
【深入探究Node】(4)“内存控制” 有十五问
共 5546字,需浏览 12分钟
·
2021-07-06 17:40
1. V8是用什么给对象分配内存的呢?
2. V8为何要限制堆的大小?
3. 原来如此,那你知道垃圾回收机制的策略是什么吗?
4. 为什么要分代呢?
5. 哦,那你谈谈是怎么分代的?
6. 那 新生代是怎么回收的?
7. 很好奇,一个新生代它是怎么晋升成老生代的。
8. 为什么要设置25%这个这么低的值呢?
9. 新生代的对象晋升后就成老生代了,那老生代为什么不能用Scavenge回收?
10. 那老生代的对象该怎么处理?
11. 那为什么还要标记整理?
12. 咦!既然标记整理是基于标记清除上演变而来的,也就是它包括了标记清除,这么棒,那就用标记整理好了,干嘛还要说它结合标记清除使用呢?
13. 原来是这样啊,要是垃圾回收算法时间花费很长,岂不是就要卡顿?
14. 你知道Buffer对象吗?Buffer对象是通过V8分配内存的吗?
15. 可以利用fs.readFile()和fs.writeFile()方法 来 读写大文件吗?
1. V8是用什么给对象分配内存的呢?
在V8中,所有的JavaScript对象都是通过堆来进行分配的。Node提供了V8中内存使用量的查看方式,执行下面的代码,将得到输出的内存信息:
$ node
> process.memoryUsage();
{ rss: 14958592,
heapTotal: 7195904,
heapUsed: 2821496 }
在上述代码中,在memoryUsage()方法返回的3个属性中,heapTotal和heapUsed是V8的堆内存使用情况,前者是已申请到的堆内存,后者是当前使用的量。至于rss为何,我们在后续的内容中会介绍到。图为V8的堆示意图: 当我们在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到堆的大小超过V8的限制为止。
当我们在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到堆的大小超过V8的限制为止。
2. V8为何要限制堆的大小?
表层原因为V8最初为浏览器而设计,不太可能遇到用大量内存的场景。对于网页来说,V8的限制值已经绰绰有余。
深层原因是V8的垃圾回收机制的限制。按官方的说法,以1.5 GB的垃圾回收堆内存为例,V8做一次小的垃圾回收需要50毫秒以上,做一次非增量式的垃圾回收甚至要1秒以上。这是垃圾回收中引起JavaScript线程暂停执行的时间,在这样的时间花销下,应用的性能和响应能力都会直线下降。这样的情况不仅仅后端服务无法接受,前端浏览器也无法接受。因此,在当时的考虑下直接限制堆内存是一个好的选择。
3. 原来如此,那你知道垃圾回收机制的策略是什么吗?
V8的垃圾回收策略主要基于分代式垃圾回收机制。
4. 为什么要分代呢?
因为在实际的应用中,对象的生存周期长短不一,不同的算法只能针对特定情况具有最好的效果。为此,现代的垃圾回收算法中按对象的存活时间将内存的垃圾回收进行不同的分代,然后分别对不同分代的内存施以更高效的算法。
5. 哦,那你谈谈是怎么分代的?
在V8中,主要将内存分为新生代和老生代两代。新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。图为V8的分代示意图。

6. 那 新生代是怎么回收的?
