
权重量化对大模型涌现能力的影响
© 作者|刘沛羽
机构|中国人民大学高瓴人工智能学院
引言:本研究旨在探讨模型权重量化对大型语言模型(LLMs)的涌现能力的影响。LLMs 相较于小型语言模型在特定任务中展现出更强的能力,如上下文学习(ICL)、思维链推理(CoT)和指令遵循(IF)。然而,由于 LLMs 参数规模巨大,实际应用中对计算资源的需求很难被满足。为了解决这个问题,研究人员广泛应用权重量化方法来减少 LLMs 的内存占用。然而,低比特量化方法往往会导致性能下降。因此,本研究旨在探讨权重量化对 LLMs 的涌现能力的影响。我们主要回答了以下两个问题:(一)大模型涌现能力是否会受到影响?(二)如何补偿低比特量化下的模型能力?同时我们开源了一个可以微调 GPTQ 量化模型的 GitHub 项目,实现单卡 A100 上一键微调 LLaMA-65B 的 2-bit/4-bit 模型。文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

我们的论文(Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study)可以参考以下链接:
论文链接:https://arxiv.org/abs/2307.08072
开源项目:https://github.com/RUCAIBox/QuantizedEmpirical
Part1简介
本文进行了一项实证研究,调查模型权重量化对大型语言模型(LLMs)涌现能力的影响。量化是一种通过将浮点数映射为低位整数来减少 LLM 显存占用的方法。我们重点关注三种涌现能力:上下文学习(In-context Learning)、思维链推理(Chain-of-thought Reasoning)和指令遵循(Instruction Following)。首先我们评估了不同参数规模的LLaMA模型(7B、13B、30B 和 65B),在不同精度水平(2-bit、4-bit、8-bit和 16-bit)下的表现。同时,针对性能下降的低比特量化情况,我们从两个角度探索了可能提升效果的方法:
-
(1)细粒度影响分析。通过研究哪些组件(或子结构)对量化更敏感,尝试保持这部分组件(或子结构)的精度来缓解量化的误差; -
(2)微调补偿。分为先微调再量化以及先量化再微调两种策略,探索提升低比特模型性能的方法。我们的研究得出了一系列重要发现,以了解量化对涌现能力的影响,并为LLMs的极低比特量化可能性提供了启示。
Part2大模型涌现能力是否会受到影响?
实验设置
我们重点关注大模型的三个关键能力,分别是上下文学习(In-context Learning,ICL),思维链推理(Chain-of-thought Reasoning,CoT)和指令遵循能力(Instruction Following,IF)。
-
