
熬了几个大夜,学完一套985博士总结的计算机视觉学习笔记(20G高...
AI 显然是最近几年非常火的一个新技术方向,从几年前大家认识到 AI 的能力,到现在产业里已经在普遍的探讨 AI 如何落地了。 我们可以预言未来在很多的领域,很多的行业,AI 都会在里边起到重要的作用。
我们可以预言未来在很多的领域,很多的行业,AI 都会在里边起到重要的作用。
随着AI的不断持续火热,越来越多的人才涌入进来,但我发现一个行业现象:人才短缺,工程师过剩。目前在商业中有所应用,而且能够创收的只有搜索推荐和计算机视觉,因此,这两个方向的人力缺口很大,尤其是计算机视觉。 前两年校招时可以看到,互联网、IT、生物医药、汽车安防等等行业,几乎都会有计算机视觉的岗位。 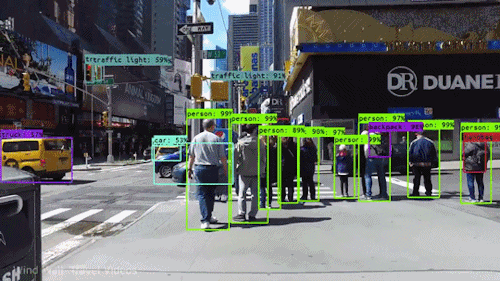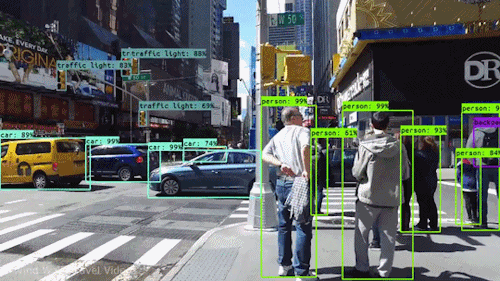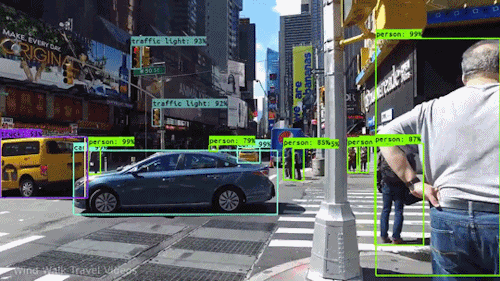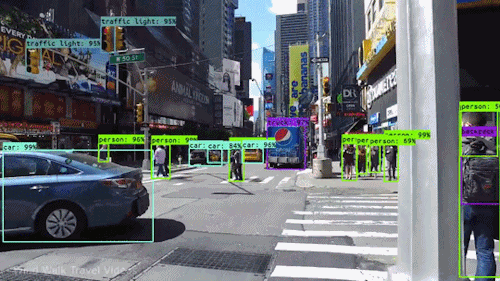
所以,很多其他方向的同学开始纷纷转向,随着大潮流投入计算机视觉这个方向,为什么这么多人投入计算机视觉方向?我认为有以下几个原因:
入门容易
模型成熟
人才缺口大
热度高,名气大
看吴恩达《机器学习》《深度学习》课程,学一点机器学习的知识。
读几篇CV模型的文章,了解一下经典的Alexnet、R-CNN系列、YOLO等。
在github上找几个tensorflow、pytorch实现上述模型的开源代码。
下载VOC、ImageNet、COCO、kaggle等数据集。
按照开源代码中的Readme准备一下数据集,跑一下结果。
但好多初学者学了两个月、跑了几次结果后就认为已经入行CV了,其实不然,这里面有一个需要注意的问题:计算机视觉属于图像处理的范畴,而很多人却把它当成机器学习来看待。
然而实际上几乎80%的CV的从业者都没有从头至尾深入的学习图像处理方面的知识。
 现在有了深度学习,不需要人为提取特征了,所以很多人不再关注图像底层的信息,而是直接越过这个根基去搭建模型,我觉得这是一个误区。 不同领域的图像,例如OCT、MR、遥感、自然图像等等,有着巨大的特征差异,对这些特征差异性都不了解,怎么在搭建模型之后对精度进行提升和改进呢?怎么在原来模型的基础上做一些改变呢? 因此,我认为好好学习一下图像预处理、后处理的知识对CV有着至关重要的作用,例如图像去噪、分割、增强、增广等等。
现在有了深度学习,不需要人为提取特征了,所以很多人不再关注图像底层的信息,而是直接越过这个根基去搭建模型,我觉得这是一个误区。 不同领域的图像,例如OCT、MR、遥感、自然图像等等,有着巨大的特征差异,对这些特征差异性都不了解,怎么在搭建模型之后对精度进行提升和改进呢?怎么在原来模型的基础上做一些改变呢? 因此,我认为好好学习一下图像预处理、后处理的知识对CV有着至关重要的作用,例如图像去噪、分割、增强、增广等等。然而网上很多教程也比较碎片,鉴于此,整理一套卷积神经网络、目标检测、OpenCV,从检测模型教学逐步深入,帮你轻松掌握目标检测,轻松提升CV算法核心能力。

 (资料内容过多,仅截取部分)
(资料内容过多,仅截取部分)上次已经给大家推荐过一次,但微信有限制每天只能加100个人,很多人反馈没有领到,这次又申请到了100个名额,速度领取,手慢无!