在分代的基础上,新生代中的对象主要通过Scavenge算法进行垃圾回收。是一种采用复制的方式实现的垃圾回收算法。
它将堆内存一分为二,每一部分空间称为semispace。在这两个semispace空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的semispace空间称为From空间,处于闲置状态的空间称为To空间。当我们分配对象时,先是在From空间中进行分配。当开始进行垃圾回收时,会检查From空间中的存活对象,这些存活对象将被复制到To空间中,而非存活对象占用的空间将会被释放。完成复制后,From空间和To空间的角色发生对换。
简而言之,在垃圾回收的过程中,就是通过将存活对象在两个semispace空间之间进行复制。
Scavenge的缺点是只能使用堆内存中的一半,这是由划分空间和复制机制所决定的。但Scavenge由于只复制存活的对象,并且对于生命周期短的场景存活对象只占少部分,所以它在时间效率上有优异的表现。
由于Scavenge是典型的牺牲空间换取时间的算法,所以无法大规模地应用到所有的垃圾回收中。但可以发现,Scavenge非常适合应用在新生代中,因为新生代中对象的生命周期较短,恰恰适合这个算法。
是故,V8的堆内存示意图应当如图所示。

当一个对象经过多次复制依然存活时,它将会被认为是生命周期较长的对象。这种较长生命周期的对象随后会被移动到老生代中,采用新的算法进行管理。对象从新生代中移动到老生代中的过程称为晋升。
7. 很好奇,一个新生代它是怎么晋升成老生代的。
对象晋升的条件主要有两个,一个是对象是否经历过Scavenge回收,一个是To空间的内存占用比超过限制。
在默认情况下,V8的对象分配主要集中在From空间中。对象从From空间中复制到To空间时,会检查它的内存地址来判断这个对象是否已经经历过一次Scavenge回收。如果已经经历过了,会将该对象从From空间复制到老生代空间中,如果没有,则复制到To空间中。这个晋升流程如图所示。
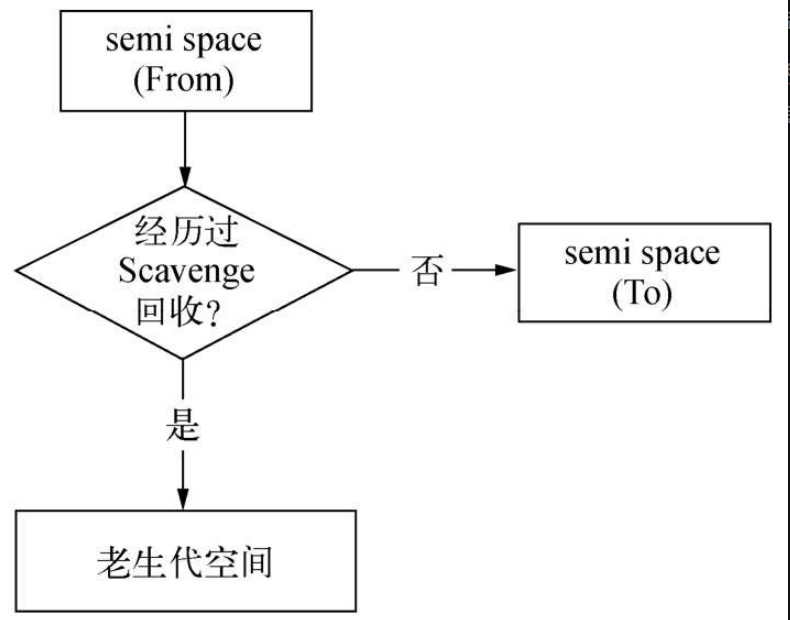
另一个判断条件是To空间的内存占用比。当要从From空间复制一个对象到To空间时,如果To空间已经使用了超过25%,则这个对象直接晋升到老生代空间中,这个晋升的判断示意图如图所示。

8. 为什么要设置25%这个这么低的值呢?
设置25%这个限制值的原因是当这次Scavenge回收完成后,这个To空间将变成From空间,接下来的内存分配将在这个空间中进行。如果占比过高,会影响后续的内存分配。
9. 新生代的对象晋升后就成老生代了,那老生代为什么不能用Scavenge回收?
对于老生代中的对象,由于存活对象占较大比重,再采用Scavenge的方式会有两个问题:一个是存活对象较多,复制存活对象的效率将会很低;另一个问题依然是浪费一半空间的问题。这两个问题导致应对生命周期较长的对象时Scavenge会显得捉襟见肘。
10. 那老生代的对象该怎么处理?
V8在老生代中主要采用了Mark-Sweep和Mark-Compact相结合的方式进行垃圾回收。
Mark-Sweep是标记清除的意思,它分为标记和清除两个阶段。与Scavenge相比,Mark-Sweep并不将内存空间划分为两半,所以不存在浪费一半空间的行为。与Scavenge复制活着的对象不同,Mark-Sweep在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。可以看出,Scavenge中只复制活着的对象,而Mark-Sweep只清理死亡对象。活对象在新生代中只占较小部分,死对象在老生代中只占较小部分,这是两种回收方式能高效处理的原因。图为Mark-Sweep在老生代空间中标记后的示意图,黑色部分标记为死亡的对象。

11. 那为什么还要标记整理?