在数据集方面,我们采用 MMLU、BBH 数据集来评测 ICL 能力,GSM8K 评测 CoT 能力。针对 IF 能力,我们使用了 Vicuna 数据集,其中包含 80 个问题,涵盖了 8 个不同的类别,然后通过 ChatGPT 来对模型的回答进行打分。 -
在量化设置方面,我们只对模型的权重进行量化,包括注意力模块(ATT)中的 query,key,value 和 output 矩阵,以及前馈网络中(FFN)的 gate、up 和 down 投影矩阵。量化的模型包括 LLaMA 的 7B,13B,30B 和 65B 规模,量化的精度包括 2-bit,4-bit 和 8-bit。 -
在评估指标方面,我们使用准确率作为 ICL 和 CoT 测试的评估指标。对于 IF 测试,我们使用 ChatGPT 对模型的输出结果进行打分。我们将结果报告在表 1 中。
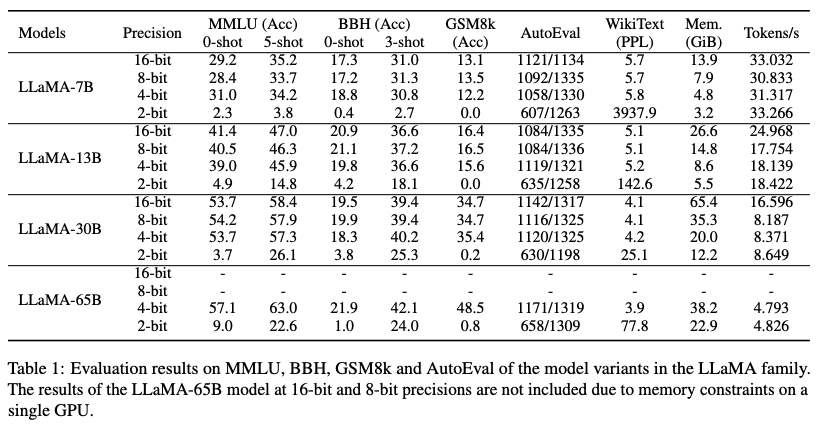 表 1. MMLU,BBH,GSM8K 以及 AutoEval 的评测结果。
表 1. MMLU,BBH,GSM8K 以及 AutoEval 的评测结果。
结论与分析
-
大型语言模型(LLMs)在 4-bit 权重量化下仍然能够保持涌现能力,但在 2-bit 量化下会遭受严重的性能下降;
在各个任务中均可以看到 4-bit 量化后的效果几乎没有明显的下降,但是在 2-bit 量化后效果则明显变差。特别是在 GSM8K 的任务中,可以看到 2-bit 量化的效果几乎接近 0。
-
4-bit 量化在相同总比特数条件下,模型表现效果更好;
我们使用模型量化比特数乘以模型参数量作为总比特数,来衡量量化模型使用的资源总量。结果发现,4-bit 量化(下图中的红色线)均处于左上角位置,即在相同的总比特数下有更好的模型表现效果。
 图 1. 模型表现与总比特数之间的关系。其中 AutoEval(d)中"Relative Score"表示量化模型与 GPT3.5 得分的比值。横坐标表示总比特数。
图 1. 模型表现与总比特数之间的关系。其中 AutoEval(d)中"Relative Score"表示量化模型与 GPT3.5 得分的比值。横坐标表示总比特数。
-
在量化的比特数固定的条件下,提升模型参数量后对 CoT 任务效果提升最明显;
从 GSM8K(CoT)任务上的测试结果上看,在量化比特数固定的条件下,增加总比特数(即增加总参数量)带来的模型性能的提升明显。而在其他任务上,随着总比特数增加,模型效果的提升则越来越小。
-
在 2-bit 量化下,ICL 任务中的提供 demonstrations(即 5-shot 设置)可以缓解模型效果损失。
在表 1 中对比 MMLU、BBH 数据集,few-shot 和 zero-shot 的结果看出,2-bit 量化后的模型 few-shot 的结果明显高于 zero-shot。
Part3如何补充极限压缩情况下的模型能力?
1细粒度影响分析
实验设置
-
