
一文读懂层次聚类(Python代码)
本篇想和大家介绍下层次聚类,先通过一个简单的例子介绍它的基本理论,然后再用一个实战案例Python代码实现聚类效果。
首先要说,聚类属于机器学习的无监督学习,而且也分很多种方法,比如大家熟知的有K-means。层次聚类也是聚类中的一种,也很常用。下面我先简单回顾一下K-means的基本原理,然后慢慢引出层次聚类的定义和分层步骤,这样更有助于大家理解。
层次聚类和K-means有什么不同?
K-means 工作原理可以简要概述为:
- 决定簇数(k)
- 从数据中随机选取 k 个点作为质心
- 将所有点分配到最近的聚类质心
- 计算新形成的簇的质心
- 重复步骤 3 和 4
这是一个迭代过程,直到新形成的簇的质心不变,或者达到最大迭代次数。
但是 K-means 是存在一些缺点的,我们必须在算法开始前就决定簇数 K 的数量,但实际我们并不知道应该有多少个簇,所以一般都是根据自己的理解先设定一个值,这就可能导致我们的理解和实际情况存在一些偏差。
层次聚类完全不同,它不需要我们开始的时候指定簇数,而是先完整的形成整个层次聚类后,通过决定合适的距离,自动就可以找到对应的簇数和聚类。
什么是层次聚类?
下面我们由浅及深的介绍什么是层次聚类,先来一个简单的例子。
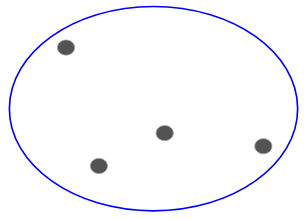
假设我们有以下几点,我们想将它们分组:

我们可以将这些点中的每一个分配给一个单独的簇,就是4个簇(4种颜色):

然后基于这些簇的相似性(距离),将最相似的(距离最近的)点组合在一起并重复这个过程,直到只剩下一个集群: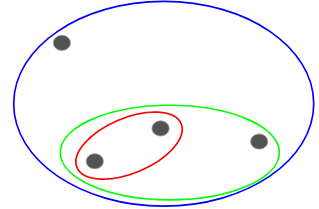
上面本质上就是在构建一个层次结构。先了解到这里,后面我们详细介绍它的分层步骤。
层次聚类的类型
主要有两种类型的层次聚类:
- 凝聚层次聚类
- 分裂层次聚类
凝聚层次聚类
先让所有点分别成为一个单独的簇,然后通过相似性不断组合,直到最后只有一个簇为止,这就是凝聚层次聚类的过程,和我们上面刚刚说的一致。
分裂层次聚类
分裂层次聚类正好反过来,它是从单个集群开始逐步分裂,直到无法分裂,即每个点都是一个簇。
所以无论是 10、100、1000 个数据点都不重要,这些点在开始的时候都属于同一个簇:
现在,在每次迭代中拆分簇中相隔最远的两点,并重复这个过程,直到每个簇只包含一个点:
上面的过程就是分裂层次聚类。
执行层次聚类的步骤
上面已经说了层次聚类的大概过程,那关键的来了,如何确定点和点的相似性呢?