Mark-Sweep最大的问题是在进行一次标记清除回收后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题,因为很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。
为了解决Mark-Sweep的内存碎片问题,Mark-Compact被提出来。Mark-Compact是标记整理的意思,是在Mark-Sweep的基础上演变而来的。它们的差别在于对象在标记为死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。图为Mark-Compact完成标记并移动存活对象后的示意图,白色格子为存活对象,深色格子为死亡对象,浅色格子为存活对象移动后留下的空洞。
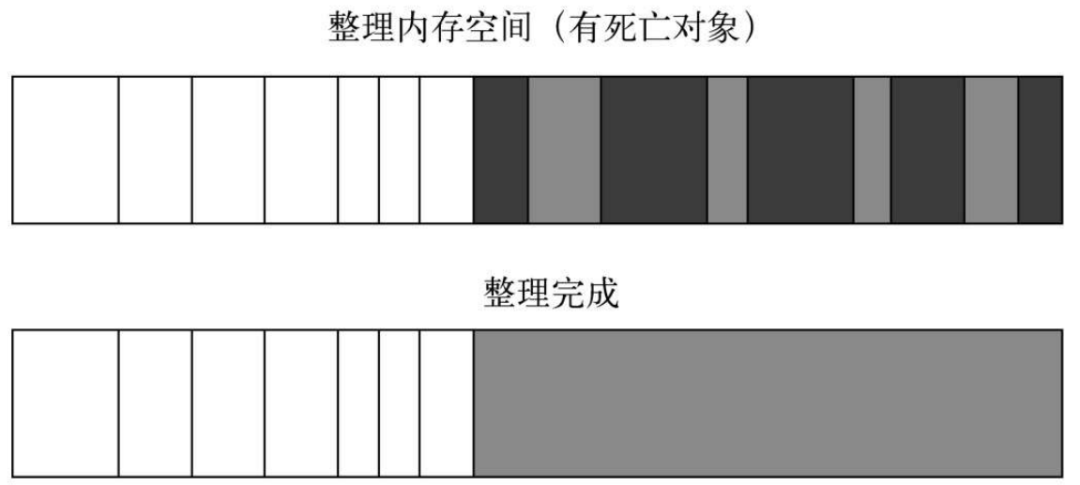 完成移动后,就可以直接清除最右边的存活对象后面的内存区域完成回收。
完成移动后,就可以直接清除最右边的存活对象后面的内存区域完成回收。
12. 咦!既然标记整理是基于标记清除上演变而来的,也就是它包括了标记清除,这么棒,那就用标记整理好了,干嘛还要说它结合标记清除使用呢?
这里将Mark-Sweep和Mark-Compact结合着介绍不仅仅是因为两种策略是递进关系,在V8的回收策略中两者是结合使用的。表是目前介绍到的3种主要垃圾回收算法的简单对比。

从表中可以看到,在Mark-Sweep和Mark-Compact之间,由于Mark-Compact需要移动对象,所以它的执行速度不可能很快,所以在取舍上,V8主要使用Mark-Sweep,在空间不足以对从新生代中晋升过来的对象进行分配时才使用Mark-Compact。
13. 原来是这样啊,要是垃圾回收算法时间花费很长,岂不是就要卡顿?
