点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

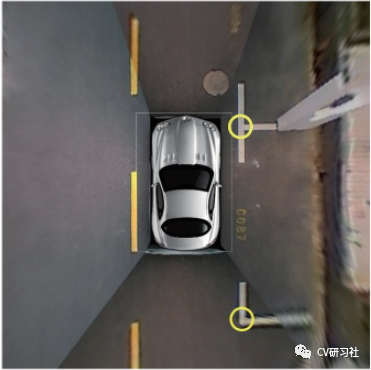
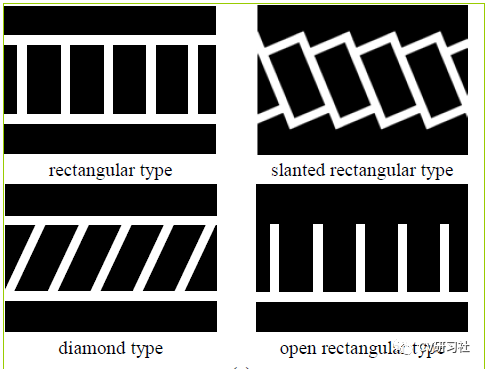
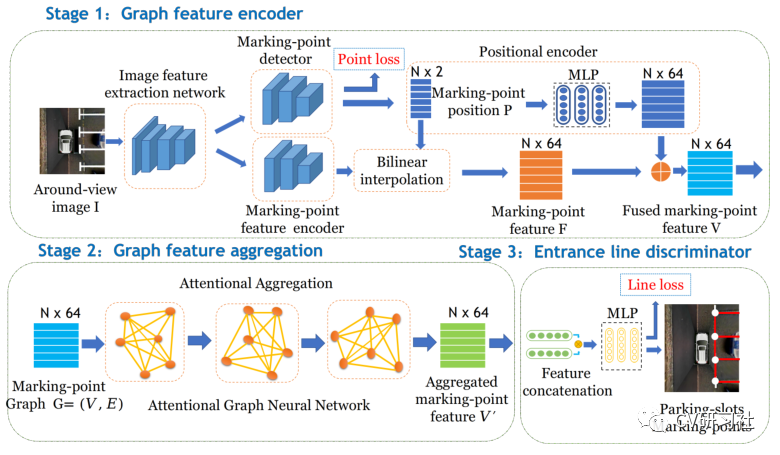
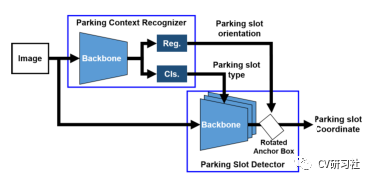
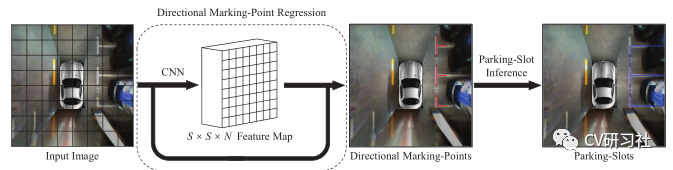
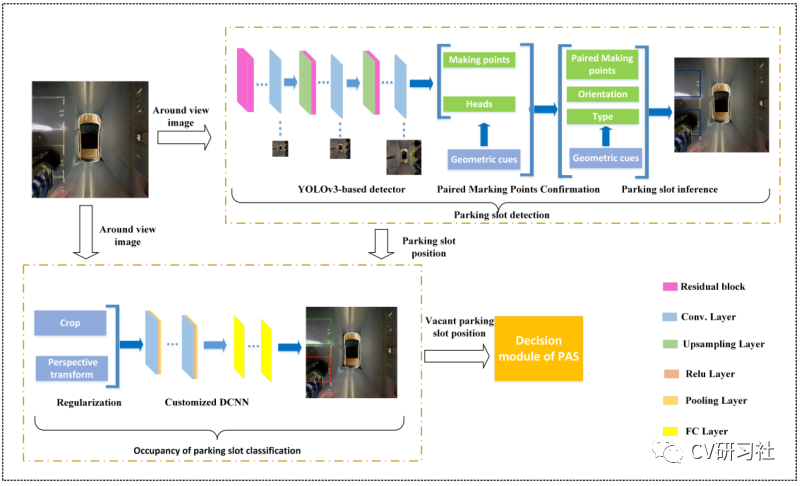
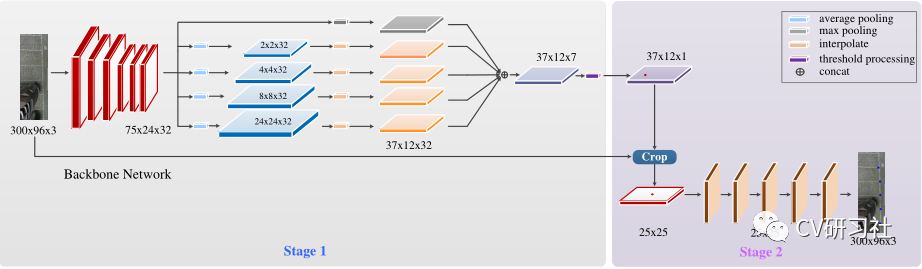
本文是一篇介绍鱼眼相机做车位线检测的文章,放眼当下泊车功能在智能汽车领域研究的如火如荼,从L2级的APA自动泊车发展到L2+的RPA远程遥控泊车再到L3级的HPA自学习泊车最后研究AVP自主泊车,其中每个功能都少不了车位线的检测。通过本文让小编带着大家一起学习车位线检测的相关技术和方法。小编近期从周视相机感知转战到环视感知领域,个人觉得对于行人、车辆等目标检测和道路信息的语义分割从实现上差别不大,但是如何做车位线检测任务让我纠结许久,也算是把近几年各种深度学习做车位线检测的文章都看了一遍,下面对常规方法做些总结分享。理想的车位线由四个角点和四条线组成,如下图所示:红色的称为入口线(the entrance line),左右两条称为分割线(the separate line),底部的紫线一般用处不大作为边界即可。a. 基于直线的方法通过找到两条分割线与入口线检测停车位,在一些使用传统图像处理算法检测车位线的系统中进行出现,使用Sobel,Canny等算子进行边缘检测,结合Hough变换利用几何特征获得潜在的停车位边界线。但是此类传统算法容易受到光照条件,线条磨损,地面阴影等环境因素的影响,性能缺乏鲁棒性。b. 基于标记点的方法是通过检测入口线和两条分割线的交叉口,然后结合角点坐标检测停车位。传统图像处理算法中提供了不少人工设计的角点检测器,如Harris角点检测,Shi-Tomasi角点检测,FAST角点检测等。如果采用此类方法仍然会出现上述Hough线检测的鲁棒性问题,所以部分学者将车位线的入口线和分割线的两个相交区域作为检测目标,如下图所示:c. 基于分割的方法是对车辆、空闲空间、停车位标识和其他对象进行逐像素的分类。这样就把车位线检测问题转换成了语义分割问题,形如前视感知中的车道线检测任务,但是语义分割任务需要经过一系列复杂的后处理才能得到相对准确的停车位,时耗上无法满足嵌入式端的实时要求。车位线的类型大方向主要有三种:垂直、水平、倾斜。但是在做车位线分类或者程序后处理时会遇到形形色色的结构,比如:比如某些路边的停车位常用路沿代替一条分割线;某些停车场的车位入口线和分割线会分离开;整个停车位颜色不同于周边区域,但是就没停车线~~~等等。在无人驾驶的感知模块,不过是前视,周视,环视的环境感知,用深度学习提取特征做分类是必不可少的一项技术。如果最便捷的做出一款车位线检测的Demo,需要做好两项准备工作:近几年开源了很多用深度学习做车位线检测的方法,下面小编给大家介绍几篇(顺序不分前后):“Attentional Graph Neural Network for Parking-slot Detection”:该文分为三个阶段,分别是图特征编码、图特征聚合、入口线鉴别,在拼接的鸟瞰图上通过图神经网络对标记点之间的邻近信息进行聚合来进行车位线检测,解决常规标记点独立检测后的后处理步骤冗余问题。