到充分的实现。主要原因在于在CV中构建通用环境非常困难。
在CV中,构建环境有两种可能性:真实环境和虚拟环境。真实环境意味着将一个智能体放在真实世界中与周围环境互动,但这样做对规模、成本和安全性的要求都非常高。另一种方法是构建虚拟环境,但这个虚拟环境的真实度可能无法满足要求,尤其是其他智能体和物体的行为是否符合真实模式。目前还没有一个很好的虚拟环境能够解决这个问题。因此,CV在实现通用性和构建通用环境方面面临着困难。
目前,我们无法完全模拟或仿真一个真实的通用环境,因此在计算机视觉中,我们只能通过采样这个世界来获取数据。采样世界意味着我们利用已有的照片和视频作为离散的采样点,并在这些离散的点上进行模型训练。然而,由于这些采样点是离散的,我们无法进行与环境的真正交互,这给构建通用环境带来了困难。

为了解决这个问题,我们可以设想智能体在与环境进行真实交互时所需要的能力,并通过这些想象来定义代理任务,例如检测和追踪。我们过去二三十年,甚至更长时间,CV领域的研究人员都在努力构建代理任务,并认为通过在这些代理任务上取得更好的表现,我们就能更接近实现AGI的目标。然而,现在的问题是,所有的代理任务几乎都已经饱和,我们无法在这些任务上获得更多的好处。
在深度学习之前,我们走向代理任务的过程是朝着实现AGI的方向发展的,但现在我们似乎已经达到了一个瓶颈。我们走向代理任务的同时,可能远离了实现AGI的目标。现在我们面临的一个最大问题是,过去几十年所熟悉的研究范式在今天可能已经不再适用或者难以继续发展,这是一个非常重要的问题。
构建一个真实而足够复杂的环境,让智能体在其中进行学习。在这个pipeline中,首先需要构建一个具有足够真实感的环境,其中不仅包括视觉上的真实感,还包括其他智能体和物体的真实行为。在这个环境中,可以进行预训练任务,就像GPT预测下一个单词一样,智能体可以预测下一帧会看到什么内容,从而进行真正的预训练。完成预训练后,可以进行特定的微调任务,使智能体能够完成我们希望它完成的任务,如识别或感知。
然而,目前整个CV届可能有些本末倒置,忽略了构建真实环境的重要性,而过于关注特定的代理任务。这导致了一种局限性,阻碍了实现通用人工智能的发展。为了实现提出的pipeline,我们需要关注相关的研究工作,包括环境构建和预训练等方面的工作。尤其要强调的是,预训练的方法本身并没有问题,但是现在的预训练方法可能在构建通用环境方面有一定的局限性。
因此,为了实现通用人工智能,我们需要重点关注如何构建更真实和复杂的环境,并探索更加通用的预训练方法,使得智能体能够在这样的环境中进行学习,获得更强大的感知和理解能力。这样的研究将为实现AGI带来重要的突破。
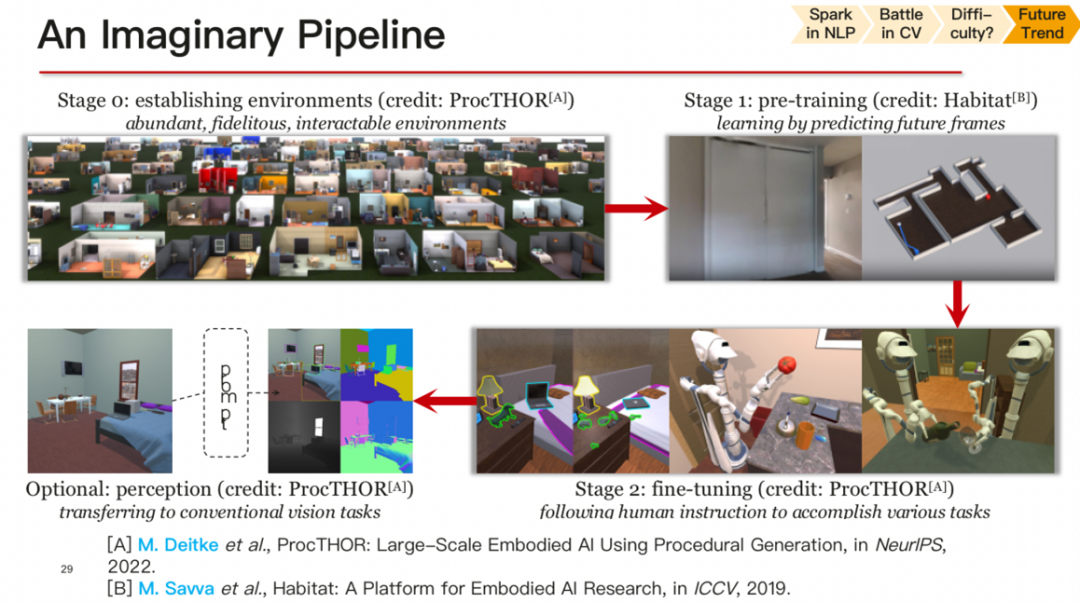
未来,若能有一个良好的环境,所有的预训练方法都会得到更新。包括过去十年深度强化学习在游戏等方面带来的一些算法,也可以借鉴视觉中的具身视觉,其中定义了很多任务,如交互和问答。但最本质的问题在于目前具身视觉所定义的内容还过于简单,无法让我们在真实环境中取得更好的表现。最近出现了一些像PaLM这样的工作,它们带给我们更多启发。然而,我们只能尽力去模拟这个环境,我认为这是一个非常大的问题,其难度甚至不亚于计算机视觉本身。
总结起来,过去二三十年间我们所熟悉的那套范式,在今天看来也许是难以为继的。如果是这样的话,计算机视觉领域面临的困难可能比我们想象的更大。这个领域现在走到了一个关键的点,对于我来说可能不太合适,因为我毕竟比较年轻。然而,我们都需要认真思考这个问题。
现在我想分享一下我的个人思想,我认为现在大语言模型,包括GPT的出现,给计算机视觉提出了很严峻的问题,我们需要想办法赶上这个趋势。一方面,我们需要探索一些新的方法论,不再仅仅依赖于数据集,但这可能需要一段时间来改变。但我认为这是趋势。另一方面,作为研究者,我们需要勇于拥抱一些新的方法论,不要再固守旧有的方法,否则我们可能会被这个时代所淘汰。总之,谢谢大家的聆听。
这个演讲的完整版本可以在链接: https://github.com/198808xc/Vision-AGI-Survey/中找到,如果有兴趣,可以去下载查阅。谢谢大家。
研讨阶段
Q1:什么是大模型?