组件影响:我们主要分析注意力组件(ATT)和全联接组件(FFN),一共测试了 3 个变种: -
(1)"all",对 Transformer 层权重全部量化为 2 bit; -
(2)" ATT",在(1)的基础上仅对 ATT 保持 FP16 其他做量化; -
(3)" FFN",仅对 FFN 保持 FP16 精度其他做量化。 -
异常维度影响:我们主要分析激活值中的异常值维度的量化对模型效果的影响,一共测试 3 个变种: -
(1)"all non-outlier dimensions",我们采用 LLM.int8() 方法,对激活值和权重所有非异常值维度进行 8-bit 量化; -
(2)"+top-1 outlier dimension",在(1)的基础上额外将影响层数最多的 top-1 异常值维度进行 8-bit 量化; -
(3)"+top-3 outlier dimension",在(1)的基础上将影响层数最多的 top-3 异常值进行 8-bit 量化。 -
子结构影响:我们分析 ATT 和 FFN 组件中的子结构,将重要的子结构保持 FP16,其他做量化。 -
结果报告为" crucial weights"。
结论与分析
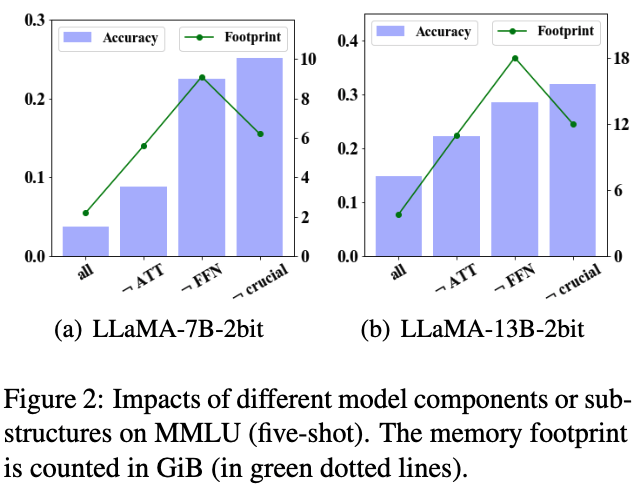 图 2. 不同模型的组件和子结构对 MMLU(5-shot)效果的影响。
图 2. 不同模型的组件和子结构对 MMLU(5-shot)效果的影响。
-
相比 ATT 结构而言,保持 FFN 结构的 FP16 精度可以提升 2-bit 量化模型的效果。
从图 2 中看出,对 FFN 保持精度( FFN)在 LLaMA-7B-2bit 和 LLaMA-13B-2bit 模型上的表现都好于其他的变种(all和 ATT)。这个结果表明保持 FFN 的精度相比 ATT 而言更加重要。
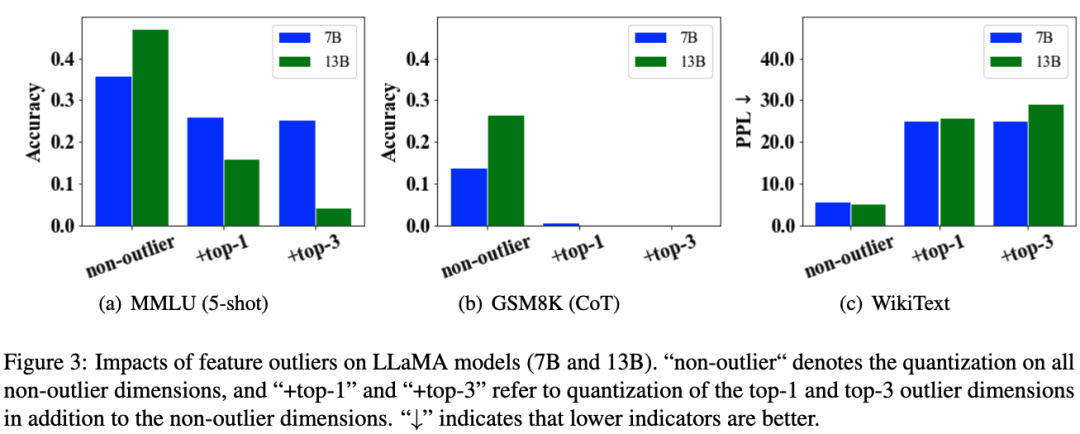 图 3. LLaMA 模型(7B 和 13B)中激活值异常值维度的影响 。"↓"表示值越低越好。
图 3. LLaMA 模型(7B 和 13B)中激活值异常值维度的影响 。"↓"表示值越低越好。
-
针对量化激活值的异常维度带来的影响,那些影响层数最多的异常值维度,量化带来的影响最大。
从图 3 中看出,仅对影响层数最多的异常值维度量化(+top-1)就可以导致严重的模型精度下降,并且这个下降的幅度在较大的模型上更明显。例如 MMLU 中可以看出,尽管 LLaMA-13B 上"non-outlier"的表现比 LLaMA-7B 的好,但是一旦将影响层数最多的异常值维度量化,模型的精度都会大幅下降,而且 LLaMA-13B 上"+top-1"的表现比 LLaMA-7B 的"+top-1"更差一些。
-
通过对子结构保持 FP16 可以进一步提升 2-bit 量化模型的效果。
