
100%抄袭!ICLR 2022投稿论文剽窃两篇顶会,连换词都懒得换
共 531字,需浏览 2分钟
·
2021-11-07 20:13

本文素材转自:新智元
【导读】ICLR 2022会议投稿出现抄袭事件,夸张的是数据和表格都是从以前的paper上直接拿下来的。在项目主席以严重的剽窃案例为由发出Desk Reject之前,作者竟然撤回了提交的内容。这是怎么回事?
朋友们,又到了一月好几度的「学术不端」曝光时间了。之前什么「借鉴」idea,「英译中」都弱爆了,甚至直接照搬都没有这次的「别出心裁」,至少人家还是「忠实原著」的。随便举一个例子,比如下面这个是原论文的图。
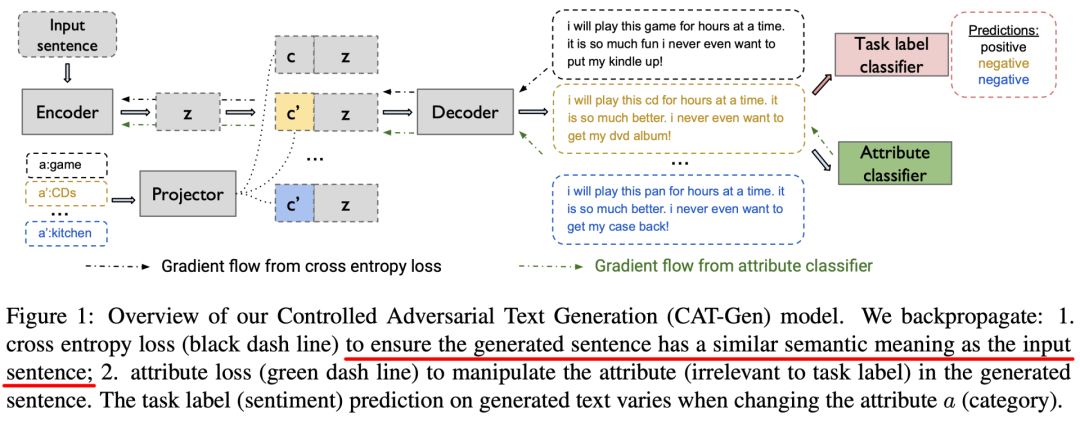
Wang et al. EMNLP 2020
再来看看这篇论文的图。
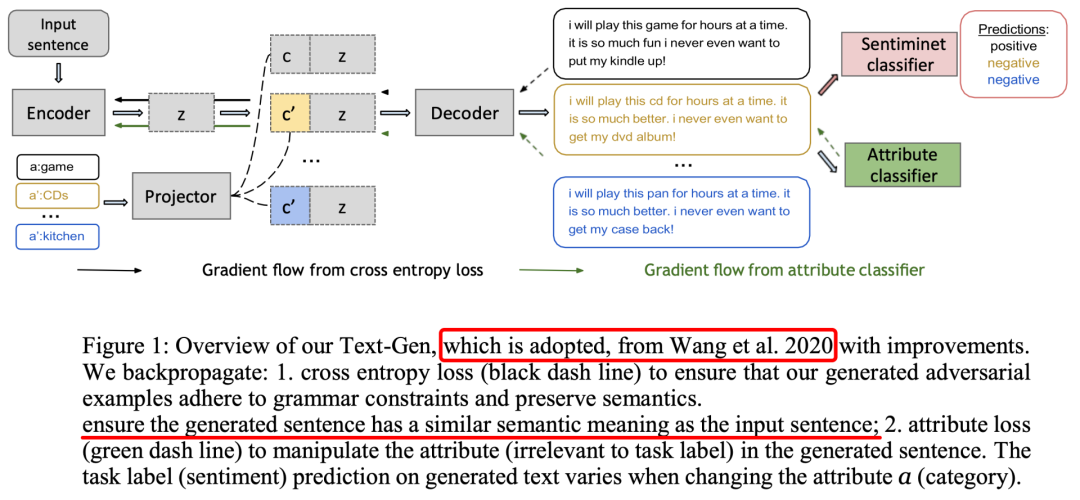
ICLR 2022投稿
请看两处红色横线部分,莫非这就是传说中的「抄串行」了?
但通篇读下来,其实严格来说并不是100%相似,而是99%。因为还有1%是抄或者改错的部分(doge)。
这么明目张胆地搞事情难道没人管管么?
果不其然,11月1日,一封来自ICLR 2022程序主席的Desk Reject直接怼脸了。