卢湖川(大连理工大学)
听了陈老师的问题后,我想谈谈我的想法。我认为要从AGI的角度来看待这个问题。AGI要求一个模型具备通吃能力,就像人一样能够处理多模态输入和输出,并能解决多种任务。这就意味着我们需要改变过去的研究范式,从一个模型解决一个任务,转变为一个模型处理多样化的数据,并面向多个任务来解决。为了实现这种通用任务能力,我们需要大模型和大数据。只有这样,模型才能涌现出解决各种下游任务的能力和创新能力,解决未知领域的问题。因此,大模型和大的模型是完全不同的。当然,数据量也会对模型的表现产生影响。
大模型的好处之一是具备强大的通用特征表达能力,因为它吸纳了大量数据。另外,大模型还能完成多个任务,这也是季峰和凌曦所介绍的。过去的解决方案是使用多个Adapter或Transformer来处理每个任务,但这可能会变得繁琐。我们需要通用的解决方法,目前也有一些相关的工作进行研究。所以,在大模型的基础上,我们应该思考新的foundation model的研究范式改变。过去我们认为对算力要求很高,但随着算力的增强,目前foundation model的算力要求并不高,这意味着研究方向发生了改变。至于通才能力和专才能力,我认为它们是交互发展的。通用能力对于大模型非常重要,但专业知识和能力仍然是必需的,就像我们人类一样,每个人都有通用的能力,但同时也具备自己的专业知识和能力,因此它们是交互发展的。总结来说,大模型和大数据是实现通用人工智能的关键,而大模型带来的通用特征表达能力和多任务处理能力是其优势。研究范式的改变和通才能力与专才能力的交互发展都是当前需要考虑的问题。
王兴刚(华中科技大学)
大模型在计算机视觉领域的通用性和表征能力是一个重要的问题。目前,虽然通用视觉表征是追求的目标,但在短期内实现整个视觉领域的统一可能需要较长时间。现在的大模型,比如像CLIP这样的模型,在某些任务上具有较强的通用性和表征能力,但对于其他任务可能不太适用。从表征的角度来看,通用的视觉表征在解决各种任务时是非常重要的。虽然有许多不同的任务,但我们希望能够通过一个统一的特征提取方法来适用于所有任务,而不需要为每个任务设计特定的特征提取器。这样可以节省时间和资源,并提高模型的效率和泛化能力。在这方面,一些大模型如CLIP不断演进,不断出现新的版本,通过不同的训练机制和更多的训练数据,它们在各种任务上的表现能力不断增强。
因此,模型的参数量并不是唯一的衡量标准,而是要综合考虑训练机制、数据量和在各种任务上的性能。另一方面,一些公司和项目存在滥用大模型的情况,把大模型作为实现目标的借口。从科学的角度来看,这种滥用并不正确。大模型应该在适当的场景下得到应用,而不是一味地追求参数量的增加。科学家们应该以负责任的态度来推进研究,并结合实际情况使用合适的模型。总体而言,大模型在计算机视觉领域有着重要的作用,但要在科学的指导下加以使用,以实现更好的研究和应用效果。
山世光(中国科学院计算技术研究所)
我倾向于称之为"foundation model",而不是简单地区分大小。我认为基础模型的规模可能会非常大,甚至可能比语言模型还大。然而,目前我们可能还没有找到合适的方法来实现这种超大规模的基础模型,但最终基础模型会变得更大。关于基础模型的作用,它的主要目标是对无法用语言或符号表达的知识进行建模。类比人类的视觉发育,婴儿在学会语言之前,已经通过视觉和其他感觉系统接收了大量的信息,并形成了关于物理世界的一些常识性知识。这些常识性知识可能无法通过语言来完全表达,而是存在于我们的视觉皮层及相关脑区中。因此,基础模型应该能够表示这些只可意会不可言传的常识性知识,它是一种分布式的、与人类符号型知识体系完全不同的知识表示方式。
ChatGPT的最大成功之处在于提供了解决人工智能领域最难的知识表示特别是常识性知识表示问题的一个重要进展。传统的符号主义知识表示方法,如知识库和知识图谱,在常识性知识表示方面存在很大的局限性。而基于大模型的分布式表示方法,如ChatGPT,成功地突破了这些限制,并提供了一种新型的知识表示和利用方式。
我认为,在表达常识性的隐性知识方面,基础模型是必不可少的。此外,类似CLIP之类的视觉-语言双模态模型,通过在表示层次上对齐视觉和语言的语义,更为大量视觉理解类任务提供了解决“理解”类任务必需的语义知识。
王菡子(厦门大学)
随着模型规模的不断增大,从最初简单的几个参数到现在的千亿级参数,我们确实面临着一系列新的挑战。其中一个挑战是对大模型结果的验证和解释。在过去,我们可以轻松地验证和解释简单的模型,比如直线模型。但是现在,像ChatGPT这样庞大的模型,以及上午提到的可信人工智能,其参数量已经超出了我们人类理解的范畴,很难通过传统方式解释其内部运作和结果。