这是聚类中最重要的问题之一了,一般计算相似度的方法是:计算这些簇的质心之间的距离。距离最小的点称为相似点,我们可以合并它们,也可以将其称为基于距离的算法。
另外在层次聚类中,还有一个称为邻近矩阵的概念,它存储了每个点之间的距离。下面我们通过一个例子来理解如何计算相似度、邻近矩阵、以及层次聚类的具体步骤。
案例介绍
假设一位老师想要将学生分成不同的组。现在有每个学生在作业中的分数,想根据这些分数将他们分成几组。关于拥有多少组,这里没有固定的目标。由于老师不知道应该将哪种类型的学生分配到哪个组,因此不能作为监督学习问题来解决。下面,我们将尝试应用层次聚类将学生分成不同的组。
下面是个5名学生的成绩:
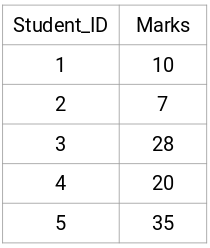
创建邻近矩阵
首先,我们要创建一个邻近矩阵,它储存了每个点两两之间的距离,因此可以得到一个形状为 n X n 的方阵。
这个案例中,可以得到以下 5 x 5 的邻近矩阵:
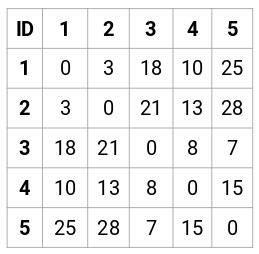
矩阵里有两点需要注意下:
- 矩阵的对角元素始终为 0,因为点与其自身的距离始终为 0
- 使用欧几里得距离公式来计算非对角元素的距离
比如,我们要计算点 1 和 2 之间的距离,计算公式为:
同理,按此计算方法完成后填充邻近矩阵其余元素。
执行层次聚类
这里使用凝聚层次聚类来实现。
步骤 1:首先,我们将所有点分配成单个簇:
这里不同的颜色代表不同的簇,我们数据中的 5 个点,即有 5 个不同的簇。
步骤2:接下来,我们需要查找邻近矩阵中的最小距离并合并距离最小的点。然后我们更新邻近矩阵: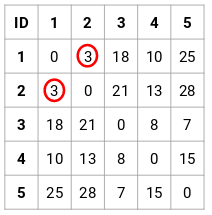 最小距离是 3,因此我们将合并点 1 和 2:
最小距离是 3,因此我们将合并点 1 和 2: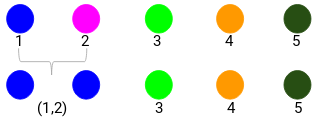 让我们看看更新的集群并相应地更新邻近矩阵:
让我们看看更新的集群并相应地更新邻近矩阵: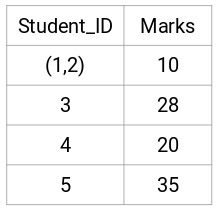
更新之后,我们取了1、2 两个点中值 (7, 10) 最大的来替换这个簇的值。当然除了最大值之外,我们还可以取最小值或平均值。然后,我们将再次计算这些簇的邻近矩阵: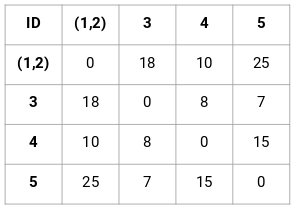 第 3 步:重复第 2 步,直到只剩下一个簇。
第 3 步:重复第 2 步,直到只剩下一个簇。
重复所有的步骤后,我们将得到如下所示的合并的聚类:
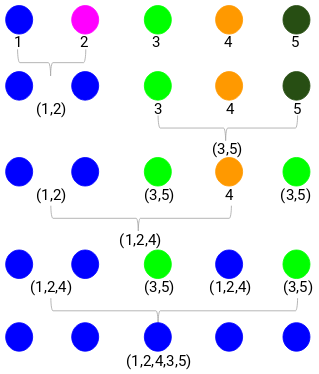
这就是凝聚层次聚类的工作原理。但问题是我们仍然不知道该分几组?是2、3、还是4组呢?
下面开始介绍如何选择聚类数。
如何选择聚类数?