我们发现 LLaMA 模型中异常值维度都集中在 FFN 组件的 down_projection 模块,这表明子结构可能是需要保持 FP16 精度的关键子结构。同时为了更好提升效果,我们还在 ATT 组件中选择了量化误差最高的 2 个子结构保持 FP16。最终结果报告为图 2 的" crucial"。可以看出来,通过保持子结构的 FP16 精度,而其他部分进行 2-bit 量化,模型的 footprint 比保持 FFN 组件 FP16 更低,但是下游任务的表现更好。
2模型微调补偿分析
实验设置
-
先微调后量化:我们将 LLaMA 模型在 ICL、CoT 以及 IF 任务上进行指令微调后再做量化。关于微调使用的数据集,ICL 使用 Alpaca 数据集,CoT 使用 CoT 数据集,IF 使用 Alpaca 数据集。关于微调方法,我们测试了: -
(1)全参数微调(Full parameter Fine-tuning,FFT) -
(2)以及基于 LoRA 的参数高效微调(LoRA) -
先量化后微调:我们先将 LLaMA 模型进行 GPTQ 的权重量化,再基于量化后的权重进行微调。为了实现量化后权重的微调,我们设计了一种改进的 LoRA 方法(如图 4 所示),把固定权重部分替换为 GPTQ 量化得到的权重,通过微调额外的 lora 参数,可以补偿量化模型带来的精度损失。目前项目已经开源。
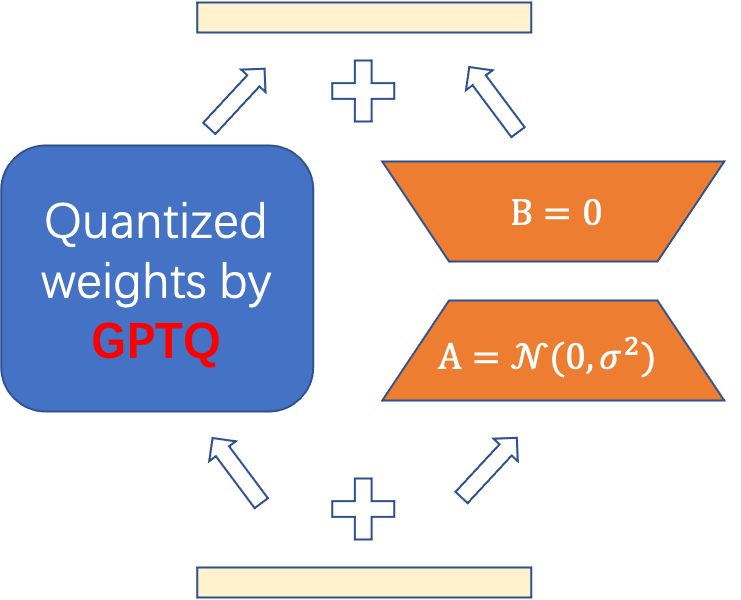 图 4. 改进后的 GPTQ-LoRA 示意图。
图 4. 改进后的 GPTQ-LoRA 示意图。
GitHub 链接:https://github.com/RUCAIBox/QuantizedEmpirical
直接微调量化后的权重是困难的,我们从 LoRA 中获得启发,直接将 LoRA 中的固定权重部分替换为 GPTQ 生成的量化权重,在微调的时候固定量化的权重,只微调 lora_A 和 lora_B 矩阵。由于量化可以极大降低显存占用,我们发现这样简单的操作可以在单卡 A100 上微调最大 65B 的模型,量化的精度为 2-bit 和 4-bit。微调所需要的资源和时间统计如下图:
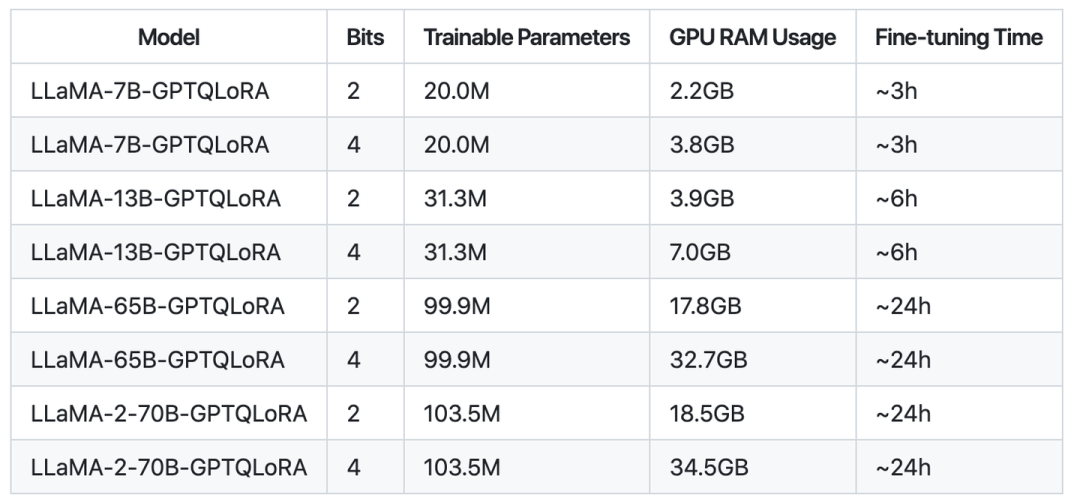
一键微调 LLaMA-65B-2bit 模型的代码如下:
# 一键微调 LLaMA-65B-2bit 模型
finetune_multi alpaca_gptqlora_65B_2bit $base_dir/alpaca_data_cleaned.json
--adapter_name=gptqlora\
--target_modules="['q_proj','k_proj','v_proj','o_proj','up_proj','gate_proj','down_proj']"\
--base_model=$checkpoint/llama-65b-hf\