这就引发了一个问题,如何验证大模型的结果是否正确、可信。由于大模型是类似黑盒子,我们难以直接解释其内部工作,从而也难以确定其结果的准确性。在这种情况下,我们需要探索新的方法来验证大模型的输出,以及评估其结果的准确性。此外,作为高校老师,面临的挑战之一是算力不足。与一些公司拥有强大算力不同,在算力不足的情况下进行大模型的研究可能会面临一定的困难。在有限的算力下,如何深入地研究大模型,甚至创造性地发展新的方法,而不仅仅是简单地调整模型参数,是一个值得探索的问题。
总的来说,大模型的发展带来了许多新的挑战,包括验证结果的可信性和解释性,以及在算力有限的情况下进行研究的难题。这些问题需要我们在人工智能领域不断寻求新的解决方案和创新。
魏云超(北京交通大学)
很高兴能参与这次研讨,我个人认为,对于“大模型”这个概念,实际上是相对而言的,取决于我们当前的硬件资源和计算技术的限制。比如,现在的一个小模型在10年前或20年前可能都算是大模型,而未来随着硬件设备或量子计算等技术的进步,现在的所有模型可能都会变成小模型。
因此,“大”与“小”都有时间上的局限性。另外,我们目前都在追求通用的视觉模型,但是视觉任务本身非常复杂,应用场景也非常多样,包括工业视觉、医学视觉等等。如果有一个模型能在特定领域内表现得极其优秀,解决问题的能力非常出色,那对于这个特定的视觉领域来说,这个模型就可以被认为是我们当前认知下的大模型或者基础模型。
Q2:大模型带来了什么帮助?
林倞(中山大学)
大型语言模型,尤其是像GPT这样的模型,对视觉领域带来了很多帮助。它们解决了视觉领域常常面临的常识理解和推理难题。过去,视觉领域常常面临将领域知识融入视觉模型的难题,而现在,像CLIP这样的模型真正实现了将对世界的理解和常识融入到一个大模型中,使其具备了更强的通用性。因此,我们应该充分利用这些大型语言模型为视觉领域带来的能力,用于推理和跨领域的任务。
此外,大型多模态模型的发展也推动了人工智能生成领域的发展。它们给了我们很多启发,使我们考虑是否可以将视觉领域的模型设计成通用架构,从底层的通用性到上层的任务导向逐步演进。这种思路可以促进视觉领域的研究发展,从而更好地应用于实际问题。大型语言模型为计算机视觉带来了很多可能性,并且启发了视觉领域的发展方向。我们应该充分利用这些机会,进一步推动计算机视觉和人工智能生成领域的研究。
黄高(清华大学)
我分享两个观点。第一个观点强调了大模型的质变。在NLP领域,大模型的出现带来了质变的能力提升,让我们看到了更大的潜力和想象空间。以前在视觉领域,数据集刷到一定程度后可能就会饱和,没有显著的性能提升。而现在,大模型在视觉领域也带来了新的启发,当参数量增加到一定程度时,可能会出现质变的能力提升。这让我们有可能评估和debug大模型,寻找性能的关键点。
第二个观点强调了通用模型的设计。像CLIP这样的模型向我们展示了开放设置下的小样本学习能力。然而,现实世界中的视觉挑战远不止于此,它还涉及到对三维和动态世界的感知。虽然我们已经取得了一些进展,但在这方面,我们仍然处于起步阶段。真正将对三维和动态世界的感知能力融入到视觉模型中,这是未来的一个重要目标。类似于生物进化中,视觉带来了巨大的进步,我们相信在未来的研究中,对于三维和动态世界的理解也将为计算机视觉带来重要的突破。这些观点都对计算机视觉领域的发展和研究方向提供了有益的启示。
王涛(航天宏图)
今天我们进行了很多讨论,我认为非常有价值。我想提出一个问题,就是关于ChatGPT的参数存储。大家都认为其拥有1750亿参数,但这些参数实际上存储了什么内容呢?我觉得一方面它包含了人类的语言推理能力,比如符号推理等理解能力。另一方面,它还蕴含了大量人类知识,因为人类的知识库非常庞大,所以ChatGPT可以回答各种问题,ChatGPT给我们带来了很多启示。首先,我们之前讨论过掩码学习这种方式,但是ChatGPT可以回答问题,做摘要,进行语言翻译,这些功能让人惊叹。它同时还学习了中英文,具备跨语言能力。我们需要进一步思考,它是如何打通这些环节的,陈老师提到的基本模块似乎是一个关键。
另一个问题是关于video chat,我们应该如何设计?大家提到了算力和数据的问题,我们应该如何训练和标记数据?如何将语义和图像之间的关系打通?给他一个片段,中间掩码掉一些内容,这种方式是否可行?还有人类的视觉先天基本模块,像识别颜色、点线面、人脸等结构,但后天学习也很重要。我们是否可以将这些基本模块和ChatGPT的模块相结合,形成一个语言推理再加上视觉基本能力的系统,以获得更好的结果?这个问题值得我们深入探讨。
胡事民(清华大学)