为了获得层次聚类的簇数,我们使用了一个概念,叫作树状图。
通过树状图,我们可以更方便的选出聚类的簇数。
回到上面的例子。当我们合并两个簇时,树状图会相应地记录这些簇之间的距离并以图形形式表示。下面这个是树状图的原始状态,横坐标记录了每个点的标记,纵轴记录了点和点之间的距离:
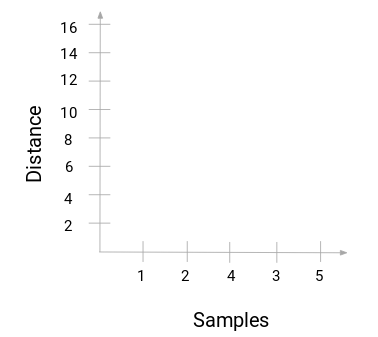
当合并两个簇时,将会在树状图中连接起来,连接的高度就是点之间的距离。下面是我们刚刚层次聚类的过程。
然后开始对上面的过程进行树状图的绘制。从合并样本 1 和 2 开始,这两个样本之间的距离为 3。
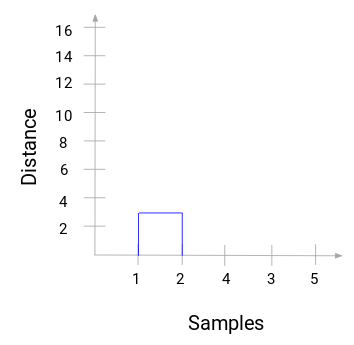
可以看到已经合并了 1 和 2。垂直线代表 1 和 2 的距离。同理,按照层次聚类过程绘制合并簇类的所有步骤,最后得到了这样的树状图:
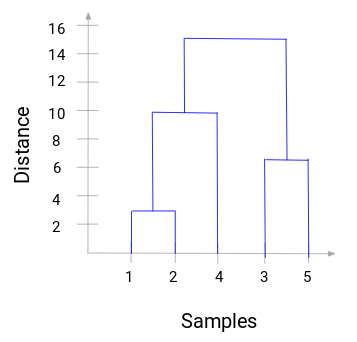
通过树状图,我们可以清楚地形象化层次聚类的步骤。树状图中垂直线的距离越远代表簇之间的距离越大。
有了这个树状图,我们决定簇类数就方便多了。
现在我们可以设置一个阈值距离,绘制一条水平线。比如我们将阈值设置为 12,并绘制一条水平线,如下:
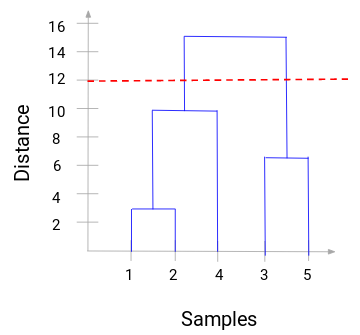
从交点中可以看到,聚类的数量就是与阈值水平线与垂直线相交的数量(红线与 2 条垂直线相交,我们将有 2 个簇)。与横坐标相对应的,一个簇将有一个样本集合为 (1,2,4),另一个集群将有一个样本集合 (3,5)。
这样,我们就通过树状图解决了分层聚类中要决定聚类的数量。
Python代码实战案例
上面是理论基础,有点数学基础都能看懂。下面介绍下在如何用代码Python来实现这一过程。这里拿一个客户细分的数据来展示一下。
数据集和代码在我的GitHub里,欢迎star!