该视频出品人是王小天,目前就职于BAT之一,AI算法高级技术专家,法国TOP3高校双硕(计算机科学和数学应用双硕士)毕业。
👇长按下方二维码 2 秒
立即领取(添加小助理人数较多,请耐心等待)
他在人工智能和芯片领域发表10余篇论文,具有深厚的学术背景和丰富的项目及业务落地经验。工作期间主要负责人工智能业务线CV与NLP相关算法工作,推进人机混合智能、语义分割、机器翻译、虹膜识别等模块的核心算法研究与优化。对图像分类、物体检测、目标跟踪、自动驾驶、计算机体系结构等有深入的研究。他兼具理论与实战落地经验,深知初学者学习痛点。说实话,这样资历的人,很难得。
这份教程是他8年人工领域实战经验的凝练,通过讲解和实战操作,让你能做到独立搭建和设计卷积神经网络(包括主流分类和检测网络),从检测模型教学逐步深入,帮你轻松掌握目标检测,并进行神经网络的训练和推理解决各种CV问题。
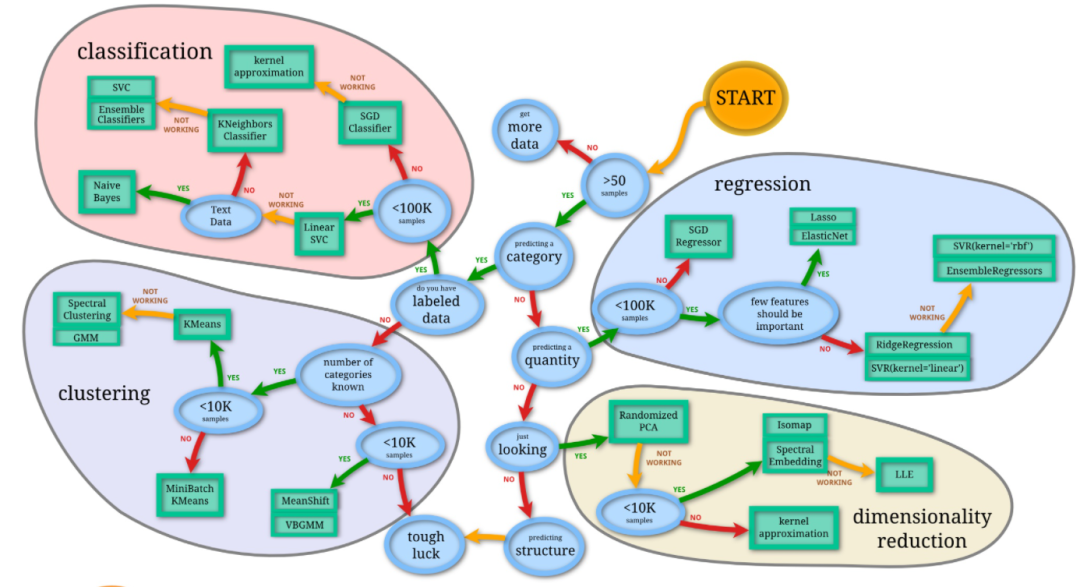
他对学习者的建议:计算机视觉的提升不在于搭建模型,而在于不断调优、改进过程中积累的经验。
我们该怎么针对不同领域的图像设置不同的参数?其中包括卷积核大小、网络架构、初始权重等等,不可能拿到一个模型,既适合医学图像,又适合人脸识别,这其中就需要n次从70%的精度调到95%以上中积累出经验。
而很多CV从业者觉得搭建出模型就告一段落,反反复复用不同的方式去搭建模型,先是tensorflow搭建完用pytorch搭,pytorch完事后用mxnet再来一遍,Python搭完用c/c++搭,但是至始至终没在精度和经验方面做出前进。
由于工作需要,这份教程我本人也在学习中,虽然已经从事这个行业多年,再看这份教程的时候,仍然能查漏补缺,收获满满,我相信不管是AI入门,还是已经具备了一定的工作经验,这份学习资料,都值得你去认真学习研究。
所有以上相关的的内容全部都已经打包好了,汇总成了一份百度云的链接,小贴心之处是怕有的兄弟没有买百度云会员的朋友,能用2MB+/S的速度下载,还特地给大家准备了下载工具。
评论