图1是100%复制/粘贴自[1](作者注明 「采用自」),包括图注
表1是来自[1]的截图(作者注明「采用自」),标题是复制/粘贴的,没有任何署名
表2:和[1]差不多,但有一些替换(例如。Android <- Phone, kitchen <- room, shirt <- clothing)
表3:复制了[1]中的前3行,没有注明出处,第4行是新的(比[1]中的第4行表现更差)
算法1是来自[2]的截图;未注明出处
被抄袭的两篇论文为:
[1] CAT-Gen: Improving Robustness in NLP Models via Controlled Adversarial Text Generation. Wang et al. EMNLP 2020

https://arxiv.org/pdf/2010.02338.pdf
[2] FreeLB: Enhanced Adversarial Training for Natural Language Understanding. Zhu et al. ICLR 2020
 https://arxiv.org/pdf/1909.11764.pdf
https://arxiv.org/pdf/1909.11764.pdf
其实,作者团队在10月29日就确认撤稿了。
但是对于学术不端的行为,怎么能放过这个「公开处刑」的机会呢!

连换词都懒得换的「抄袭」
虽然之前很火的「Patches are all you need」只有4页,但是这篇论文只有「6页」的原因,显然是不一样的。
 https://openreview.net/pdf?id=EO4VJGAllb
https://openreview.net/pdf?id=EO4VJGAllb
摘要
读论文嘛,首先要看看摘要部分。

左:CAT-Gen原文;右:Text-Gen论文
用红色圈出相似的地方之后,嚯,有点厉害啊。
这篇论文向我们展示了经典的单词替换 +「把」字句变「被」字句。显然,意思丝毫不变。
甚至,摘要的前半部分还算是稍微动手改了改,后半部分直接把原文拿过来贴上。真的,是一个单词都没有改。(但复制的时候还挺不小心的,漏了空格和横短线)
引言
引言部分居然还有点「良心发现」,挪用了些关键词,句子嘛,倒是好好重写了一番。

左:CAT-Gen原文;右:Text-Gen论文
就是这个引用的文章,是不是重合的太多了?
论文正文
这上来就已经「彻底放弃抵抗」了,大段大段直接往上糊。

左:CAT-Gen原文;右:Text-Gen论文
你说一个字不改也就罢了,抄还抄不全乎。
单词拼不对,单词之间少空格,强迫症看了真心头疼,抄袭也得有点「责任心」嘛。
这两篇文章都提到了一个「三阶段」架构,那就都拿出来看看。
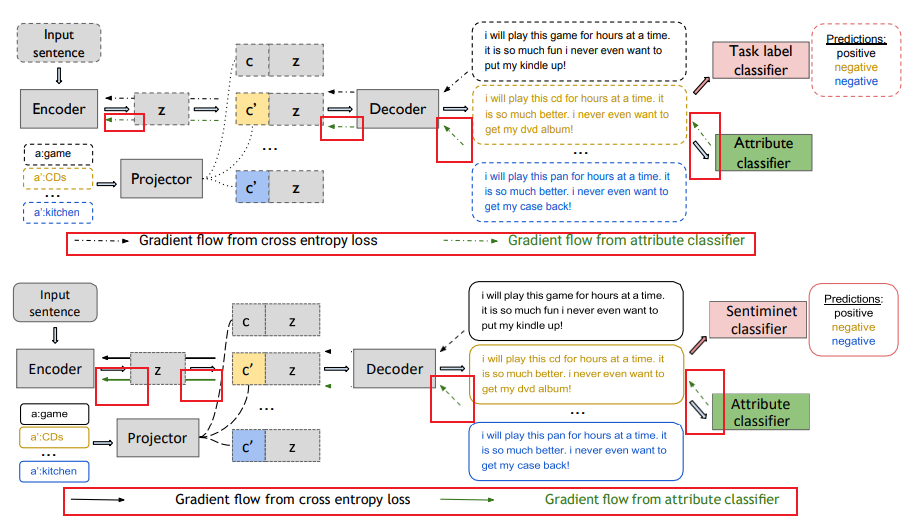
上:CAT-Gen原文;下:Text-Gen论文
Text-Gen这篇论文的图直接是从CAT-Gen原文复制过来的,就把箭头的示意图从虚线改成实线。
但是,虽然示意图是变了,图中的箭头只有一半改成了实线,另一半还是虚线。
Text-Gen文中的算法,乍一看和CAT-Gen原文不一样,原来是从另一篇文章FreeLB里面直接贴过来的。

左:FreeLB原文;右:Text-Gen论文
右边看上去没有左边清晰,那是因为Text-Gen论文这个算法部分并不是手敲进去的,而是直接从FreeLB原文截的图。
实验结果
实验结果自然也是完全一样。
展示前人的工作效果时也是直接截图。

上:CAT-Gen原文;下:Text-Gen论文
轮到自己的工作时,Text-Gen的实验结果表格几乎和CAT-Gen原文一样,就只进行了一些单词字面的替代。(表格画得也是潦草得很)