有一点我想谈的是,ChatGPT推出后我们的思考是什么?首先,大模型已经呈现出多方竞争的状态,主要分为三派。一派是OpenAI和由OpenAI派生出来的Claude,他们技术上处于领先地位,自我迭代发展非常快。另一派是以Meta的LLaMA为代表的开源派,许多单位在使用开源的大模型进行微调和改进。第三个是本土派,国内的一些大学和公司在进行自己的研究,如清华唐杰、复旦邱锡鹏等,以及百度、讯飞等企业。对于自然语言大模型,现在主要采用Transformer架构,但它仍然存在问题,因为人类的知识表示和推理还没有很好整合,存在差距。
谈到视觉大模型,我们讨论了很多,如SegmentAnything、CLIP等,但与ChatGPT这种现象级的应用相比,仍然有很大差距。ChatGPT之所以有影响,是因为它实现了很好的对话应用,引起了全社会的极大关注。
但是对于视觉大模型,我们需要探讨更多的问题,如采用何种架构,是否需要一个像ChatGPT一样的应用场景来让视觉大模型落地。我个人觉得可以尝试创建一个人与机器人交互的场景,让机器人理解人类,并将检测、识别等计算机视觉的常用功能整合起来;这样的场景才能催生视觉大模型的发展。为了解决这个问题,我们面临两个挑战。第一个是需要一个统一的视觉内容的骨干网络,类似于自然语言处理中的Transformer。第二个是算力问题,因为视觉大模型的算力远超过自然语言大模型,需要发展算力网,通过软硬件协同优化,积极发挥国产芯片的落地应用。
徐凯(国防科技大学)
胡老师刚才谈的非常有启发性。最近OpenAI的一篇博客讨论了通用AI的一个实现思路,我非常认同。他们提出将智能系统分为三层:最上层是一个大语言模型,用于和用户交互,接受用户指令,理解用户意图,同时将用户指定的某项复杂任务拆解成一系列相对简单的子任务,类似于基于思维链(Chain-of-Thought)的任务拆解。每一个子任务,可能对应一段代码,一个工具,或者是一个软件、一个服务,比如计算器、浏览器、各种app等,用于执行具体任务,这一层叫工具利用。在大语言模型层和工具利用层之间,还要有一个记忆层。
为什么要有这么一个记忆层呢?我们知道大模型具有一定的记忆能力(注:这里的记忆指的是与特定用户或情境相关的记忆,而不是大模型在预训练阶段记忆的通用知识),多轮对话本身就体现了一定的记忆能力,但这是短期记忆能力。一个智能体要想完成更复杂的任务,比如像家庭机器人一样长期陪伴在用户身边,需要长期记忆用户的习惯爱好、脾气秉性等,只有基于长期记忆机制,才能逐渐“驯化”出一个定制化的智能体,以提升用户的使用体验。文章提出可以基于向量数据库来实现长期记忆,因为它可以支持高效查询。
不过我认为,这个长期记忆应该不止是符号化的、知识型的记忆,还需要有对3D空间的记忆,也就是要对智能体所在的3D环境、周遭的3D对象进行高效的建模和编码,以支持智能体在3D环境中完成复杂交互任务,从而实现具身智能。这对于机器人来说是很有必要的:比如机器人倒水的时候把杯子碰倒了,GPT可以告诉机器人去拿抹布。要具体执行“拿抹布”这个动作,需要进一步输出细化的动作指令,如果没有关于3D空间的记忆,GPT发出的动作指令可能根本无法完成。
那么,该如何实现对3D场景的高效建模和表征,以支持上述的空间智能呢?还没有一个很好的答案。刚才有老师提到了NeRF表示的前景,NeRF的确非常强大,但它在这里是否合适?我不知道。NeRF的提出面向的是新视角合成(渲染),它把几何编码在神经网络里,这的确是一种非常紧凑的表示,但是它对高效查询并不友好,给定一个3D空间中的位置,神经网络只能告诉你这一点在物体内(occupied)还是物体外(free space),以及颜色信息,却无法告知你附近的几何信息(为此你需要逐点去查询),更无法告诉你全局的拓扑和几何信息,这对于实现空间智能是有问题的。我想,可能需要一种更加结构化的、同时也是可微分学习的3D场景表达,同时支持几何和语义信息的高效关联、查询、更新等。这个方向会非常有意思。
谢凌曦(华为)
我想解释一下我的定义,什么是foundation model。我认为作为一个foundation model,它的大小或者完成的任务并不是它的本质。它的本质在于建立这个世界的数据分布,只要一个模型建立了一个好的数据分布,它就可以被称为是一个foundation model。在这种情况下,我们需要回应一下山老师之前提出的问题,即视觉模型的参数量。我认为视觉模型的参数量会比NLP模型要大很多,因为视觉世界比自然语言的世界要复杂。所以,如果我们要用一个模型来建模视觉世界的数据分布,它所需要的参数量会至少要大一些。在这种情况下,我们目前的关键问题不是我们不知道什么样的架构是合适的,因为我认为现在的Transformer已经足够强大了。我们现在真正不知道的是这个世界到底是什么样的。我们没有一个很好的理解,难道互联网就是我们整个世界的一个映射?