“Context-Based Parking Slot Detection With a Realistic Dataset”:该文有点类似Faser RCNN的粗略定位+精细微调两阶段网络,先在PCR模块中识别是否有停车位,在通过PSD模块对旋转BBox准确定位。“DMPR-PS A Novel Approach For Parking-slot Detection Using Directional Marking-point regression”该文通过检测带方向的标记点得到一张拼接后的鸟瞰图中所有入口线与分割线的相交区域,然后对其进行过滤筛选并配对分类出车位类型。“Vacant Parking Slot Detection in the Around View Image Based on Deep Learning”:该文分为两个模块,车位线的检测和车位占用情况分类。车位线的检测模块采用YOLOv3的方式对整个车位槽的头部区域进行检测分类得到车位类型,省去了只检测两个交叉点后通过后处理得到车位类型的环节。“PSDet: EfficientandUniversalParkingSlotDetection”:该文也是对车位线的交叉点进行检测,不同之处在于它对比了几种交叉点特征描述器的形式,采用圆形特征描述子提取交叉点范围内的特征能够更好的识别车位线相交区域。相关文章较多,小编就不一一举例了,需要相关文章的小伙伴可以私聊找我。说完了网络结构,我们来看看有哪些开源的车位线数据集。目前找到的只有三个:ps2.0是一份四颗鱼眼拼接后的数据,数据均属于停车场景,训练集约1W张,测试集不到5K张,标签是mat格式。数据如下图所示:PSV同ps2.0数据集差不多,由四颗鱼眼相机拼接后的图片制作而成。数据量较小,训练集2550张,验证集425张,测试集1274张,标签是语义分割图。数据如下图所示:WoodScape数据集更偏向于每颗鱼眼独立的环境感知,标签包括约1W张外接框标签、约1W张语义标签、约1W张深度图、4颗相机的标定文件等信息,适用于分割、深度估计、三维包围盒检测、斑点检测等9项任务。数据如下图所示:基于开源数据集训练的结果往往不适用自己的场景,需要自采自标小批量的对应场景做网络微调从而提高车位线的检测效果。在这个过程中我们会遇到很多问题,比如如何采集数据、采集多少数据、采集哪些场景?其实最麻烦的就是一个维度划分的问题,虽然车位线的类型只有垂直、水平、倾斜三种,但是外部环境因素多种多样。比如:制定采集标准时,一定要考虑细致详尽,并对每种数据的采集数量确保相对平衡,否则会造成部分情况效果较差。下图是从一篇文章中找到的维度参考,做做Demo应该可以了:除了堆数据提高性能以外,可以考虑网络的输入和输出形式,输入是四颗鱼眼的拼接图还是单颗鱼眼的原始数据?输出是以车位线四个关键点的形式还是入口处两个相交区域外接框形式又或者语义图形式?小编还在斟酌中,暂无很好的建议。要想把Demo做到产品还有一大段路要走,不仅仅只关注把原型开发的模型移植到嵌入式端跑起来就结束了。从前期打通数据链路开始,关注RAW数据类型,ISP参数调节,算法模块设计,硬件加速单元的分配等;再到数据采集方式,标注形式数量,工具链如何提供高效迭代验证,以及代码质量审核,模型间性能评估等等一系列工作。路漫漫其修远兮,吾将上下而求索。好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~