上:CAT-Gen原文;下:Text-Gen论文
这最后的定量实验数据就更搞笑了。
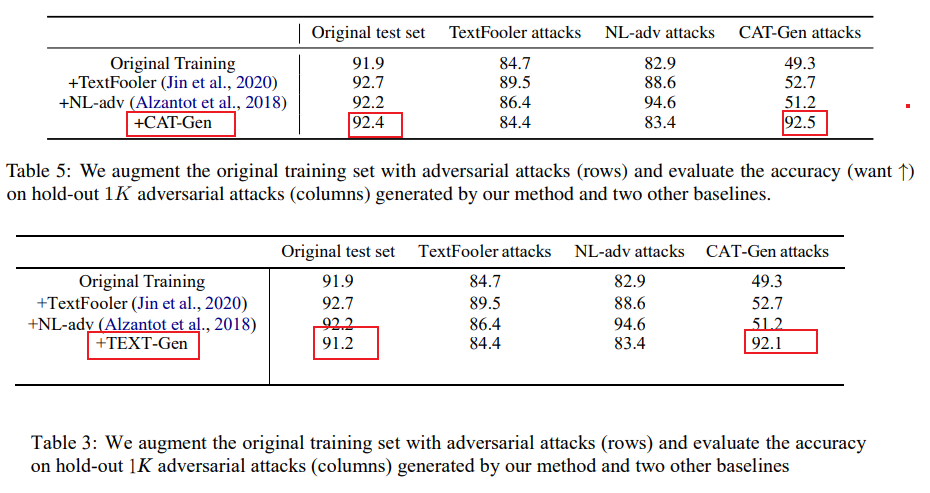
上:CAT-Gen原文;下:Text-Gen论文
文章都已经是抄袭了,还要坚守最后一点「倔强」,非要用Text-Gen自己的数据作为试验结果。Text-Gen的性能数据漂亮也就罢了,结果还不如人家原文的CAT-Gen的数据。
连评委都在吐槽。(编都不知道编个好点的)

网友评论
抄袭事件一出,Reddit已经有了好多人的评论。有的网友觉得这个造假者的「撤稿」行为太「冠冕堂皇」。
「难道他们内心认可抄袭这件事是错的,然后还是去抄袭了吗?」

有的网友感觉这种抄袭已经没什么好大惊小怪的了。
「机器学习和深度学习的论文经常会出现抄袭的情况。这种事就看有没有人去查。抄袭的人本质上就是在赌没有人会注意到他的抄袭。」
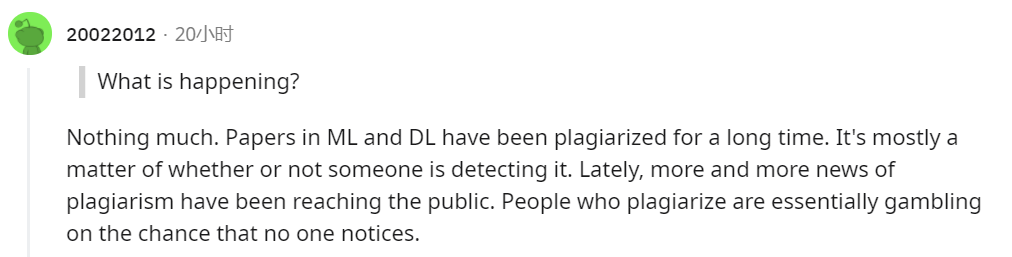
另一个网友也非常同意「抄袭的人本质上就是在赌没有人会注意到他的抄袭」这个观点。
「许多剽窃博士学位的人发现他们看似是『逃脱』了辛苦,但他们的整个职业生涯都被毁掉了。」

最近的学术不端行为频频发生,这也是给学术研究者时时刻刻的提醒,科研工作者心中一定要牢记求真,求实,对学术诚信要有敬畏之心,绝不能踏过红线,不要有侥幸心理,否则就是自毁前程。每位科研工作者在做好自己的工作时,要懂得尊重他人的学术成果。
参考资料:
https://www.reddit.com/r/MachineLearning/comments/qkb6ga/plagiarism_case_detected_iclr_2022_newsdiscussion/
涉事论文:https://openreview.net/pdf?id=EO4VJGAllb
论文[1]:https://arxiv.org/pdf/2010.02338.pdf
论文[2]:https://arxiv.org/pdf/1909.11764.pdf
— 双11福利 · 甄选40门AI好课1分起秒 —
福利:甄选40门AI好课1分起秒
时间:截止2021年11月12日 中午12点
主会场:www.julyedu.com
— 推荐阅读 —
最新大厂面试题
AI开源项目论文
NLP ( 自然语言处理 )
CV(计算机视觉)
推荐
戳↓↓“阅读原文” 进入活动主会场!