所以我想再强调一下,我们需要自己去定义这个世界的模型。无论是用Yann LeCun的方法去定义一个world model,还是通过具身的方法去实现高度真实的仿真来定义这个世界,这是我们现在最迫切需要做的事情。一旦有了这个定义,我们就能够建立起自然和人工的对齐,然后在这个基础上运行各种模型,将分布对齐到各种任务中,从而实现各种复杂的任务。至于徐老师刚才提到的记忆力,我认为NLP是一个记忆力很好的典范,它可以记住很多知识。为什么呢?因为我们给予它足够多的数据,让它真正地记住了这个数据分布,并且它发现了数据与任务之间的关联。如果我们能够真正订阅一个足够真实的世界,那么在这样的环境中训练出来的模型也一定会具有足够强的记忆力,否则它不可能去记住这个分布。所以我认为理解这个世界,或者说建立仿真环境是非常重要的。
操晓春(中山大学)
刚才提到的NLP研究里无监督填空的角度,我们汉字常用的有6000个字,所以复杂度是1/6000。如果是两个字,最多则是6000的2次方。因为语言是人类创造的,所以存在强烈的规则性,这个填空寻优的复杂度远低于暴力的指数次方,所以在这种填空问题上应该是相对容易的。比如说我们学过汉字的人都可以去填词,填得好不好不说,至少可以填上去。
第二点是视觉大模型为什么相对困难?凌曦老师刚才说复杂2到3个数量级,我感觉可能还不止,因为我们可以简单算一下。以NLP填空和视觉的completion为例,一个物体旁边可能是任何几何形状(遮挡)和颜色的物体,这个可能性几乎是无限的,譬如一个人的旁边可以是杯子、墙、扫帚,甚至是恐龙或者泰国大象,所以在这种情况下,咱们不应该做太多假设,否则容易被pre-train影响而产生bias,因此复杂度是远远高于NLP的。目前早期的视觉基础大模型还不够强大,仅通过类似于NLP填空的的方法效果不佳,至少现在没有成功。所以,我直觉可能还需要一步一步来,在某些特定领域,比如面向卡通或者日本漫画的视觉任务,由于存在大量的先验和简化,问题空间大大降低,其卡通任务的视觉大模型可能先于泛在视觉大模型,超越人类的视觉系统。
最后是胡老师说到的统一视觉基础大模型的骨干网络,刚才有人说了Transformer这个framework,我也一直在跟学生讨论,它在NLP为什么成功?因为它有人类设计的或者约定俗成的语法结构,有元音、辅音、主谓宾等很好切割的components,但是视觉是不好断开的,其语义components及components之间的关系要更加复杂。虽然Transformer在视觉上也取得了很多进展,但是是否成为胡老师要求的视觉大模型骨干网络,现在还不清楚。
吴小俊(江南大学)
我认为大模型可以用数学中的子空间概念来理解。每个大模型实际上就是物理世界子空间的建模。现有的模型如SAM和CLIP可以看作现实世界的子空间,可能还有细分行业的子空间。因此,基础模型可以看作是子空间的一个实例,而子空间的本质是由其特征量决定的。找到我们数据的大模型,就是要找到数据的这些特征量。因为视觉大模型与一些基础功能模块相关,而这些基础功能模块实际上就是子空间的特征量。
这些子空间可能呈现的方式不同,例如在欧式空间中可能是特征,或者像张老师早期提出的remaining management中可能会呈现出全面空间,这也与现实世界对应。用子空间这个概念来理解ChatGPT可能会有点异想天开,但可以认为整体上我们从线性代数到泛函分析,再到泛函的维度,从有限到无限,可能现在的ChatGPT是一个比较大的子空间,甚至有点像泛函的子空间。
而我们现在的视觉模型里的子空间是一些具体领域的小子空间。但是这些子空间经过研究后,最后汇聚成了我们视觉的大模型。这个观点可以解释陈老师提出的观点,以及其他专家提出的相似观点。至于徐老师提出的内部记忆和外部记忆,我不太认同。因为我觉得模型中的记忆机制更像是受到宏观计算架构的影响,而我们人脑中的信息存储机制实际上是内容相关的。
陈宝权(北京大学)
视觉领域的问题非常复杂,因为空间太大。目前的基础模型只是满足了需求的两三个部分,只有到那个时候,我们才可能看到类似video ChatGPT 这样的东西。AIMP对视觉提供了很大的启示,现在大家正在研究视觉语言大模型,像SAM这样的模型出现后,下一步可能是通过数据量和标注的提升,提高精度,让人们感到惊艳。类似ImageNet标注大数据集推动了视觉发展一样,接下来可能会有视觉语言的大模型,类似ChatGPT,通过众多人对视觉任务进行语言标注,从而完成更大的数据集建设,推动视觉语言大模型的诞生,产生让人惊艳的video ChatGPT等等。
另外,目前的视觉大模型让我们从闭集走向了开集,以前在所有任务上,包括RTC任务,都是在封闭的数据集里进行。但是现在SAM出现后,虽然在闭集上表现不太好,但是因为其泛化能力很强,它在通用表达上接近人类认知,因此受到认可。随着技术不断进步,可能会真正实现在现实中开集验证。最后,这些大模型对未来的机器人和嵌入式设备,包括手机等,都会有很大帮助。因为它们可以完成通用任务,与环境交互,使ChatGPT不断地进行交互和学习,从而不断提升能力,这将带来更大的潜力。
Q3:计算机视觉的哪些问题在大模型的背景下不值得再继续做下去了?