https://github.com/xiaoyusmd/PythonDataScience
这个数据来源于UCI 机器学习库。我们的目的是根据批发分销商的客户在不同产品类别(如牛奶、杂货、地区等)上的年度支出,对他们进行细分。
首先对数据进行一个标准化,为了让所有数据在同一个维度便于计算,然后应用层次聚类来细分客户。
from sklearn.preprocessing import normalize
data_scaled = normalize(data)
data_scaled = pd.DataFrame(data_scaled, columns=data.columns)
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))
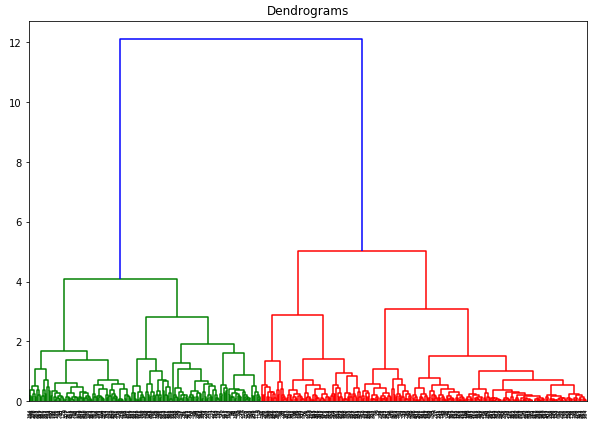
x 轴包含了所有样本,y 轴代表这些样本之间的距离。距离最大的垂直线是蓝线,假如我们决定要以阈值 6 切割树状图:
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))
plt.axhline(y=6, color='r', linestyle='--')
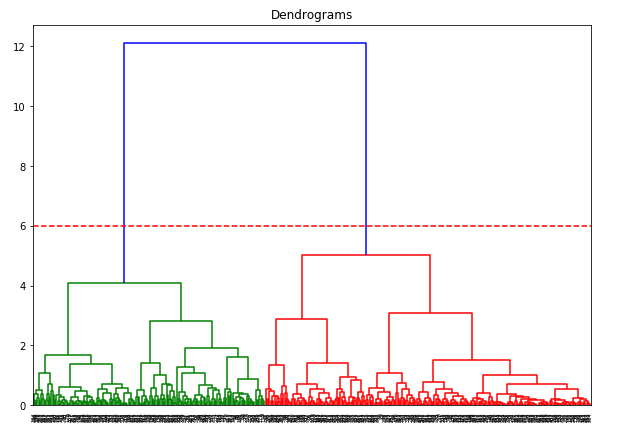
现在我们有两个簇了,我们要对这 2 个簇应用层次聚类:
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(data_scaled)
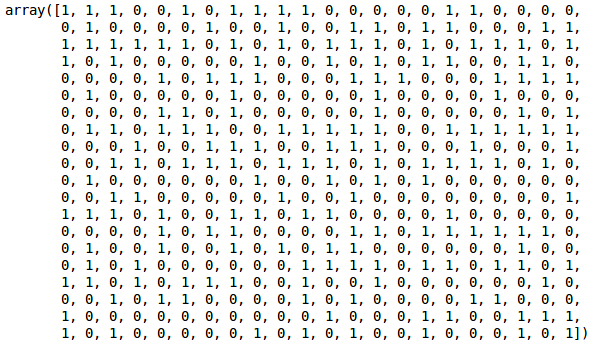
由于我们定义了 2 个簇,因此我们可以在输出中看到 0 和 1 的值。0 代表属于第一个簇的点,1 代表属于第二个簇的点。
plt.figure(figsize=(10, 7))
plt.scatter(data_scaled['Milk'], data_scaled['Grocery'], c=cluster.labels_)
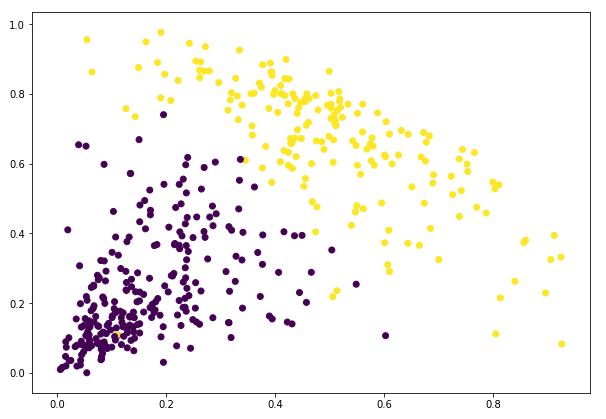
到这里我们就成功的完成了聚类。
参考:https://www.analyticsvidhya.com/blog/2019/05/beginners-guide-hierarchical-clustering/
- END -