垃圾回收的3种基本算法都需要将应用逻辑暂停下来,待执行完垃圾回收后再恢复执行应用逻辑,这种行为被称为“全停顿”(stop-the-world)。在V8的分代式垃圾回收中,一次小垃圾回收只收集新生代,由于新生代默认配置得较小,且其中存活对象通常较少,所以即便它是全停顿的影响也不大。
但V8的老生代通常配置得较大,且存活对象较多,全堆垃圾回收(full垃圾回收)的标记、清理、整理等动作造成的停顿就会比较可怕,需要设法改善。
为了降低全堆垃圾回收带来的停顿时间,V8先从标记阶段入手,将原本要一口气停顿完成的动作改为增量标记(incremental marking),也就是拆分为许多小“步进”,每做完一“步进”就让JavaScript应用逻辑执行一小会儿,垃圾回收与应用逻辑交替执行直到标记阶段完成。图为增量标记示意图。
 V8在经过增量标记的改进后,垃圾回收的最大停顿时间可以减少到原本的1/6左右。V8后续还引入了延迟清理(lazy sweeping)与增量式整理(incrementalcompaction),让清理与整理动作也变成增量式的。同时还计划引入并行标记与并行清理,进一步利用多核性能降低每次停顿的时间。
V8在经过增量标记的改进后,垃圾回收的最大停顿时间可以减少到原本的1/6左右。V8后续还引入了延迟清理(lazy sweeping)与增量式整理(incrementalcompaction),让清理与整理动作也变成增量式的。同时还计划引入并行标记与并行清理,进一步利用多核性能降低每次停顿的时间。
14. 你知道Buffer对象吗?Buffer对象是通过V8分配内存的吗?
知道。他不是。
为何Buffer对象并非通过V8分配?这在于Node并不同于浏览器的应用场景。在浏览器中,JavaScript直接处理字符串即可满足绝大多数的业务需求,而Node则需要处理网络流和文件I/O流,操作字符串远远不能满足传输的性能需求。
关于Buffer的细节 后面再仔细讲解一下。
所以,从这里我们可以知道,Node的内存构成主要由通过V8进行分配的部分和Node自行分配的部分。受V8的垃圾回收限制的主要是V8的堆内存。
15. 可以利用fs.readFile()和fs.writeFile()方法 来 读写大文件吗?
由于V8的内存限制,我们无法通过fs.readFile()和fs.writeFile()直接进行大文件的操作,而改用fs.createReadStream()和fs.createWriteStream()方法通过流的方式实现对大文件的操作。
下面的代码展示了如何读取一个文件,然后将数据写入到另一个文件的过程:
 由于读写模型固定,上述方法有更简洁的方式,具体如下所示:
由于读写模型固定,上述方法有更简洁的方式,具体如下所示:
 可读流提供了管道方法
可读流提供了管道方法pipe(),封装了data事件和写入操作。通过流的方式,上述代码不会受到V8内存限制的影响,有效地提高了程序的健壮性。如果不需要进行字符串层面的操作,则不需要借助V8来处理,可以尝试进行纯粹的Buffer操作,这不会受到V8堆内存的限制。但是这种大片使用内存的情况依然要小心,即使V8不限制堆内存的大小,物理内存依然有限制。
14. 你知道Buffer对象吗?Buffer对象是通过V8分配内存的吗?
知道。他不是。
为何Buffer对象并非通过V8分配?这在于Node并不同于浏览器的应用场景。在浏览器中,JavaScript直接处理字符串即可满足绝大多数的业务需求,而Node则需要处理网络流和文件I/O流,操作字符串远远不能满足传输的性能需求。
关于Buffer的细节 后面再仔细讲解一下。
所以,从这里我们可以知道,Node的内存构成主要由通过V8进行分配的部分和Node自行分配的部分。受V8的垃圾回收限制的主要是V8的堆内存。
15. 可以利用fs.readFile()和fs.writeFile()方法 来 读写大文件吗?
由于V8的内存限制,我们无法通过fs.readFile()和fs.writeFile()直接进行大文件的操作,而改用fs.createReadStream()和fs.createWriteStream()方法通过流的方式实现对大文件的操作。
下面的代码展示了如何读取一个文件,然后将数据写入到另一个文件的过程:
由于读写模型固定,上述方法有更简洁的方式,具体如下所示:
可读流提供了管道方法pipe(),封装了data事件和写入操作。通过流的方式,上述代码不会受到V8内存限制的影响,有效地提高了程序的健壮性。如果不需要进行字符串层面的操作,则不需要借助V8来处理,可以尝试进行纯粹的Buffer操作,这不会受到V8堆内存的限制。但是这种大片使用内存的情况依然要小心,即使V8不限制堆内存的大小,物理内存依然有限制。