金连文(华南理工大学)
结合我在OCR领域的经验,我想谈谈一些体会。在OCR领域,我们需要处理视觉和语言方面的任务。比如,给定一个发票,我们需要识别其中的内容,并提取关键信息,生成结构化的输出,这也适用于其他包含结构化文档的任务。关于GPT模型,它在理解和语言相关任务上表现优秀,让我们感觉像大脑皮质一样有效。我们进行了一些实验,比如在小组或学习中,使用开源的大模型(如V3引擎、GPT-3.5的API),来完成理解任务,如从视频中抽取关键文本。这些模型的效果都非常好,尤其在与语言相关的任务上。
接下来,我想补充一点。作为CV领域的研究人员,我们希望能在CV领域发展出自己的基础模型,而不仅仅受到NLP领域的影响。GPT模型给我们带来的最大启示并不是在语言理解或文本生成方面的突破,而是在将全人类的知识融入一个模型的简单方法。尽管目前还不完美,但我们已经看到了它的潜力。通过内训练和强化学习技术,我们可以使模型学习全人类的知识。在视频领域是否能实现类似的模型,还需要进一步探索和研究。
操晓春(中山大学)
接着金老师的答案,我补充一点。由于在座的金老师、白翔老师等在OCR技术方面的技术创新,许多其它领域的任务已经不再需要。比如以前我们想要从PDF、PPT中提取文字,需要研究PDF、PPT的格式,这需要不停地更新技术版本。然而,有了OCR后,我们可以简化这个过程,Screen Capture文档,直接用OCR高效地提取所需的关键文字信息。
谢凌曦(华为)
我来谈谈两个较好的研究方向。第一个是视觉网络架构的设计,第二个是视频预训练。当然,我并不是说这两个方向一定不要去做,因为这两个领域都非常庞大,但我们觉得这两个领域目前都面临着很大的挑战。比如以前在网络架构设计方面,我们可以设计一个新的网络架构,并在baseline上进行评测,如果分类效果更好,那就说明这个网络效果更好。预训练也是一样,我们可以设计预训练结构和算法,并在相应数据集上进行测试,如果精度更高,那就说明我们的算法更好。
但为什么现在这两个领域似乎进展缓慢呢?这是因为现有的数据集已经相当饱和了,即使我们换用更大的数据集,也很难获得明显的提升。所以我认为,现在这两个方向并非没有必要继续研究,而是因为它们面临一些困境,我们迫切需要一个更好的评测指标来指导研究。这个评测指标可能是多方面的,要么是更大、更难的数据集,但我对这一点不太看好;要么是一个更好的交互环境。在报告中重点讨论了环境的问题,如果我们解决了评测或环境的问题,我相信无论是更好的网络架构还是更优的预训练算法,都会涌现出来。
刚才有老师说了,现在的一些模型都是盲目的尝试,我非常同意这一观点。但现在为什么没有人去专注于这个方面呢?因为即使你设计了一个非常巧妙的方法,可能在实际应用中也只能使点击率提高0.2个百分点,可能这篇论文的影响力也不会很大。所以我们面临的评测压力更大,我认为一旦评测或环境的问题解决了,很多视觉领域都会迎来新的突破。我就是这么认为的。
山世光(中国科学院计算技术研究所)
陈老师说的很有道理。我想表达的意思是,有一段时间sparse coding、sparse representation特别火的时候,我当时做编委的期刊主编确实曾给全体编委发邮件,建议谨慎录用这类主题的投稿,当然是谨慎录用,不是直接拒稿,但暗示不鼓励,因为已经难以判断很多投稿的实际价值。回到井东的问题,我觉得很难一一列举哪些问题可能不该做。但的确,当我们有了更大的context model或更强的基础模型后,过去很多问题的定义确实就看起来不那么有意义了。例如小样本学习任务,特别是基于Meta learning的方法,benchmark的设置是假设有几十类甚至只有几类组成的base set,然后要做新类的N-way K-shot,我认为这个问题的定义就是错的。类比人,人不是这样的setting,人的小样本学习能力是构建在大量学习基础上的,没有进化和发育过程中对大量“基类”的学习,人恐怕也不会具有“小样本学习能力”。