--quant_checkpoint="$checkpoint/llama-65b-2bit-formulate"\
--use_gradient_checkpointing\ --bits=2
结论与分析
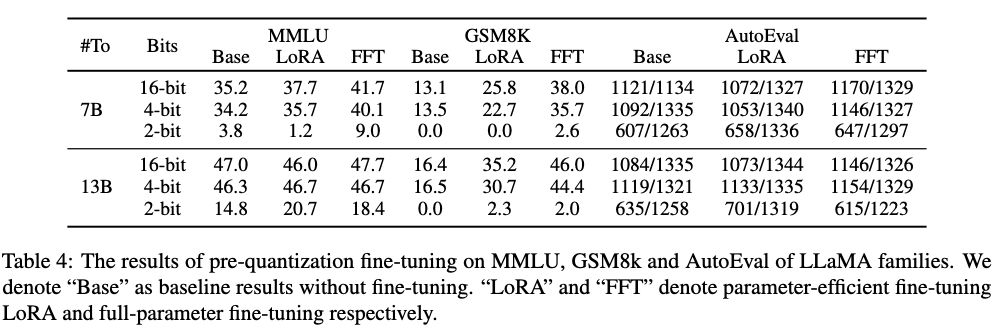 表 2. 量化前微调在 MMLU,GSM8K 以及 AutoEval 上的表现。
表 2. 量化前微调在 MMLU,GSM8K 以及 AutoEval 上的表现。
-
先微调再量化,依然在 2-bit 的精度上会遇到明显的模型效果下降。
表 2 中,我们发现 LoRA 和 FFT 微调后,如果模型再量化到 2-bit,则效果会明显下降。特别是 GSM8K 任务上,LoRA 微调的 LLaMA-7B 量化到 2-bit,Accuracy 依然会下降到 0.0。这个结果说明先微调再量化无法有效提升量化后模型的表现。
-
在 ICL 和 CoT 任务上,LoRA 微调的效果相比 FFT 微调仍有差距。
我们在表 2 中观察到,LoRA 列的表现仍低于 FFT 列。其中最明显的是 GSM8K 任务,LLaMA-13B 的 4-bit 量化的效果 FFT 比 LoRA 高 13.7。这表明在复杂的任务上,全参数微调依然是更加合适的微调方式。
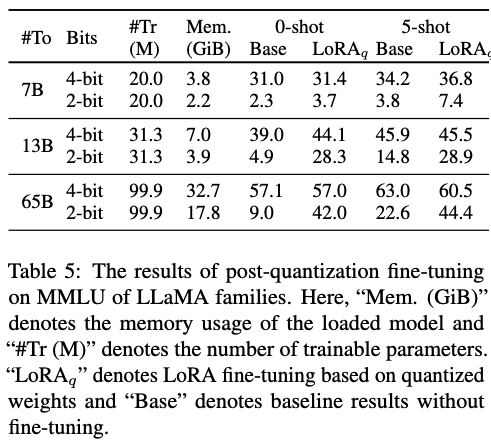 表 3. 量化后微调在 MMLU 上的表现。这里"Mem."表示仅加载模型所占用的显存,"Tr(M)"表示可训练的参数量。
表 3. 量化后微调在 MMLU 上的表现。这里"Mem."表示仅加载模型所占用的显存,"Tr(M)"表示可训练的参数量。
-
先量化后微调,可以有效提升量化后模型的表现,同时也可以极大减少微调所需要的显存。
在表 3 中,先量化后微调的结果记作 ,我们可以观察到在 2-bit 量化的模型上,通过改进后的轻量化微调方法可以有效补偿量化所带来的效果损失。其中对于 LLaMA-65B 模型而言,MMLU 的结果有明显提升。目前该方法已经开源,且还在持续开发中,欢迎大家试用,如果有什么问题欢迎大家提提建议。
Part4总结
我们的实证实验表明,大型语言模型(LLM)在进行 4-bit 权重量化后,仍然可以表现出涌现能力,如上下文学习(In-context Learning)、思维链推理(Chain-of-thought Reasoning)和指令遵循(Instruction Following)。然而,模型在 2-bit 量化后性能严重下降。为了提高 2-bit 权重量化模型的性能,我们进行了两项特殊实验:细粒度影响分析以确定敏感组件和子结构,以及通过模型微调进行性能补偿。发现通过保持特定组件和子结构的精度,以及量化后的微调方法,可以有效提升量化后模型的表现。最终,我们的实验结果揭示了权重量化对大模型涌现能力的影响,并探索了 2-bit 权重量化在 LLMs 中的可能性。
更多推荐
↓↓↓