我们要解决的AI问题,是没法突破信息论瓶颈的,要解决大规模未知参数的欠定求解问题,要么引入更多数据形成更多方程,要么引入更多知识或信息作为约束条件,否则没有理由获得更确定的解。现在有了foundation model,我认为就是带来了更多隐性知识或上下文信息,从而使得我们获得满意解的可能性大大增强。如果不用这些知识或信息,之前的方法很难获得满意的解。我认为这是foundation model起作用的本质,它为下游的数据不足任务的求解提供了一个强大的基石——基石之外的解就不用考虑了,或者只需要在基石上再增点砖添点瓦就OK了。所以,从这个意义上讲,可能大量问题的解决都要从这个角度来重新考虑benchmark,重新设定测试协议。
王涛(航天宏图)
工业界还有很多大模型没有解决的问题。通用大模型、行业模大模型和场景大模型是分阶段发展的。在工业场景中,场景级的大模型非常困难,尤其是由于数据量很小的问题,如在无人机巡检中,道路、电力线缺陷识别,或者在亚米级遥感影像飞机、舰船类型等弱小目标识别等。这些场景级的大模型的实际应用都面临很大的挑战。解决场景级的大模型问题必须考虑样本收集、小样本学习和迁移学习。
在工业场景中,收集样本是一个挑战,例如对于事故车的检测,需要大量各种类型的事故车照片。迁移学习也是一个问题,如何将大模型的知识迁移到具体的工业应用场景。在文字识别中,当遇到艺术字体等复杂情况时,视频难度会急剧增加。大模型具备普通人的基本能力,但要成为场景级的专家也同样困难。这种场景级的专家模型可以应用在具体的工业场景中,而通用大模型可以用于普通人的生活场景。
查红彬(北京大学)
大家在讨论当前大模型时代该做什么,不该做什么,以及可能要做什么。大模型如ChatGPT在文本与语音处理方面确实发挥了重要作用,能够有效利用从大数据中获取的结构性和抽象知识。然而,大模型只是我们解决现实问题的一部分。人类智能在发展过程中,具有先天和后天两个部分,其中基因是一种重要的先天信息来源。可以说,基因是在数百万年人类进化过程中积累下来的一种大模型知识,但是只有基因是不能让人具备智能的。要成为具有智能的个体,还需要人的脑与身体系统具有柔性,具有可塑性,即能够通过与环境交互和反馈进行学习,使人的系统本身在现实环境中产生变化。所以,大模型提供了类似于基因的基础信息,但要使系统具备柔性和适应性,需要在线的学习和处理能力,通过与环境的交互来改变模型自身,使其更好地适应现实环境及其变化。因此,除了研究大模型,我们还需要考虑怎样使系统具备这种柔性和适应性。
金连文(华南理工大学)
刚才听了很多老师的讲解,非常受启发,我也再谈谈,希望大家一起思考。首先,ChatGPT在自然语言处理方面让我们看到了一些令人惊喜的地方,比如有限能力和规模定义、语言模型的思维链等问题。我一直在思考,虽然已经有一些相关的研究,但涉及视觉领域的研究似乎还比较少,不知道是否存在与NLP类似的有限能力和规模定义的问题。在通用的视觉领域研究这个问题可能很困难,因为需要大量的计算资源,这也是之前大部分老师讲的。但在一些垂直领域中,也许大家可以探讨这个问题。
其次,ChatGPT给我们带来的启示并不在于它在特定任务中的性能有多好,我们的体会在于它解决实际问题的通用能力非常强。比如,一个模型可以放置在任何地方使用。而在我们以前做研究或解决实际应用问题时,对不同的厂家可能需要重新获取数据并进行处理。但有了这样通用的基础模型后,这种情况会大大减少。所以我想问,在垂直领域中是否有可能发现视觉存在类似的尺度定理、思维链,或者视觉有限能力的问题?在NLP领域中研究较多,而视觉领域的相关文章还较少。
Q4:大模型背景下科研该如何展开?
肖斌(重庆邮电大学)
我认为在目前大模型发展的趋势下,CV方向受到的冲击很大,我们应该避免受到过大的影响,而是要转变思路。最近参加了几次NLP和大模型领域内的调研,邀请了很多该领域的专家参加。一个共性问题是,高校研究人员做大模型研究所面临的挑战主要是计算能力的问题。NLP领域的大模型参数量相对CV领域的参数较少,即使NLP做得较好的团队,也只有数百张甚至上千张GPU卡,对于我们高校来说,这已经是极限了,这带来了算力上的巨大挑战。我认为,我们可以尝试从以下几个方面来切入。首先,数据共享,避免每个团队做大模型时重复清洗大量数据。其次,模型结构共享和开源,研究适用于计算机视觉的基础结构,并开源这些结构。第三,算法优化,针对特定任务优化算法,使其在有限算力下运行效果良好。最后,模型的度量,制定统一客观的度量标准,以确定大模型的性能,避免局部指标误导。总的来说,当前我们需要关注如何转变思维,解决算力问题,推动数据、模型结构和算法的共享和优化,并确立统一的模型性能评估标准。这将有助于我们在计算机视觉领域的大模型研究取得更好的进展。
毋立芳(北京工业大学)
首先,关于大模型的作用,大模型在很大程度上是对现有知识的总结和应用。它们可以视为一种基于大量数据和经验的知识迁移工具。然而,大模型的适应能力有限,它们可能无法处理一些特定场景下的问题。如何在大模型的基础上进一步提高它们在不同场景下的适应性和灵活性,这可以是一个有意义的研究方向,探索如何让大模型更好地理解和应对不同的环境和情境。其次,关于资源有限的问题。虽然许多人可能没有足够的计算资源来构建大规模模型,但我们可以通过引入外部知识、背景信息或领域专业知识,来提高问题的解决效率。这种知识引入的方法可以在特定场景下,甚至是传统任务中,帮助我们更好地解决问题,从而弥补资源有限的情况。这种方法可能会涉及到知识图谱、迁移学习、领域知识的融合等技术,是一个值得进一步研究的方向。
刘静(中国科学院自动化研究所)
在简洁的描述中,我认为大模型的能力评价是一个复杂的问题,对科研方向有着重要的引导作用。为了确保自己的工作性能达到最佳水平,我们需要建立有效的评测方法。以GPT-4为例,他在综合评测中表现出色,包括检索、视觉问答和开放领域的任务。这表明大模型在开放环境下的任务需求日益凸显,传统的研究更偏向于闭集任务,而这需要变化。大模型的能力可能不适合简单的单一样本评价,而应更关注开放环境下的综合表现。这引出了一个值得深入研究的问题,即如何评价大模型的综合能力,以及如何比较大模型、小模型和更强能力模型的表现,而不仅仅依赖于现有的基准测试。同时,对于开放任务的价值也需要更深入地探索和思考。
代季峰(清华大学)
我认为这个问题可以从另一个角度来思考,可能会更有益。我觉得实际上与其说重点在于模型参数或者Bug,不如强调在构建性模型以及实现任务通用性或强泛化能力方面的重要性。模型参数和Bug可以被视为实现这一目标的手段,或者说是当前阶段的手段。如果我们围绕"Action Model"这一概念展开,会发现有许多值得探索的事情。
举例来说,在ChatGPT或者NLP领域,他们的重要之处在于找到了一种对NLP世界进行本质建模的方法。他们直接对NLP中的每个TOKEN、每个word的分布进行建模,而不是通过预测下一个TOKEN来建模。对于视觉领域,我们以前在处理静态图像时往往放弃了物理世界的复杂性,只关注于静态的像素分布。我们需要思考更本质的方式,如何更有效地对图像中的分布、表征和监督进行建模。尽管现有的图像方法在某些方面有效,但并不足够本质,因为现实世界不仅仅是图像瞬间的表现,还包含着时间的流逝、因果关系等。这些方面在图像领域的Master运行模型中并没有得到本质建模,因此我认为在这个领域还有许多值得探索的问题。对,这就是我的看法。
汤进(安徽大学)
我们还需要补充一点,就是很多人在担忧这个问题,特别是在网络使用GPU的情况下。我想通过一个例子来说明,就像航空学院是否还自己制造飞机一样。航空学院专注于培养学生,而不是自己制造飞机。同样,我们在过去的科学与技术领域,也存在着工程与系统之间的差距。因此,我们过去认为应该做任何事情,但当事情发展到一定程度时,当它变成了确定性事件时,只需要采取行动,就能实现目标。我们可以考虑是否值得在工业界修复BUG,因为有时候在办事之前会遇到亏损的情况。所以,我建议大家仔细思考一下,我们今天所做的事情背后的动机。此外,我们也需要考虑历史的发展,以及未来可能出现的情况。就像海啸或海浪过后,我们是否还会停留在原地不前进?如果海平面上升,我们是否还能继续从事当前的工作?也许我们需要做出一些调整,适应新的情况。
吴保元(香港中文大学(深圳))
我对这个问题有两个角度的思考。第一个角度研究大模型的安全性问题,因为大模型的安全问题可能会造成更严重的安全后果。首先一个考虑是我们之前针对小模型的研究方法是否适用于大模型,目前已经有一些这方面的探索,初步发现了一些新的挑战,比如效率问题。另一个考虑是大模型是否存在全新的安全隐患,比如数据记忆能力过强和幻想问题。另一个角度是将大模型视为一种工具来使用。例如,我们可以将其用作辅助工具,而不是全程自主完成任务。比如,当我们想要完成一项特定的复杂任务时,尽管大模型的通用能力可能不足以很好地解决该复杂问题,但可以将该问题分解成多个较为简单的子问题,然后利用大模型完成其中的一部分,以加速整个流程。在这方面我们已经进行了一些探索,初步验证了这种思路的可行性,其潜力值得进一步挖掘。
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。